Snowflake verdankt seine enorme Popularität der Fähigkeit, große Datenmengen mit minimaler Konfiguration und extrem geringer Latenz zu verarbeiten. Entsprechend ist Snowflake bei Datenteams in tausenden Unternehmen gesetzt. In diesem Leitfaden zeigen wir Optimierungstechniken, mit denen Sie Performance und Effizienz von Snowflake voll ausschöpfen. Mit diesen Best Practices laufen Ihre Queries schneller – und Sie senken gleichzeitig die Kosten.
Alle in diesem Beitrag vorgestellten Techniken zum Performance Tuning in Snowflake basieren auf realen Strategien, die SELECT bei über 100 Snowflake-Kunden umgesetzt hat. Falls Ihnen etwas fehlt, freuen wir uns über Ihr Feedback! Schreiben Sie uns per E-Mail oder nutzen Sie das Chat-Symbol unten am Bildschirmrand.
Dieser Beitrag widmet sich Techniken zur Query-Optimierung und zeigt, wie Sie damit Ihre Snowflake-Queries beschleunigen. Das kann zwar auch die Kosten senken – ist Kostensenkung aber Ihr Hauptziel, gibt es bessere Ausgangspunkte. Werfen Sie in diesem Fall einen Blick auf unseren Beitrag zur Snowflake-Kostenoptimierung mit konkreten Strategien zur Kostensenkung.
Techniken zur Snowflake Query Optimization
Die in diesem Beitrag vorgestellten Techniken zur Optimierung der Snowflake-Query-Performance lassen sich grob in drei Kategorien einteilen:
1. Effizienz beim Lesen der Daten verbessern
Queries verbringen mitunter viel Zeit damit, Daten aus dem Tabellenspeicher zu lesen. Dieser Schritt erscheint im Query Profile als TableScan. Beim TableScan werden Daten über das Netzwerk vom Speicherort der Tabelle in die Worker-Nodes des Virtual Warehouses geladen. Beschleunigen lässt sich das, indem Sie das geladene Datenvolumen reduzieren oder das Virtual Warehouse vergrößern.
Snowflake liest ausschließlich die in einer Query ausgewählten Spalten sowie die für die Filter relevanten Micro-Partitions – vorausgesetzt, die Micro-Partitions der Tabelle sind passend zur Filterbedingung gut geclustert.
Mit diesen vier Techniken reduzieren Sie das geladene Datenvolumen und beschleunigen so TableScans:
- Anzahl der gelesenen Spalten verringern
- Query Pruning & Tabellen-Clustering nutzen
- Geclusterte Spalten in Join-Prädikaten verwenden
- Voraggregierte Tabellen einsetzen
2. Effizienz der Datenverarbeitung verbessern
Operationen wie Joins, Sortierungen und Aggregationen laufen nach den TableScans und entwickeln sich häufig zum Flaschenhals. Zu den Strategien zur Optimierung gehören: weniger Verarbeitungsschritte, inkrementelle Verarbeitung und der gezielte Einsatz Ihres Wissens über die Daten.
Techniken zur Verbesserung der Verarbeitungseffizienz:
- Anzahl der Query-Operationen vereinfachen und reduzieren
- Verarbeitetes Datenvolumen durch frühzeitiges Filtern verringern
- Wiederholte Referenzen auf CTEs vermeiden
- Unnötige Sortierungen entfernen
- Window Functions statt Self-Joins bevorzugen
- Joins mit OR-Bedingung vermeiden
- Ihr Wissen über die Daten nutzen, damit Snowflake effizient verarbeiten kann
- Abfragen auf komplexe Views vermeiden
- Query-Caches effektiv einsetzen
3. Warehouse-Konfiguration optimieren
Snowflakes Virtual Warehouses lassen sich problemlos so konfigurieren, dass sie größere workloads mit höherer Parallelität bewältigen. Zentrale Stellschrauben für mehr Performance:
- Warehouse-Größe erhöhen
- Cluster-Anzahl des Warehouses erhöhen
- Scaling Policy des Warehouses anpassen
Bevor wir in die Optimierungen einsteigen, schauen wir uns zunächst an, wie Sie identifizieren, was eine Query ausbremst.
So optimieren Sie eine Snowflake-Query
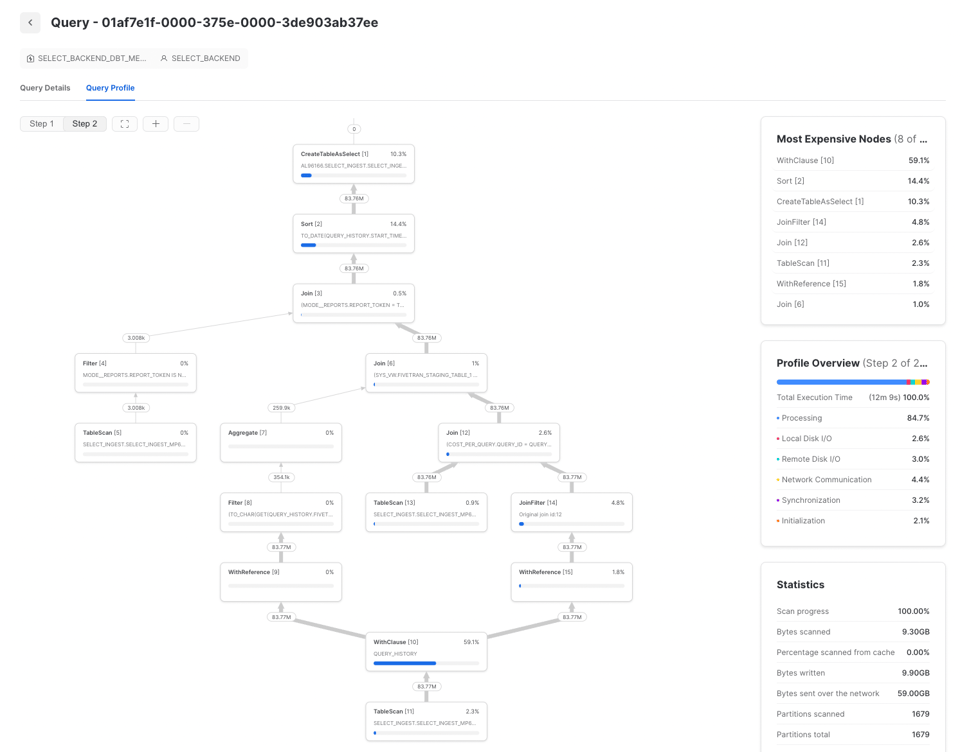
Bevor Sie eine Snowflake-Query optimieren können, müssen Sie den tatsächlichen Flaschenhals kennen – und genau dafür ist Query Profiling da. Welche Operationen bremsen, und worauf sollten Sie sich konzentrieren?
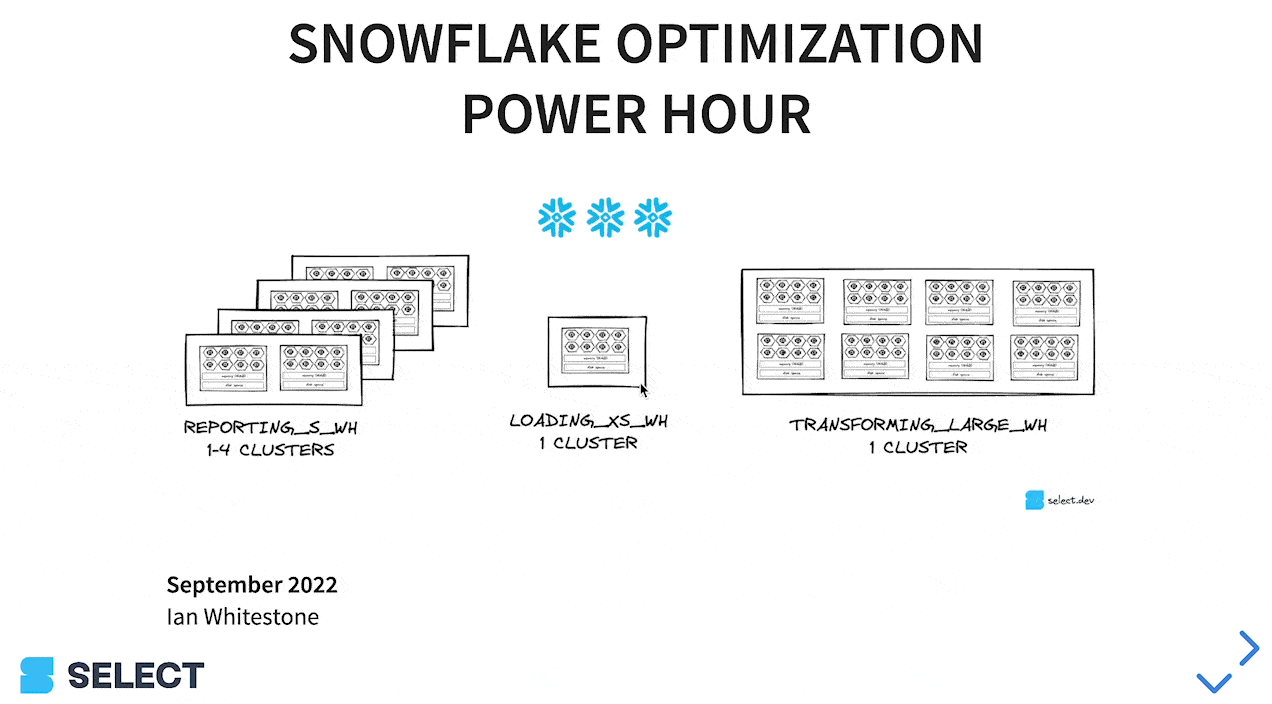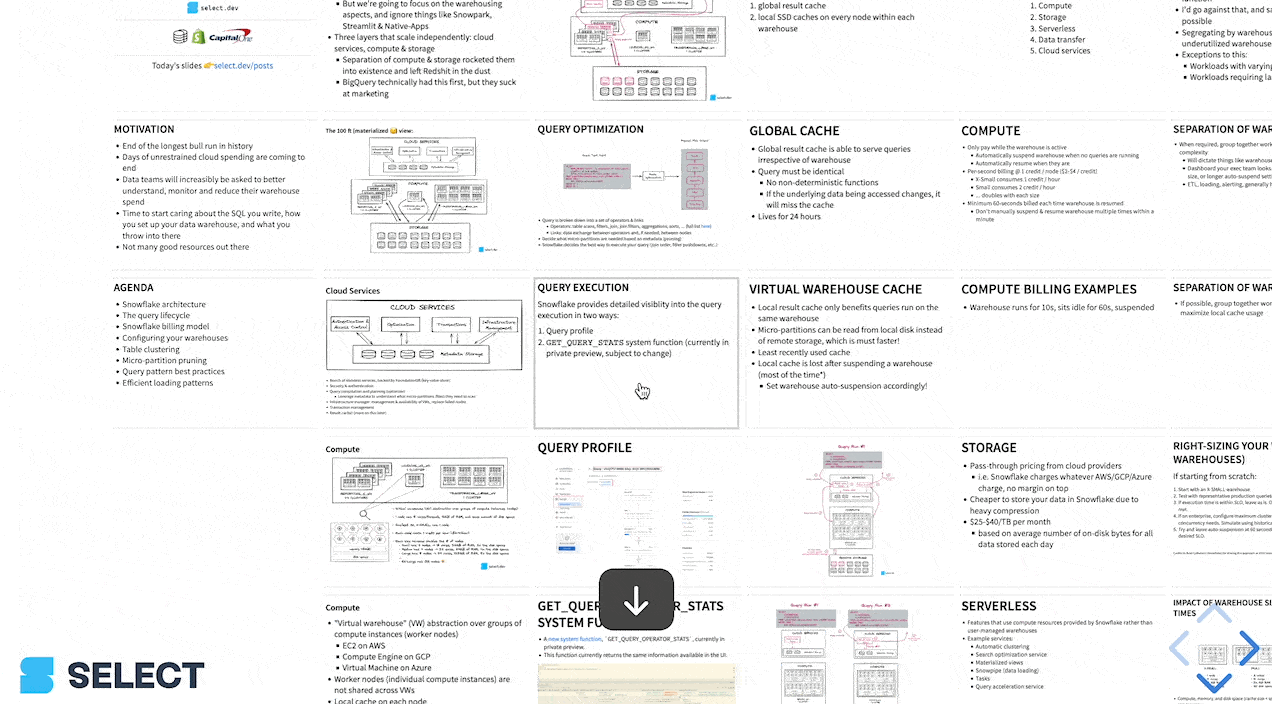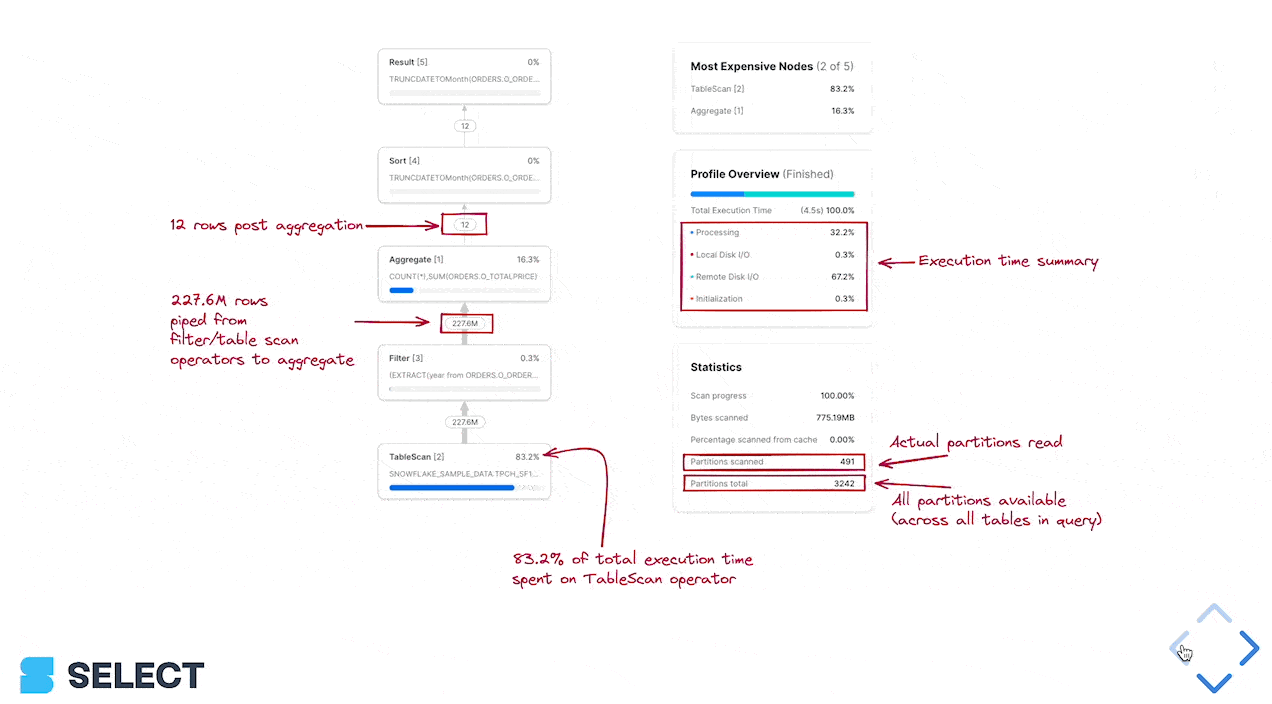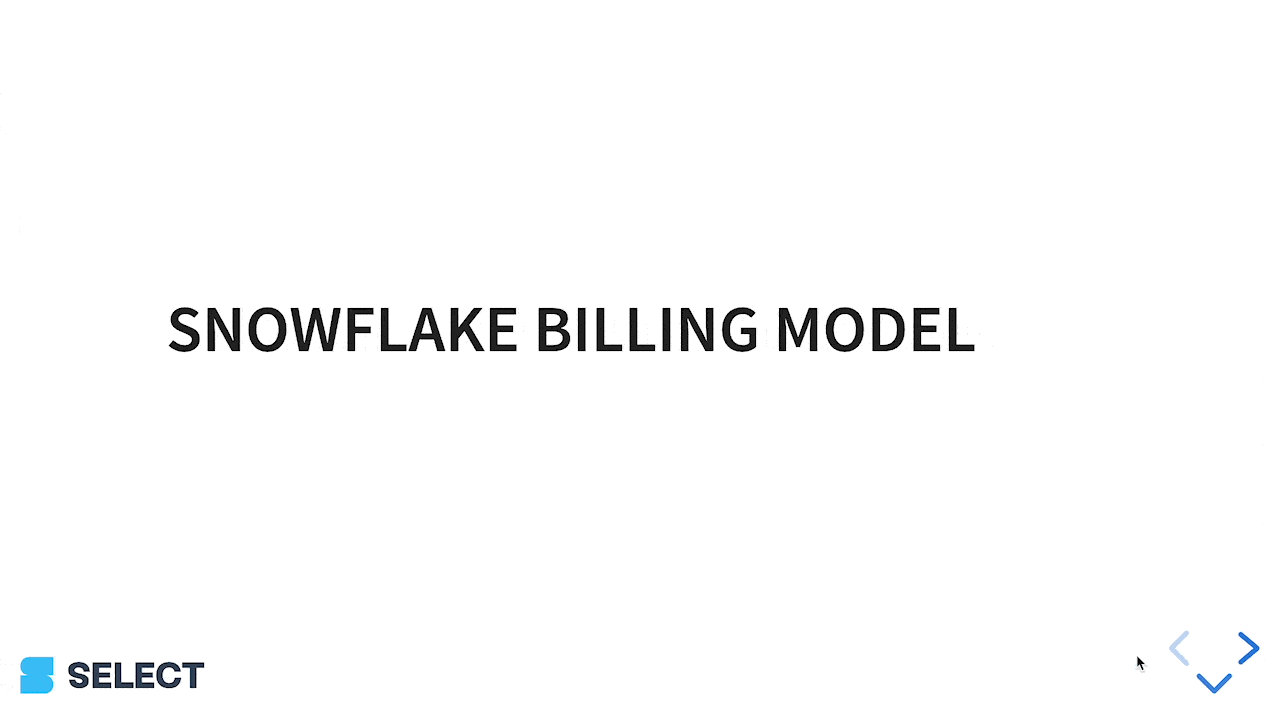
Werfen Sie dazu einen Blick auf das Snowflake Query Profile (Query Plan) und insbesondere auf den Abschnitt "Most Expensive Nodes". Dort sehen Sie, welche Teile der Query die meiste Ausführungszeit beanspruchen.
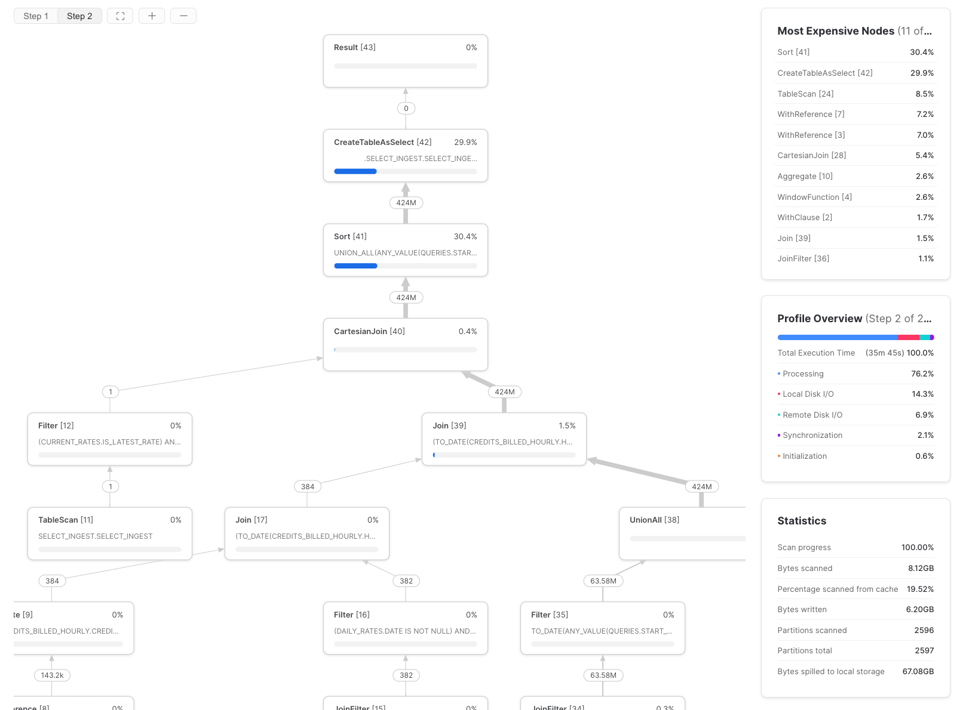
In diesem Beispiel ist der Sort-Schritt der Flaschenhals – ein klares Signal, sich auf die Effizienz der Datenverarbeitung zu konzentrieren und gegebenenfalls die Warehouse-Größe zu erhöhen. Sind die teuersten Knoten einer Query TableScans, lohnt sich der Aufwand am ehesten bei der Lese-Effizienz.
1\. Weniger Spalten auswählen
Eine simple Maßnahme – aber wo sie möglich ist, macht sie einen großen Unterschied. Anforderungen an Queries verändern sich im Lauf der Zeit, und Spalten, die einst nützlich waren, werden später vielleicht gar nicht mehr benötigt. Snowflake speichert Daten in einem hybriden, spaltenorientierten Dateiformat namens Micro-Partitions. Dieses Format erlaubt es Snowflake, die Menge der aus dem Storage zu lesenden Daten zu reduzieren. Das Herunterladen der Micro-Partition-Daten nennt man Scanning – und je weniger Spalten, desto weniger Datentransfer über das Netzwerk.
2\. Query Pruning nutzen
Damit Snowflake die Anzahl der gescannten Micro-Partitions reduzieren kann (Query Pruning), müssen ein paar Voraussetzungen erfüllt sein:
- Ihre Query muss einen Filter enthalten, der die benötigten Daten einschränkt. Das kann ein expliziter
where-Filter oder ein impliziterjoin-Filter sein. - Ihre Tabelle muss auf der Filterspalte gut geclustert sein.
Die folgende Query auf die hypothetische orders-Tabelle aus dem Diagramm führt zu Query Pruning, weil (a) die orders-Tabelle nach created_at geclustert ist (die Daten sind nach created_at sortiert) und (b) die where-Klausel created_at explizit auf ein bestimmtes Datum filtert.
select *
from orders
where created_at > '2022/08/14'

Ob sich die Pruning-Performance verbessern lässt, sehen Sie an den Werten Partitions scanned und Partitions total im Query Profile.
Wenn Ihre Query bislang ohne where-Filter auskommt, kann das Hinzufügen einen TableScan deutlich beschleunigen (und auch nachgelagerte Knoten, da sie weniger Daten verarbeiten). Hat Ihre Query bereits einen where-Filter, aber "Partitions scanned" liegt nahe bei "Partitions total", dann greift die where-Klausel nicht effektiv für das Pruning.
So verbessern Sie das Pruning:
- Platzieren Sie where-Klauseln so früh wie möglich in der Query, sonst werden sie nicht in den TableScan-Schritt "heruntergeschoben" (das beschleunigt auch spätere Schritte).
- Nehmen Sie gut geclusterte Spalten in Join- und Merge-Bedingungen auf, die als JoinFilter heruntergeschoben werden und so Pruning ermöglichen.
- Achten Sie darauf, dass die in where-Filtern genutzten Spalten zum Clustering der Tabelle passen (mehr zum Clustering hier).
- Vermeiden Sie Funktionen in where-Bedingungen – sie verhindern oft, dass Snowflake Micro-Partitions prunen kann.
3\. Geclusterte Spalten in Join-Prädikaten verwenden
Die gängigste Form, die die meisten Nutzer kennen, ist statisches Query Pruning. Hier ein einfaches Beispiel, ähnlich dem obigen:
select *
from orders
where order_date > current_date - 7
Ist die orders-Tabelle nach order_date geclustert, erkennt der Snowflake-Query-Optimizer, dass die meisten Micro-Partitions (Dateien) mit Daten älter als sieben Tage ignoriert werden können. Da das Scannen von Remote-Daten viel Verarbeitungszeit erfordert, beschleunigt das Eliminieren von Micro-Partitions die Query erheblich.
Ein weniger bekanntes Feature der Snowflake-Query-Engine ist dynamisches Pruning. Während statisches Pruning vor der Ausführung in der Planungsphase greift, erfolgt dynamisches Query Pruning erst während der Ausführung.
Stellen Sie sich einen Prozess vor, der bestehende Datensätze in der orders-Tabelle regelmäßig über einen MERGE-Befehl aktualisiert. Im Hintergrund erfordert ein MERGE einen Join zwischen der Quelltabelle mit den neuen bzw. aktualisierten Datensätzen und der Zieltabelle (orders), die wir aktualisieren wollen.
Dynamisches Pruning greift während des Joins. Wie? Während die Snowflake-Query-Engine die Daten aus der Quelltabelle liest, erkennt sie den Wertebereich der vorhandenen Datensätze und schiebt automatisch eine Filteroperation auf die Zieltabelle herunter, um unnötiges Scannen zu vermeiden.
Ein konkretes Beispiel: Angenommen, wir haben eine Quelltabelle mit drei Datensätzen, die wir in der nach Bestelldatum geclusterten Ziel-orders-Tabelle aktualisieren wollen. Ein typischer MERGE würde Datensätze über einen eindeutigen Schlüssel wie order key abgleichen. Da diese Schlüssel meist zufällig vergeben sind, erzwingen sie kein Pruning. Ändern wir die MERGE-Bedingung jedoch so, dass sowohl auf order key als auch auf order date abgeglichen wird, kann dynamisches Pruning greifen. Während Snowflake die Daten aus der Quelltabelle liest, erkennt es den Datumsbereich der drei zu aktualisierenden Bestellungen. Diesen Bereich schiebt es als Filter auf die Zielseite herunter, sodass nicht die gesamte große Tabelle gescannt werden muss.

Wie wenden Sie das im Alltag an? Wenn Sie aktuell MERGE- oder JOIN-Operationen haben, bei denen viel Zeit in das Scannen der Zieltabelle (rechts) fließt, prüfen Sie, ob sich zusätzliche Prädikate in die Join-Klausel aufnehmen lassen, die Query Pruning erzwingen. Hinweis: Das funktioniert nur, wenn (a) Ihre Zieltabelle nach einem Schlüssel geclustert ist und (b) die Quelltabelle (links), die Sie joinen, einen eng begrenzten Wertebereich auf dem Cluster-Schlüssel enthält (also z. B. eine Teilmenge der Bestelldaten).
Beim Einsatz einer incremental Materialization Strategy in dbt wird im Hintergrund eine MERGE-Query ausgeführt. Um eine zusätzliche Join-Bedingung für dynamisches Pruning hinzuzufügen, erweitern Sie das unique_key-Array um die zusätzliche Spalte (z. B. updated_at).
{{ config(
materialized='incremental',
unique_key=['order_id', 'updated_at'],
) }}
select *
from {{ ref('stg_orders') }}
...
4\. Voraggregierte Tabellen nutzen
Legen Sie "Rollup"- oder "Derived"-Tabellen mit weniger Zeilen an. Voraggregierte Tabellen lassen sich häufig so gestalten, dass sie die für die meisten Queries benötigten Informationen liefern und dabei weniger Speicherplatz verbrauchen. Das macht sie deutlich schneller abfragbar. Im Handel ist eine gängige Strategie, eine tägliche Orders-Rollup-Tabelle für Finanz- und Bestandsreporting zu nutzen und die rohe orders-Tabelle nur dann anzufassen, wenn die Granularität pro Bestellung gefragt ist.
5\. Vereinfachen!
Jede Operation in einer Query kostet Zeit, weil Daten zwischen Worker-Threads bewegt werden müssen. Konsolidieren und entfernen Sie unnötige Operationen, um den Netzwerktransfer zu reduzieren. Das hilft Snowflake außerdem, Berechnungen wiederzuverwenden und Aufwand zu sparen. Meistens beeinflussen CTEs und Subqueries die Performance nicht – setzen Sie sie also gezielt für bessere Lesbarkeit ein.
Generell gilt: Je weniger jede einzelne Query tun muss, desto leichter ist das Debugging. Zusätzlich sinkt die Wahrscheinlichkeit, dass der Snowflake-Query-Optimizer Fehlentscheidungen trifft (etwa eine ungünstige Join-Reihenfolge wählt).
6\. Verarbeitetes Datenvolumen reduzieren
Je weniger Daten, desto schneller läuft jeder Verarbeitungsschritt durch. Wenn Sie sowohl die Anzahl der Spalten als auch die der Zeilen pro Schritt reduzieren, verbessert das die Performance.
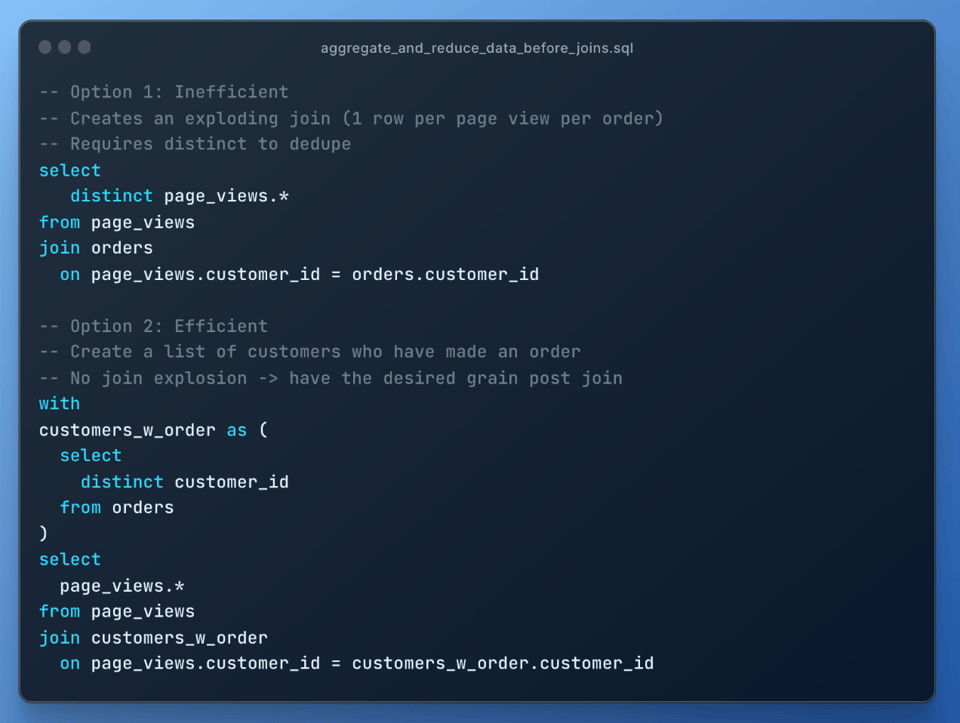
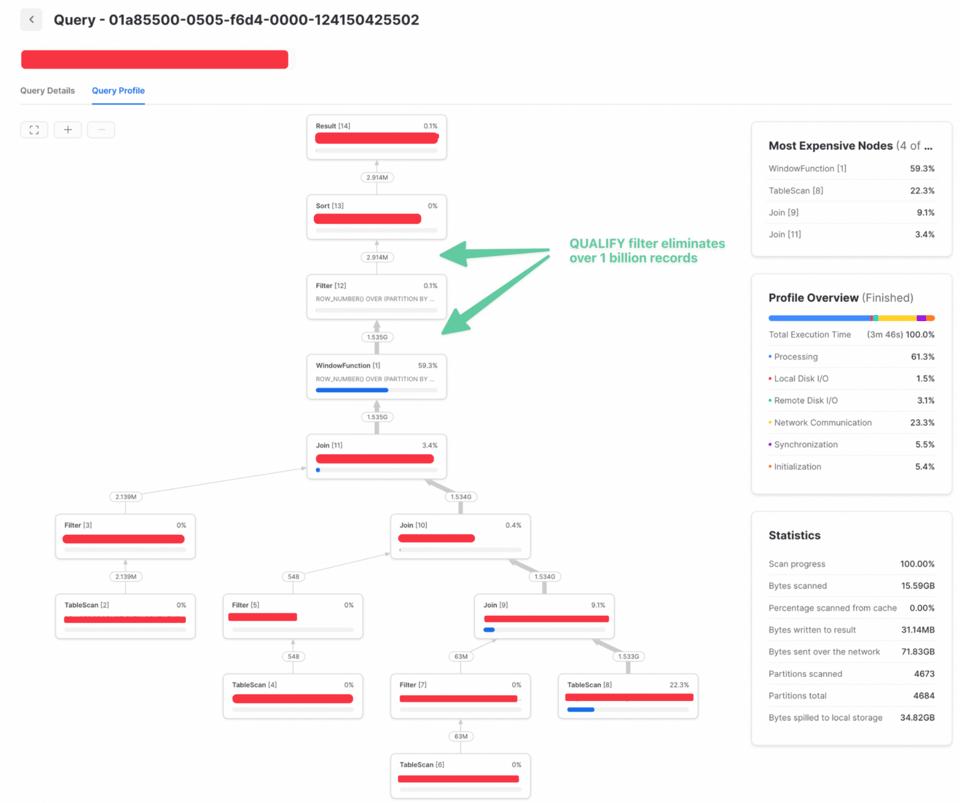
Hier ein Beispiel, in dem das Vorziehen eines Qualify-Filters die Query-Laufzeit verdreifacht hat. Das erste Query Profile zeigt die Laufzeit, als der QUALIFY-Filter nach einem Join lief.
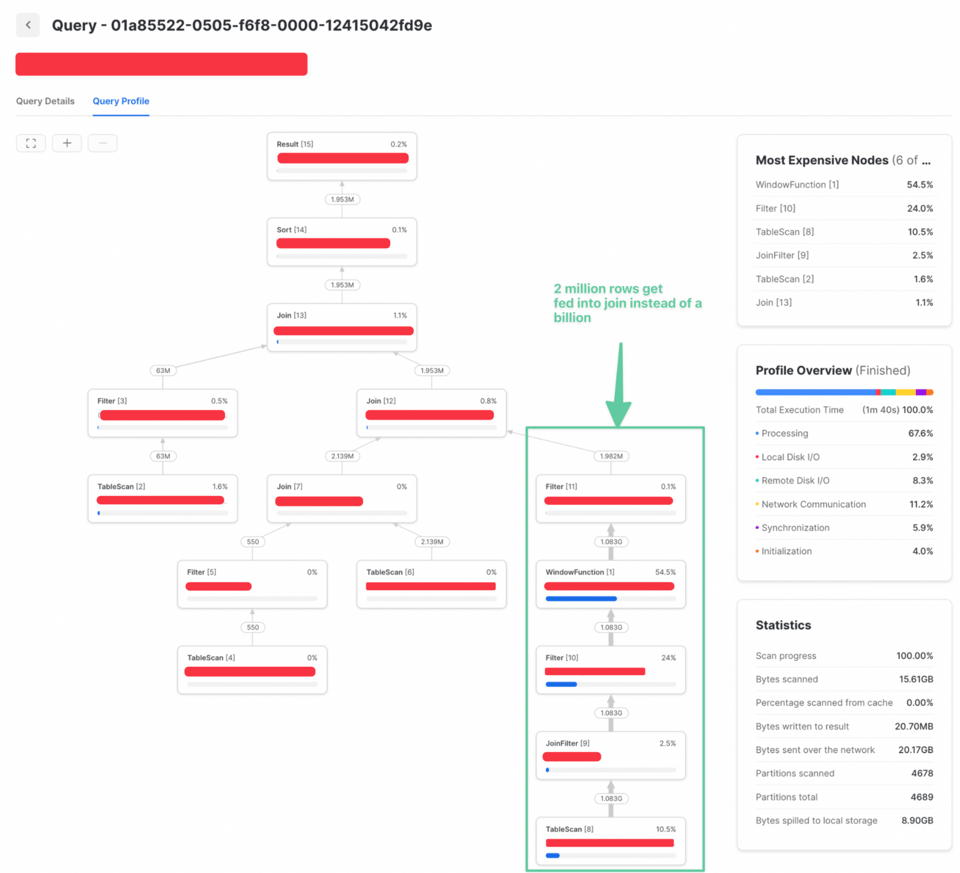
Da der QUALIFY-Filter keine Informationen aus dem Join benötigte, ließ er sich nach vorn ziehen. So werden deutlich weniger Daten gejoint und die Performance steigt erheblich:
Bei Transformationsqueries, die in eine andere Tabelle schreiben, ist Inkrementalisierung ein besonders wirksamer Hebel. Im Beispiel der orders-Tabelle könnten wir die Query so konfigurieren, dass sie nur neue oder geänderte Bestellungen verarbeitet und die Ergebnisse per Merge in die bestehende Tabelle einspielt.
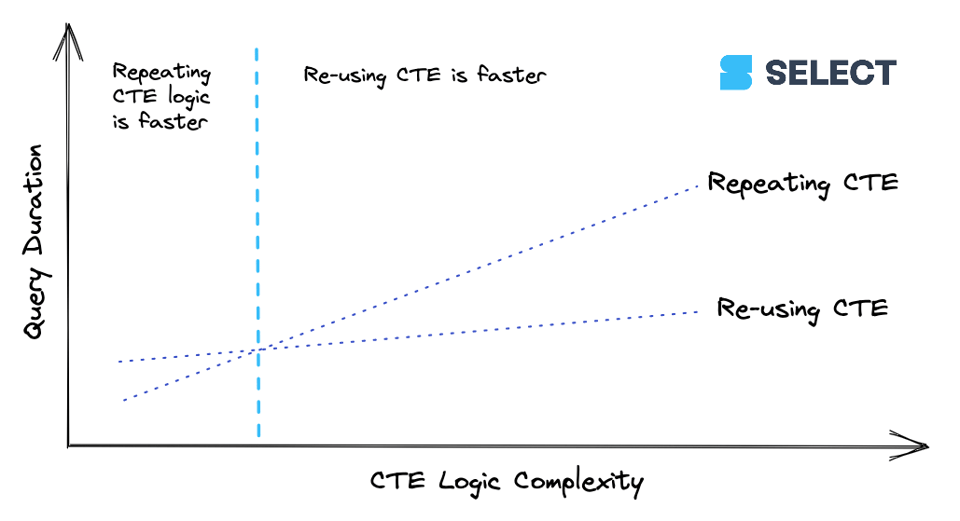
7\. Wiederholte CTEs können manchmal schneller sein
Wir haben bereits darüber geschrieben, ob Sie CTEs in Snowflake einsetzen sollten. Sobald Sie einen CTE in Ihrer Query mehr als einmal referenzieren, sehen Sie eine WithClause-Operation im Query Profile (siehe Beispiel unten). In bestimmten Szenarien kann das die Query sogar langsamer machen – effizienter kann es dann sein, den CTE bei jeder Verwendung neu zu schreiben.
Ab einem gewissen Komplexitätsgrad eines CTEs ist es günstiger, ihn einmal zu berechnen und das Ergebnis an die nachgelagerten Referenzen weiterzureichen, als ihn mehrfach neu zu berechnen. Dieses Verhalten ist allerdings nicht konsistent – Ausprobieren lohnt sich. So lässt sich der Zusammenhang visualisieren:
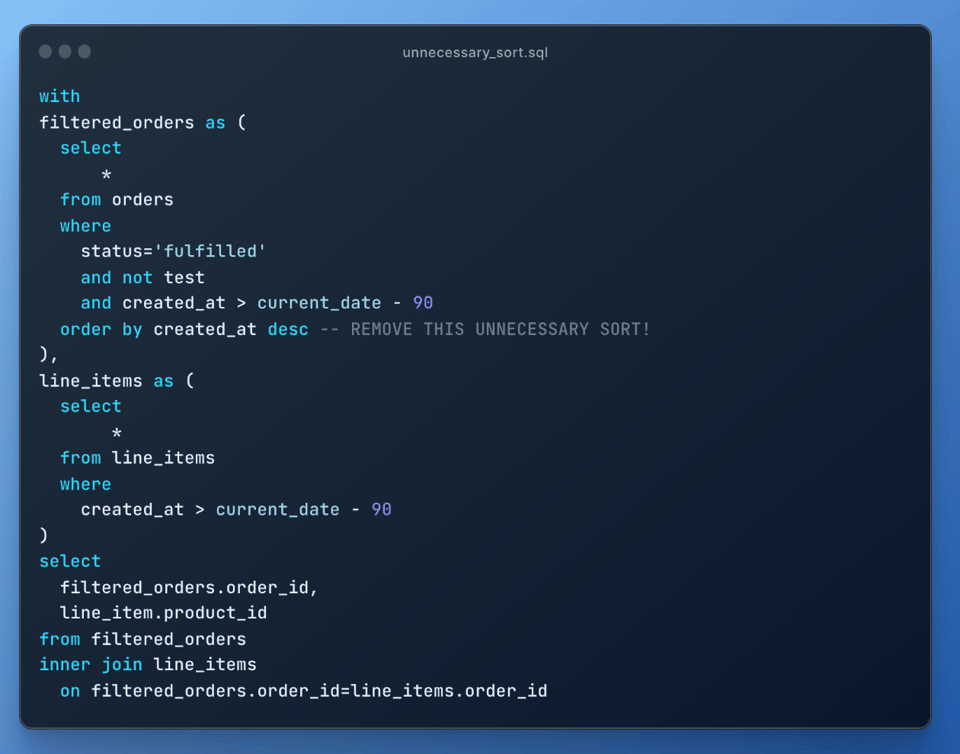
8\. Unnötige Sortierungen entfernen
Sortieren ist eine teure Operation – entfernen Sie also alle Sortierungen, die nicht zwingend nötig sind:
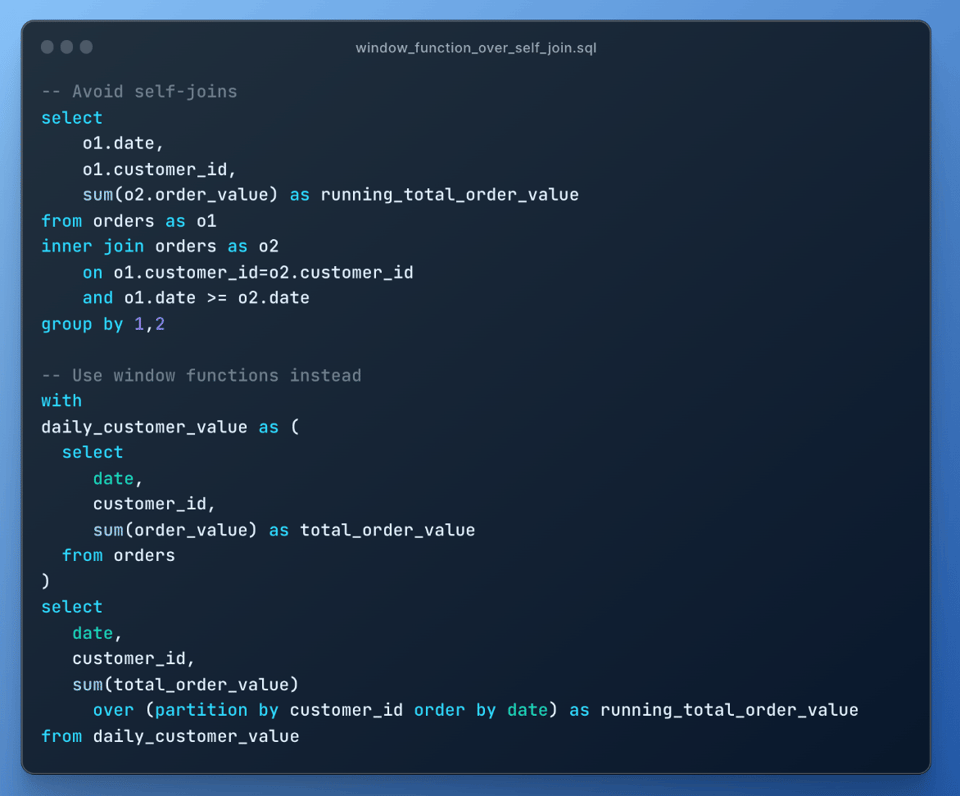
9\. Window Functions statt Self-Joins
Setzen Sie statt eines Self-Joins wo immer möglich Window Functions ein. Self-Joins sind sehr teuer, weil sie zu einer Join-Explosion führen:
10\. Joins mit OR-Bedingung vermeiden
Ähnlich wie Self-Joins führen Joins mit einer OR-Bedingung zu einer Join-Explosion, da sie als kartesischer Join mit nachgelagertem Filter ausgeführt werden. Verwenden Sie stattdessen zwei Left Joins:
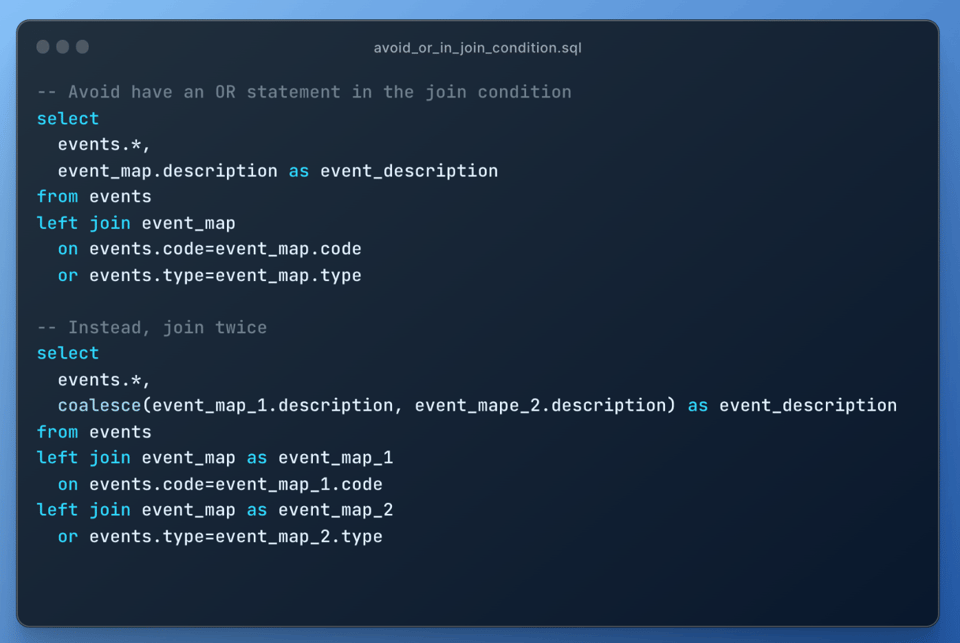
11\. Ihr Wissen über die Daten nutzen, damit Snowflake effizient arbeitet
Ihr eigenes Wissen über die Daten kann die Query-Performance verbessern. Wenn eine Query etwa nach vielen Spalten gruppiert und Sie wissen, dass einige davon redundant sind, weil andere bereits dieselbe oder eine höhere Granularität abbilden, kann es schneller sein, diese Spalten aus dem Group By zu entfernen und sie in einem separaten Schritt wieder hinzuzujoinen.
Ist eine gruppierte oder gejointe Spalte stark verzerrt (also: wenige distinkte Werte treten besonders häufig auf), kann das die Geschwindigkeit von Snowflake spürbar beeinträchtigen. Ein klassisches Beispiel ist die Gruppierung nach einer Spalte mit vielen Null-Werten. Diese Zeilen herauszufiltern und in einer eigenen Operation zu verarbeiten, kann die Query deutlich beschleunigen.
Auch Range-Joins können in allen Data Warehouses – Snowflake eingeschlossen – langsam sein. Mit Ihrem Wissen über die Intervalllängen in den Daten lässt sich die entstehende Join-Explosion reduzieren. Schauen Sie sich unseren aktuellen Beitrag dazu an, falls Sie langsame Range-Join-Performance beobachten.
12\. Komplexe Views vermeiden
Als Best Practice gilt: Vermeiden Sie es, in Ihren Queries komplexe Views anzulegen oder zu verwenden. Views eignen sich für einfache Datentransformationen wie das Umbenennen von Spalten, simple Spaltenberechnungen oder Datenmodelle mit leichten Joins.
Wie komplexe Views Chaos anrichten können, zeigt diese harmlos aussehende Query:
select
a.*,
b.*
from model_a as a
left join model_b as b
on a.id=b.id
Diese Query lief wiederholt > 45 Minuten und scheiterte schließlich mit einem "Incident".
Ein Blick ins Query Profile (auch "Query Plan" genannt) zeigte: Die abgefragten Modelle waren in Wahrheit komplexe Views mit hunderten Tabellen.
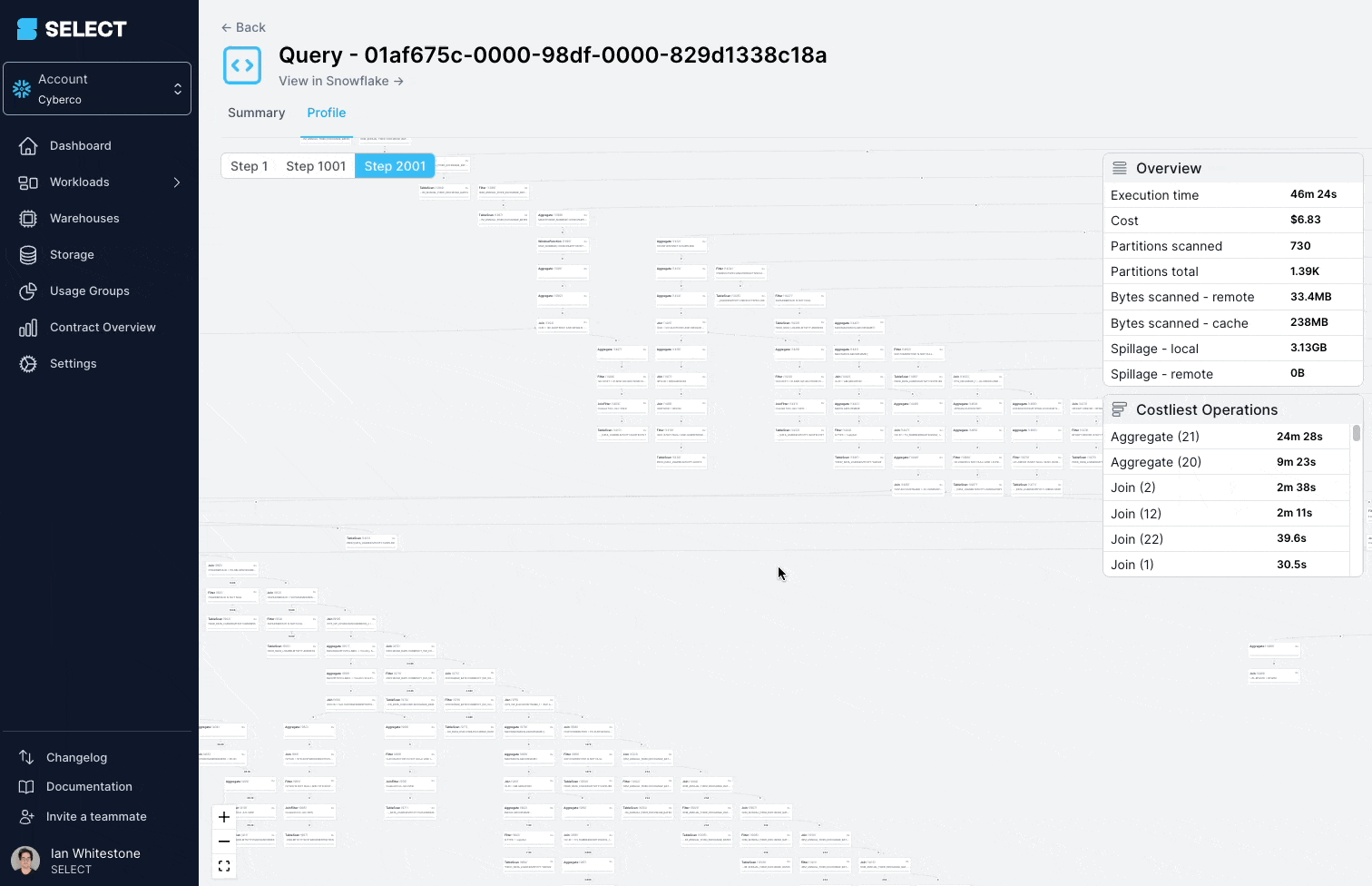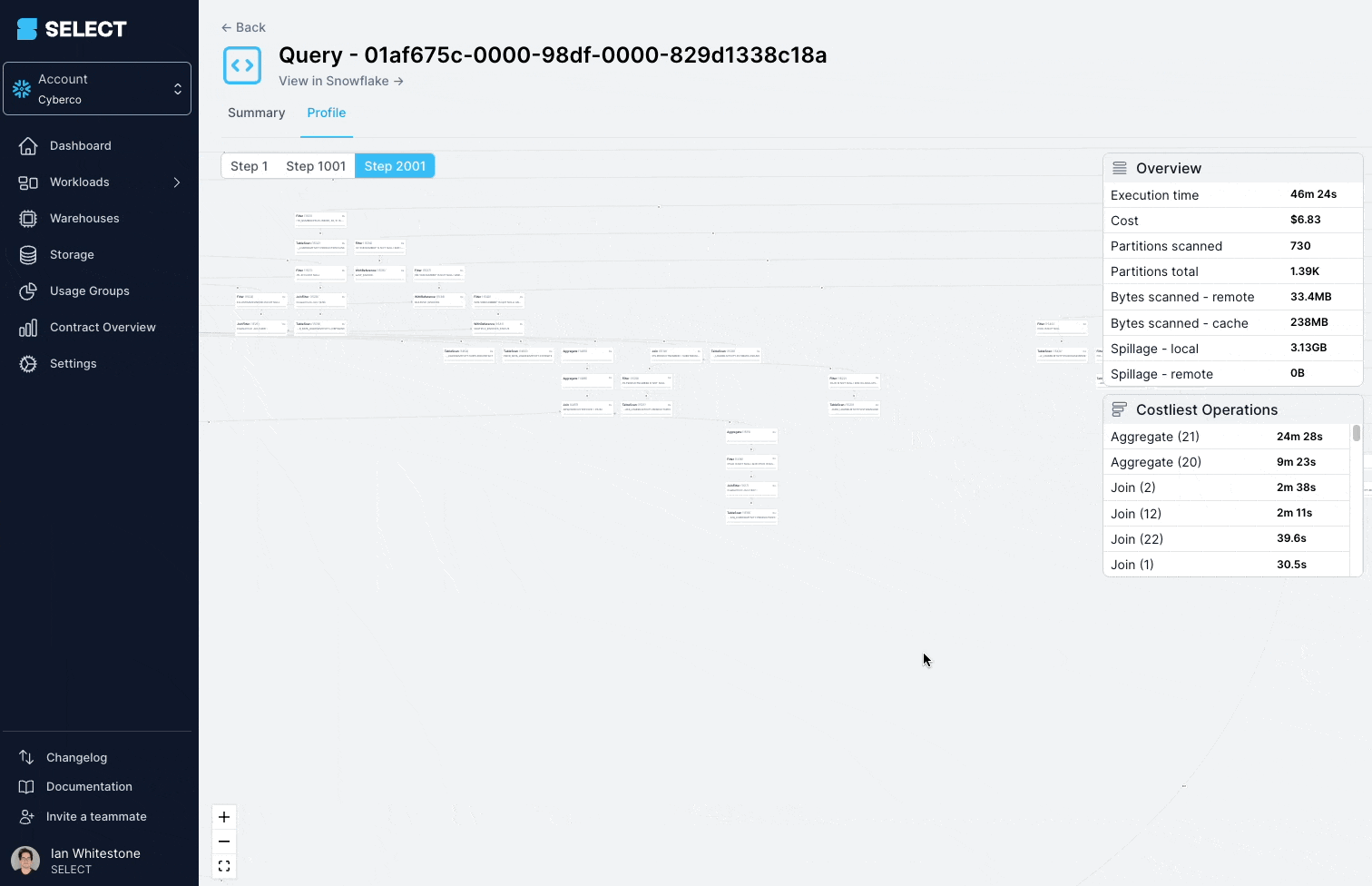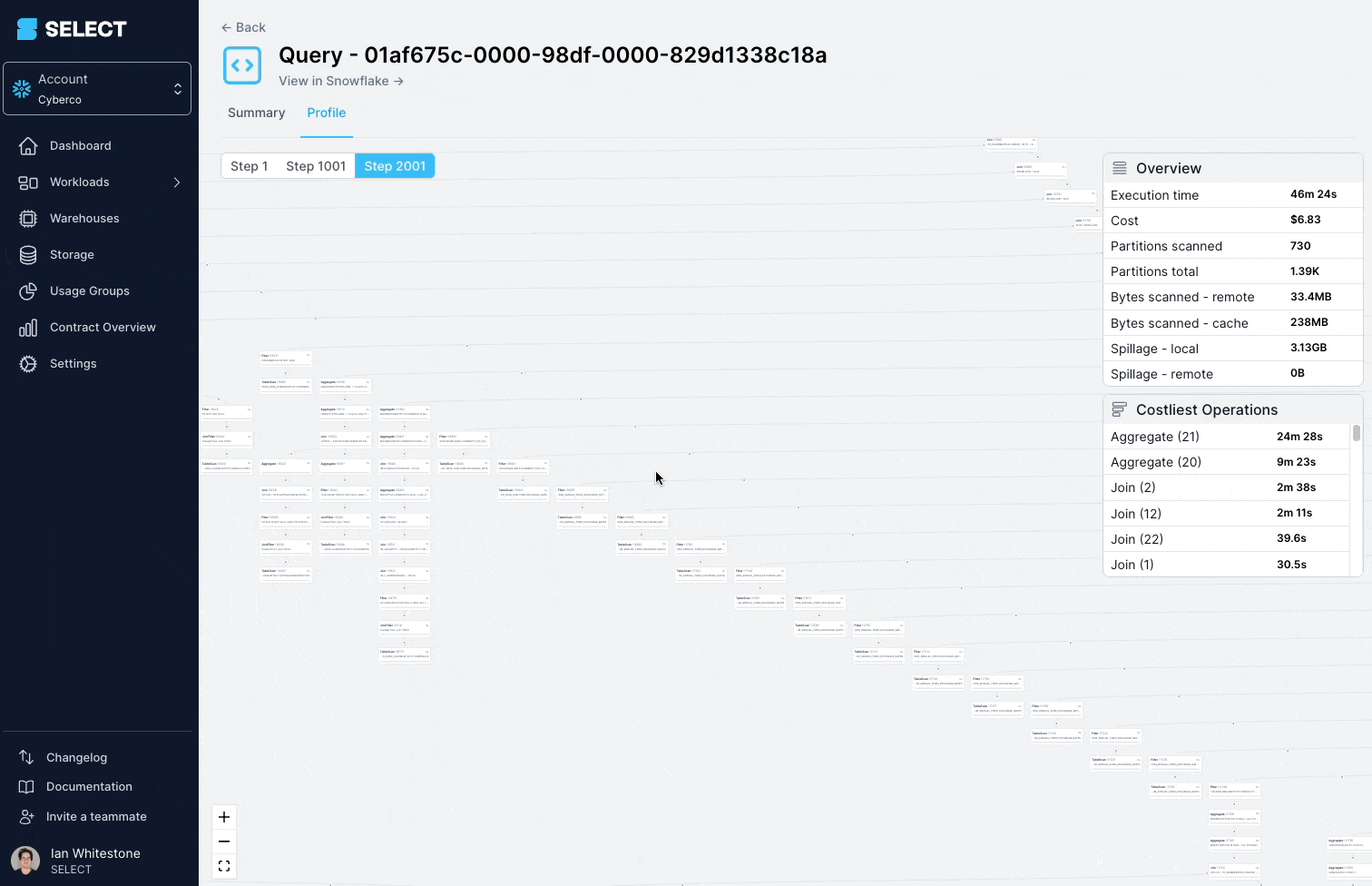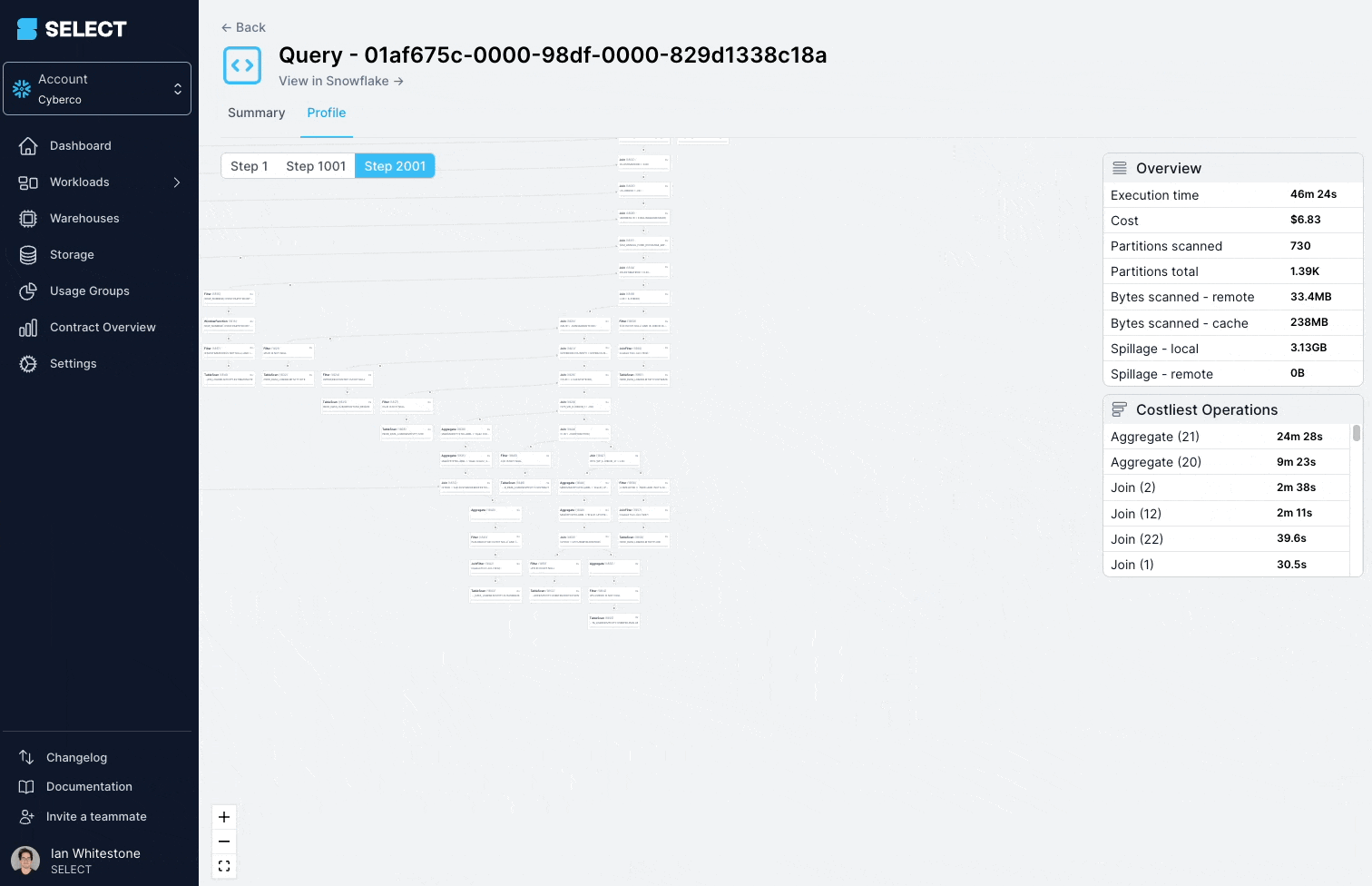
Die Lösung: die komplexe View in einfachere, kleinere Bestandteile zerlegen und diese als Tabellen persistieren.
13\. Query-Caches effektiv einsetzen
Jeder Knoten in einem Virtual Warehouse besitzt lokalen Festplattenspeicher, der als Cache für aus dem Remote-Storage gelesene Micro-Partitions dient. Greifen mehrere Queries auf denselben Datensatz einer Tabelle zu, können sie die Daten aus dem lokalen Disk-Cache statt aus dem Remote-Storage lesen – das beschleunigt Queries, deren Hauptflaschenhals das Lesen ist.
Wird das Warehouse suspendiert, garantiert Snowflake nicht, dass der Cache beim erneuten Hochfahren erhalten bleibt. Der Effekt: Queries müssen die Daten erneut aus dem Tabellenspeicher scannen, statt sie aus dem deutlich schnelleren lokalen Cache zu lesen. Beeinträchtigt der Cache-Verlust Ihre Queries, hilft es, die Auto-Suspend-Schwelle zu erhöhen.
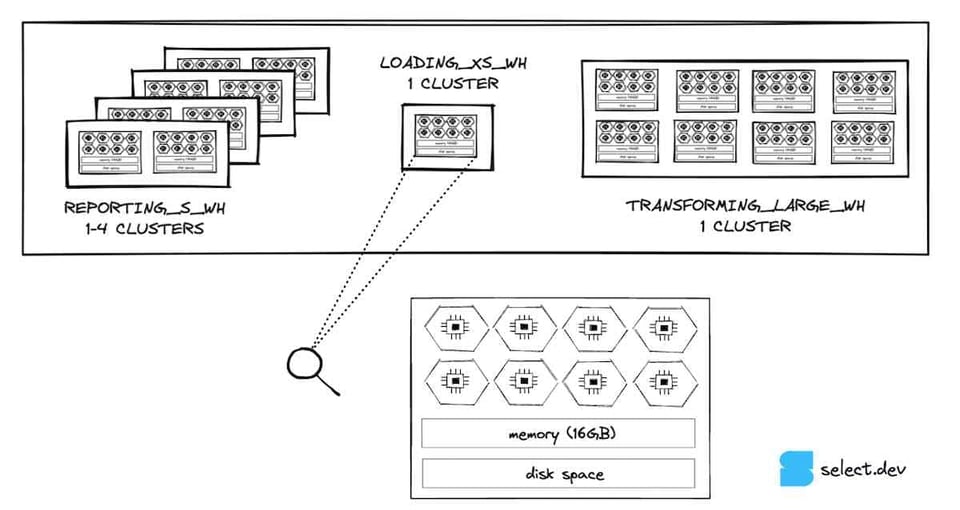
Zusätzlich verfügt Snowflake über einen globalen Result Cache, der Ergebnisse identischer Queries zurückliefert, sofern sie innerhalb von 24 Stunden ausgeführt wurden und sich die Daten in den abgefragten Tabellen nicht geändert haben. Bestimmte Situationen verhindern die Nutzung des globalen Result Caches (etwa nicht-deterministische Funktionen in der Query). Prüfen Sie daher, ob Sie den Cache wie erwartet treffen. Falls nicht, passen Sie ggf. Ihre Query an oder kontaktieren Sie den Support, um einen Bug zu melden.
14\. Warehouse-Größe erhöhen
Die Warehouse-Größe bestimmt die gesamte Rechenleistung, die Queries auf dem Warehouse zur Verfügung steht – auch bekannt als vertikale Skalierung.
Vergrößern Sie das Virtual Warehouse, wenn:
- Queries auf Remote Disk spillen (im Query Profile erkennbar)
- Ergebnisse schneller benötigt werden (typisch für nutzernahe Anwendungen)
Queries, die auf Remote Disk spillen, laufen ineffizient, da viel Netzwerkverkehr zwischen dem ausführenden Warehouse und der Remote Disk anfällt, auf der die Daten liegen. Eine Erhöhung der Warehouse-Größe verdoppelt sowohl den verfügbaren RAM als auch die lokale Disk, die deutlich schneller zugreifbar sind als Remote Disks. Tritt Remote-Disk-Spillage auf, kann ein größeres Warehouse die Geschwindigkeit einer Query mehr als verdoppeln. Mehr Details zur Snowflake-Warehouse-Dimensionierung sowie zur Konfiguration der Warehouse-Größen in dbt finden Sie in unseren früheren Beiträgen.
Hinweis: Wenn die meisten Queries auf dem Warehouse kein größeres Warehouse benötigen und Sie nicht für alle Queries hochskalieren wollen, können Sie stattdessen den Query Acceleration Service von Snowflake nutzen. Dieser Service ist ab der Enterprise Edition verfügbar und stellt Queries, die viele Daten scannen, zusätzliche Compute-Ressourcen zur Verfügung.
15\. Max Cluster Count erhöhen
Mit Multi-Cluster Warehouses, ab der Enterprise Edition verfügbar, lassen sich mehrere Instanzen derselben Warehouse-Größe parallel betreiben.
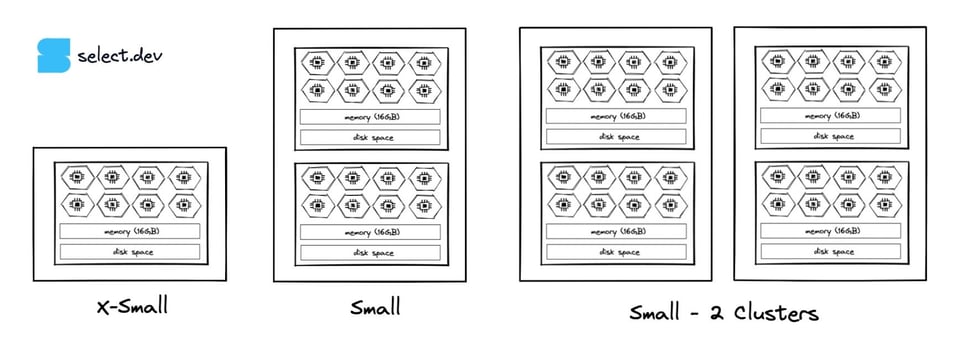
Gibt es Phasen, in denen Queuing dazu führt, dass Queries die erforderliche Verarbeitungsgeschwindigkeit verfehlen, sollten Sie Multi-Clustering nutzen oder die maximale Cluster-Anzahl im Warehouse erhöhen. So kann das Warehouse dem Query-Volumen folgen, indem es Cluster hinzu- oder abschaltet.
Anders als bei der Cluster-Anzahl kann Snowflake die Größe von Virtual Warehouses nicht automatisch an das Query-Volumen anpassen. Das macht Multi-Cluster Warehouses für stark schwankende Query-Volumen besonders wirtschaftlich, da jeder Cluster nur im aktiven Zustand abgerechnet wird.
16\. Cluster Scaling Policy anpassen
Snowflake bietet zwei Scaling Policies: Standard und Economy. Für alle Virtual Warehouses, die nutzernahe Queries bedienen, empfiehlt sich die Standard-Policy. Wer sehr kostenbewusst ist, kann die Economy-Policy für queue-tolerante workloads wie das Data Loading ausprobieren, um zu prüfen, ob sich Kosten senken lassen, ohne den nötigen Durchsatz einzubüßen. Ansonsten empfehlen wir Standard für alle Warehouses.
Weitere Ressourcen
Wer noch mehr zur Snowflake-Query-Optimierung sucht, dem empfehlen wir die folgenden Video-Ressourcen.
Behind the Cape: 3-teilige Serie zur Snowflake-Kostenoptimierung (2023)
In dieser dreiteiligen Videoserie war Ian gemeinsam mit Snowflake Data Superhero Keith Belanger bei Behind the Cape zu Gast – einer Reihe, in der Snowflake-Experten in verschiedene Themen eintauchen.
Teil 1
In dieser Folge haben wir uns das gewichtige Thema Snowflake-Kostenoptimierung vorgenommen. Da uns nur 30 Minuten zur Verfügung standen, blieb es eher beim großen Bild: Wie startet man? Wie funktioniert Snowflakes Abrechnungsmodell? Und welche Tools bietet Snowflake zur Kostenkontrolle?
Hier die vollständige Themenliste:
- Wie sollten Sie mit der Snowflake-Kostenoptimierung starten? (TL;DR: Verschaffen Sie sich zuerst ein ganzheitliches Bild Ihrer Kostentreiber, bevor Sie in einzelne Optimierungen einsteigen.)
- Wo die meisten Kunden heute beim Verständnis ihrer Snowflake-Nutzung stehen
- Wie Snowflakes Abrechnungsmodell funktioniert (wussten Sie, dass die Datenspeicherung in Snowflake tatsächlich günstiger ist?)
- Die Tools, die Snowflake für Kostentransparenz bereitstellt
- Methoden zur Kostenkontrolle (Resource Monitors, Query Timeouts und ACCESS CONTROL – an das niemand denkt!)
- Womit fängt man beim Kostensparen an? Bei Queries? Oder einen Schritt höher?
- Ressourcen zum Weiterlesen.
Für alle, die einen Überblick über Kostenoptimierung, Monitoring und Steuerung suchen, ist das ein guter Startpunkt. Die Aufzeichnung finden Sie unten. Es gibt noch viel mehr zu besprechen – in die Tiefe konnten wir nicht gehen, das holen wir bald nach!
Play
Teil 2
In dieser Folge gehen wir tiefer in einige wichtige Grundkonzepte der Snowflake-Query-Optimierung:
- Der Lebenszyklus einer Snowflake-Query
- Dimensionierung von Snowflake Virtual Warehouses
- So nutzen Sie das Snowflake Query Profile, um Flaschenhälse zu identifizieren
Play
Teil 3
In der finalen Folge der Serie geht es um die wichtigsten Query-Optimierungstechniken:
- Snowflake Micro-Partitions verstehen
- So nutzen Sie Query Pruning
- So stellen Sie sicher, dass Ihre Tabellen effektiv geclustert sind
Play
Snowflake Optimization Power Hour Video (2022)
Am 28. September 2022 hielt Ian bei der Snowflake Toronto User Group einen Vortrag zu Snowflake Performance Tuning und Kostenoptimierung. Inhalte:
- Snowflake-Architektur
- Der Lebenszyklus einer Snowflake-Query
- Snowflakes Abrechnungsmodell
- Ein einfaches Framework zur Kostenoptimierung sowie eine detaillierte Methodik zur Berechnung der Kosten pro Query
- Best Practices zur Warehouse-Konfiguration
- Tipps zum Tabellen-Clustering
Folien
Die Folien finden Sie hier. Zum Navigieren klicken Sie unten rechts auf die Pfeile oder nutzen die Pfeiltasten Ihrer Tastatur. Mit "esc" oder "o" gelangen Sie in eine Übersicht aller Folien. Von dort aus navigieren Sie erneut mit den Pfeilen und können entweder eine Folie anklicken oder per "esc"/"o" wieder hineinzoomen.
Aufzeichnung des Vortrags
Eine Aufzeichnung des Vortrags ist auf YouTube verfügbar. Der Vortrag beginnt bei 3:29.
Play
Auf Wunsch komme ich gerne zu Ihnen und halte diesen Vortrag (oder eine Variante davon) für Ihr Team, damit alle Gelegenheit zum Nachfragen haben. Schreiben Sie an [email protected], wenn Sie das vereinbaren möchten.
Query Optimization at Snowflake (2020)
Wenn Sie die Interna des Snowflake-Query-Optimizers besser verstehen wollen, empfehle ich diesen Vortrag von Jiaqi Yan, einem der erfahrensten Database Engineers bei Snowflake:
Play
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT leitete Ian sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouses und den Ausbau der Kostentransparenz.
Niall Woodward · Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT war Niall Data Engineer bei Brooklyn Data Company und mehreren Startups. Als Open-Source-Enthusiast ist er Maintainer von SQLFluff und Creator von drei dbt-Packages: dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.