In un articolo precedente abbiamo esplorato le basi dei dati semi-strutturati e il supporto che Snowflake offre per gestirli. Abbiamo inoltre analizzato i diversi metodi per importare dati semi-strutturati in Snowflake. Ora che questi dati sono in Snowflake, qual è il passo successivo? In questo articolo ci concentreremo nello specifico su come lavorare in modo efficace con i dati JSON. Approfondiremo le funzionalità di trasformazione e le funzioni specifiche che Snowflake mette a disposizione per questo scopo. Faremo inoltre un breve riepilogo su come caricare dati JSON in Snowflake.
Le funzioni di parsing JSON di Snowflake
Snowflake offre numerose funzioni per lavorare con dati JSON semi-strutturati. Le tre più comuni sono:
PARSE_JSON: riceve in input una stringa come documento JSON e restituisce un valoreVARIANTTRY_PARSE_JSON: funziona esattamente comePARSE_JSON, ma restituisce un valore null se si verifica un errore durante il parsingLATERAL FLATTEN: serve ad appiattire un array su più righe, una per ogni oggetto contenuto nell'array.
Approfondiremo ciascuna di queste funzioni qui sotto. Prima, però, ci servono dei dati di esempio su cui lavorare!
Creare dati JSON di esempio
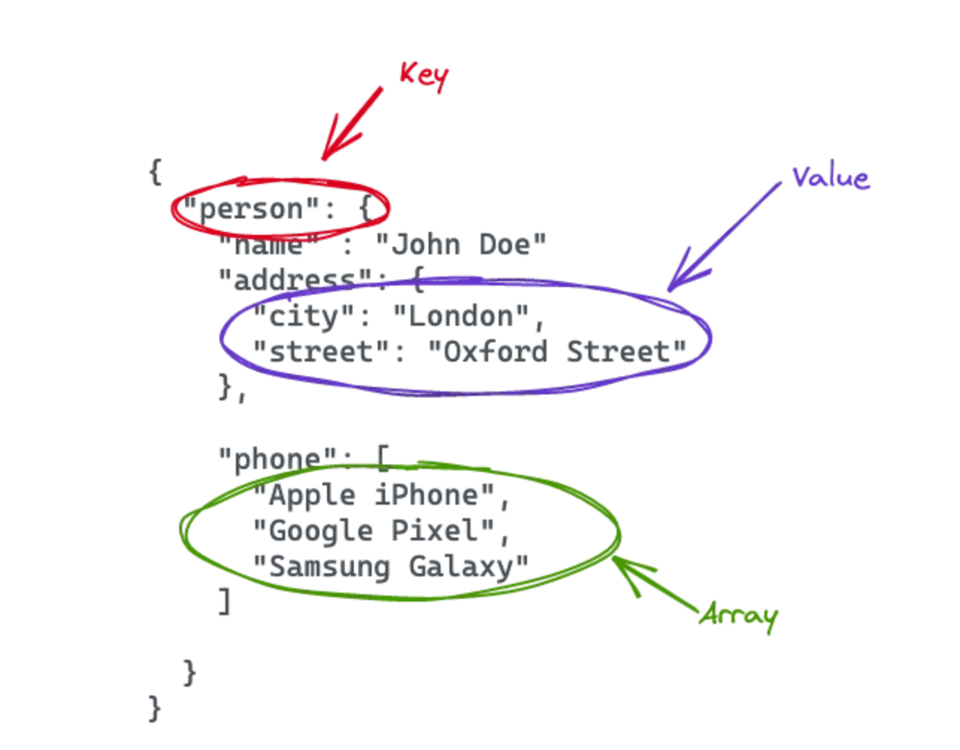
Nel corso dell'articolo lavoreremo con i seguenti dati JSON di esempio, che contengono informazioni su una persona:
1{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Caricheremo questi dati in una tabella chiamata sample_json_data e la useremo per testare tutte le funzionalità. La tabella conterrà il documento JSON in un'unica colonna VARIANT denominata src:
create table sample_json_data
(src variant)
;
Come usare PARSE_JSON
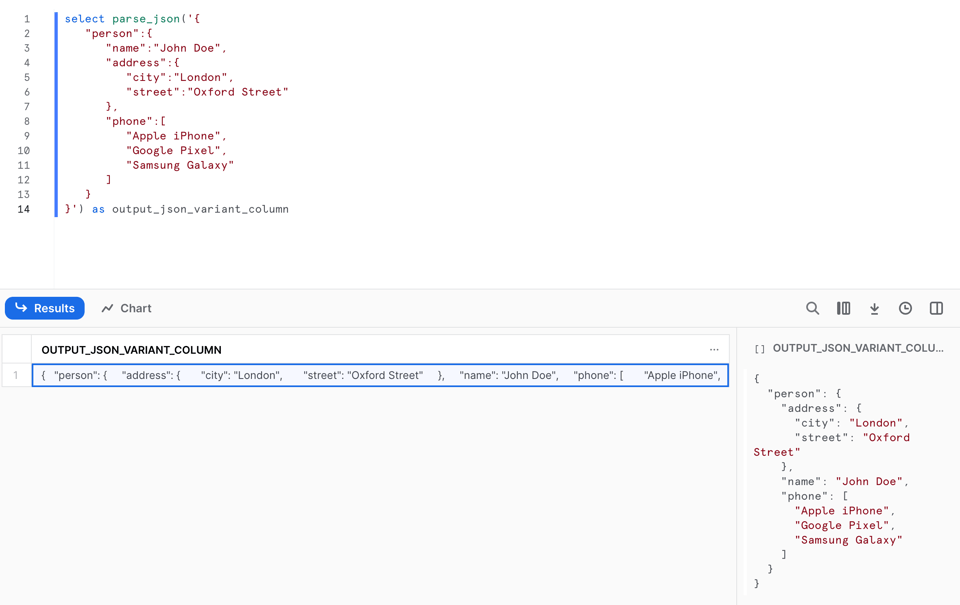
Per convertire la stringa di un documento JSON in un VARIANT dobbiamo utilizzare la funzione PARSE_JSON.
1select parse_json('{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}') as output_json_variant_column
Ecco il risultato:
Ora possiamo usare questa funzione per popolare la nostra tabella sample_json_data
1insert into sample_json_data
2select parse_json('{
3 "person":{
4 "name":"John Doe",
5 "address":{
6 "city":"London",
7 "street":"Oxford Street"
8 },
9 "phone":[\
\
10 "Apple iPhone",\
\
11 "Google Pixel",\
\
12 "Samsung Galaxy"\
\
13 ]
14 }
15}');
Come usare TRY_PARSE_JSON
TRY_PARSE_JSON funziona esattamente come PARSE_JSON:
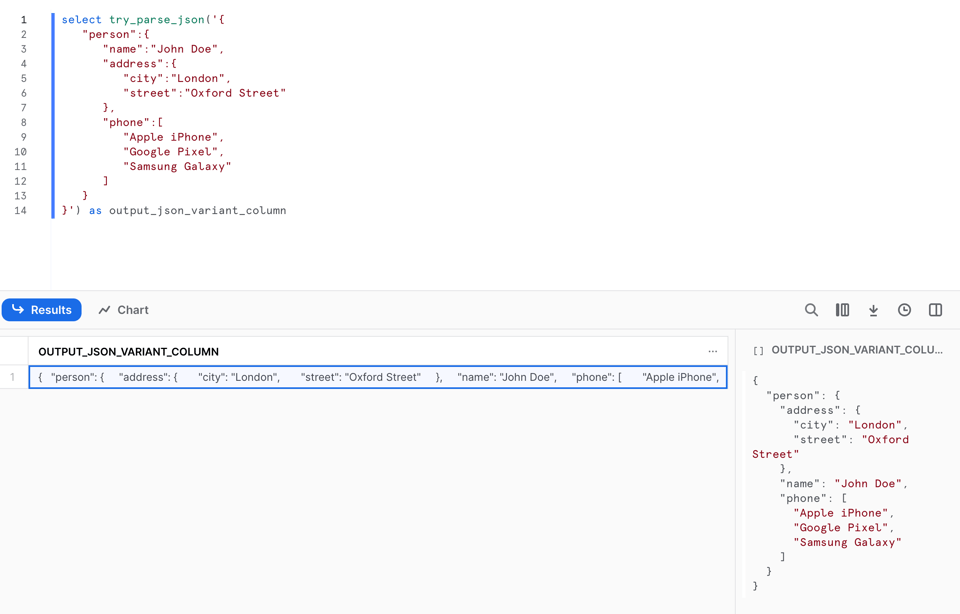
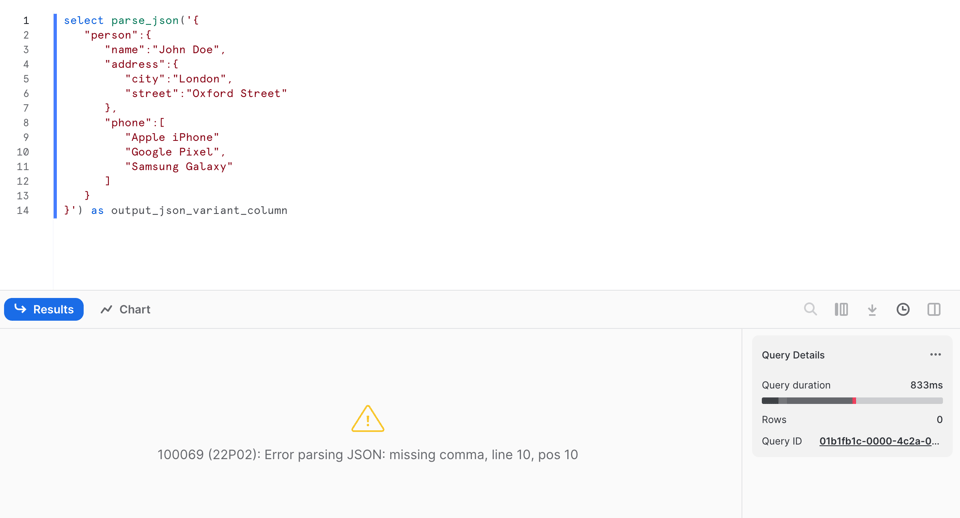
Tuttavia, a differenza di PARSE_JSON, restituisce null quando non riesce a effettuare il parsing del JSON. Osservando la riga 9 noterà che ho rimosso la virgola!
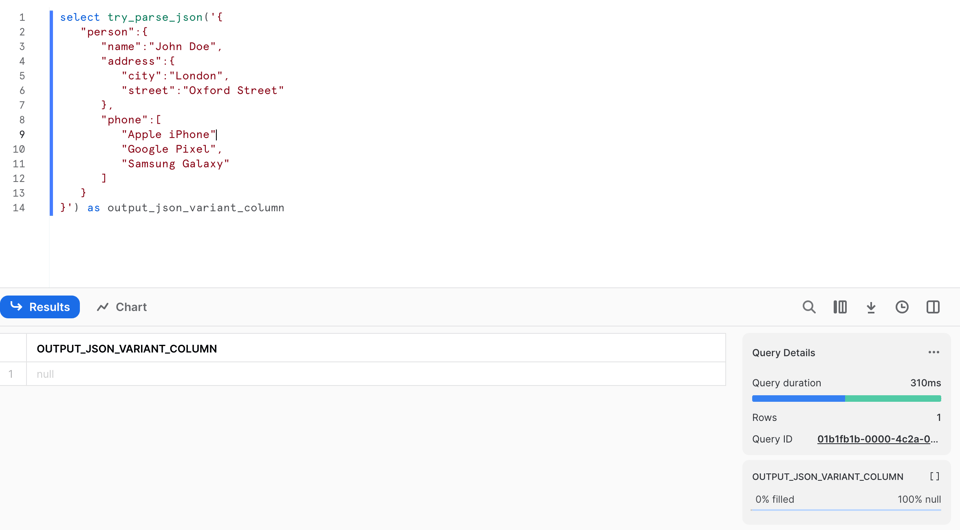
Se eseguiamo PARSE_JSON su questi dati malformati, l'operazione fallisce con un errore:
La notazione per interrogare una colonna JSON
Iniziamo ora ad accedere ai dati contenuti in questo tipo semi-strutturato. Per recuperare i valori da una chiave di primo livello possiamo usare la notazione con i due punti, ad esempio src:person. Se invece ha bisogno di scendere più in profondità nella struttura dell'oggetto, ha due opzioni: la notazione puntata, con un'istruzione come src:person.address.city, oppure la notazione con parentesi quadre, come src['person']['address']['city'].
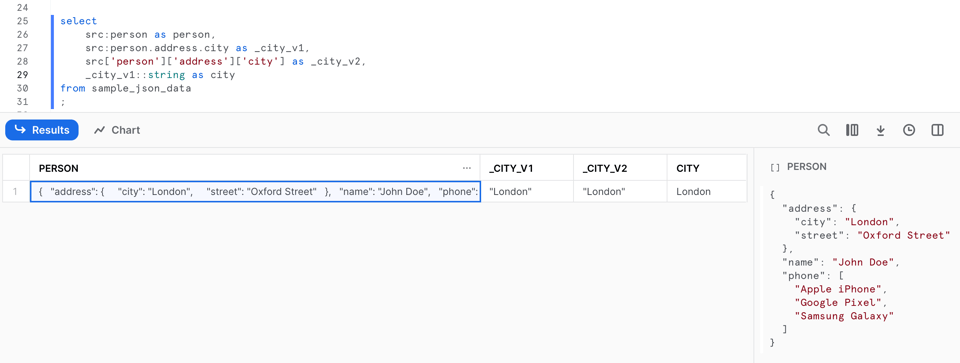
Possiamo riassumere questi metodi con le seguenti formulazioni generali:
- Notazione puntata:
<column>:<level1_element>.<level2_element>.<level3_element> - Notazione con parentesi quadre:
<column>['<level1_element>']['<level2_element>']['<level3_element>']
Se alcune chiavi non rispettano le regole degli identificatori SQL di Snowflake — ad esempio quando contengono spazi — con la notazione puntata è necessario racchiuderne il nome tra virgolette doppie. Con la notazione a parentesi quadre, invece, i valori vanno sempre racchiusi tra apici singoli.
Come usare LATERAL FLATTEN per elaborare gli array
Nella sezione precedente abbiamo visto le basi della navigazione di un documento JSON tramite notazione puntata e a parentesi quadre. Ma cosa succede quando il documento contiene degli array? Applicando la stessa logica, selezionare src:person:phone restituirebbe l'intero array come un unico valore, ad esempio [ "Apple iPhone", "Google Pixel", "Samsung Galaxy" ].
Per iterare sull'array ed estrarne i singoli valori dobbiamo appiattirlo. Otterremo così tre righe distinte, ciascuna con un singolo valore dell'array.
Snowflake offre due funzioni a questo scopo: LATERAL e FLATTEN, che si usano spesso insieme.
Il join LATERAL consente a una inline view di fare riferimento alle colonne di un'espressione di tabella precedente. A differenza di un join non laterale, l'output di un join laterale comprende solo le righe generate dalla inline view. Vale la pena segnalare che, nella mia esperienza, non ho mai utilizzato un join LATERAL senza la funzione FLATTEN, anche se tecnicamente è possibile.
La funzione FLATTEN espande i valori composti su più righe. Accetta un tipo di dato semi-strutturato (VARIANT, OBJECT o ARRAY) e produce una vista laterale. Vediamolo con un esempio in cui espandiamo il nostro array di telefoni cellulari su più righe utilizzando queste due funzioni:
SELECT
p.*
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p
La query produce il seguente risultato:
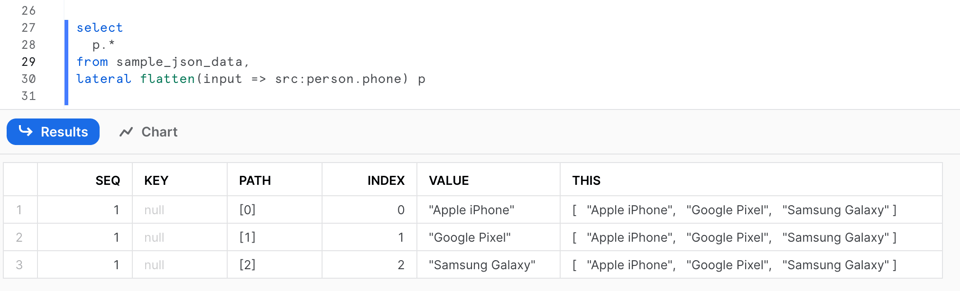
L'output della funzione FLATTEN comprende diverse colonne:
SEQ: numero di sequenza univoco associato al record di input; si tenga presente che la sequenza potrebbe non essere ordinata né priva di salti.KEY: per mappe e oggetti, questa colonna contiene la chiave del valore espanso.PATH: il percorso dell'elemento all'interno della struttura dati che si sta appiattendo.INDEX: l'indice dell'elemento se fa parte di un array; altrimenti NULL.VALUE: il valore dell'elemento all'interno dell'array o dell'oggetto appiattito.THIS: l'elemento specifico che si sta appiattendo, utile nel flattening ricorsivo.
Inoltre, le colonne provenienti dal lato sinistro del join LATERAL restano accessibili. Possiamo quindi modificare la query per convertire i dati semi-strutturati del documento JSON in una struttura piatta:
SELECT
src:person.name::varchar AS person_name,
src:person.address.city::varchar AS city,
src:person.address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Ecco il risultato:

In questa query SQL è necessario il cast esplicito delle colonne perché l'output è in forma variant, ovvero i valori sono racchiusi tra virgolette doppie. Dobbiamo quindi convertirli esplicitamente al tipo di dato desiderato.
Lavorare con più livelli di array annidati
Se si trova davanti a uno scenario con più livelli di array annidati, in cui un array ne contiene un altro, può applicare la funzione LATERAL FLATTEN ai valori espansi del livello 1 per espandere ulteriormente i valori dell'array al livello annidato. Lo pseudocodice di un'operazione di questo tipo sarebbe il seguente:
SELECT
lvl_1.value,
lvl_2.value
FROM table
LATERAL FLATTEN (input => src:topLevelArray) AS lvl_1,
LATERAL FLATTEN (input => lvl_1.value:innerLevelArray) AS lvl_2;
In sostanza è tutto qui. Combinando la notazione puntata o a parentesi quadre con LATERAL FLATTEN, può costruire una solida base per lavorare con i dati JSON memorizzati nelle tabelle di Snowflake. Questo approccio le permette di trasformare i dati nel formato che le serve in modo efficiente.
Costruire documenti JSON a partire da dati relazionali
Abbiamo visto come elaborare i dati JSON. E nella direzione opposta, quando vogliamo trasformare dati strutturati in JSON?
Convertire i dati relazionali di una tabella Snowflake in formato JSON è fondamentale, soprattutto quando si condividono dati con sistemi esterni che spesso richiedono JSON per i payload delle API. Vediamo come farlo utilizzando le funzioni native di Snowflake.
Immagini di avere una tabella chiamata relational_data, creata a partire dall'output della funzione LATERAL FLATTEN. Il nostro obiettivo è ricondurre questi dati relazionali a una struttura JSON. Per prima cosa creiamo e popoliamo la tabella relational_data:
CREATE TABLE relational_data (
person_name VARCHAR,
city VARCHAR,
street VARCHAR,
mobile_phone VARCHAR
);
INSERT INTO relational_data
SELECT
src:"person".name::varchar AS person_name,
src:"person".address.city::varchar AS city,
src:"person".address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Per costruire un oggetto JSON con coppie chiave-valore utilizziamo la funzione OBJECT_CONSTRUCT. Questa funzione accetta coppie di argomenti, in cui il primo è una chiave e il secondo è un valore. Per gli oggetti annidati ricorriamo a un'ulteriore chiamata di OBJECT_CONSTRUCT. Per creare una struttura base di una persona con un nome, l'istruzione SQL sarebbe:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name)) AS src
FROM relational_data;
La query produce la seguente struttura JSON:
{
"person": {
"name": "John Doe"
}
}
Includiamo ora l'oggetto address con i valori per city e street:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
)
)
) AS src
FROM relational_data;
Infine, per aggiungere un array di telefoni cellulari, utilizziamo la funzione ARRAY_AGG(), che crea un array a partire dai valori in input. Ecco la query SQL completa per la struttura JSON finale:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
),
'phone', ARRAY_AGG(mobile_phone) WITHIN GROUP (ORDER BY person_name) OVER (PARTITION BY person_name)
)
) AS src
FROM relational_data;
Il processo ricostruisce correttamente il documento JSON:
1{
2 "person": {
3 "address": {
4 "city": "London",
5 "street": "Oxford Street"
6 },
7 "name": "John Doe",
8 "phone": [\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Con questi passaggi abbiamo trasformato in modo efficace dati relazionali in un documento JSON strutturato, pronto per essere utilizzato nelle più diverse applicazioni.
Come caricare i dati JSON
Negli esempi precedenti abbiamo usato dati JSON di esempio. La maggior parte dei clienti Snowflake non li ha già pronti e dovrà iniziare caricando i dati JSON nel proprio account.
Per caricare un file di dati JSON in una tabella Snowflake, il comando SQL sarebbe simile a questo:
COPY INTO <table_name>
FROM (
SELECT
$1:person:name::STRING as name,
$1:person:address:city::STRING as city,
$1:person:address:street::STRING as street,
$1:person:phone[0]::STRING as phone1,
$1:person:phone[1]::STRING as phone2,
$1:person:phone[2]::STRING as phone3
FROM <my_stage>/<my_json_file.json>
);
Il comando presuppone che:
<table_name>sia il nome della tabella di destinazione in Snowflake.<my_stage>sia il nome dello stage in cui è memorizzato il file JSON.<my_json_file.json>sia il nome del file JSON.
Nell'istruzione SELECT:
- La notazione
$1fa riferimento alla prima colonna del file in caricamento, che in questo caso corrisponde all'intero blob JSON. - La notazione con i due punti
:serve a navigare nella struttura JSON. - Il cast
::STRINGconverte gli elementi JSON nel tipo di dato appropriato, che in questo esempio èSTRING. Può adattare il tipo di dato in base alle sue esigenze.
L'esempio presuppone che la struttura JSON sia coerente in tutti i record del file JSON. Se la struttura varia, potrebbe essere necessaria una logica aggiuntiva di gestione degli errori o di parsing.
Per un approfondimento sulle diverse opzioni di caricamento dei dati semi-strutturati (inclusi i dati JSON) nel suo data warehouse Snowflake, consulti il nostro articolo precedente.
Consigli pratici per lavorare con i dati JSON
Ecco alcuni ulteriori consigli utili da tenere a mente quando si lavora con i dati JSON:
- Utilizzi un formattatore JSON online gratuito, come questo, per formattare i suoi dati. Sarà così più facile ispezionarne visivamente la struttura e comprenderne la gerarchia.
- Costruisca le query un passo alla volta e verifichi l'output a ogni passaggio. Ad esempio, eviti di interrogare 4 livelli di JSON annidato in un colpo solo. Sarà molto più semplice individuare gli errori, che inevitabilmente si verificheranno.
- Utilizzi colonne temporanee per semplificare le operazioni. Può ad esempio effettuare il parsing di alcuni livelli di JSON in un'unica colonna e poi proseguire l'elaborazione a partire da lì. Le colonne in eccesso possono essere eliminate in seguito con il comando exclude di Snowflake. Ecco un esempio che mostra come evitare l'elaborazione ripetitiva del campo
address. Restituirà solo due colonne:cityestreet:
with
data as (
select
src:person.address as address,
address:city::string as city,
address:street::string as street
from sample_json_data
s)
select * exclude(address)
from data
- Quando crea nuovi dataset a partire da dati JSON, cerchi di separare le colonne consultate più di frequente in colonne dedicate, invece di lasciarle in un'unica colonna
variant. L'esperienza di interrogazione delle tabelle migliorerà notevolmente per l'utente finale. - Gli attributi JSON sono case sensitive. Se scrivo
address.Cityinvece diaddress:city, otterrònull.
La nostra guida si conclude qui. Ora sa come effettuare il parsing di un documento JSON, appiattirlo e memorizzarlo in una tabella relazionale in Snowflake. Abbiamo inoltre esplorato il processo inverso: la creazione di JSON a partire da una tabella Snowflake. I nostri esempi si sono concentrati su strutture dati semplici, ma gli stessi principi si applicano a documenti JSON di qualsiasi complessità o dimensione. Tutto sta nel combinare con maestria queste funzioni, come abbiamo mostrato negli esempi essenziali. Affrontando strutture più complesse, queste funzioni potranno entrare a far parte di Common Table Expressions (CTE), ma il concetto di fondo resta lo stesso.
Buon coding! 🧑💻
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è un Snowflake Data SuperHero di lunga data e un punto di riferimento sulla piattaforma Snowflake. La sua esperienza nel mondo dei dati copre oltre un decennio, durante il quale ha ricoperto i ruoli di data engineer, architect e admin Snowflake in progetti diversi, in settori e tecnologie eterogenei. Tomas è un membro attivo della community, condivide costantemente le sue competenze e ispira gli altri. È inoltre instructor per O'Reilly e conduce sessioni di formazione live online.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato le iniziative per ottimizzare il data warehouse e aumentare la visibilità sui costi.