Em um post anterior, exploramos os fundamentos de dados semiestruturados e o suporte que o Snowflake oferece para esse tipo de dado. Também discutimos diferentes formas de ingerir dados semiestruturados no Snowflake. Agora que esses dados já estão no Snowflake, qual o próximo passo? Neste post, vamos focar especificamente em como trabalhar com dados JSON de forma eficaz. Vamos nos aprofundar nos recursos de transformação e nas funções que o Snowflake oferece para isso. E faremos também uma rápida revisão de como carregar dados JSON no Snowflake.
Funções de parsing de JSON no Snowflake
O Snowflake oferece várias funções para trabalhar com dados JSON semiestruturados. As três mais comuns que você vai usar são:
PARSE_JSON: recebe uma string como documento JSON e retorna um valor do tipoVARIANTTRY_PARSE_JSON: funciona exatamente como oPARSE_JSON, mas retorna nulo caso ocorra algum erro durante o parsingLATERAL FLATTEN: usado para achatar um array em várias linhas — uma para cada objeto do array.
Vamos detalhar cada uma delas a seguir. Mas, primeiro, precisamos de alguns dados de exemplo!
Criando dados JSON de exemplo
Ao longo do post, vamos usar o seguinte JSON de exemplo, com informações sobre uma pessoa:
1{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Vamos carregar esses dados em uma tabela chamada sample_json_data e utilizá-la para testar todos os recursos. A tabela vai armazenar o documento JSON em uma única coluna do tipo VARIANT, chamada src:
create table sample_json_data
(src variant)
;
Como usar o PARSE_JSON
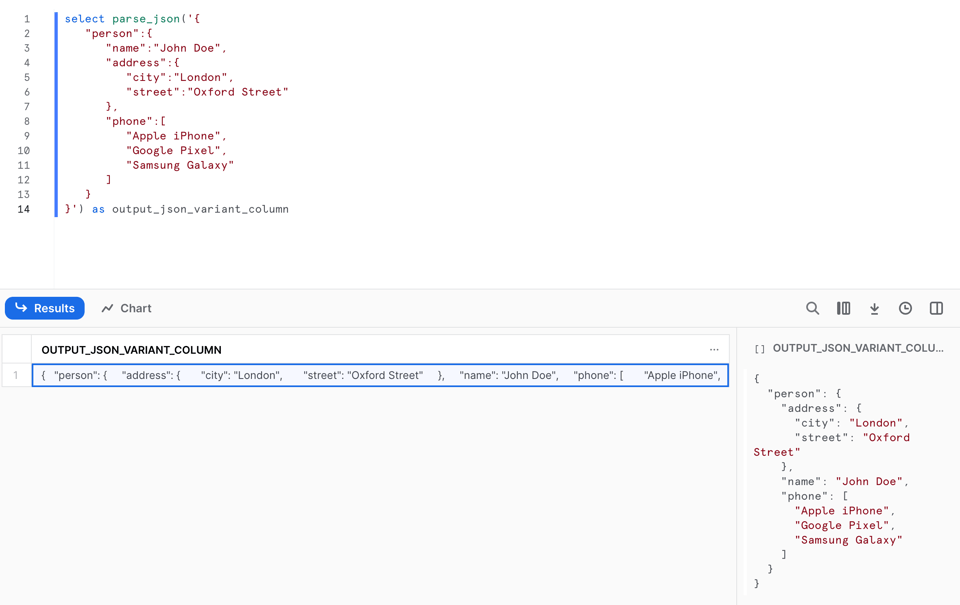
Para converter uma string com um documento JSON em um VARIANT, usamos a função PARSE_JSON.
1select parse_json('{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}') as output_json_variant_column
Veja o resultado:
Agora podemos usar essa função para popular a tabela sample_json_data:
1insert into sample_json_data
2select parse_json('{
3 "person":{
4 "name":"John Doe",
5 "address":{
6 "city":"London",
7 "street":"Oxford Street"
8 },
9 "phone":[\
\
10 "Apple iPhone",\
\
11 "Google Pixel",\
\
12 "Samsung Galaxy"\
\
13 ]
14 }
15}');
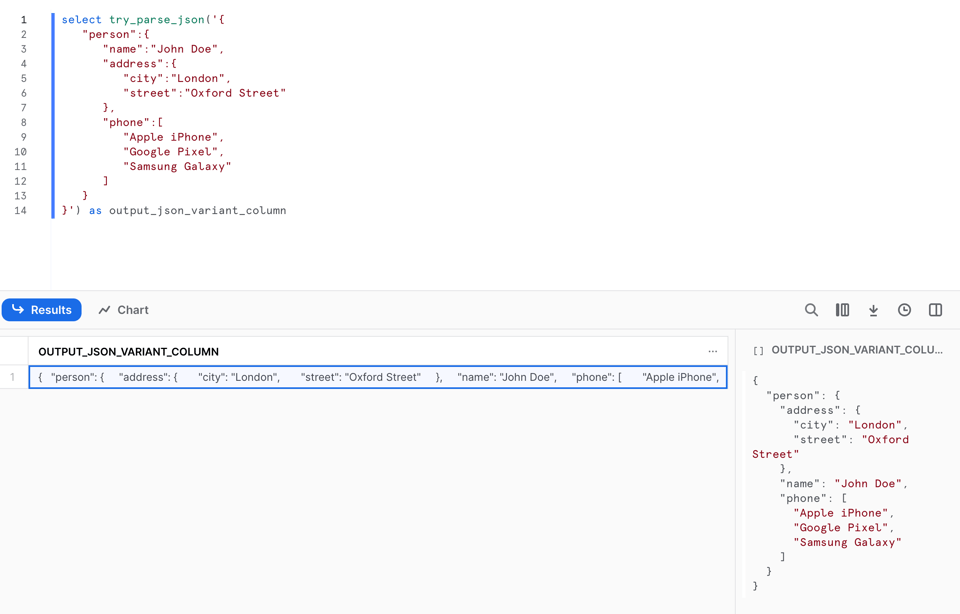
Como usar o TRY_PARSE_JSON
O TRY_PARSE_JSON funciona exatamente como o PARSE_JSON:
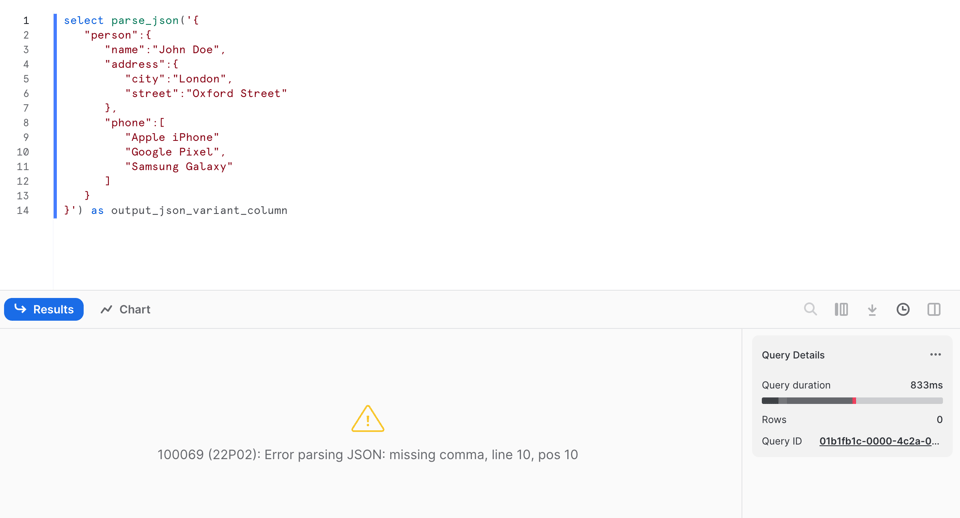
Porém, diferente do PARSE_JSON, ele retorna null quando não consegue fazer o parsing do JSON. Veja na linha 9: removi a vírgula!
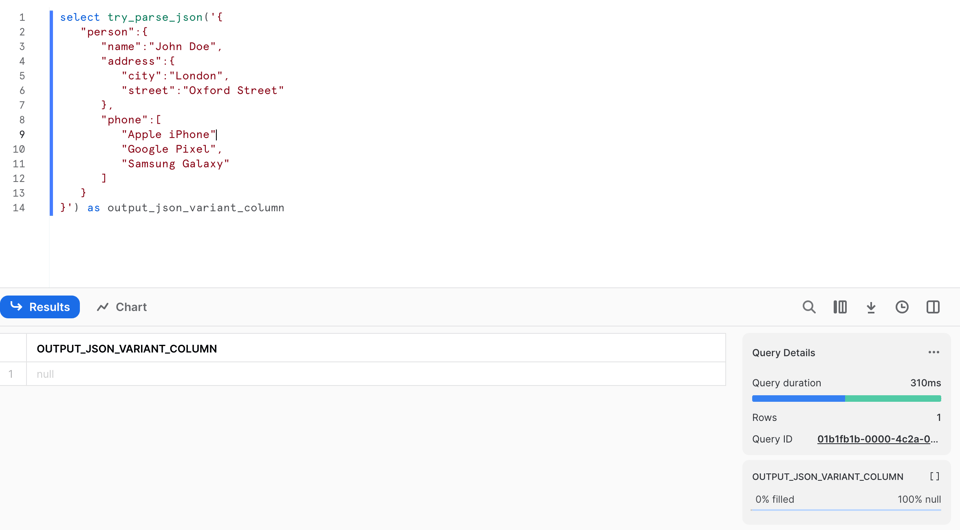
Se rodarmos o PARSE_JSON nesse dado inválido, ele falha com erro:
Notação para consultar uma coluna JSON
Agora vamos começar a acessar dados dentro desse tipo semiestruturado. Para recuperar dados de uma chave de nível superior, podemos usar a notação de dois-pontos, como em src:person. Se precisar descer mais na estrutura do objeto, há duas opções: notação de ponto, como src:person.address.city, ou notação de colchetes, como src['person']['address']['city'].
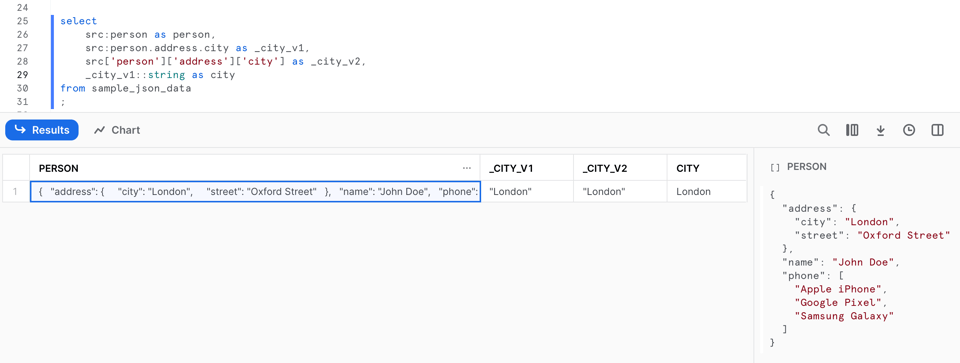
Podemos resumir esses métodos com as seguintes formas genéricas:
- Notação de ponto:
<column>:<level1_element>.<level2_element>.<level3_element> - Notação de colchetes:
<column>['<level1_element>']['<level2_element>']['<level3_element>']
Se algumas chaves não seguirem as regras de identificadores SQL do Snowflake — por exemplo, se contiverem espaços — é preciso colocar o nome da chave entre aspas duplas ao usar a notação de ponto. Já na notação de colchetes, os valores devem sempre vir entre aspas simples.
Como usar o LATERAL FLATTEN para processar arrays
Na seção anterior, vimos os fundamentos da navegação em um documento JSON com notação de ponto e de colchetes. Mas, e quando o documento contém arrays? Seguindo a mesma lógica, selecionar src:person:phone retornaria o array inteiro como um único valor, algo como [ "Apple iPhone", "Google Pixel", "Samsung Galaxy" ].
Para percorrer o array e expandir os valores individualmente, precisamos achatá-lo. O resultado serão três linhas, cada uma com um único valor do array.
O Snowflake oferece duas funções para isso: LATERAL e FLATTEN, normalmente usadas em conjunto.
O join LATERAL permite que uma view inline referencie colunas de uma expressão de tabela anterior. Diferente de um join não-lateral, a saída de um join lateral inclui apenas as linhas geradas pela view inline. Vale notar que, na minha experiência, nunca usei um join LATERAL sem a função FLATTEN, ainda que seja tecnicamente possível.
A função FLATTEN explode valores compostos em várias linhas. Ela recebe um tipo de dado semiestruturado (VARIANT, OBJECT ou ARRAY) e produz uma view lateral. Vamos ilustrar com um exemplo de como expandir nosso array de celulares em várias linhas usando essas duas funções:
SELECT
p.*
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p
Essa consulta gera o seguinte resultado:
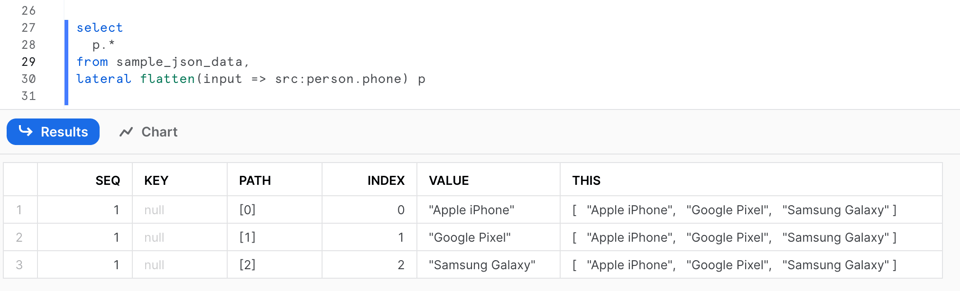
A saída da função FLATTEN inclui várias colunas:
SEQ: um número sequencial único associado ao registro de entrada; note que a sequência pode não estar ordenada nem ser contínua.KEY: para maps ou objetos, essa coluna contém a chave do valor explodido.PATH: o caminho até o elemento dentro da estrutura de dados que está sendo achatada.INDEX: o índice do elemento, caso ele faça parte de um array; caso contrário, NULL.VALUE: o valor do elemento no array ou objeto achatado.THIS: o elemento específico que está sendo achatado, útil em achatamentos recursivos.
Além disso, as colunas do lado esquerdo do join LATERAL continuam acessíveis. Assim, podemos alterar a consulta para transformar os dados semiestruturados do documento JSON em uma estrutura plana:
SELECT
src:person.name::varchar AS person_name,
src:person.address.city::varchar AS city,
src:person.address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Veja o resultado:

Nessa consulta SQL, o cast explícito das colunas é necessário porque a saída vem em formato variant, ou seja, os valores ficam entre aspas duplas. Precisamos convertê-los explicitamente para o tipo de dado desejado.
Trabalhando com vários níveis de arrays aninhados
Se você se deparar com vários níveis de arrays aninhados, em que um array contém outro, basta aplicar o LATERAL FLATTEN sobre os valores expandidos do primeiro nível para expandir os valores do nível seguinte. O pseudocódigo para essa operação ficaria assim:
SELECT
lvl_1.value,
lvl_2.value
FROM table
LATERAL FLATTEN (input => src:topLevelArray) AS lvl_1,
LATERAL FLATTEN (input => lvl_1.value:innerLevelArray) AS lvl_2;
É basicamente isso. Combinando a notação de ponto ou de colchetes com o LATERAL FLATTEN, você cria uma base sólida para trabalhar com dados JSON armazenados em tabelas do Snowflake. Essa abordagem permite transformar os dados no formato que você precisa, com eficiência.
Construindo documentos JSON a partir de dados relacionais
Já vimos como processar dados JSON. E o caminho inverso, quando queremos transformar dados estruturados em JSON?
Converter dados relacionais de uma tabela do Snowflake para JSON é essencial, principalmente ao compartilhar dados com sistemas externos que frequentemente exigem JSON em payloads de API. Vamos ver como fazer isso usando as funções nativas do Snowflake.
Imagine que temos uma tabela chamada relational_data, criada a partir da saída da função LATERAL FLATTEN. O objetivo é transformar esses dados relacionais de volta em uma estrutura JSON. Primeiro, criamos e populamos a tabela relational_data:
CREATE TABLE relational_data (
person_name VARCHAR,
city VARCHAR,
street VARCHAR,
mobile_phone VARCHAR
);
INSERT INTO relational_data
SELECT
src:"person".name::varchar AS person_name,
src:"person".address.city::varchar AS city,
src:"person".address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Para criar um objeto JSON com pares chave-valor, usamos a função OBJECT_CONSTRUCT. Ela recebe pares de argumentos: o primeiro é a chave e o segundo é o valor. Para objetos aninhados, usamos outra chamada de OBJECT_CONSTRUCT. Para criar uma estrutura básica de pessoa com um nome, o SQL ficaria assim:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name)) AS src
FROM relational_data;
Essa consulta gera a seguinte estrutura JSON:
{
"person": {
"name": "John Doe"
}
}
Em seguida, vamos incluir o objeto address com os valores de city e street:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
)
)
) AS src
FROM relational_data;
Por fim, para adicionar um array de celulares, usamos a função ARRAY_AGG(), que cria um array a partir de valores de entrada. Veja a consulta SQL completa para a estrutura JSON final:
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
),
'phone', ARRAY_AGG(mobile_phone) WITHIN GROUP (ORDER BY person_name) OVER (PARTITION BY person_name)
)
) AS src
FROM relational_data;
Esse processo reconstrói o documento JSON com sucesso:
1{
2 "person": {
3 "address": {
4 "city": "London",
5 "street": "Oxford Street"
6 },
7 "name": "John Doe",
8 "phone": [\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Com esses passos, transformamos dados relacionais em um documento JSON estruturado, pronto para uso em diversas aplicações.
Como carregar dados JSON
Nos exemplos acima, usamos dados JSON de teste. A maioria dos clientes do Snowflake não terá esses dados prontos e precisará começar carregando o JSON na sua conta.
Para carregar um arquivo JSON em uma tabela do Snowflake, o comando SQL ficaria mais ou menos assim:
COPY INTO <table_name>
FROM (
SELECT
$1:person:name::STRING as name,
$1:person:address:city::STRING as city,
$1:person:address:street::STRING as street,
$1:person:phone[0]::STRING as phone1,
$1:person:phone[1]::STRING as phone2,
$1:person:phone[2]::STRING as phone3
FROM <my_stage>/<my_json_file.json>
);
Esse comando pressupõe que:
<table_name>é o nome da tabela de destino no Snowflake.<my_stage>é o nome do stage onde o arquivo JSON está armazenado.<my_json_file.json>é o nome do arquivo JSON.
No SELECT:
- A notação
$1se refere à primeira coluna do arquivo que está sendo carregado, que, neste caso, é o blob JSON inteiro. - A notação de dois-pontos
:é usada para navegar pela estrutura JSON. - O cast
::STRINGconverte os elementos JSON para o tipo de dado desejado, que neste exemplo éSTRING. Você pode ajustar o tipo de dado conforme a sua necessidade.
Este exemplo pressupõe que a estrutura JSON é consistente em todos os registros do arquivo. Se a estrutura variar, pode ser necessário adicionar tratamento de erros ou lógica extra de parsing.
Para se aprofundar nas diferentes opções de carregamento de dados semiestruturados (incluindo JSON) no seu data warehouse Snowflake, confira nosso post anterior.
Dicas para trabalhar com dados JSON
Algumas outras dicas úteis para ter em mente ao trabalhar com dados JSON:
- Use um formatador de JSON online e gratuito, como este aqui, para formatar seus dados. Isso facilita a inspeção visual da estrutura e o entendimento da hierarquia dos dados.
- Monte suas consultas passo a passo e valide o resultado em cada etapa. Por exemplo, não tente consultar 4 níveis de JSON aninhado de uma só vez. Assim, fica muito mais fácil identificar os erros — que, inevitavelmente, vão aparecer.
- Use colunas temporárias para simplificar as operações. Por exemplo, dá para fazer o parse de alguns níveis de JSON em uma única coluna e seguir processando a partir dela. Depois, é só descartar as colunas extras com o comando exclude do Snowflake. Veja um exemplo que mostra como remover o processamento repetitivo do campo
address. Ele retorna apenas duas colunas:cityestreet:
with
data as (
select
src:person.address as address,
address:city::string as city,
address:street::string as street
from sample_json_data
)
select * exclude(address)
from data
- Ao criar novos datasets a partir de dados JSON, tente separar as colunas mais acessadas em colunas próprias, em vez de deixá-las em uma única coluna
variant. Isso melhora bastante a experiência do usuário final ao consultar as tabelas. - Atributos JSON são case sensitive. Se eu digitar
address.Cityem vez deaddress:city, o retorno seránull.
Com isso, encerramos nosso guia. Agora você já sabe como fazer o parsing de um documento JSON, achatá-lo e armazená-lo em uma tabela relacional no Snowflake. Também exploramos o caminho inverso — gerar JSON a partir de uma tabela do Snowflake. Nossos exemplos focaram em estruturas simples, mas os princípios valem para documentos JSON de qualquer complexidade ou tamanho. Tudo se resume a combinar essas funções com habilidade, como mostramos nos exemplos diretos. Conforme você lida com estruturas mais complexas, essas funções podem virar parte de Common Table Expressions (CTEs), mas o conceito por trás continua o mesmo.
Bons códigos! 🧑💻
Tomáš Sobotík·Senior Data Engineer & Snowflake SME na Norlys
Tomas é um Snowflake Data SuperHero de longa data e especialista no assunto Snowflake. Sua ampla experiência no mundo dos dados ultrapassa uma década, atuando como Snowflake data engineer, arquiteto e admin em diversos projetos, em setores e tecnologias variados. Tomas é membro central da comunidade, compartilhando ativamente seu conhecimento e inspirando outras pessoas. Ele também é instrutor da O'Reilly, conduzindo sessões de treinamento online ao vivo.
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando equipes full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.