前回のブログでは、半構造化データの基礎と、Snowflakeのサポート内容についてご紹介しました。あわせて、半構造化データをSnowflakeに取り込む方法もいくつか取り上げました。では、Snowflakeに取り込んだ後はどう進めればよいのでしょうか。本記事ではJSONデータの扱い方に絞り、Snowflakeが備える変換機能や専用関数を掘り下げていきます。まずはJSONデータをSnowflakeにロードする方法を簡単に振り返ってみましょう。
SnowflakeのJSON解析関数
Snowflakeには、半構造化JSONデータを扱うためのさまざまな関数が用意されています。よく使う代表的な3つは次のとおりです。
PARSE_JSON:文字列をJSONドキュメントとして受け取り、VARIANT値を返しますTRY_PARSE_JSON:PARSE_JSONとまったく同じ動作をしますが、解析時にエラーが発生した場合はnullを返しますLATERAL FLATTEN:配列を複数行に展開します(配列内のオブジェクト1つにつき1行)
それぞれの詳細はこの後で解説していきます。その前に、まずはサンプルデータを用意しましょう。
サンプルJSONデータの作成
本記事では、人物情報を含む以下のサンプルJSONデータを使って解説していきます。
1{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
このデータをsample_json_dataというテーブルにロードし、各機能の動作確認に使います。テーブルは、srcというVARIANT型の単一カラムにJSONドキュメントを保持する構成です。
create table sample_json_data
(src variant)
;
PARSE_JSONの使い方
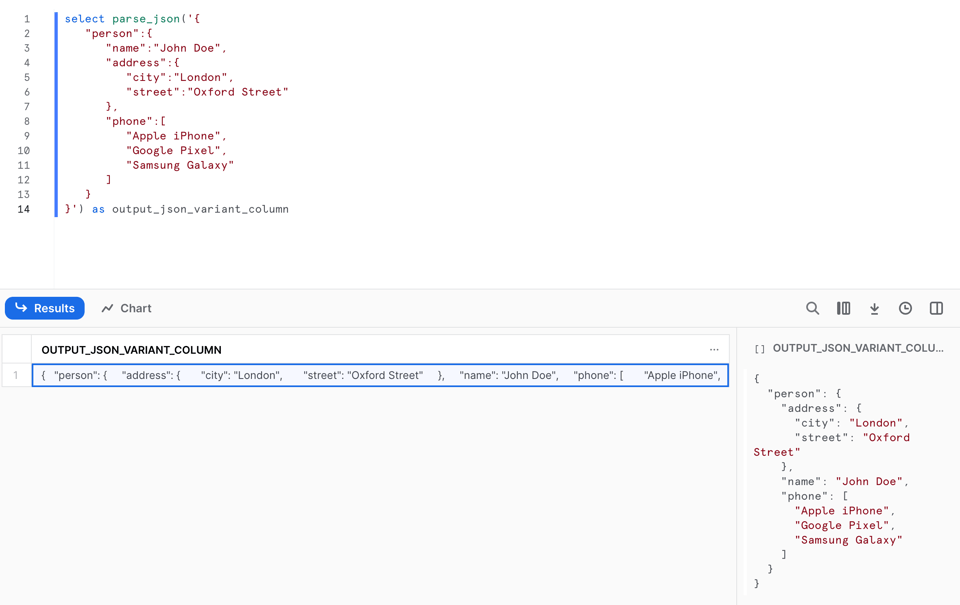
JSONドキュメントの文字列をVARIANTに変換するには、PARSE_JSON関数を使います。
1select parse_json('{
2 "person":{
3 "name":"John Doe",
4 "address":{
5 "city":"London",
6 "street":"Oxford Street"
7 },
8 "phone":[\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}') as output_json_variant_column
実行結果は次のとおりです。
この関数を使ってsample_json_dataにデータを投入できます。
1insert into sample_json_data
2select parse_json('{
3 "person":{
4 "name":"John Doe",
5 "address":{
6 "city":"London",
7 "street":"Oxford Street"
8 },
9 "phone":[\
\
10 "Apple iPhone",\
\
11 "Google Pixel",\
\
12 "Samsung Galaxy"\
\
13 ]
14 }
15}');
TRY_PARSE_JSONの使い方
TRY_PARSE_JSONはPARSE_JSONとまったく同じように動作します。
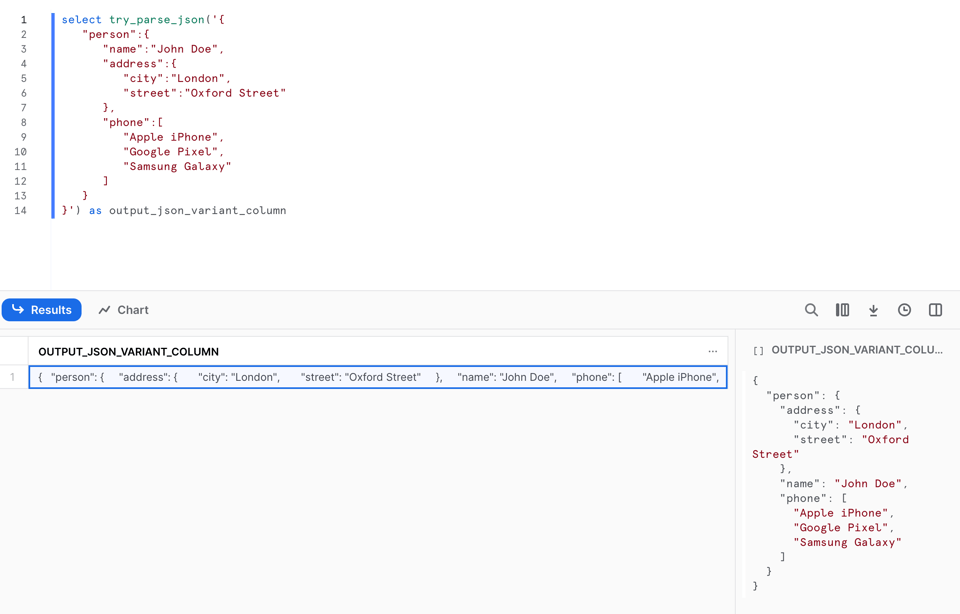
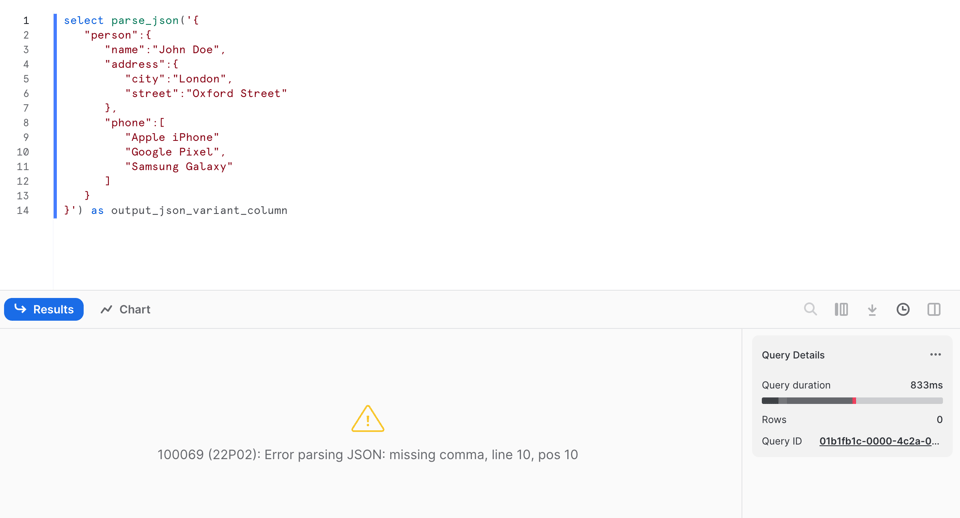
ただしPARSE_JSONとは異なり、JSONの解析に失敗した場合はnullを返します。9行目を見ると、カンマをわざと取り除いていることが分かります。
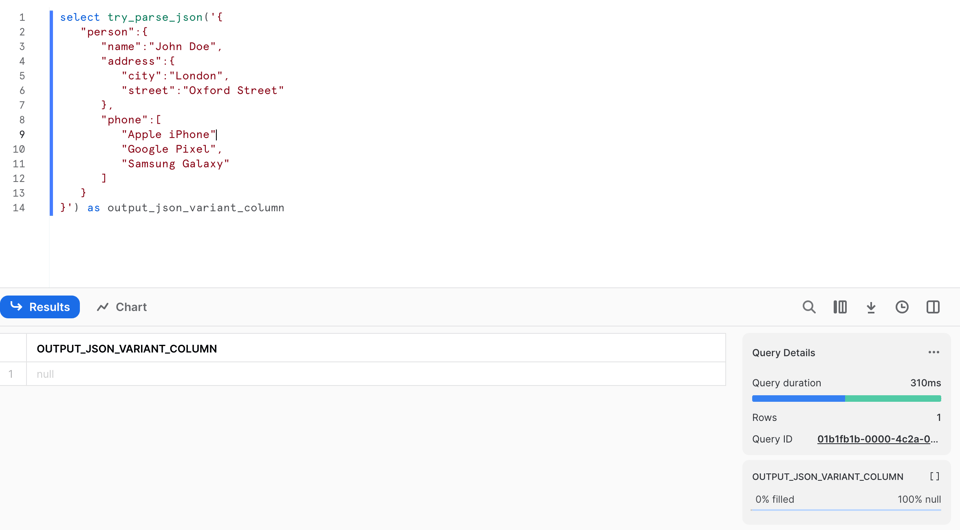
この不正なデータに対してPARSE_JSONを実行すると、エラーで失敗します。
JSONカラムをクエリする際の記法
それでは、半構造化データ型の中身にアクセスしていきましょう。最上位のキーからデータを取り出すには、src:personのようにコロン記法を使います。さらに深い階層に踏み込む場合は2通りの方法があり、src:person.address.cityのようなドット記法か、src['person']['address']['city']のようなブラケット記法を選べます。
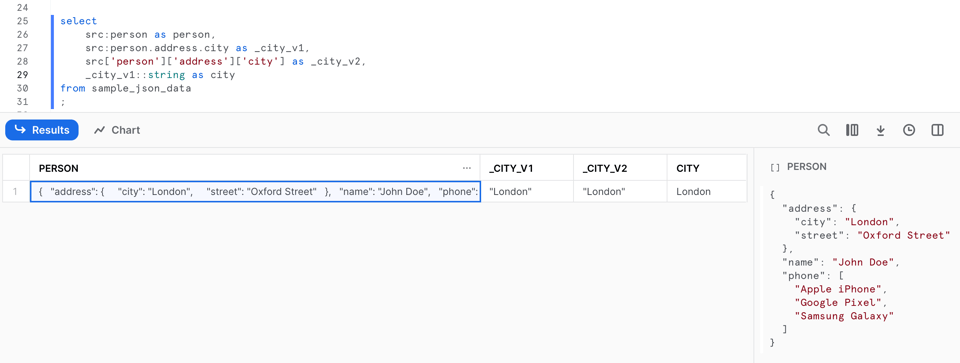
これらは次のような汎用形でまとめられます。
- ドット記法:
<column>:<level1_element>.<level2_element>.<level3_element> - ブラケット記法:
<column>['<level1_element>']['<level2_element>']['<level3_element>']
キーがSnowflake SQLの識別子ルールに準拠していない場合(たとえばキーにスペースが含まれる場合など)、ドット記法ではキー名をダブルクォートで囲む必要があります。ブラケット記法では、値を常にシングルクォートで囲んでください。
LATERAL FLATTENで配列を処理する方法
前のセクションでは、ドット記法とブラケット記法でJSONドキュメントをたどる基本を解説しました。では、ドキュメントに配列が含まれている場合はどうでしょうか。同じ要領でsrc:person:phoneを選択すると、配列全体が単一の値として返され、[ "Apple iPhone", "Google Pixel", "Samsung Galaxy" ]のような結果になります。
配列を1要素ずつ取り出して展開するには、配列をフラット化する必要があります。これにより、配列内の各値を1件ずつ含む3行が得られます。
Snowflakeはこの用途向けに、LATERALとFLATTENの2つの関数を提供しており、多くの場合これらを組み合わせて使用します。
LATERAL結合を使うと、インラインビューから先行するテーブル式のカラムを参照できます。非ラテラル結合とは異なり、ラテラル結合の出力にはインラインビューから生成された行だけが含まれます。なお筆者の経験では、LATERAL結合をFLATTEN関数なしで使ったことは一度もありません(技術的には可能です)。
FLATTEN関数は、複合値を複数行に展開します。半構造化データ型(VARIANT、OBJECT、ARRAY)を入力として受け取り、ラテラルビューを生成します。それでは、この2つの関数を使って携帯電話の配列を複数行に展開する例を見てみましょう。
SELECT
p.*
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p
このクエリの結果は次のとおりです。
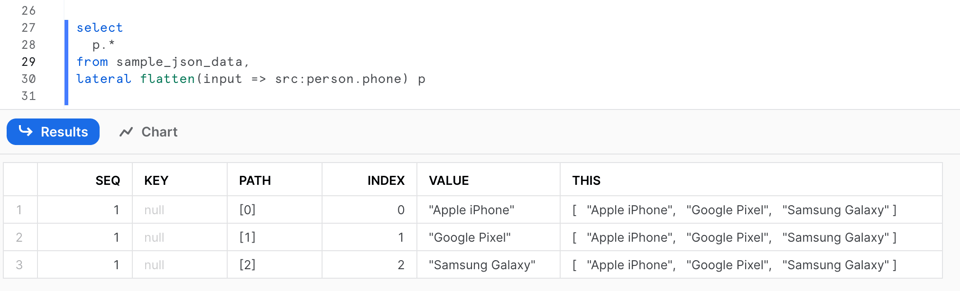
FLATTEN関数の出力には、次のような複数のカラムが含まれます。
SEQ:入力レコードに紐づく一意のシーケンス番号。順序が保証されない場合や、欠番が生じる場合があります。KEY:マップやオブジェクトの場合、展開された値のキーが入ります。PATH:フラット化対象のデータ構造内における、その要素までのパス。INDEX:要素が配列の一部である場合のインデックス。それ以外はNULLになります。VALUE:フラット化された配列またはオブジェクトの要素の値。THIS:フラット化対象となっている要素そのもの。再帰的なフラット化で役立ちます。
さらに、LATERAL結合の左側のカラムも引き続き参照できます。これを活かして、JSONドキュメントの半構造化データをフラットな構造に変換するようクエリを書き換えてみましょう。
SELECT
src:person.name::varchar AS person_name,
src:person.address.city::varchar AS city,
src:person.address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
実行結果は次のとおりです。

このSQLでは、出力がvariant形式(値がダブルクォートで囲まれた状態)で返されるため、カラムを明示的にキャストする必要があります。目的のデータ型に明示的に変換してください。
多階層のネストされた配列を扱う
配列の中にさらに配列が含まれるような多階層のネスト構造に出くわした場合は、レベル1で展開した値に対してさらにLATERAL FLATTENを適用することで、内側の配列も展開できます。この処理の擬似コードは次のようになります。
SELECT
lvl_1.value,
lvl_2.value
FROM table
LATERAL FLATTEN (input => src:topLevelArray) AS lvl_1,
LATERAL FLATTEN (input => lvl_1.value:innerLevelArray) AS lvl_2;
基本はこれだけです。ドット記法やブラケット記法とLATERAL FLATTENを組み合わせれば、SnowflakeテーブルにJSONデータを格納して扱うための強固な基礎ができあがります。このアプローチを使えば、必要な形式へ効率よくデータを変換できます。
リレーショナルデータからJSONドキュメントを構築する
ここまでJSONデータを処理する方法を見てきました。では逆に、構造化データをJSONに変換したい場合はどうすればよいのでしょうか。
SnowflakeテーブルのリレーショナルデータをJSON形式に変換することは、特にAPIペイロードとしてJSONを必要とする外部システムとデータを連携する際に欠かせません。Snowflakeのネイティブ関数を使った実現方法を見ていきましょう。
ここでは、LATERAL FLATTEN関数の出力から作成したrelational_dataというテーブルがあるとします。目標は、このリレーショナルデータを再びJSON構造に変換することです。まずrelational_dataテーブルを作成し、データを投入します。
CREATE TABLE relational_data (
person_name VARCHAR,
city VARCHAR,
street VARCHAR,
mobile_phone VARCHAR
);
INSERT INTO relational_data
SELECT
src:"person".name::varchar AS person_name,
src:"person".address.city::varchar AS city,
src:"person".address.street::varchar AS street,
p.value::varchar AS mobile_phone
FROM sample_json_data,
LATERAL FLATTEN(input => src:person.phone) p;
キーと値のペアを持つJSONオブジェクトを構築するには、OBJECT_CONSTRUCT関数を使います。この関数は引数をペアで受け取り、1つ目がキー、2つ目が値となります。入れ子のオブジェクトを作りたい場合は、もう一度OBJECT_CONSTRUCTを呼び出します。name属性のみを持つ基本的なperson構造を作るSQLは次のとおりです。
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name)) AS src
FROM relational_data;
このクエリは、次のようなJSON構造を生成します。
{
"person": {
"name": "John Doe"
}
}
続いて、cityとstreetを含むaddressオブジェクトを追加します。
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
)
)
) AS src
FROM relational_data;
最後に、携帯電話の配列を追加するため、入力値から配列を作るARRAY_AGG()関数を使います。最終的なJSON構造を生成する完全なSQLは次のとおりです。
SELECT OBJECT_CONSTRUCT('person',
OBJECT_CONSTRUCT('name', person_name,
'address', OBJECT_CONSTRUCT(
'city', city,
'street', street
),
'phone', ARRAY_AGG(mobile_phone) WITHIN GROUP (ORDER BY person_name) OVER (PARTITION BY person_name)
)
) AS src
FROM relational_data;
この手順により、元のJSONドキュメントを正しく再構成できます。
1{
2 "person": {
3 "address": {
4 "city": "London",
5 "street": "Oxford Street"
6 },
7 "name": "John Doe",
8 "phone": [\
\
9 "Apple iPhone",\
\
10 "Google Pixel",\
\
11 "Samsung Galaxy"\
\
12 ]
13 }
14}
以上の手順で、リレーショナルデータをそのままさまざまな用途に活用できる構造化されたJSONドキュメントへ変換できました。
JSONデータのロード方法
これまでの例ではサンプルJSONデータを使ってきましたが、実際のSnowflakeユーザーの多くは手元にこうしたデータがないため、まずは自分のアカウントにJSONデータをロードするところから始める必要があります。
JSONデータファイルをSnowflakeテーブルにロードするSQLコマンドは、たとえば次のようになります。
COPY INTO <table_name>
FROM (
SELECT
$1:person:name::STRING as name,
$1:person:address:city::STRING as city,
$1:person:address:street::STRING as street,
$1:person:phone[0]::STRING as phone1,
$1:person:phone[1]::STRING as phone2,
$1:person:phone[2]::STRING as phone3
FROM <my_stage>/<my_json_file.json>
);
このコマンドは、以下を前提としています。
<table_name>:Snowflake側のロード先テーブル名<my_stage>:JSONファイルが格納されているステージ名<my_json_file.json>:JSONファイル名
SELECT句では、次のように使い分けています。
$1は、ロード対象ファイルの最初のカラム(この例ではJSONブロブ全体)を参照するために使います。- コロン
:は、JSON構造をたどるために使います。 ::STRINGキャストは、JSON要素を適切なデータ型(この例ではSTRING)に変換します。データ型は要件に合わせて変更してください。
この例は、JSONファイル内のすべてのレコードでJSON構造が一貫していることを前提にしています。構造にばらつきがある場合は、追加のエラーハンドリングや解析ロジックが必要になることがあります。
Snowflakeのデータウェアハウスに半構造化データ(JSONデータを含む)をロードする方法の詳細については、前回のブログ記事をご参照ください。
JSONデータを扱う際のヒント
JSONデータを扱う際に押さえておきたい、その他の便利なヒントをいくつかご紹介します。
- こちらのような無料のオンラインJSONフォーマッターでデータを整形しましょう。構造を目で確認しやすくなり、データ階層の把握もスムーズになります。
- クエリは段階的に組み立て、各ステップごとに出力を検証しましょう。たとえば、4階層のネストJSONを一気にクエリしようとするのは禁物です。必ず発生するミスを早く見つけられるようになります。
- 一時的なカラムを使って処理をシンプルに保ちましょう。たとえばJSONの数階層分を一度に1つのカラムへ解析し、そのカラムを起点に処理を続ける、といった具合です。不要になったカラムは、後からSnowflakeのexcludeコマンドで除外できます。以下は、
addressフィールドの繰り返し処理を避ける例で、出力されるのはcityとstreetの2カラムだけです。
with
data as (
select
src:person.address as address,
address:city::string as city,
address:street::string as street
from sample_json_data
)
select * exclude(address)
from data
- JSONデータから新しいデータセットを作成する際は、よく参照されるカラムを
variantカラム1つにまとめてしまわず、別々のカラムに切り出しておきましょう。テーブルをクエリする側の使い勝手が大きく向上します。 - JSONの属性は大文字と小文字が区別されます。
address:cityのつもりでaddress.Cityと書いてしまうと、nullが返ってきます。
以上で本ガイドは終了です。これでJSONドキュメントを解析し、フラット化して、Snowflakeのリレーショナルテーブルに格納する方法をご理解いただけたはずです。さらに、その逆の流れ、つまりSnowflakeテーブルからJSONを生成する方法も取り上げました。本記事で扱ったのはシンプルなデータ構造でしたが、ここで紹介した原則はあらゆる複雑さ・規模のJSONドキュメントに応用できます。要は、シンプルな例で示したように、これらの関数をいかに上手に組み合わせるかに尽きます。より複雑な構造を扱うようになると、これらの関数が共通テーブル式(CTE)の一部として登場することもありますが、根底にある考え方は変わりません。
Happy coding! 🧑💻
Tomáš Sobotík·Senior Data Engineer & Snowflake SME at Norlys
Tomasは長年にわたって活躍するSnowflake Data SuperHeroであり、Snowflake全般のエキスパートとして知られています。データ業界での経験は10年を超え、さまざまな業界・技術領域のプロジェクトでSnowflakeのデータエンジニア、アーキテクト、管理者を務めてきました。コミュニティの中心メンバーとしても積極的に知見を共有し、多くの人々を刺激し続けています。また、O'Reillyのインストラクターとして、ライブのオンライントレーニングも担当しています。
Ian Whitestone·Co-founder & CEO of SELECT
Ianは、SaaS型のSnowflakeコスト管理・最適化プラットフォームであるSELECTの共同創業者兼CEOです。SELECTを立ち上げる前は、ShopifyとCapital Oneで6年間にわたりフルスタックのデータサイエンス&エンジニアリングチームを率いていました。Shopify時代には、データウェアハウスの最適化とコスト可視性の向上を主導しました。