Dans un précédent article, nous avons exploré les bases des données semi-structurées et la prise en charge qu'en assure Snowflake. Nous y avons également présenté plusieurs méthodes pour ingérer des données semi-structurées dans Snowflake. Maintenant que ces données s'y trouvent, quelle est l'étape suivante ? Cet article se concentre sur la manière d'exploiter efficacement les données JSON en particulier. Nous y détaillerons les possibilités de transformation et les fonctions spécifiques que Snowflake met à disposition, après un bref rappel sur le chargement de données JSON dans Snowflake.
Les fonctions de parsing JSON de Snowflake
Snowflake propose toute une palette de fonctions pour manipuler des données JSON semi-structurées. Voici les trois plus courantes :
PARSE_JSON: prend une chaîne en entrée comme document JSON et retourne une valeurVARIANTTRY_PARSE_JSON: fonctionne exactement commePARSE_JSON, mais retourne une valeur null en cas d'erreur de parsingLATERAL FLATTEN: sert à aplatir un tableau en plusieurs lignes — une par objet du tableau.
Nous détaillerons chacune d'elles plus bas. Mais avant cela, il nous faut quelques données d'exemple !
Créer des données JSON d'exemple
Tout au long de cet article, nous travaillerons avec les données JSON d'exemple suivantes, qui décrivent une personne :
1{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Nous chargerons ces données dans une table nommée sample_json_data, qui servira de support pour tester l'ensemble des fonctionnalités. La table stockera le document JSON dans une unique colonne VARIANT appelée src :
create table sample_json_data
(src variant)
;
Comment utiliser PARSE_JSON
Pour convertir une chaîne représentant un document JSON en VARIANT, on utilise la fonction PARSE_JSON.
1select parse_json('{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}') as output_json_variant_column
Et voici le résultat :
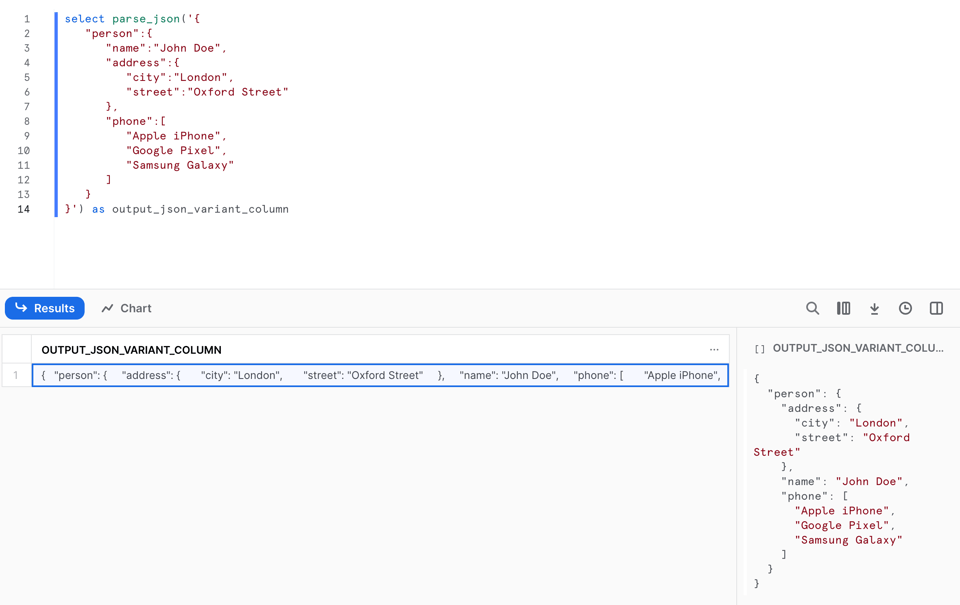
Cette fonction nous permet désormais d'alimenter notre table sample_json_data
1insert into sample_json_data
2select parse_json('{
3 "person":{
4 "name":"John Doe",
5 "address":{
6 "city":"London",
7 "street":"Oxford Street"
8 },
9 "phone":[\
\
10 "Apple iPhone",\
\
11 "Google Pixel",\
\
12 "Samsung Galaxy"\
\
13 ]
14 }
15}');
Comment utiliser TRY_PARSE_JSON
TRY_PARSE_JSON s'utilise exactement comme PARSE_JSON :
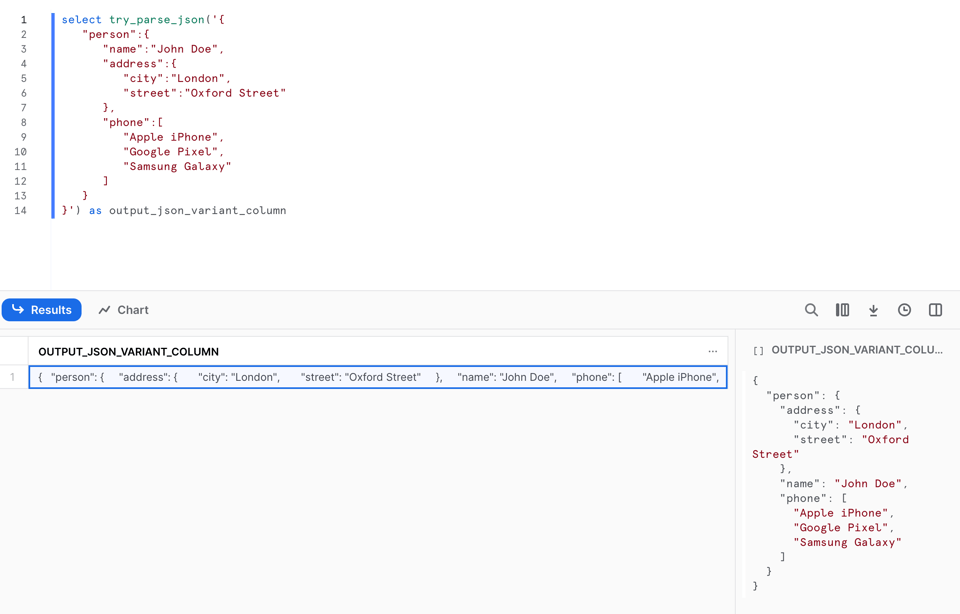
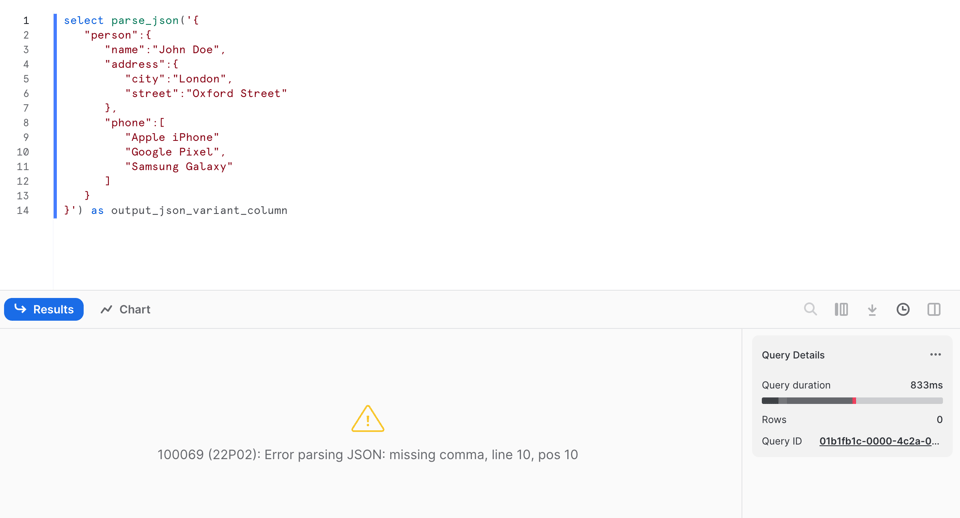
En revanche, contrairement à PARSE_JSON, elle retourne null si le parsing échoue. Regardez la ligne 9 : j'ai supprimé la virgule !
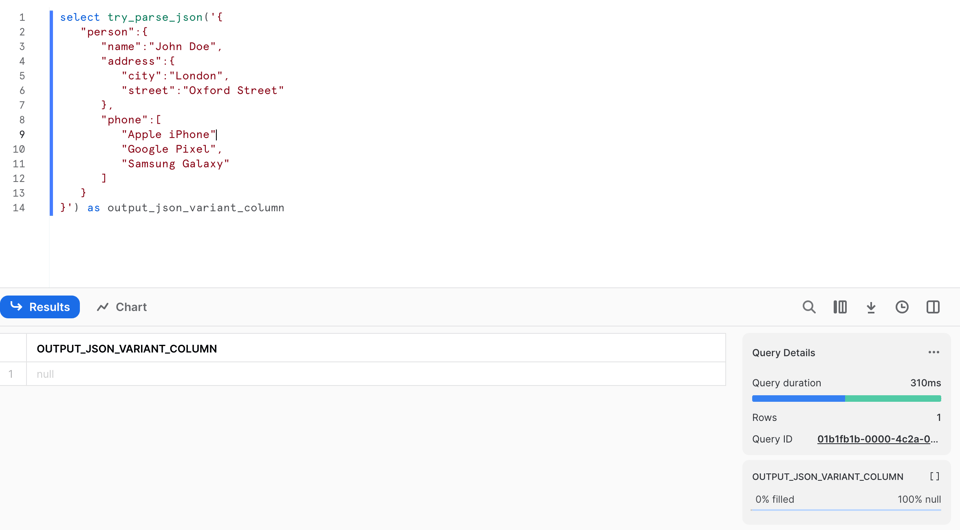
Si on lance PARSE_JSON sur ces données invalides, l'exécution échoue avec une erreur :
Notation pour interroger une colonne JSON
Passons maintenant à l'accès aux données contenues dans ce type semi-structuré. Pour récupérer la valeur d'une clé de premier niveau, on peut utiliser la notation à deux-points, comme src:person. Pour aller plus profond dans la structure de l'objet, deux options s'offrent à vous : la notation par points, avec une instruction du type src:person.address.city, ou la notation par crochets, avec une instruction comme src['person']['address']['city'].
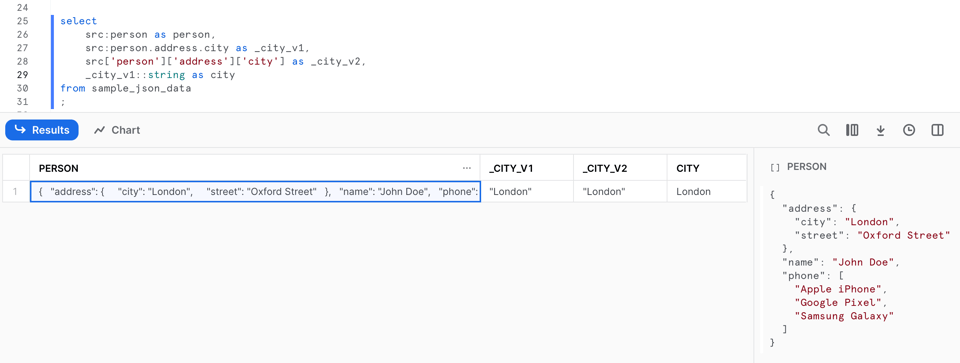
On peut résumer ces méthodes par les formulations générales suivantes :
- Notation par points :
<column>:<level1_element>.<level2_element>.<level3_element> - Notation par crochets :
<column>['<level1_element>']['<level2_element>']['<level3_element>']
Si certaines clés ne respectent pas les règles d'identifiant SQL de Snowflake — par exemple si elles contiennent des espaces — il faut entourer leur nom de guillemets doubles avec la notation par points. Avec la notation par crochets, les valeurs doivent toujours être entourées d'apostrophes.
Comment traiter des tableaux avec LATERAL FLATTEN
Dans la section précédente, nous avons vu comment naviguer dans un document JSON avec la notation par points et par crochets. Mais que se passe-t-il si votre document contient des tableaux ? Avec la même logique, src:person:phone renverrait le tableau entier sous la forme d'une seule valeur, comme [ "Apple iPhone", "Google Pixel", "Samsung Galaxy" ].
Pour parcourir le tableau et en extraire chaque valeur, il faut l'aplatir. On obtient alors trois lignes distinctes, chacune contenant une valeur du tableau.
Snowflake propose deux fonctions pour cela : LATERAL et FLATTEN, généralement utilisées conjointement.
La jointure LATERAL permet à une vue en ligne de référencer des colonnes issues d'une expression de table qui la précède. À la différence d'une jointure non latérale, sa sortie ne contient que les lignes produites par la vue en ligne. À noter que, d'après mon expérience, je n'ai jamais utilisé une jointure LATERAL sans FLATTEN, même si c'est techniquement possible.
La fonction FLATTEN, elle, éclate des valeurs composées en plusieurs lignes. Elle prend en entrée un type semi-structuré (VARIANT, OBJECT ou ARRAY) et produit une vue latérale. Voici un exemple qui montre comment développer notre tableau de téléphones mobiles en plusieurs lignes à l'aide de ces deux fonctions :
SELECT
p.*
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p
Cette requête produit le résultat suivant :
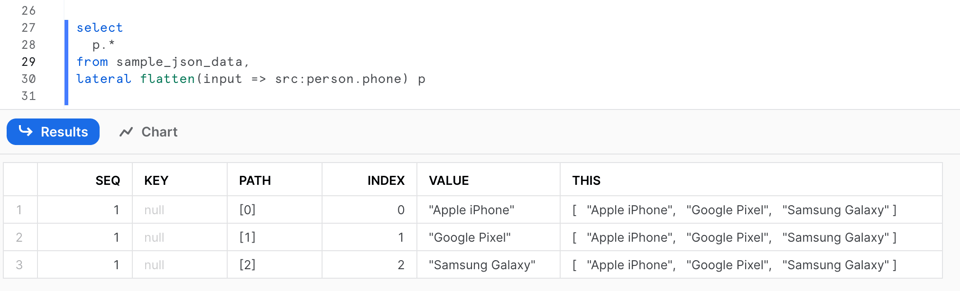
La sortie de FLATTEN comporte plusieurs colonnes :
SEQ: un numéro de séquence unique associé à l'enregistrement d'entrée ; à noter qu'il peut ne pas être ordonné ni continu.KEY: pour les maps ou objets, cette colonne contient la clé de la valeur éclatée.PATH: le chemin d'accès à l'élément au sein de la structure aplatie.INDEX: l'index de l'élément s'il appartient à un tableau ; NULL sinon.VALUE: la valeur de l'élément dans le tableau ou l'objet aplati.THIS: l'élément spécifique en cours d'aplatissement, utile dans le cadre d'un aplatissement récursif.
Par ailleurs, les colonnes situées à gauche de la jointure LATERAL restent accessibles. On peut donc adapter notre requête pour convertir les données semi-structurées du document JSON en structure plate :
SELECT
src:person.name::varchar AS person_name,
src:person.address.city::varchar AS city,
src:person.address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Et voici le résultat :

Dans cette requête SQL, la conversion explicite des colonnes est indispensable car la sortie est de type variant : les valeurs sont entourées de guillemets doubles. Il faut donc les convertir explicitement vers le type souhaité.
Travailler avec plusieurs niveaux de tableaux imbriqués
Si vous êtes confronté à plusieurs niveaux de tableaux imbriqués, où un tableau en contient un autre, vous pouvez réappliquer LATERAL FLATTEN aux valeurs développées du niveau 1 pour éclater à leur tour celles du niveau imbriqué. Le pseudo-code d'une telle opération ressemblerait à ceci :
SELECT
lvl_1.value,
lvl_2.value
FROM table
LATERAL FLATTEN (input => src:topLevelArray) AS lvl_1,
LATERAL FLATTEN (input => lvl_1.value:innerLevelArray) AS lvl_2;
C'est à peu près tout. En combinant notation par points ou par crochets avec LATERAL FLATTEN, vous disposez de bases solides pour exploiter les données JSON stockées dans vos tables Snowflake. Cette approche vous permet de transformer efficacement vos données dans le format souhaité.
Construire des documents JSON à partir de données relationnelles
Nous avons vu comment traiter des données JSON. Et dans l'autre sens, comment transformer des données structurées en JSON ?
Convertir au format JSON les données relationnelles d'une table Snowflake est souvent indispensable, notamment lors du partage de données avec des systèmes externes qui attendent du JSON pour les payloads d'API. Voyons comment procéder à l'aide des fonctions natives de Snowflake.
Imaginons une table nommée relational_data, créée à partir de la sortie de LATERAL FLATTEN. L'objectif est de reconvertir ces données relationnelles en structure JSON. Commençons par créer et alimenter la table relational_data :
CREATE TABLE relational_data (
person_name VARCHAR,
city VARCHAR,
street VARCHAR,
mobile_phone VARCHAR
);
INSERT INTO relational_data
SELECT
src:"person".name::varchar AS person_name,
src:"person".address.city::varchar AS city,
src:"person".address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
Pour construire un objet JSON sous forme de paires clé-valeur, on utilise la fonction OBJECT_CONSTRUCT. Elle prend des paires d'arguments : le premier est la clé, le second la valeur. Pour les objets imbriqués, on enchaîne avec un autre appel à OBJECT_CONSTRUCT. Pour créer une structure de personne basique avec un nom, l'instruction SQL est la suivante :
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name)) AS src
FROM relational_data;
Cette requête produit la structure JSON suivante :
{
"person": {
"name": "John Doe"
}
}
Ajoutons maintenant l'objet adresse avec les valeurs de ville et de rue :
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
)
)
) AS src
FROM relational_data;
Enfin, pour ajouter un tableau de téléphones mobiles, on utilise la fonction ARRAY_AGG(), qui crée un tableau à partir des valeurs d'entrée. Voici la requête SQL complète pour obtenir la structure JSON finale :
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
),
'phone', ARRAY_AGG(mobile_phone) WITHIN GROUP (ORDER BY person_name) OVER (PARTITION BY person_name)
)
) AS src
FROM relational_data;
Ce traitement reconstruit fidèlement le document JSON :
1{
2 "person": {
3 "address": {
4 "city": "London",
5 "street": "Oxford Street"
6 },
7 "name": "John Doe",
8 "phone": [\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
Grâce à ces étapes, nous avons transformé des données relationnelles en un document JSON structuré, prêt à être exploité dans diverses applications.
Comment charger des données JSON
Dans les exemples ci-dessus, nous avons utilisé des données JSON d'exemple. La plupart des clients Snowflake n'en disposent pas d'emblée et doivent commencer par charger leurs données JSON dans leur compte.
Pour charger un fichier de données JSON dans une table Snowflake, la commande SQL ressemble à ceci :
COPY INTO <table_name>
FROM (
SELECT
$1:person:name::STRING as name,
$1:person:address:city::STRING as city,
$1:person:address:street::STRING as street,
$1:person:phone[0]::STRING as phone1,
$1:person:phone[1]::STRING as phone2,
$1:person:phone[2]::STRING as phone3
FROM <my_stage>/<my_json_file.json>
);
Cette commande part des hypothèses suivantes :
<table_name>est le nom de la table de destination dans Snowflake.<my_stage>est le nom du stage qui contient le fichier JSON.<my_json_file.json>est le nom de votre fichier JSON.
Dans l'instruction SELECT :
- La notation
$1fait référence à la première colonne du fichier en cours de chargement, qui correspond ici à l'ensemble du blob JSON. - La notation à deux-points
:sert à naviguer dans la structure JSON. - Le cast
::STRINGconvertit les éléments JSON dans le type voulu, iciSTRING. Vous pouvez bien sûr adapter le type à vos besoins.
Cet exemple suppose que la structure JSON est identique sur tous les enregistrements du fichier. Si elle varie, vous aurez probablement besoin d'ajouter une logique de parsing ou de gestion des erreurs.
Pour aller plus loin sur les différentes options de chargement de données semi-structurées (JSON compris) dans votre data warehouse Snowflake, consultez notre précédent article.
Conseils pour travailler avec des données JSON
Voici quelques bonnes pratiques à garder en tête lorsque vous manipulez des données JSON :
- Utilisez un formateur JSON en ligne gratuit comme celui-ci pour mettre en forme vos données. C'est bien plus simple d'en inspecter visuellement la structure et de comprendre la hiérarchie.
- Construisez vos requêtes par étapes et vérifiez le résultat à chaque fois. Évitez par exemple d'interroger 4 niveaux de JSON imbriqués d'un seul coup : vous repérerez bien plus vite les erreurs, qui ne manqueront pas d'arriver.
- Recourez à des colonnes temporaires pour simplifier vos traitements. Vous pouvez par exemple parser plusieurs niveaux de JSON dans une colonne, puis poursuivre le traitement à partir de celle-ci. Les colonnes superflues pourront être écartées par la suite avec la commande exclude de Snowflake. Voici un exemple qui évite de retraiter à plusieurs reprises le champ
address. Il ne produit que deux colonnes :cityetstreet:
with
data as (
select
src:person.address as address,
address:city::string as city,
address:street::string as street
from sample_json_data
)
select * exclude(address)
from data
- Lorsque vous créez de nouveaux jeux de données à partir de JSON, isolez les colonnes fréquemment consultées dans des colonnes dédiées au lieu de tout laisser dans une seule colonne
variant. L'expérience des utilisateurs finaux qui interrogeront vos tables s'en trouvera nettement améliorée. - Les attributs JSON sont sensibles à la casse. Si vous tapez
address.Cityau lieu deaddress:city, vous obtiendreznull.
Voilà qui clôt ce guide. Vous savez désormais parser un document JSON, l'aplatir et le stocker dans une table relationnelle Snowflake. Nous avons aussi exploré la démarche inverse : générer du JSON à partir d'une table Snowflake. Nos exemples portaient sur des structures simples, mais les principes s'appliquent à des documents JSON de toute taille et de toute complexité. Tout repose sur la combinaison judicieuse de ces fonctions, comme l'illustrent nos exemples. Pour des structures plus complexes, ces fonctions s'intégreront sans doute à des Common Table Expressions (CTE), mais le concept sous-jacent reste identique.
Bon code ! 🧑💻
Tomáš Sobotík·Senior Data Engineer & Snowflake SME chez Norlys
Tomas est un Snowflake Data SuperHero de longue date et un expert reconnu de Snowflake. Son parcours dans l'univers de la donnée s'étend sur plus d'une décennie, durant laquelle il a occupé les rôles de data engineer, d'architecte et d'administrateur Snowflake sur de nombreux projets, dans des secteurs et technologies variés. Membre actif de la communauté, il partage volontiers son expertise et inspire ses pairs. Il est également formateur O'Reilly et anime des sessions de formation en direct en ligne.
Ian Whitestone·Co-fondateur & CEO de SELECT
Ian est co-fondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à diriger des équipes full stack de data science et d'ingénierie chez Shopify et Capital One. Chez Shopify, il a piloté les chantiers d'optimisation du data warehouse et d'amélioration de l'observabilité des coûts.