L'immense popularité de Snowflake tient à sa capacité à traiter de grands volumes de données avec une latence extrêmement faible et une configuration minimale. C'est devenu un incontournable des équipes data dans des milliers d'organisations. Dans ce guide, nous partageons des techniques d'optimisation pour tirer le meilleur des performances et de l'efficacité de Snowflake. Appliquez ces bonnes pratiques pour accélérer vos requêtes tout en réduisant vos coûts.
Toutes les techniques de performance tuning Snowflake présentées ici reposent sur des stratégies concrètes que SELECT a aidé plus de 100 clients Snowflake à déployer. Si un point manque selon vous, faites-le-nous savoir ! Contactez-nous par e-mail ou via la bulle de chat en bas de l'écran.
Cet article porte sur les techniques d'optimisation des requêtes et sur la manière de les exploiter pour accélérer vos requêtes Snowflake. Cela peut contribuer à réduire vos coûts, mais d'autres pistes sont plus pertinentes si c'est votre objectif principal. Consultez notre article sur l'optimisation des coûts Snowflake pour des stratégies concrètes de réduction des coûts.
Techniques d'optimisation des requêtes Snowflake
Les techniques d'optimisation des performances des requêtes Snowflake présentées ici se répartissent globalement en trois catégories :
1. Améliorer l'efficacité de la lecture des données
Les requêtes consacrent parfois un temps considérable à lire les données depuis le stockage de la table. Cette étape apparaît sous le nom de TableScan dans le query profile. Un TableScan consiste à télécharger les données depuis l'emplacement de stockage de la table vers les nœuds workers du virtual warehouse, via le réseau. On peut accélérer ce processus en réduisant le volume téléchargé ou en augmentant la taille du virtual warehouse.
Snowflake ne lit que les colonnes sélectionnées dans une requête, ainsi que les micro-partitions correspondant aux filtres de la requête — à condition que les micro-partitions de la table soient bien clustérisées sur la condition de filtrage.
Les quatre techniques permettant de réduire les données téléchargées par une requête, et donc d'accélérer les TableScans, sont :
- Réduire le nombre de colonnes lues
- Tirer parti du query pruning et du clustering des tables
- Utiliser des colonnes clustérisées dans les prédicats de jointure
- Utiliser des tables pré-agrégées
2. Améliorer l'efficacité du traitement des données
Des opérations comme les jointures, les tris et les agrégations interviennent en aval des TableScans et constituent souvent le goulot d'étranglement des requêtes. Pour optimiser le traitement, on peut réduire le nombre d'étapes, traiter les données de manière incrémentale et exploiter sa connaissance des données pour gagner en performance.
Voici les techniques pour améliorer l'efficacité du traitement des données :
- Simplifier et réduire le nombre d'opérations de la requête
- Réduire le volume de données traitées en filtrant en amont
- Éviter les références répétées aux CTE
- Supprimer les tris inutiles
- Privilégier les window functions aux self-joins
- Éviter les jointures avec une condition OR
- Exploiter votre connaissance des données pour aider Snowflake à les traiter efficacement
- Éviter d'interroger des vues complexes
- Veiller à exploiter efficacement les caches de requêtes
3. Optimiser la configuration du warehouse
Les virtual warehouses Snowflake se configurent facilement pour absorber des workloads plus volumineux et à forte concurrence. Les paramètres clés pour gagner en performance sont :
- Augmenter la taille du warehouse
- Augmenter le nombre de clusters du warehouse
- Modifier la politique de scaling du warehouse
Avant de passer aux optimisations, rappelons comment identifier ce qui ralentit une requête.
Comment optimiser une requête Snowflake
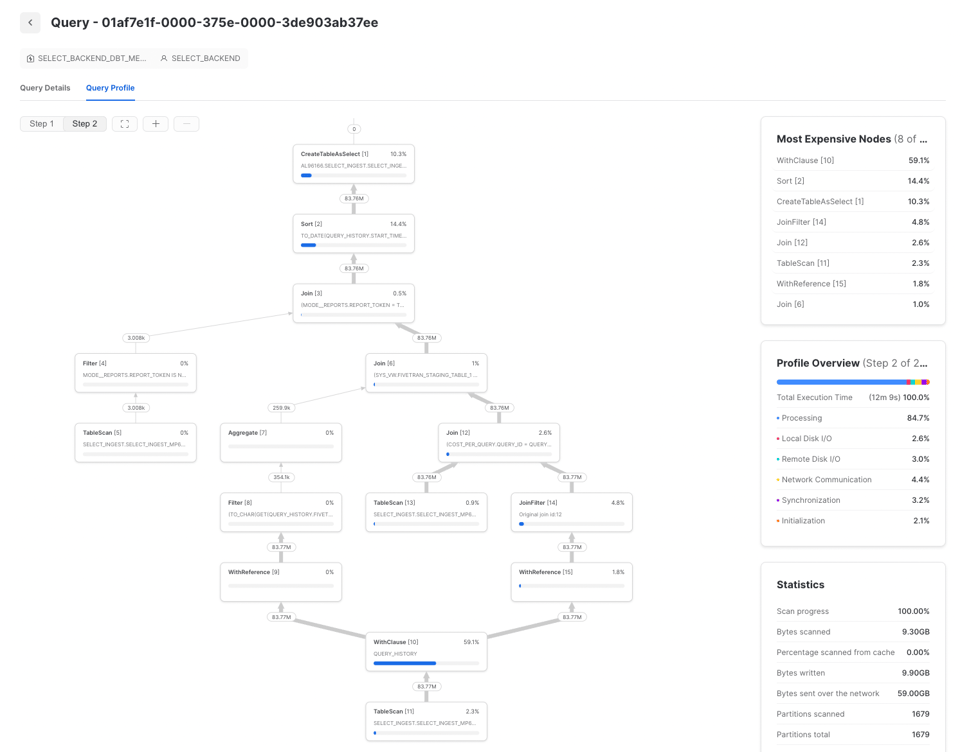
Avant d'optimiser une requête Snowflake, il faut comprendre où se situe réellement le goulot d'étranglement, en s'appuyant sur le query profiling. Quelles opérations la ralentissent, et où concentrer vos efforts ?
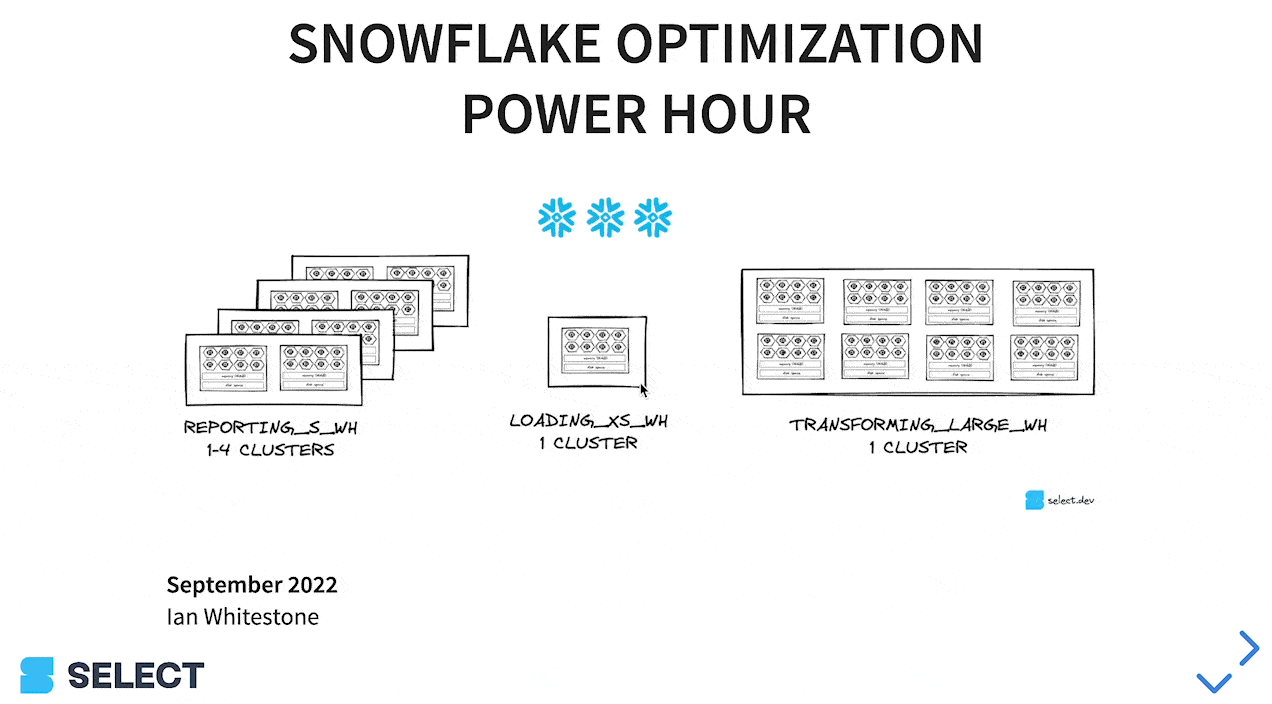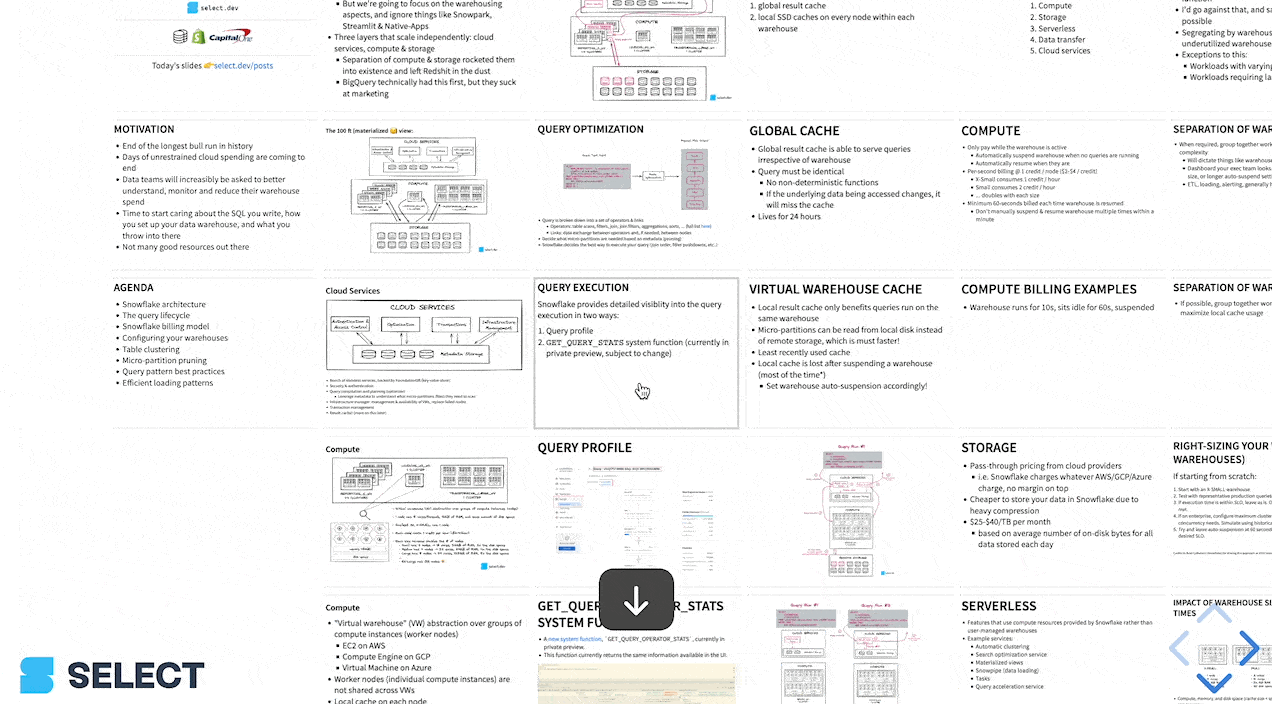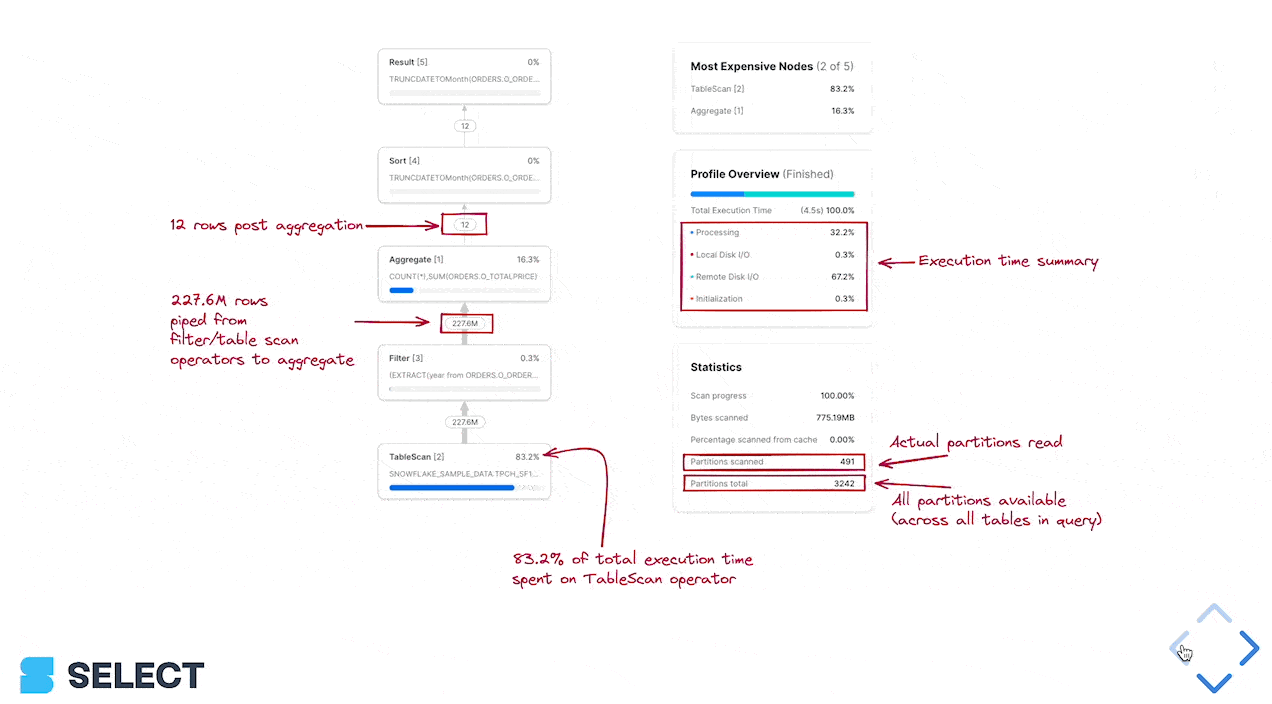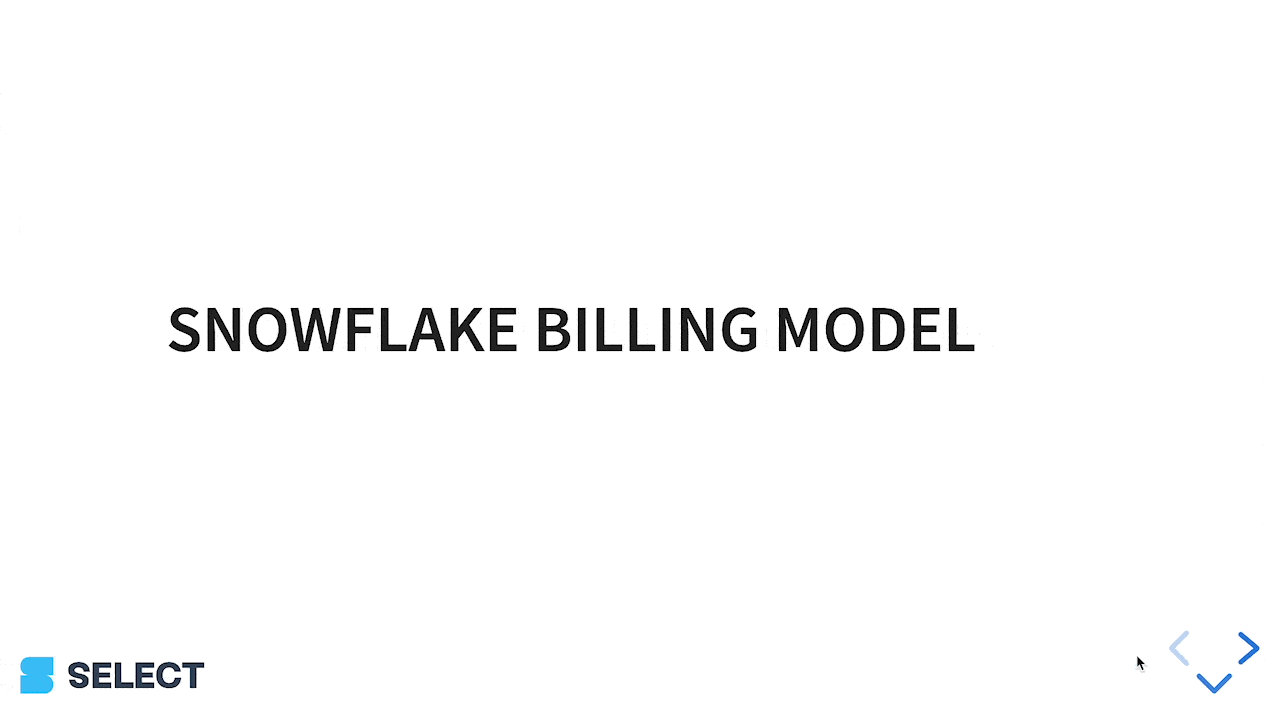
Pour le déterminer, ouvrez le Query Profile Snowflake (plan d'exécution) et examinez la section Most Expensive Nodes. Elle indique les étapes qui consomment le plus de temps d'exécution.
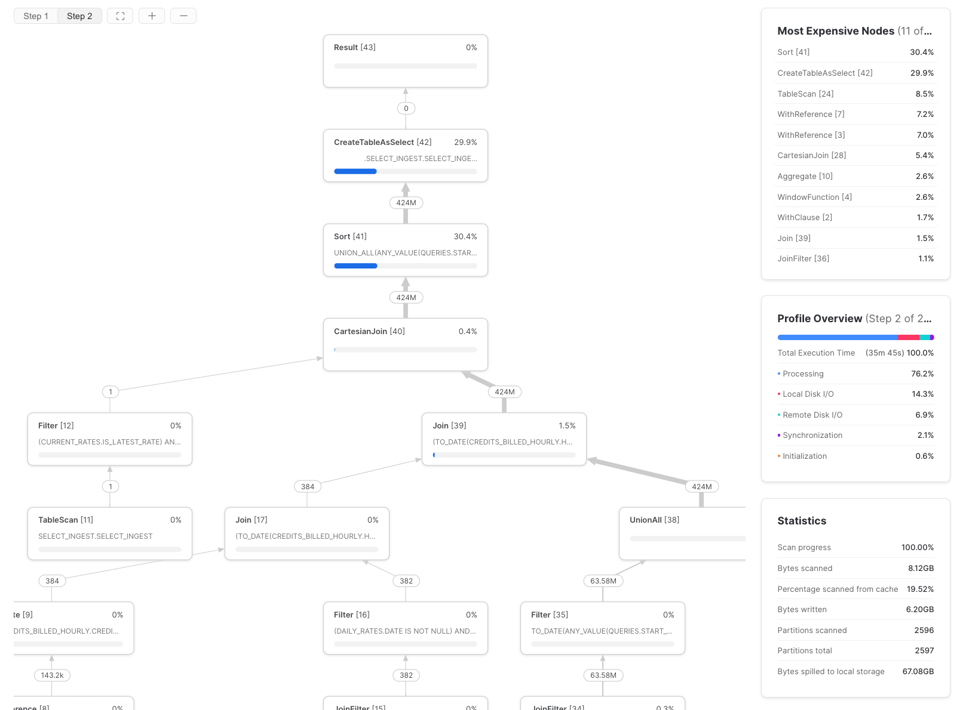
Dans cet exemple, le goulot d'étranglement se situe à l'étape de Sort, ce qui indique qu'il faut se concentrer sur l'efficacité du traitement des données, et éventuellement augmenter la taille du warehouse. Si les nœuds les plus coûteux sont des TableScans, les efforts seront mieux investis dans l'optimisation de la lecture des données.
1\. Sélectionner moins de colonnes
C'est simple, mais lorsque c'est faisable, l'impact est considérable. Les besoins d'une requête évoluent avec le temps, et des colonnes autrefois utiles peuvent ne plus l'être pour les processus en aval. Snowflake stocke les données dans un format de fichier hybride colonnaire appelé micro-partitions. Ce format permet à Snowflake de réduire la quantité de données à lire depuis le stockage. Le téléchargement des données des micro-partitions s'appelle le scanning, et réduire le nombre de colonnes diminue le volume transféré sur le réseau.
2\. Tirer parti du query pruning
Pour réduire le nombre de micro-partitions scannées par une requête — une technique appelée query pruning — plusieurs conditions doivent être réunies :
- Votre requête doit inclure un filtre limitant les données nécessaires. Il peut s'agir d'un filtre
whereexplicite ou d'un filtrejoinimplicite. - Votre table doit être bien clustérisée sur la colonne utilisée pour le filtrage.
L'exécution de la requête ci-dessous sur la table hypothétique orders du schéma déclenchera du query pruning, car (a) la table orders est clustérisée sur created_at (les données sont triées par created_at) et (b) la clause where filtre explicitement created_at sur une date précise.
select *
from orders
where created_at > '2022/08/14'

Pour savoir si les performances de pruning peuvent être améliorées, examinez les statistiques Partitions scanned et Partitions total du query profile.
Si votre requête n'utilise pas de filtre where, en ajouter un peut accélérer considérablement le TableScan (et les nœuds en aval, qui traitent alors moins de données). Si votre requête comporte déjà un filtre where mais que Partitions scanned est proche de Partitions total, c'est que le filtre n'est pas effectivement pruné.
Pour améliorer le pruning :
- Placez les clauses where le plus tôt possible dans les requêtes, sinon elles risquent de ne pas être pushed down sur l'étape TableScan (ce qui accélère aussi les étapes ultérieures)
- Ajoutez des colonnes bien clustérisées aux conditions de jointure et de merge, qui pourront être pushed down comme JoinFilters pour activer le pruning
- Assurez-vous que les colonnes utilisées dans les filtres where correspondent au clustering de la table (pour en savoir plus sur le clustering, c'est par ici)
- Évitez les fonctions dans les conditions where — elles empêchent souvent Snowflake de pruner les micro-partitions
3\. Utiliser des colonnes clustérisées dans les prédicats de jointure
La forme de pruning la plus connue est le static query pruning. Voici un exemple simple, proche du précédent :
select *
from orders
where order_date > current_date - 7
Si la table orders est clustérisée sur order_date, l'optimiseur de requêtes Snowflake reconnaîtra que la plupart des micro-partitions (fichiers) contenant des données antérieures à 7 jours peuvent être ignorées. Comme le scan de données distantes prend un temps de traitement significatif, éliminer des micro-partitions accélère considérablement la requête.
Une fonctionnalité moins connue du moteur de requêtes Snowflake est le pruning dynamique. Contrairement au pruning statique, qui a lieu avant l'exécution lors de la phase de planification, le pruning dynamique se produit à la volée, pendant l'exécution.
Imaginez un processus qui met régulièrement à jour les enregistrements existants de la table orders via une commande MERGE. En coulisses, un MERGE nécessite une jointure entre la table source contenant les enregistrements nouveaux/mis à jour et la table cible (orders) à mettre à jour.
Le pruning dynamique entre en jeu pendant la jointure. Comment cela fonctionne-t-il ? Lorsque le moteur Snowflake lit les données de la table source, il identifie la plage d'enregistrements présents et pousse automatiquement un filtre vers la table cible pour éviter les scans inutiles.
Illustrons par un exemple. Imaginons une table source contenant 3 enregistrements à mettre à jour dans la table cible orders, clustérisée par date de commande. Un MERGE typique met en correspondance les enregistrements via une clé unique, comme order key. Comme ces clés uniques sont généralement aléatoires, elles n'imposent aucun pruning. Si l'on modifie la condition de MERGE pour faire correspondre les enregistrements sur order key et order date, le pruning dynamique peut alors entrer en jeu. Lorsque Snowflake lit les données de la table source, il détecte la plage de dates couverte par les 3 commandes en cours de mise à jour. Il peut ensuite pousser cette plage dans un filtre côté cible, évitant ainsi de scanner toute la grande table.

Comment appliquer cela au quotidien ? Si vous avez des opérations MERGE ou JOIN où le scan de la table cible (à droite) prend un temps important, demandez-vous si vous pouvez ajouter des prédicats à votre clause de jointure pour forcer le pruning. À noter : cela ne fonctionnera que si (a) votre table cible est clustérisée sur une clé et (b) la table source (à gauche) que vous joignez contient une plage d'enregistrements étroitement bornée sur la clé de clustering (par exemple, un sous-ensemble de dates de commande).
Lorsque vous utilisez une stratégie de matérialisation incremental dans dbt, une requête MERGE est exécutée en coulisses. Pour ajouter une condition de jointure supplémentaire et forcer le pruning dynamique, ajoutez la colonne (par exemple updated_at) au tableau unique_key.
{{ config(
materialized='incremental',
unique_key=['order_id', 'updated_at'],
) }}
select *
from {{ ref('stg_orders') }}
...
4\. Utiliser des tables pré-agrégées
Créez des tables rollup ou dérivées contenant moins de lignes. Les tables pré-agrégées peuvent souvent être conçues pour fournir les informations dont la plupart des requêtes ont besoin tout en occupant moins d'espace de stockage. Elles sont ainsi bien plus rapides à interroger. Pour les acteurs du retail, une stratégie courante consiste à utiliser une table rollup quotidienne des commandes pour le reporting financier et de stock, en n'interrogeant la table brute que lorsqu'une granularité par commande est nécessaire.
5\. Simplifier !
Chaque opération d'une requête prend du temps pour déplacer les données entre les threads workers. Consolider et supprimer les opérations inutiles réduit le volume de transferts réseau nécessaires à l'exécution. Cela aide aussi Snowflake à réutiliser des calculs et à économiser du travail. La plupart du temps, les CTE et les sous-requêtes n'impactent pas les performances : utilisez-les pour améliorer la lisibilité.
De manière générale, faire en sorte que chaque requête en fasse moins facilite le débogage. Cela réduit aussi le risque que l'optimiseur Snowflake fasse un mauvais choix (par exemple, retenir le mauvais ordre de jointure).
6\. Réduire le volume de données traitées
Moins il y a de données, plus chaque étape de traitement est rapide. Réduire à la fois le nombre de colonnes et de lignes traitées à chaque étape d'une requête améliore les performances.
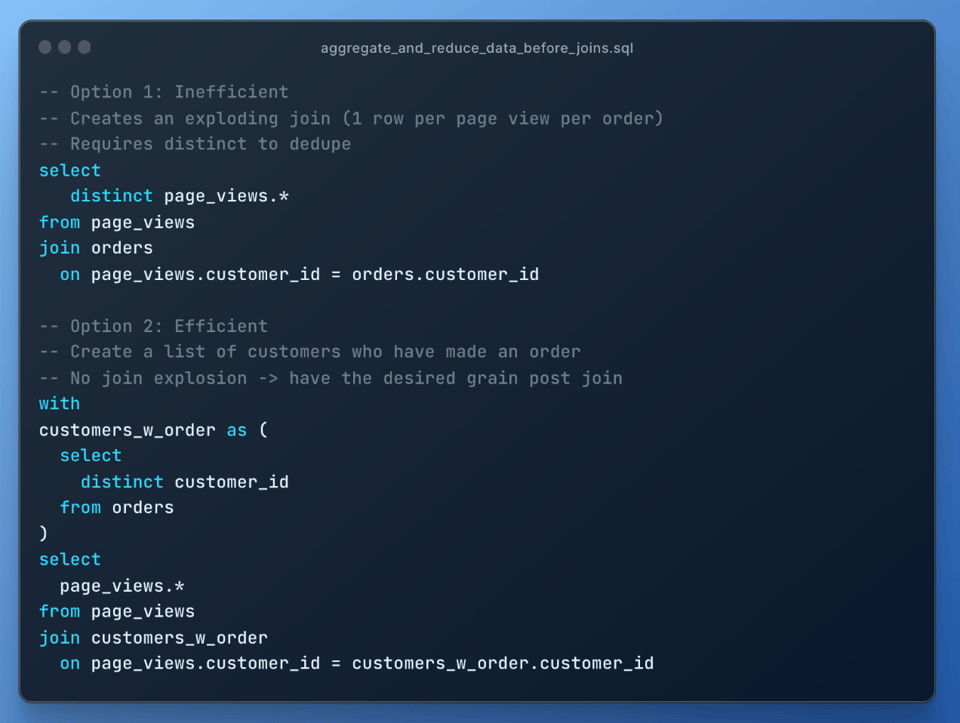
Voici un exemple où déplacer un filtre qualify plus tôt dans la requête a multiplié la vitesse d'exécution par 3. Le premier query profile montre le temps d'exécution lorsque le filtre QUALIFY intervenait après une jointure.
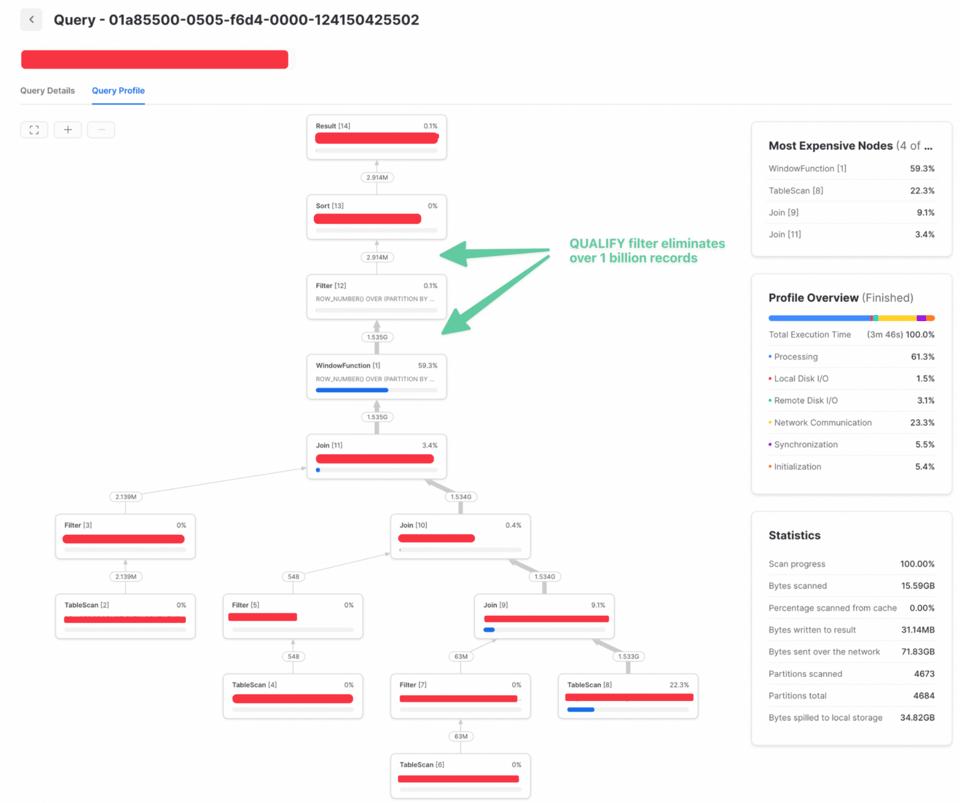
Comme le filtre QUALIFY ne nécessitait pas d'informations issues de la jointure, il a pu être placé plus tôt. Résultat : nettement moins de données jointes et des performances grandement améliorées :
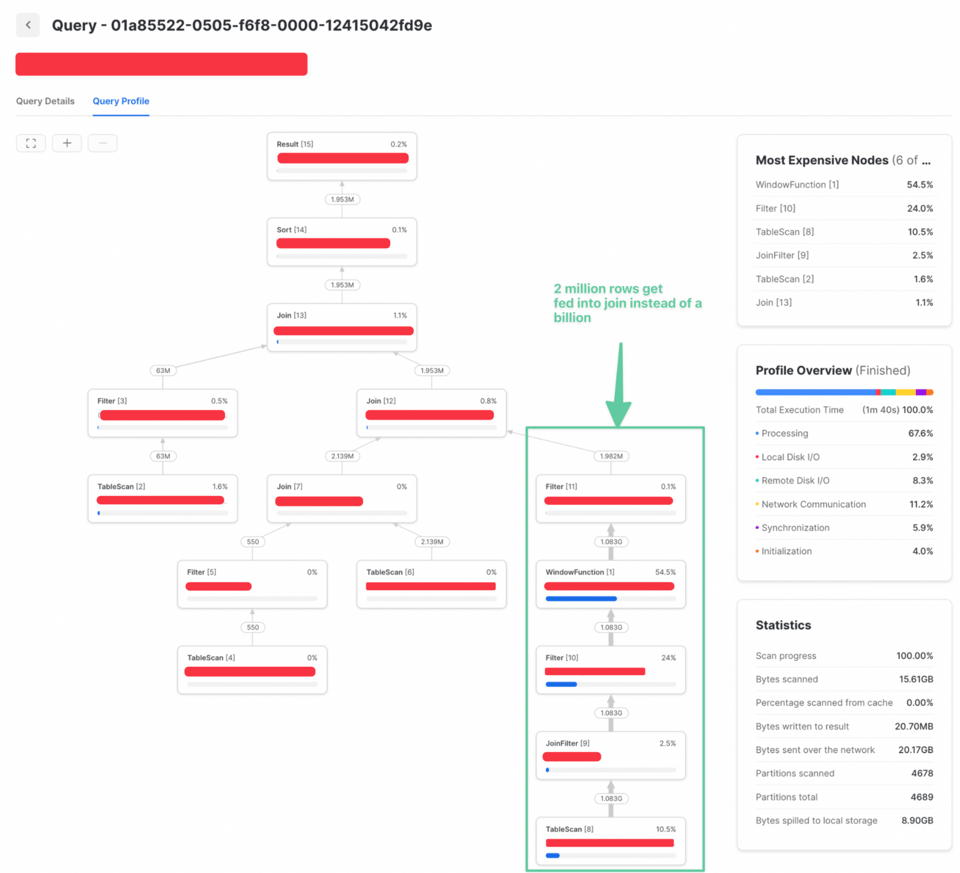
Pour les requêtes de transformation qui écrivent dans une autre table, l'incrémentalisation est un levier puissant pour réduire le volume traité. Dans l'exemple de la table orders, on pourrait configurer la requête pour ne traiter que les commandes nouvelles ou mises à jour, puis fusionner ces résultats dans la table existante.
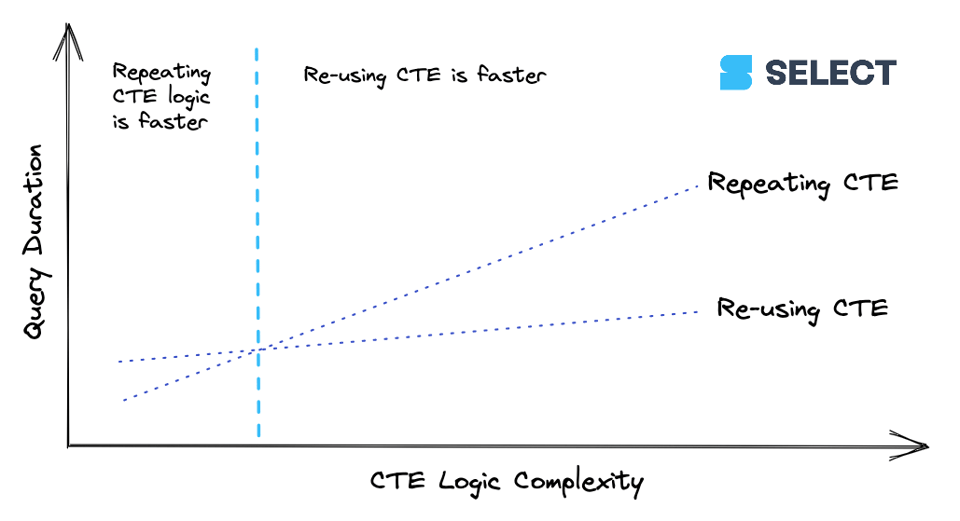
7\. Répéter les CTE peut parfois être plus rapide
Nous avons déjà abordé la question de savoir s'il faut utiliser des CTE dans Snowflake. Chaque fois que vous référencez une CTE plusieurs fois dans votre requête, une opération WithClause apparaît dans le query profile (voir exemple ci-dessous). Dans certains cas, cela peut en réalité ralentir la requête, et il devient plus efficace de réécrire la CTE à chaque référence.
Lorsqu'une CTE atteint un certain niveau de complexité, il devient moins coûteux de la calculer une seule fois puis de transmettre ses résultats aux références en aval, plutôt que de la recalculer à chaque fois. Ce comportement n'est cependant pas systématique : mieux vaut donc expérimenter. Voici une façon de visualiser la relation :
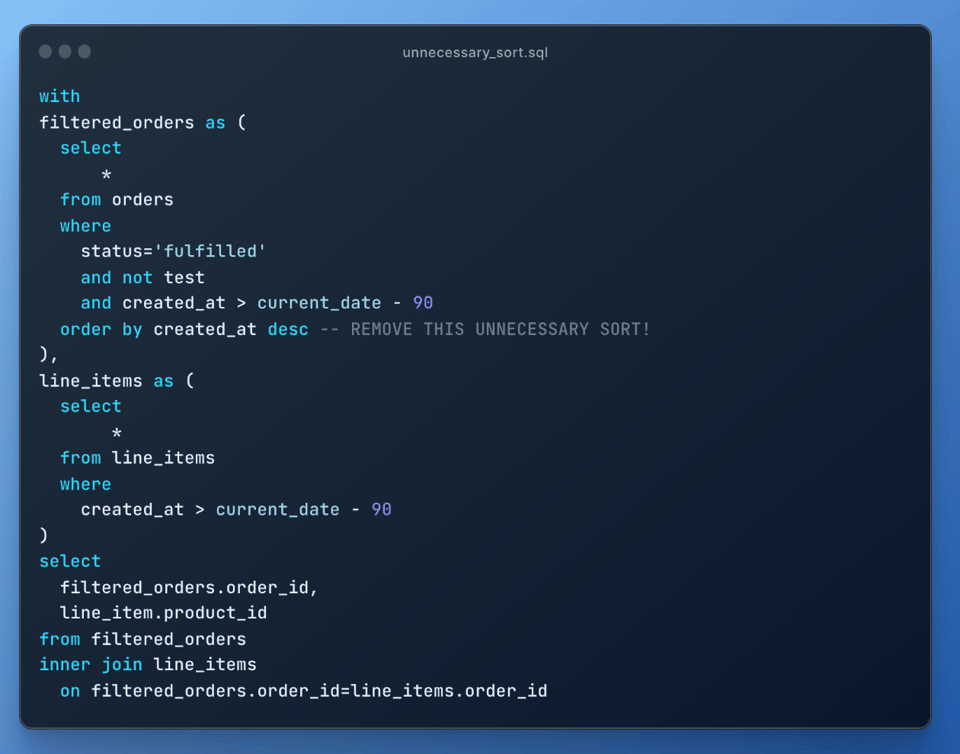
8\. Supprimer les tris inutiles
Le tri est une opération coûteuse : veillez à supprimer tous les tris qui ne sont pas nécessaires :
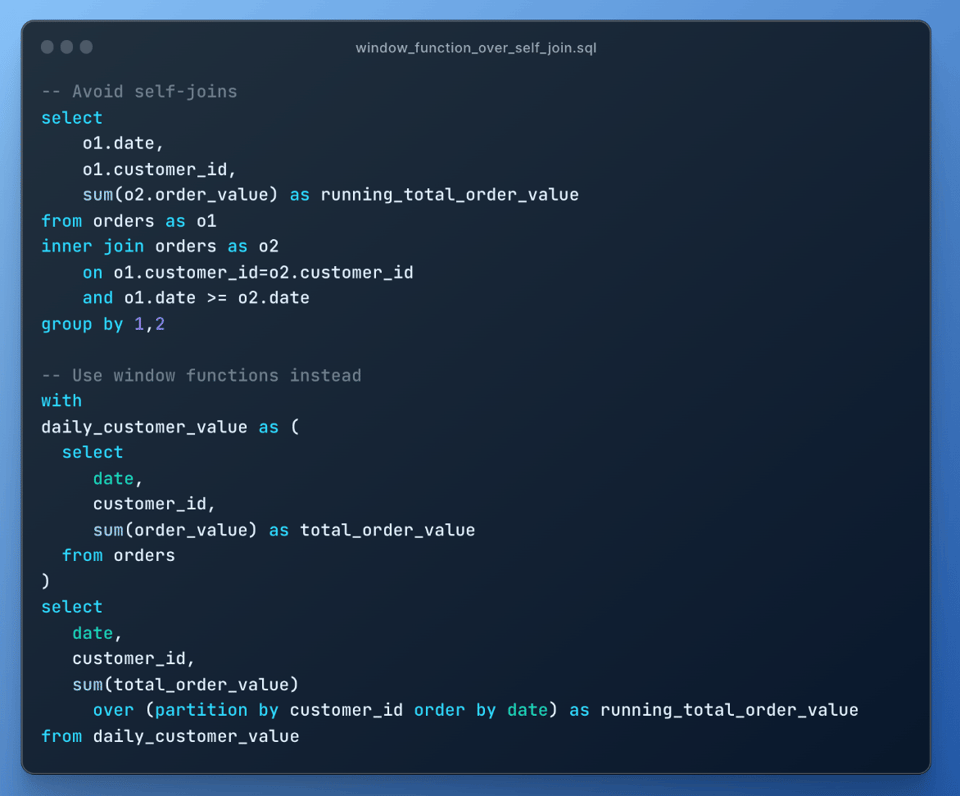
9\. Privilégier les window functions aux self-joins
Plutôt qu'un self join, utilisez autant que possible des window functions : les self joins sont très coûteux, car ils provoquent une explosion de jointure :
10\. Éviter les jointures avec une condition OR
À l'instar des self-joins, les jointures dont la condition contient un OR provoquent une explosion de jointure : elles s'exécutent comme une jointure cartésienne suivie d'un filtre. Utilisez plutôt deux left joins :
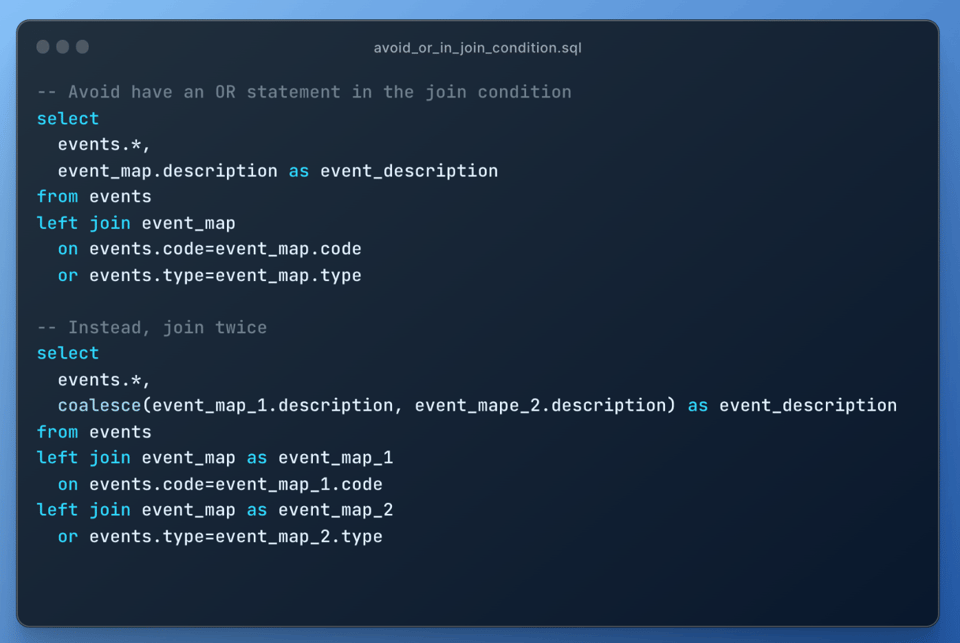
11\. Exploiter votre connaissance des données pour aider Snowflake à les traiter efficacement
Votre connaissance des données peut servir à améliorer les performances des requêtes. Par exemple, si une requête groupe sur de nombreuses colonnes et que vous savez que certaines sont redondantes (les autres représentant déjà la même granularité ou une granularité supérieure), il peut être plus rapide de les retirer du group by et de les rejoindre dans une étape séparée.
Si une colonne groupée ou jointe est fortement asymétrique (un petit nombre de valeurs distinctes très fréquentes), cela peut nuire considérablement à la vitesse de Snowflake. Cas classique : un regroupement sur une colonne contenant un grand nombre de valeurs nulles. Filtrer ces lignes et les traiter dans une opération distincte peut accélérer la requête.
Enfin, les range joins peuvent être lents dans tous les entrepôts de données, Snowflake compris. Votre connaissance de la longueur des intervalles peut servir à réduire l'explosion de jointure qui en résulte. Consultez notre article récent si vous observez des performances lentes sur les range joins.
12\. Éviter les vues complexes
Bonne pratique : évitez de créer et d'utiliser des vues complexes dans vos requêtes. Les vues doivent servir à persister des transformations simples : renommage de colonnes, calculs basiques, ou modèles de données avec des jointures légères.
Pour mesurer les dégâts que peuvent causer des vues complexes, examinez cette requête en apparence anodine :
select
a.*,
b.*
from model_a as a
left join model_b as b
on a.id=b.id
Cette requête mettait régulièrement plus de 45 minutes à s'exécuter et échouait sur un Incident.
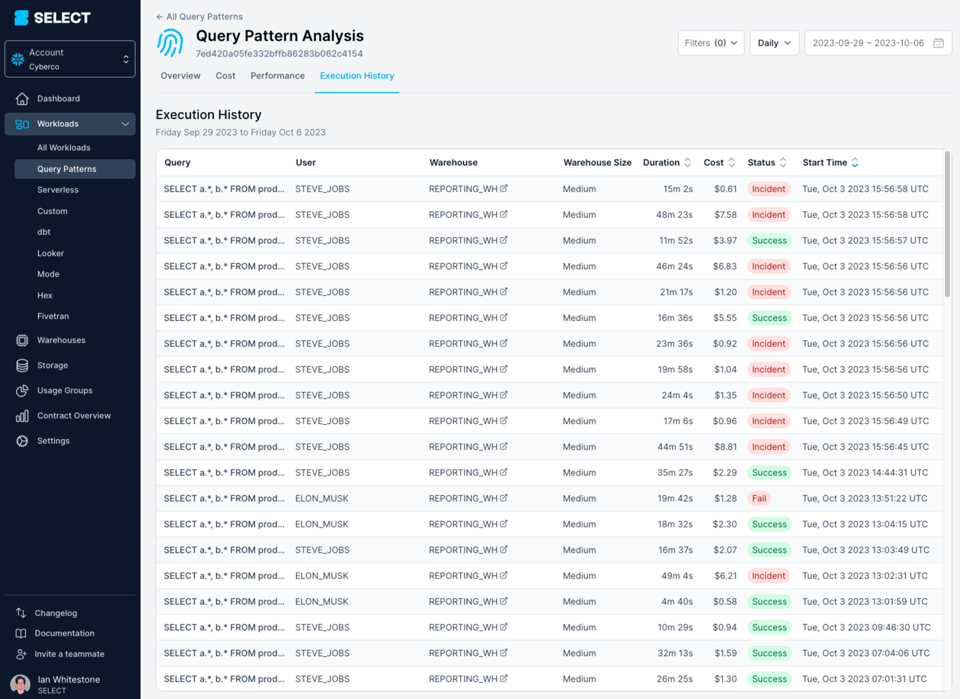
En creusant dans le query profile (aussi appelé plan d'exécution), on s'aperçoit que les modèles interrogés étaient en fait des vues complexes, comportant des centaines de tables.
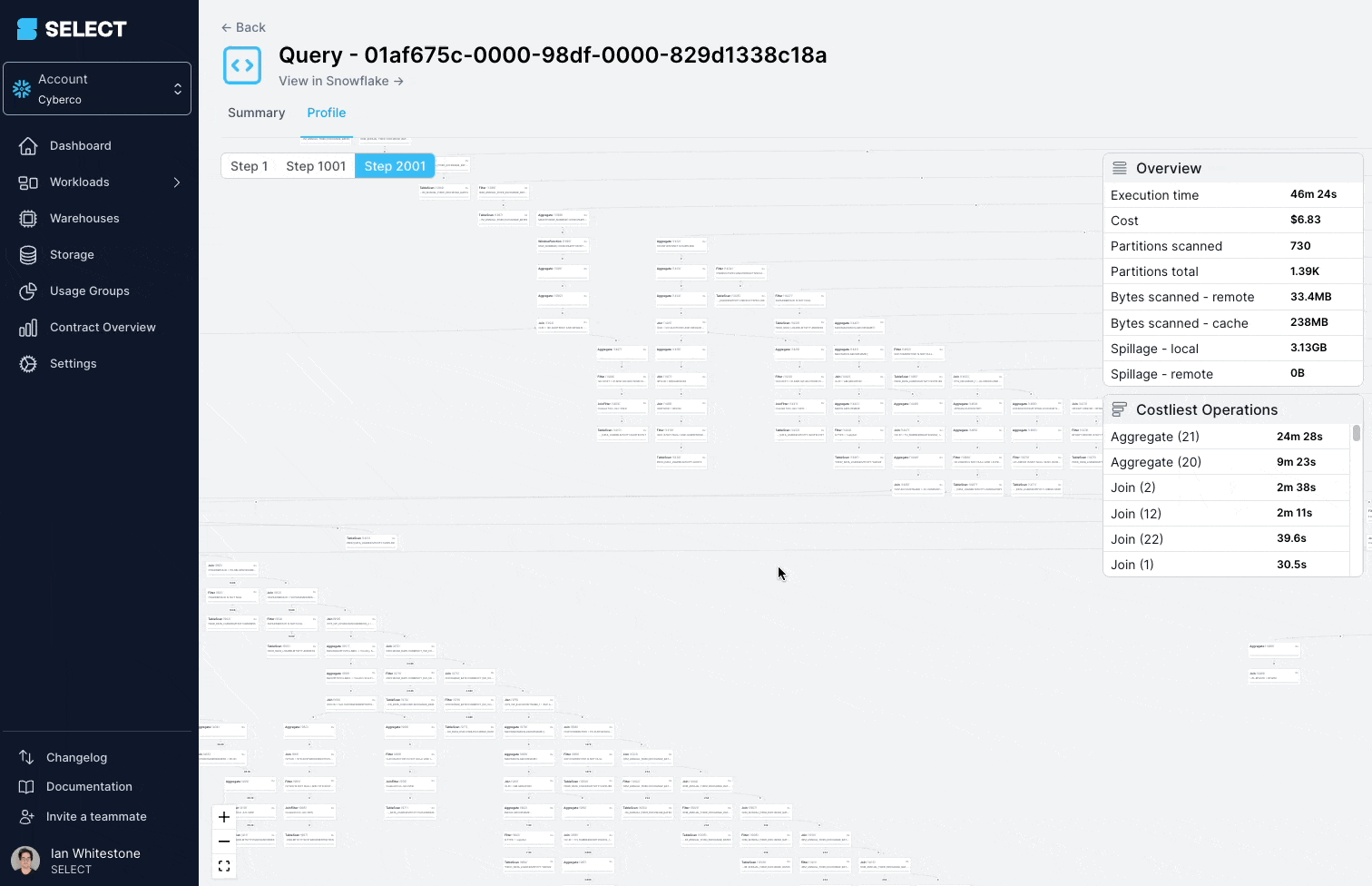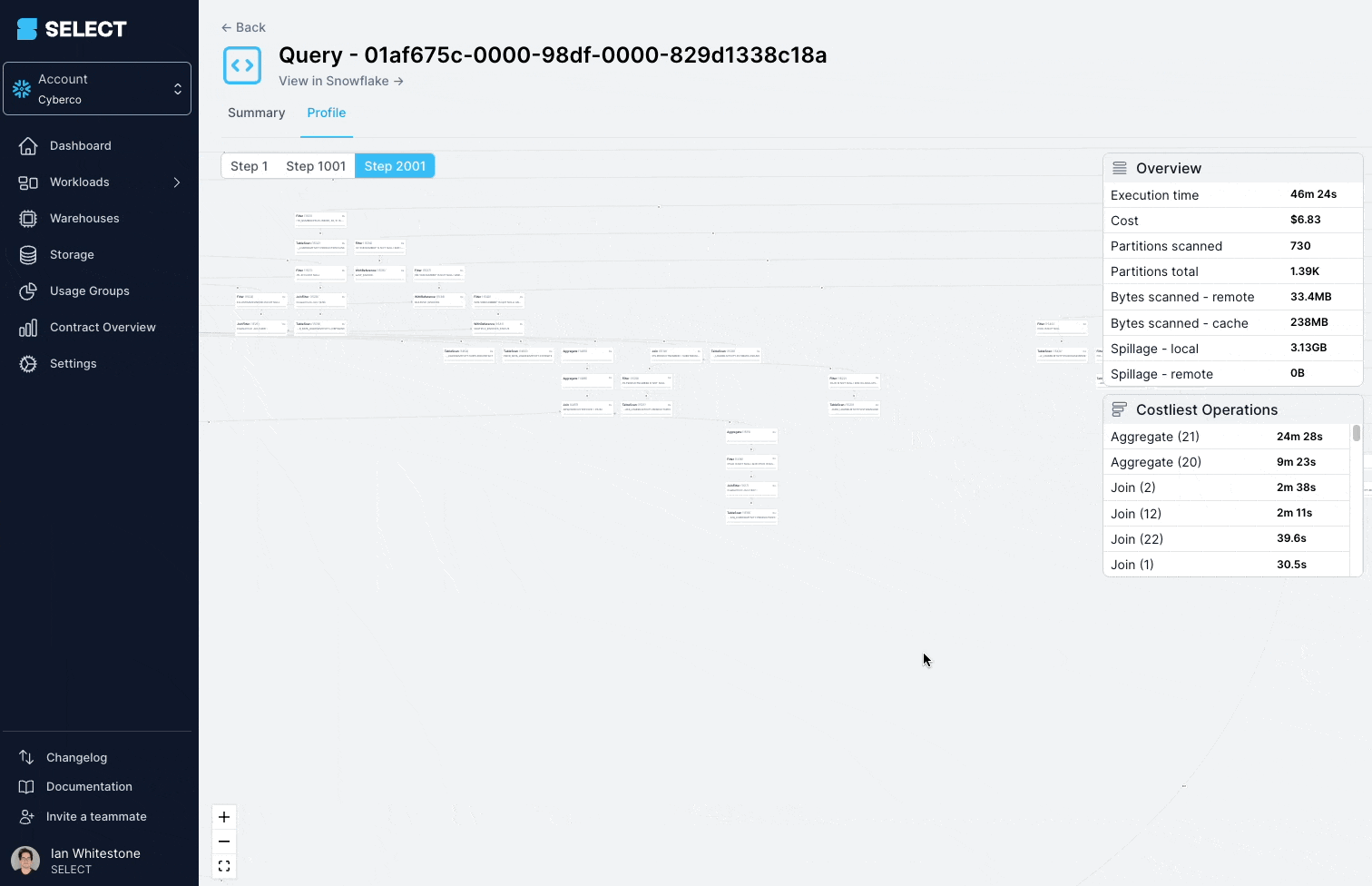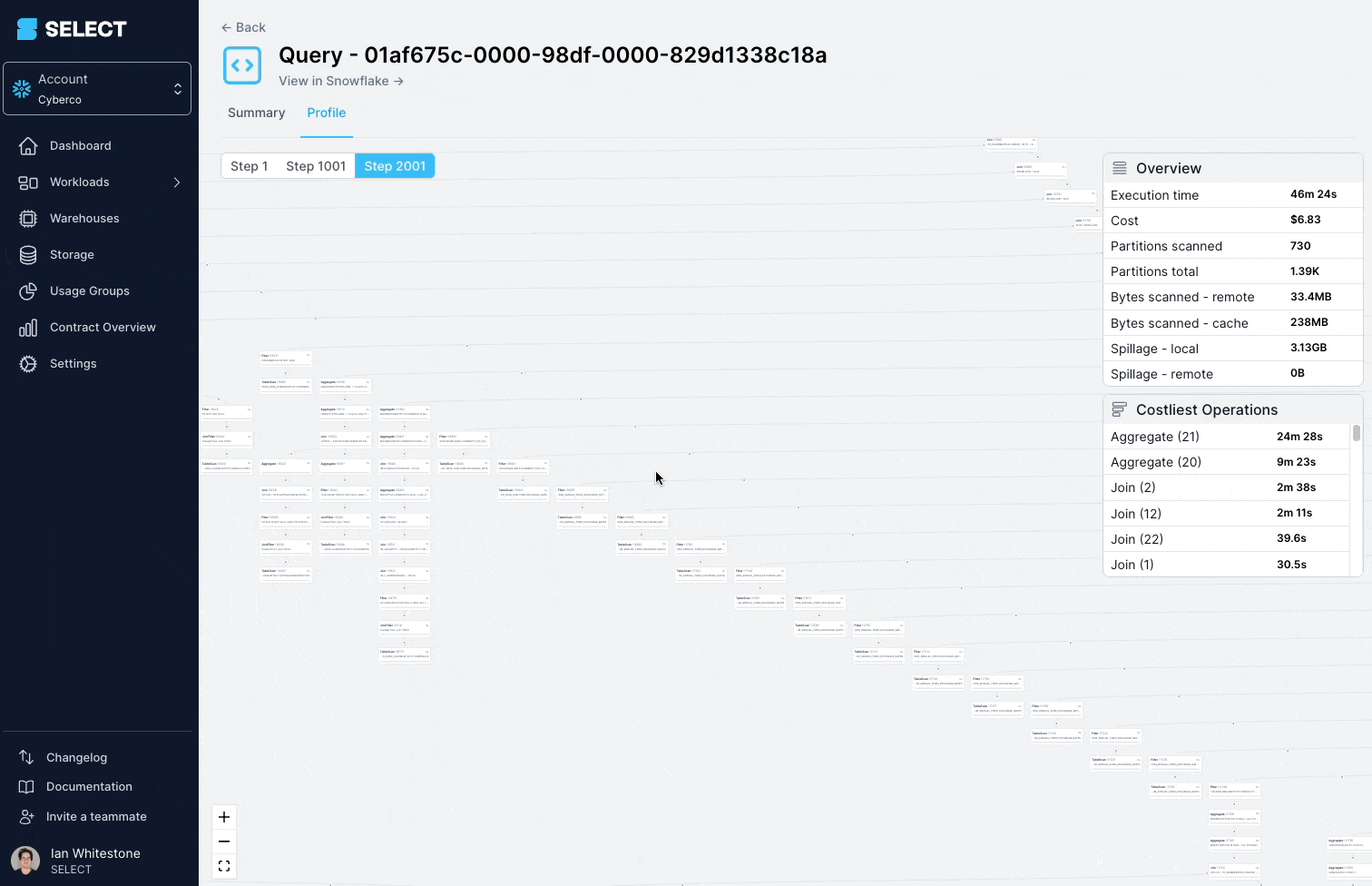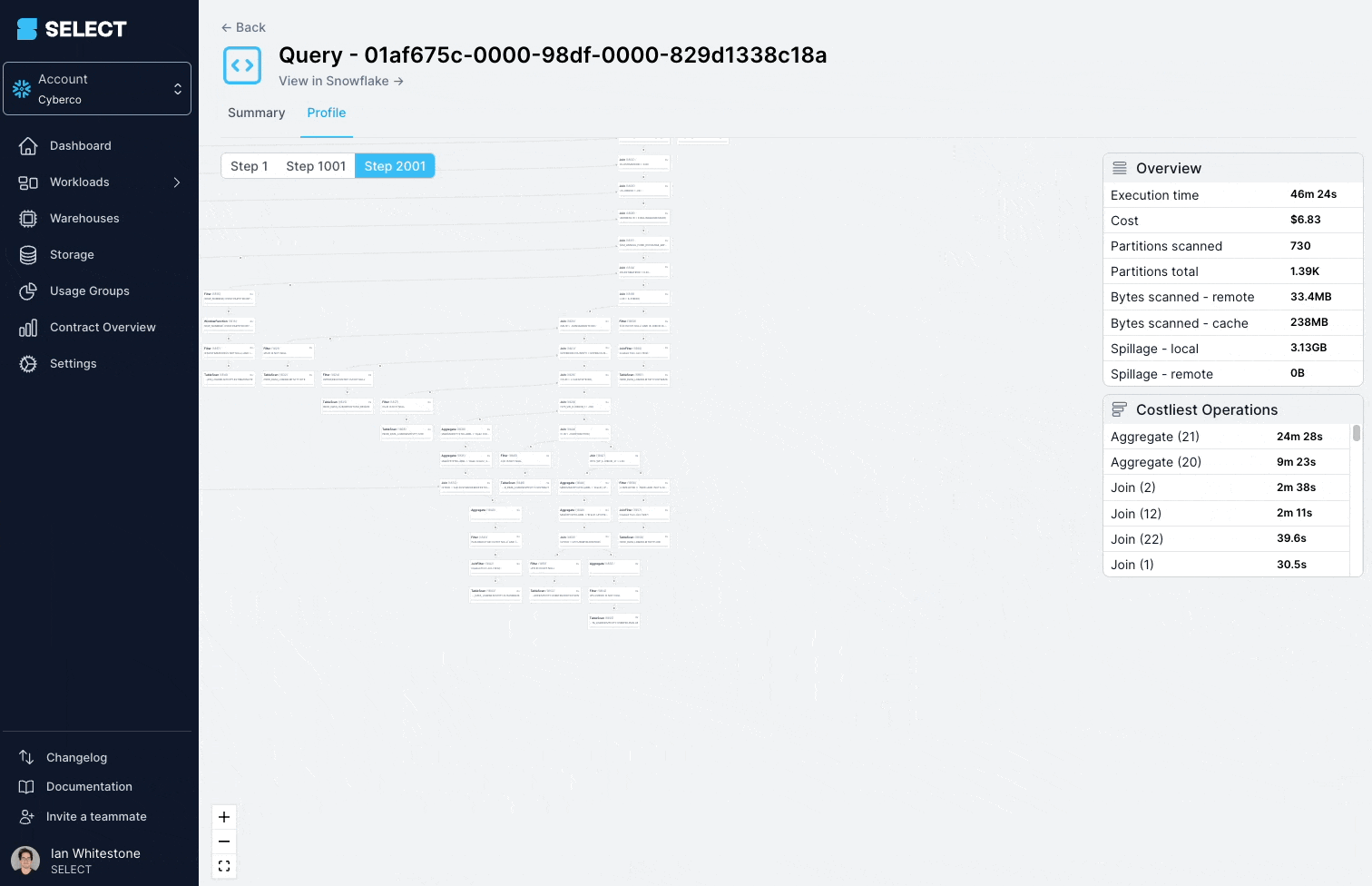
La solution consiste à décomposer la vue complexe en parties plus simples et plus petites, et à les persister sous forme de tables.
13\. Veiller à exploiter efficacement les caches de requêtes
Chaque nœud d'un virtual warehouse dispose d'un stockage disque local qui peut servir à mettre en cache les micro-partitions lues depuis le stockage distant. Si plusieurs requêtes accèdent au même ensemble de données dans une table, elles peuvent scanner ces données depuis le cache disque local plutôt que depuis le stockage distant, ce qui accélère la requête lorsque la lecture des données est le principal goulot d'étranglement.
Lorsque le warehouse se suspend, Snowflake ne garantit pas la persistance du cache à la reprise. La perte du cache oblige les requêtes à re-scanner les données depuis le stockage de la table, au lieu de les lire depuis le cache local, bien plus rapide. Si la perte de cache du warehouse pénalise vos requêtes, augmentez le seuil d'auto-suspend.
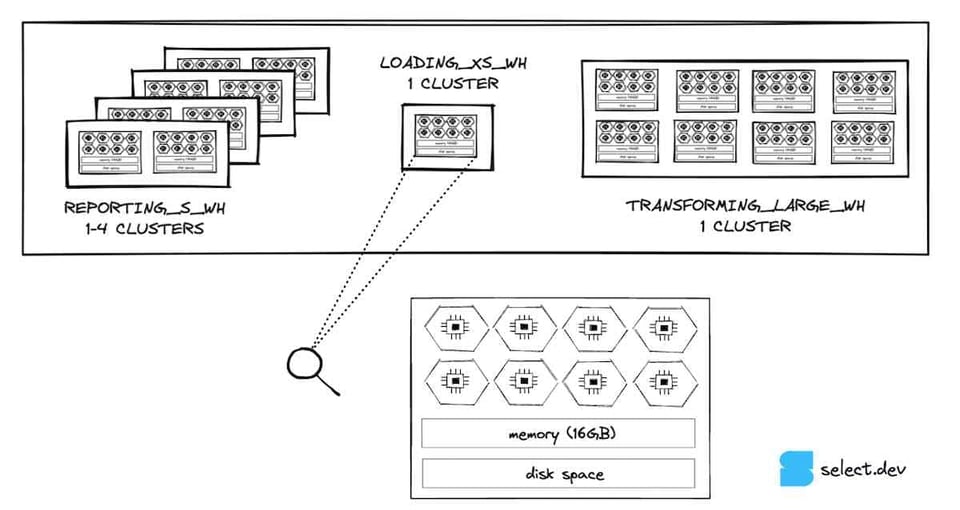
Par ailleurs, Snowflake dispose d'un cache de résultats global, qui renvoie les résultats des requêtes identiques exécutées dans les 24 heures, à condition que les données des tables interrogées soient inchangées. Certaines situations empêchent l'utilisation de ce cache global (par exemple si la requête contient une fonction non déterministe) : vérifiez bien que vous touchez le cache de résultats global quand vous l'attendez. Sinon, il faudra peut-être ajuster votre requête ou contacter le support pour signaler un bug.
14\. Augmenter la taille du warehouse
La taille du warehouse détermine la puissance de calcul totale disponible pour les requêtes qui s'y exécutent, ce qu'on appelle le scaling vertical.
Augmentez la taille du virtual warehouse lorsque :
- Les requêtes débordent sur le disque distant (visible dans le query profile)
- Les résultats des requêtes doivent être obtenus plus rapidement (généralement pour des applications utilisateurs)
Les requêtes qui débordent sur le disque distant s'exécutent inefficacement, en raison des importants volumes de trafic réseau entre le warehouse qui exécute la requête et le disque distant qui stocke les données utilisées. Augmenter la taille du warehouse double à la fois la RAM et le disque local disponibles, bien plus rapides d'accès que le disque distant. En cas de débordement sur disque distant, augmenter la taille du warehouse peut plus que doubler la vitesse d'une requête. Nous avons détaillé le dimensionnement des warehouses Snowflake par le passé, ainsi que la configuration des tailles de warehouse dans dbt.
Si la plupart des requêtes du warehouse ne nécessitent pas une taille supérieure et que vous souhaitez éviter de l'augmenter pour toutes, envisagez plutôt le Query Acceleration Service de Snowflake. Disponible à partir de l'édition Enterprise, ce service apporte des ressources de calcul supplémentaires aux requêtes qui scannent beaucoup de données.
15\. Augmenter le Max Cluster Count
Les warehouses multi-clusters, disponibles à partir de l'édition Enterprise, permettent de créer plusieurs instances d'un warehouse de même taille.
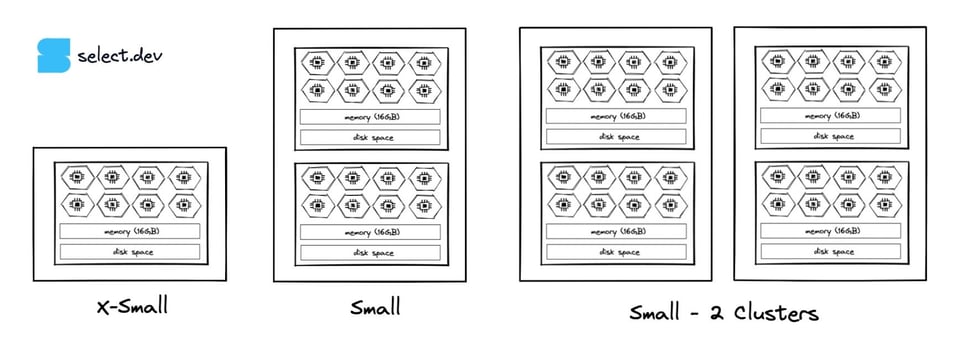
Si, à certaines périodes, la mise en file d'attente (queuing) empêche les requêtes d'atteindre les vitesses de traitement requises, envisagez le multi-clustering ou l'augmentation du nombre maximal de clusters dans un warehouse. Le warehouse pourra ainsi suivre les volumes de requêtes en ajoutant ou retirant des clusters.
Contrairement au nombre de clusters, Snowflake ne peut pas ajuster automatiquement la taille des virtual warehouses en fonction du volume de requêtes. Les warehouses multi-clusters sont donc plus rentables pour traiter des volumes de requêtes volatils, chaque cluster n'étant facturé qu'à l'état actif.
16\. Ajuster la politique de scaling des clusters
Snowflake propose deux politiques de scaling : Standard et Economy. Pour tous les virtual warehouses qui servent des requêtes utilisateurs, utilisez la politique Standard. Si vous êtes très soucieux des coûts, testez la politique Economy sur des workloads tolérants à la mise en file d'attente, comme le chargement de données, pour voir si elle réduit les coûts tout en maintenant le débit requis. Sinon, nous recommandons Standard pour tous les warehouses.
Autres ressources
Si vous cherchez d'autres contenus sur l'optimisation des requêtes Snowflake, nous vous recommandons les ressources vidéo ci-dessous.
Behind the Cape : série en 3 parties sur l'optimisation des coûts Snowflake (2023)
Dans cette série vidéo en 3 parties, Ian a rejoint Keith Belanger, data superhero Snowflake, pour Behind the Cape, une série où des experts Snowflake explorent divers sujets.
Partie 1
Dans cet épisode, nous nous sommes attaqués au vaste sujet de l'optimisation des coûts Snowflake. N'ayant que 30 minutes, la discussion est restée à un niveau assez général : comment se lancer, le modèle de facturation de Snowflake et les outils que Snowflake fournit pour maîtriser les coûts.
Voici la liste complète des sujets abordés :
- Comment se lancer dans l'optimisation des coûts Snowflake ? (En résumé : bâtir une compréhension globale des facteurs de coûts avant de plonger dans les optimisations)
- Où en sont la plupart des clients aujourd'hui dans leur compréhension de l'utilisation de Snowflake
- Comment fonctionne le modèle de facturation de Snowflake (saviez-vous qu'il est en fait moins cher de stocker des données dans Snowflake ?)
- Les outils proposés par Snowflake pour la visibilité sur les coûts
- Les méthodes pour maîtriser les coûts (resource monitors, query timeouts et ACCESS CONTROL — celui auquel personne ne pense !)
- Par où commencer pour réduire les coûts ? Optimiser les requêtes ? Ou prendre de la hauteur ?
- Ressources pour aller plus loin.
Pour celles et ceux qui souhaitent un aperçu de l'optimisation, du monitoring et du contrôle des coûts, c'est un excellent point de départ. La vidéo se trouve ci-dessous. Il y a tellement à dire sur ce sujet et nous n'avons pas pu aller très en profondeur : un suivi s'imposera bientôt !
Play
Partie 2
Dans cet épisode, nous approfondissons des concepts fondamentaux autour de l'optimisation des requêtes Snowflake :
- Le cycle de vie d'une requête Snowflake
- Le dimensionnement des virtual warehouses Snowflake
- Comment utiliser le query profile Snowflake et identifier les goulots d'étranglement
Play
Partie 3
Dans le dernier épisode de la série, nous explorons les techniques d'optimisation de requêtes les plus importantes :
- Comprendre les micro-partitions Snowflake
- Comment tirer parti du query pruning
- Comment s'assurer que vos tables sont efficacement clustérisées
Play
Snowflake Optimization Power Hour (2022)
Le 28 septembre 2022, Ian a donné une présentation au Snowflake Toronto User Group sur le performance tuning et l'optimisation des coûts Snowflake. Les sujets suivants ont été abordés :
- L'architecture Snowflake
- Le cycle de vie d'une requête Snowflake
- Le modèle de facturation de Snowflake
- Un cadre simple pour l'optimisation des coûts, accompagné d'une méthodologie détaillée pour calculer le coût par requête
- Les bonnes pratiques de configuration des warehouses
- Des conseils sur le clustering des tables
Slides
Les slides sont consultables ici. Pour naviguer, cliquez sur les flèches en bas à droite ou utilisez les flèches de votre clavier. Appuyez sur la touche "esc" ou "o" pour passer en mode "overview" et voir toutes les slides. De là, vous pouvez à nouveau naviguer avec les flèches et soit cliquer sur une slide, soit appuyer sur "esc" / "o" pour vous y concentrer.
Enregistrement de la présentation
Un enregistrement de la présentation est disponible sur YouTube. La présentation commence à 3:29.
Play
Si vous le souhaitez, je serai ravi de venir donner cette présentation (ou une variante) à votre équipe, qui pourra alors poser ses questions. Écrivez à [email protected] pour organiser cela.
Query Optimization at Snowflake (2020)
Si vous souhaitez mieux comprendre les rouages internes de l'optimiseur de requêtes Snowflake, je vous recommande vivement cette conférence de Jiaqi Yan, l'un des database engineers les plus expérimentés de Snowflake :
Play
Ian Whitestone·Co-fondateur & CEO de SELECT
Ian est co-fondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de fonder SELECT, Ian a passé 6 ans à diriger des équipes data science et engineering full stack chez Shopify et Capital One. Chez Shopify, Ian a piloté les efforts d'optimisation du data warehouse et l'amélioration de l'observabilité des coûts.
Niall Woodward·Co-fondateur & CTO de SELECT
Niall est co-fondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de fonder SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open source, il est aussi mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.