L'enorme popolarità di Snowflake nasce dalla capacità di elaborare grandi volumi di dati con latenza estremamente bassa e una configurazione minima. Non a caso è il punto di riferimento dei data team di migliaia di organizzazioni. In questa guida condividiamo le tecniche di ottimizzazione per spingere al massimo performance ed efficienza di Snowflake. Segua queste best practice per accelerare le query e al tempo stesso ridurre i costi.
Tutte le tecniche di performance tuning per Snowflake trattate in questo post derivano da strategie concrete che SELECT ha aiutato a implementare presso oltre 100 clienti Snowflake. Se pensa che ci sia qualcosa che abbiamo tralasciato, ci scriva volentieri! Ci contatti via email oppure usi la chat in basso nello schermo.
Questo post tratta le tecniche di ottimizzazione delle query e come sfruttarle per rendere più veloci le query su Snowflake. Anche se questo può contribuire ad abbassare i costi, se è quello il suo obiettivo principale conviene partire da altri punti. Dia un'occhiata al nostro post sull'ottimizzazione dei costi Snowflake per strategie concrete di riduzione dei costi.
Tecniche di ottimizzazione delle query Snowflake
Le tecniche di ottimizzazione delle performance delle query Snowflake illustrate in questo post si possono ricondurre a grandi linee a tre categorie:
1. Migliorare l'efficienza di lettura dei dati
A volte le query impiegano molto tempo nella lettura dei dati dallo storage delle tabelle. Nel query profile questa fase compare come TableScan: un TableScan implica il download dei dati via rete dalla posizione di storage della tabella ai nodi worker del virtual warehouse. Si può accelerare il processo riducendo il volume di dati scaricati oppure aumentando la dimensione del virtual warehouse.
Snowflake legge solo le colonne selezionate in una query e le micro-partizioni rilevanti per i filtri della query, a condizione che le micro-partizioni della tabella siano ben clusterizzate sulla condizione di filtro.
Le quattro tecniche per ridurre i dati scaricati da una query, e quindi accelerare i TableScan, sono:
- Ridurre il numero di colonne lette
- Sfruttare query pruning e clustering delle tabelle
- Usare colonne clusterizzate nei predicati di join
- Usare tabelle pre-aggregate
2. Migliorare l'efficienza di elaborazione dei dati
Operazioni come Join, Sort e Aggregate avvengono a valle dei TableScan e spesso diventano il vero collo di bottiglia delle query. Per ottimizzare l'elaborazione si può ridurre il numero di passaggi della query, elaborare i dati in modo incrementale e sfruttare la propria conoscenza dei dati per migliorare le performance.
Le tecniche per migliorare l'efficienza di elaborazione includono:
- Semplificare e ridurre il numero di operazioni della query
- Ridurre il volume di dati elaborati filtrando il prima possibile
- Evitare riferimenti ripetuti alle CTE
- Rimuovere i sort superflui
- Preferire le window function ai self-join
- Evitare join con condizione OR
- Sfruttare la conoscenza dei dati per aiutare Snowflake a elaborarli in modo efficiente
- Evitare di interrogare viste complesse
- Garantire un uso efficace delle query cache
3. Ottimizzare la configurazione del warehouse
I virtual warehouse di Snowflake si configurano facilmente per supportare workloads più grandi e con maggiore concorrenza. Le configurazioni chiave che migliorano le performance sono:
- Aumentare la dimensione del warehouse
- Aumentare il numero di cluster del warehouse
- Cambiare la policy di scaling del warehouse
Prima di entrare nel merito delle ottimizzazioni, ricordiamo come si individua ciò che sta rallentando una query.
Come ottimizzare una query Snowflake
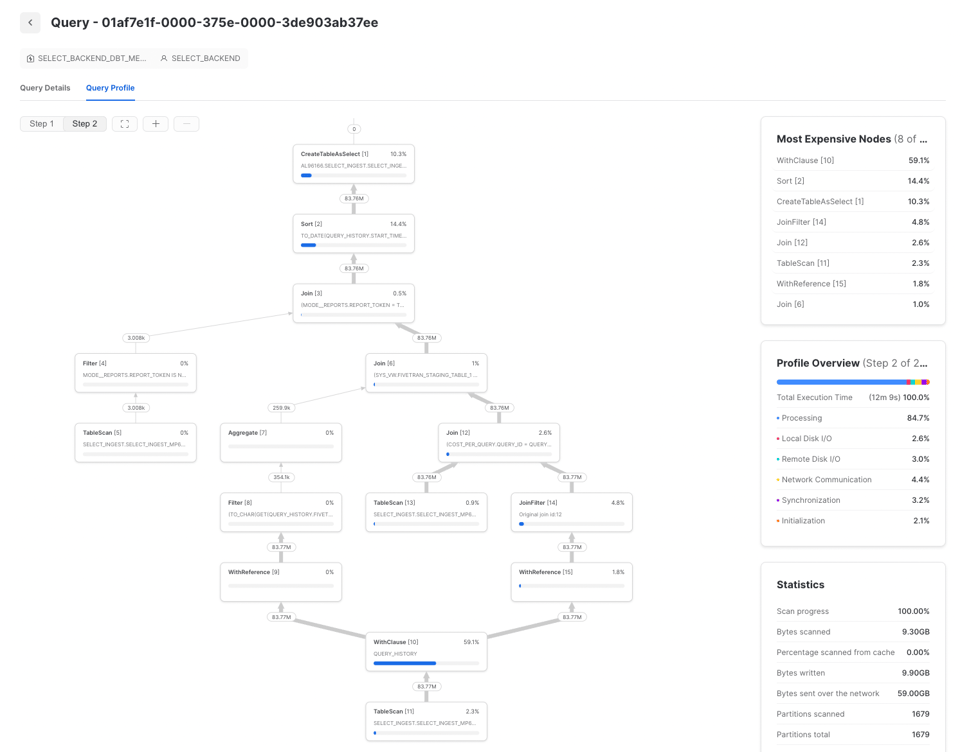
Prima di poter ottimizzare una query Snowflake, è fondamentale capire dove sta il vero collo di bottiglia sfruttando il query profiling. Quali operazioni la rallentano e, di conseguenza, dove conviene concentrare gli sforzi?
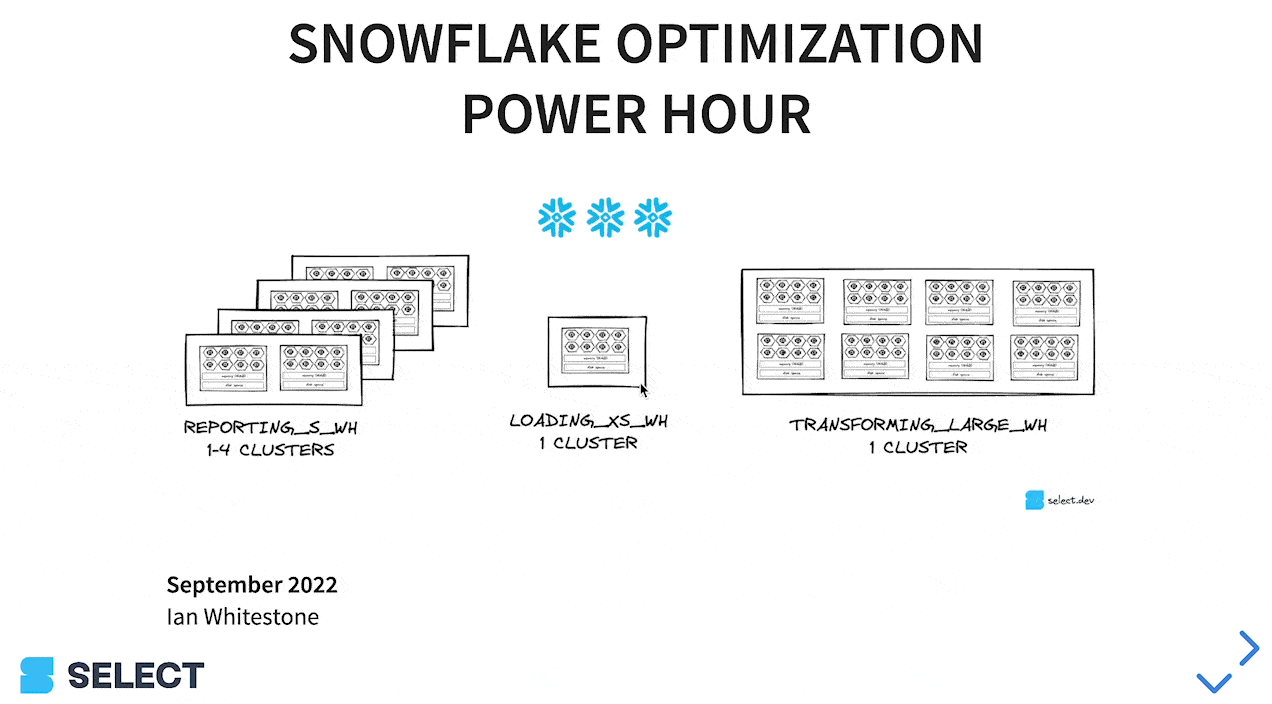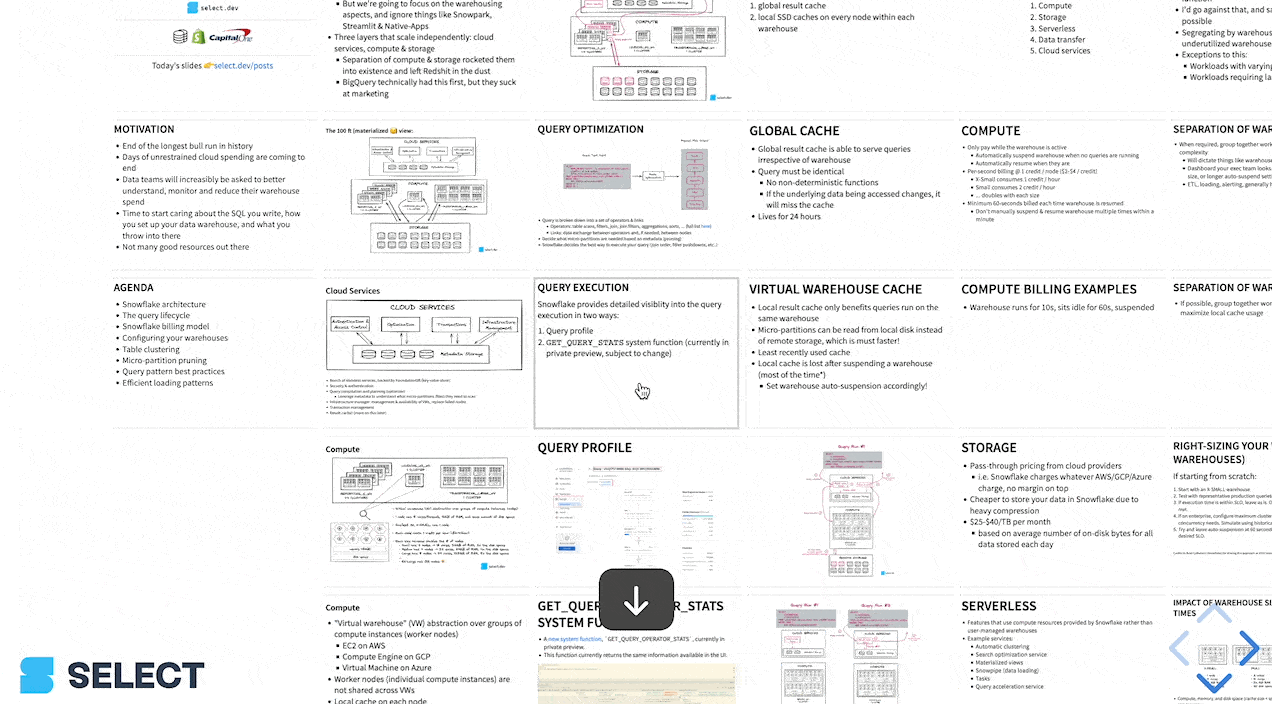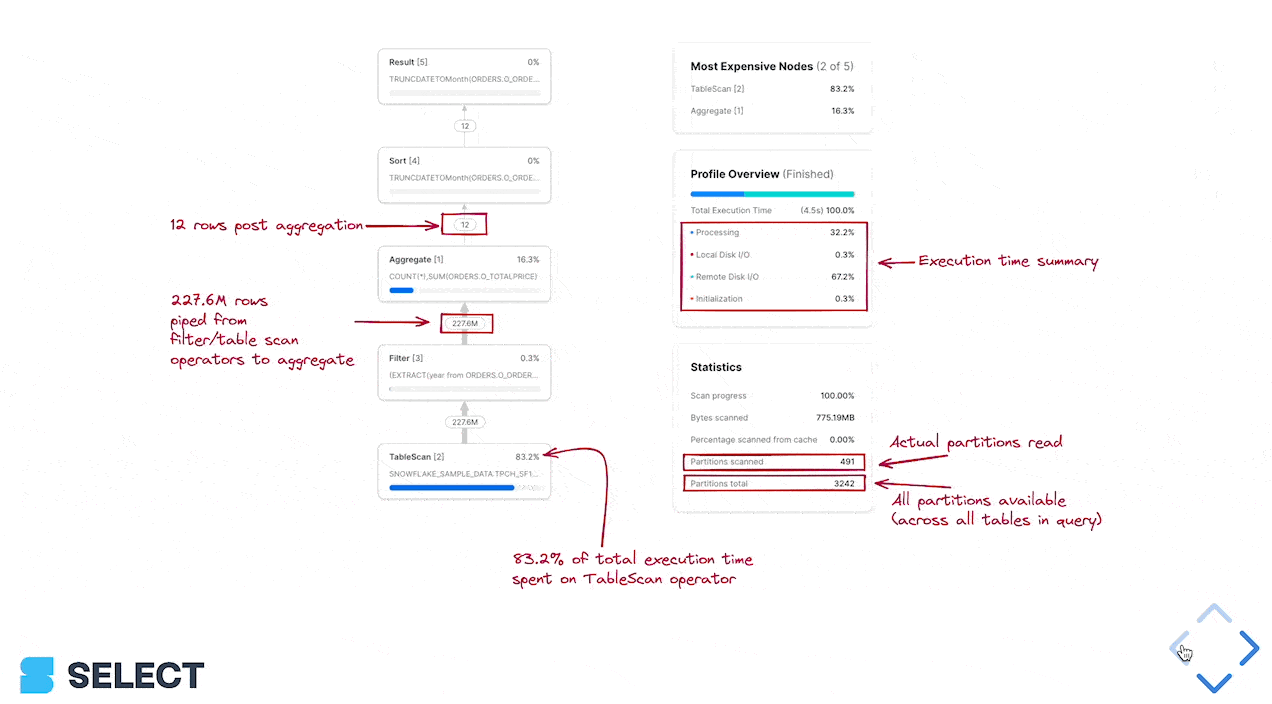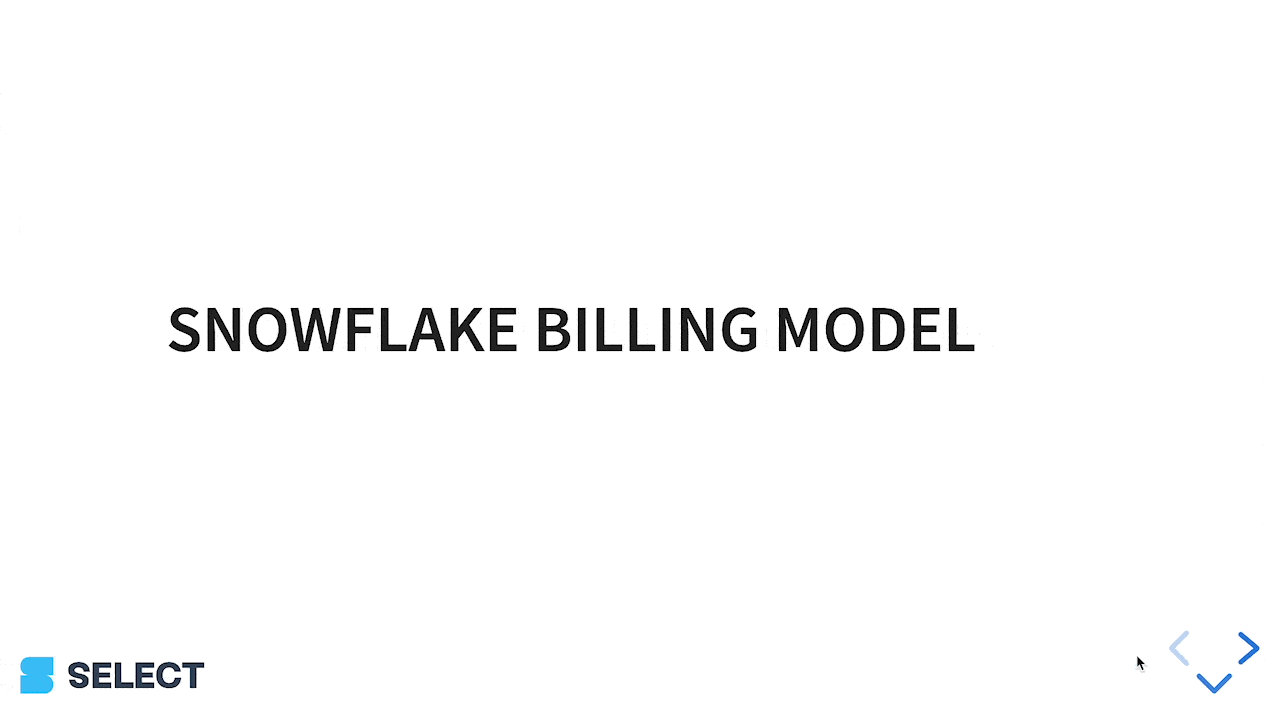
Per scoprirlo, usi il Query Profile di Snowflake (il piano della query) e guardi la sezione 'Most Expensive Nodes'. Le indica quali parti della query stanno consumando la maggior parte del tempo di esecuzione.
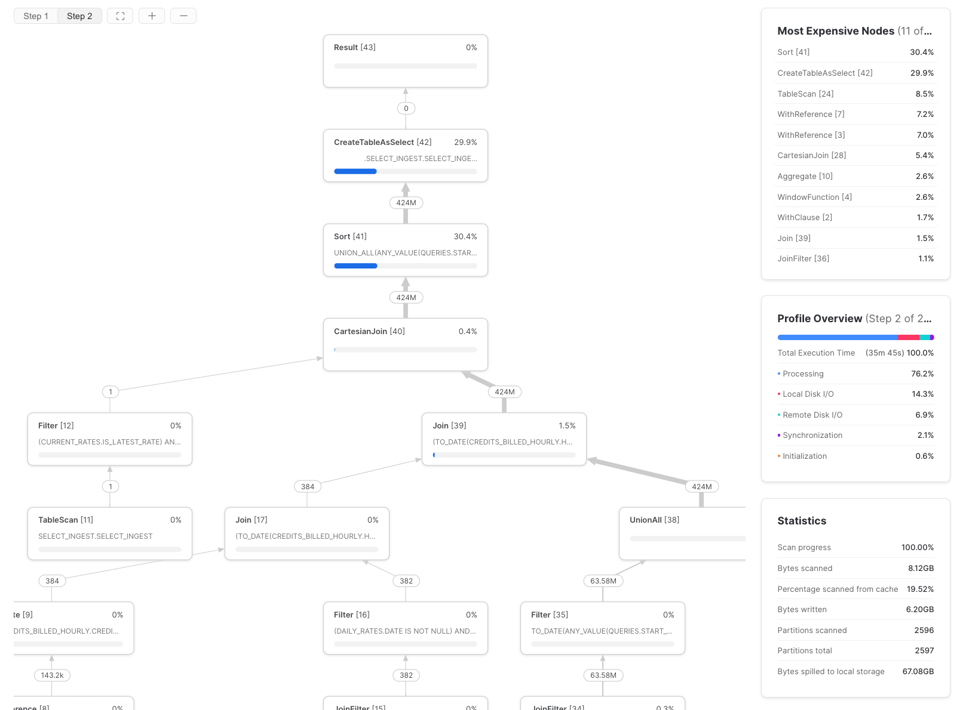
In questo esempio si vede che il collo di bottiglia è la fase di Sort, segnale che conviene puntare sull'efficienza di elaborazione dei dati e, eventualmente, aumentare la dimensione del warehouse. Se invece i nodi più costosi di una query sono TableScans, è meglio dedicare gli sforzi all'ottimizzazione dell'efficienza di lettura dei dati.
1\. Selezionare meno colonne
È un consiglio banale ma, dove possibile, fa una grande differenza. I requisiti delle query cambiano nel tempo e colonne un tempo utili potrebbero non servire più ai processi a valle. Snowflake archivia i dati in un formato di file ibrido a colonne chiamato micro-partizioni. Questo formato consente a Snowflake di limitare la quantità di dati da leggere dallo storage. Il processo di download dei dati delle micro-partizioni si chiama scanning, e ridurre il numero di colonne significa meno dati da trasferire in rete.
2\. Sfruttare il query pruning
Per ridurre il numero di micro-partizioni scansionate da una query — una tecnica nota come query pruning — devono verificarsi alcune condizioni:
- La query deve includere un filtro che limiti i dati richiesti. Può essere un filtro
whereesplicito oppure un filtrojoinimplicito. - La tabella deve essere ben clusterizzata sulla colonna usata per il filtro.
Eseguendo la query seguente sulla tabella ipotetica orders mostrata nel diagramma si ottiene il query pruning, perché (a) la tabella orders è clusterizzata per created_at (i dati sono ordinati per created_at) e (b) la clausola where filtra esplicitamente created_at con una data specifica.
select *
from orders
where created_at > '2022/08/14'

Per capire se le performance del pruning si possono migliorare, osservi le statistiche Partitions scanned e Partitions total nel query profile.
Se in una query non sta usando una clausola where per filtrare, aggiungerla può accelerare in modo significativo il TableScan (e di riflesso i nodi a valle, che elaboreranno meno dati). Se invece la query ha già una clausola where ma le 'Partitions scanned' sono vicine alle 'Partitions total', vuol dire che la clausola where non sta facendo un pruning efficace.
Migliori il pruning così:
- Posizioni le clausole where il più in alto possibile nella query, altrimenti rischiano di non essere 'pushed down' fino al TableScan (questo accelera anche le fasi successive)
- Aggiunga colonne ben clusterizzate alle condizioni di join e merge, così da poter essere pushed down come JoinFilter e abilitare il pruning
- Si assicuri che le colonne usate nei filtri where siano allineate al clustering della tabella (per saperne di più sul clustering clicchi qui)
- Eviti l'uso di funzioni nelle condizioni where: spesso impediscono a Snowflake di fare pruning sulle micro-partizioni
3\. Usare colonne clusterizzate nei predicati di join
La forma di pruning più nota e familiare alla maggior parte degli utenti è il pruning statico. Ecco un esempio semplice, simile a quello visto sopra:
select *
from orders
where order_date > current_date - 7
Se la tabella orders è clusterizzata per order_date, il query optimizer di Snowflake capirà che la maggior parte delle micro-partizioni (i file) con dati più vecchi di 7 giorni può essere ignorata. Poiché la scansione dei dati remoti richiede tempi di elaborazione significativi, eliminare micro-partizioni accelera notevolmente la query.
Una funzionalità meno conosciuta del query engine di Snowflake è il dynamic pruning. A differenza del pruning statico, che avviene prima dell'esecuzione durante la pianificazione della query, il dynamic query pruning si attiva al volo, mentre la query è in esecuzione.
Consideri un processo che aggiorna regolarmente record già presenti nella tabella orders tramite un comando MERGE. Dietro le quinte, un MERGE richiede un join tra la tabella sorgente con i record nuovi o aggiornati e la tabella di destinazione (orders) che si vuole aggiornare.
Il dynamic pruning entra in gioco durante il join. Come funziona? Mentre il query engine di Snowflake legge i dati dalla tabella sorgente, individua il range di record presenti e applica automaticamente un'operazione di filtro sulla tabella di destinazione, evitando scansioni di dati superflue.
Vediamolo con un esempio. Immagini di avere una tabella sorgente con 3 record da aggiornare nella tabella di destinazione orders, clusterizzata per data dell'ordine. Una tipica operazione MERGE confronterebbe i record tra le due tabelle tramite una chiave univoca, come la order key. Poiché di solito queste chiavi univoche sono casuali, non producono alcun query pruning. Se invece si modifica la condizione di MERGE per confrontare i record sia per order key sia per order date, il dynamic query pruning si può attivare. Mentre Snowflake legge i dati dalla tabella sorgente, rileva il range di date coperto dai 3 ordini in aggiornamento e lo applica come filtro sul lato destinazione, evitando di scansionare l'intera tabella, molto grande.

Come applicarlo nel lavoro di tutti i giorni? Se oggi ha operazioni di MERGE o JOIN in cui viene speso molto tempo a scansionare la tabella di destinazione (a destra), valuti se può introdurre predicati aggiuntivi nella clausola di join in grado di forzare il query pruning. Attenzione: funziona solo se (a) la tabella di destinazione è clusterizzata su una chiave e (b) la tabella sorgente (a sinistra) che si sta unendo contiene un range di record strettamente delimitato sulla chiave di clustering (cioè un sottoinsieme di date d'ordine).
Quando si usa una strategia di materializzazione incremental in dbt, dietro le quinte viene eseguita una query MERGE. Per aggiungere una condizione di join in più e forzare il dynamic pruning, aggiorni l'array unique_key includendo la colonna aggiuntiva (per esempio updated_at).
{{ config(
materialized='incremental',
unique_key=['order_id', 'updated_at'],
) }}
select *
from {{ ref('stg_orders') }}
...
4\. Usare tabelle pre-aggregate
Crei tabelle 'rollup' o 'derivate' con meno righe di dati. Le tabelle pre-aggregate possono spesso essere progettate per fornire le informazioni richieste dalla maggior parte delle query occupando meno spazio di storage. Questo le rende molto più veloci da interrogare. Nel retail una strategia diffusa è usare una tabella di rollup giornaliero degli ordini per la reportistica finanziaria e di magazzino, interrogando la tabella grezza degli ordini solo quando serve la granularità per singolo ordine.
5\. Semplificare!
Ogni operazione in una query richiede tempo per spostare i dati tra i worker thread. Consolidare ed eliminare le operazioni superflue riduce il traffico di rete necessario all'esecuzione. Aiuta inoltre Snowflake a riutilizzare i calcoli ed evitare lavoro inutile. Nella maggior parte dei casi CTE e subquery non incidono sulle performance, quindi le usi pure per migliorare la leggibilità.
In generale, far svolgere meno lavoro a ogni query le rende anche più facili da debuggare. Inoltre riduce il rischio che il query optimizer di Snowflake prenda decisioni sbagliate (per esempio scegliere il join order errato).
6\. Ridurre il volume di dati elaborati
Meno dati ci sono, più velocemente si completa ogni fase di elaborazione. Ridurre sia il numero di colonne sia quello di righe processate in ciascun passaggio della query migliora le performance.
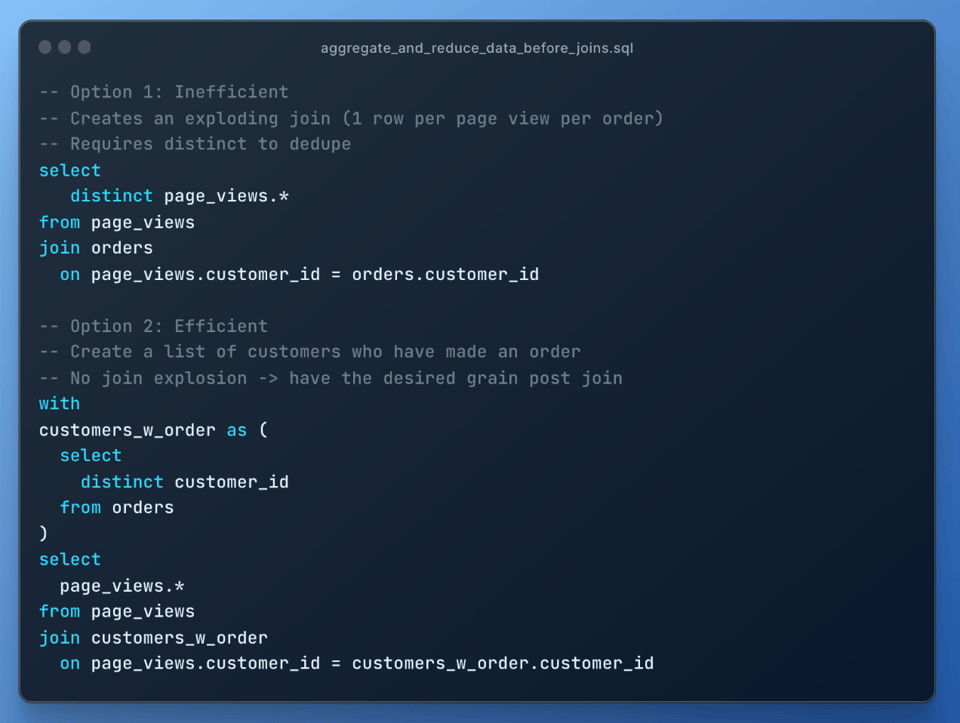
Ecco un esempio in cui anticipare un filtro qualify nella query ha portato a un runtime 3 volte più veloce. Il primo query profile mostra il tempo di esecuzione quando il filtro QUALIFY veniva applicato dopo un join.
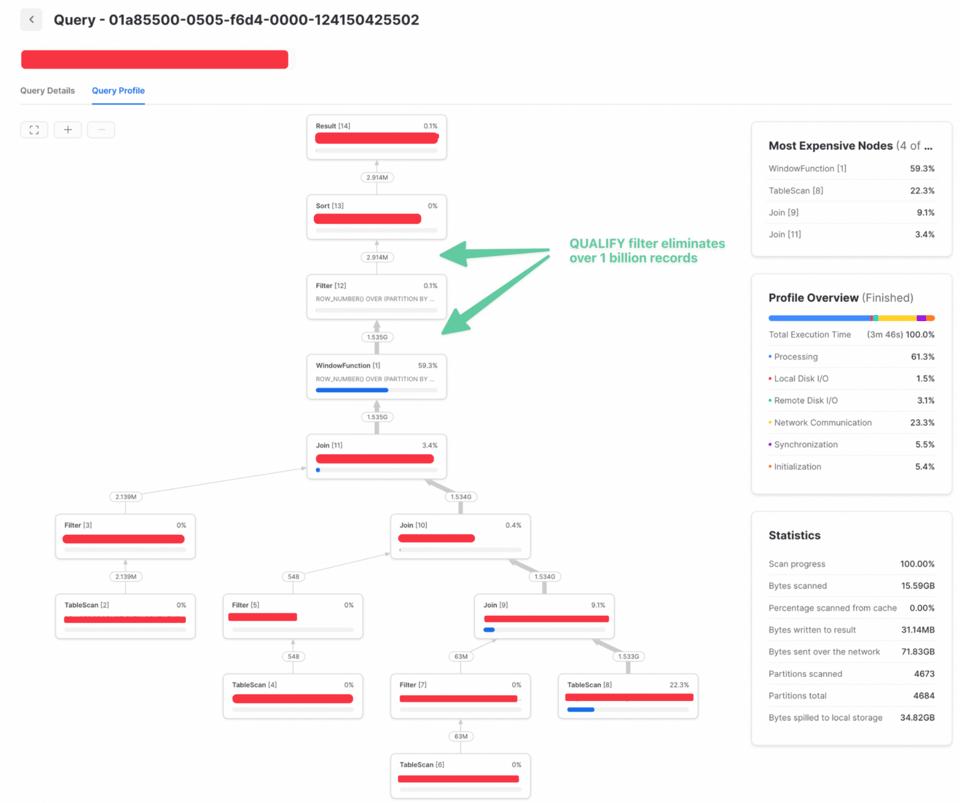
Dato che il filtro QUALIFY non aveva bisogno di informazioni successive al join, è stato possibile spostarlo prima. Risultato: molti meno dati da unire e performance nettamente migliori:
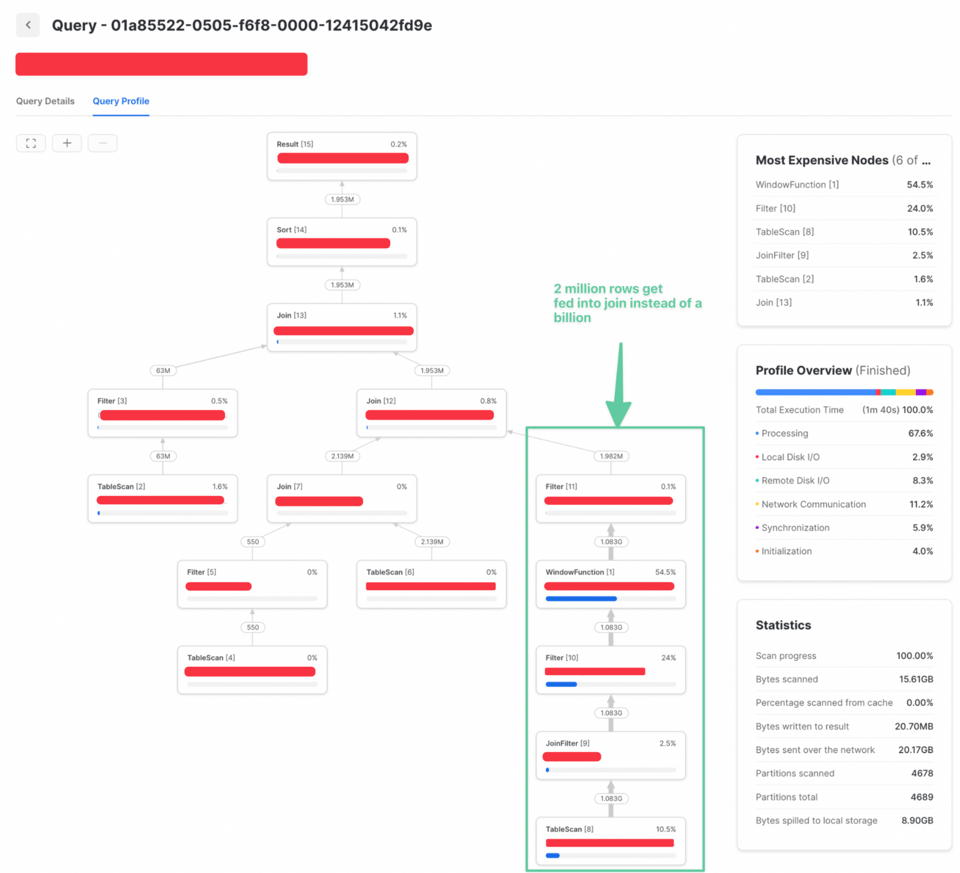
Per le query di trasformazione che scrivono in un'altra tabella, un modo molto efficace per ridurre il volume di dati processati è l'incrementalizzazione. Restando sull'esempio della tabella orders, si potrebbe configurare la query in modo da elaborare solo gli ordini nuovi o aggiornati e fare il merge dei risultati nella tabella esistente.
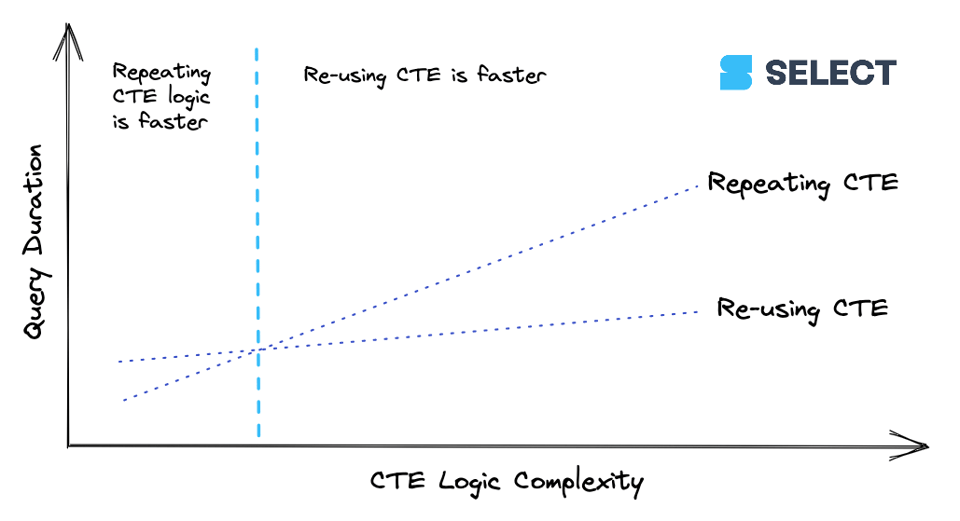
7\. A volte ripetere le CTE è più veloce
Abbiamo già parlato del tema se convenga usare le CTE in Snowflake. Ogni volta che richiama una CTE più di una volta nella query, nel query profile compare un'operazione WithClause (vedi esempio sotto). In certi scenari questo può rallentare la query, e può essere più efficiente riscrivere la CTE ogni volta che serve farvi riferimento.
Quando una CTE raggiunge un certo livello di complessità, conviene calcolarla una volta sola e poi passarne i risultati ai riferimenti a valle, anziché ricalcolarla più volte. Questo comportamento però non è costante, quindi è meglio sperimentare. Ecco un modo per visualizzare la relazione:
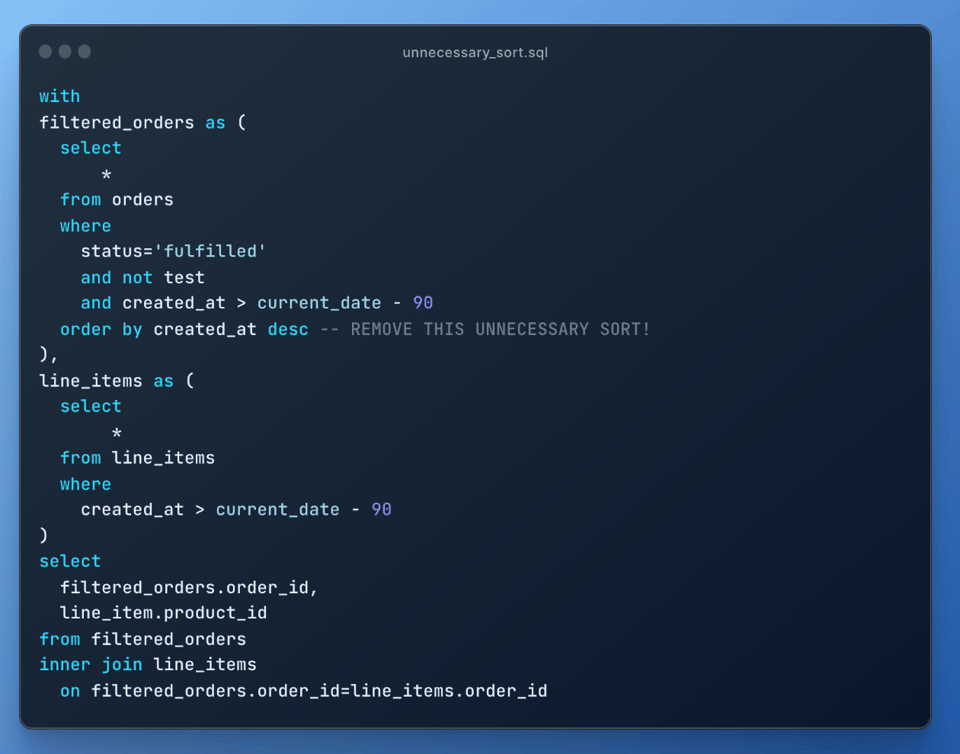
8\. Rimuovere i sort superflui
L'ordinamento è un'operazione costosa: si assicuri di rimuovere tutti i sort non indispensabili:
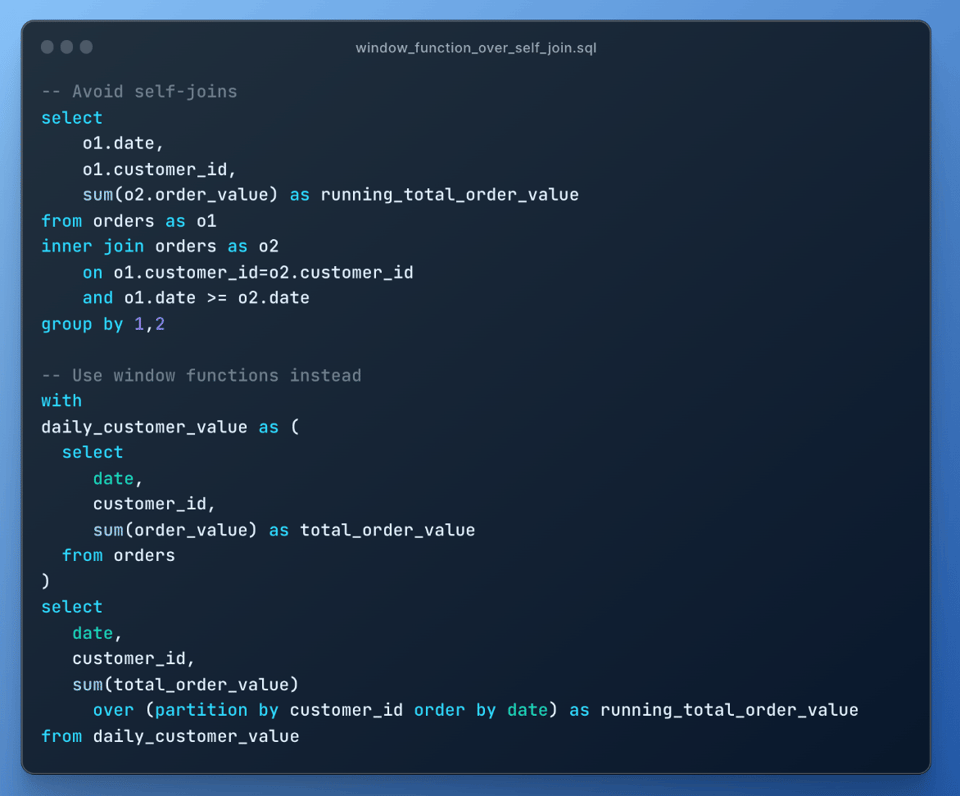
9\. Preferire le window function ai self-join
Anziché ricorrere a un self-join, provi a usare le window function quando possibile: i self-join sono molto costosi perché generano un'esplosione di join:
10\. Evitare join con condizione OR
Come i self-join, anche i join con una condizione OR producono un'esplosione di join, perché vengono eseguiti come join cartesiani con un'operazione di filtro successiva. Usi invece due left join:
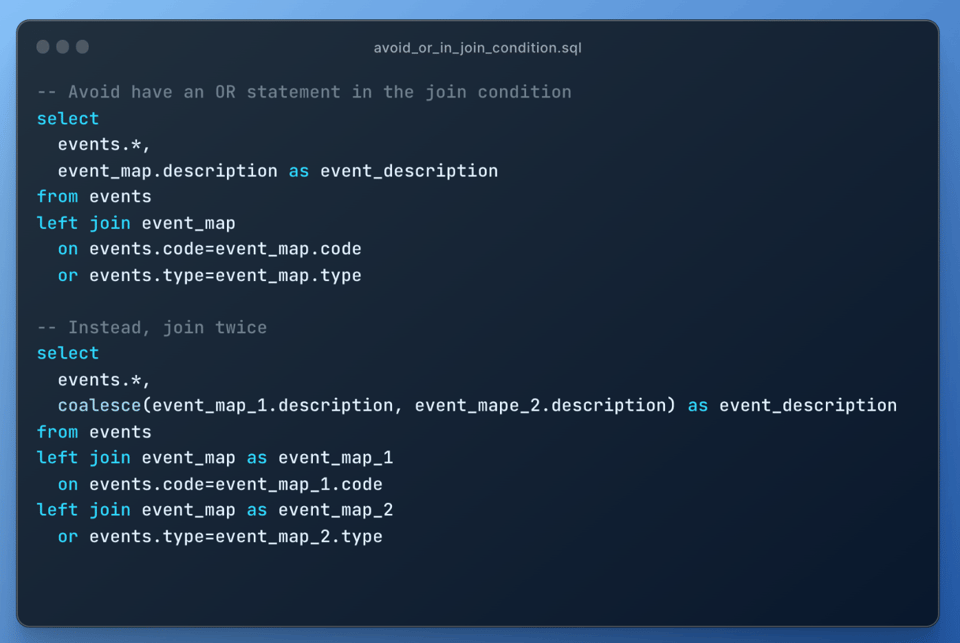
11\. Sfruttare la conoscenza dei dati per aiutare Snowflake a elaborarli in modo efficiente
La conoscenza dei propri dati è un'arma potente per migliorare le performance delle query. Per esempio, se una query raggruppa su molte colonne e lei sa che alcune sono ridondanti perché le altre rappresentano già la stessa granularità o una superiore, può essere più veloce toglierle dal group by e ricollegarle in un passaggio separato.
Se una colonna usata in group by o in join è fortemente skewed (ossia un piccolo numero di valori distinti ricorre con frequenza molto alta), questo può penalizzare la velocità di Snowflake. Un caso tipico è il raggruppamento su una colonna con un numero significativo di valori null. Filtrare le righe con questi valori ed elaborarle in un'operazione separata può rendere la query più rapida.
Infine, i range join sono lenti in tutti i data warehouse, Snowflake compreso. La conoscenza della lunghezza degli intervalli nei dati permette di ridurre l'esplosione di join che ne deriva. Dia un'occhiata al nostro recente post sul tema se riscontra performance lente sui range join.
12\. Evitare le viste complesse
Come best practice, eviti di creare e utilizzare viste complesse nelle sue query. Le viste dovrebbero servire a rendere persistenti trasformazioni semplici dei dati: rinominare colonne, calcoli di base, o modelli di dati con join leggeri.
Per capire quanti danni possa fare una vista complessa, consideri questa query apparentemente innocua:
select
a.*,
b.*
from model_a as a
left join model_b as b
on a.id=b.id
Questa query impiegava ripetutamente oltre 45 minuti e falliva con un "Incident".
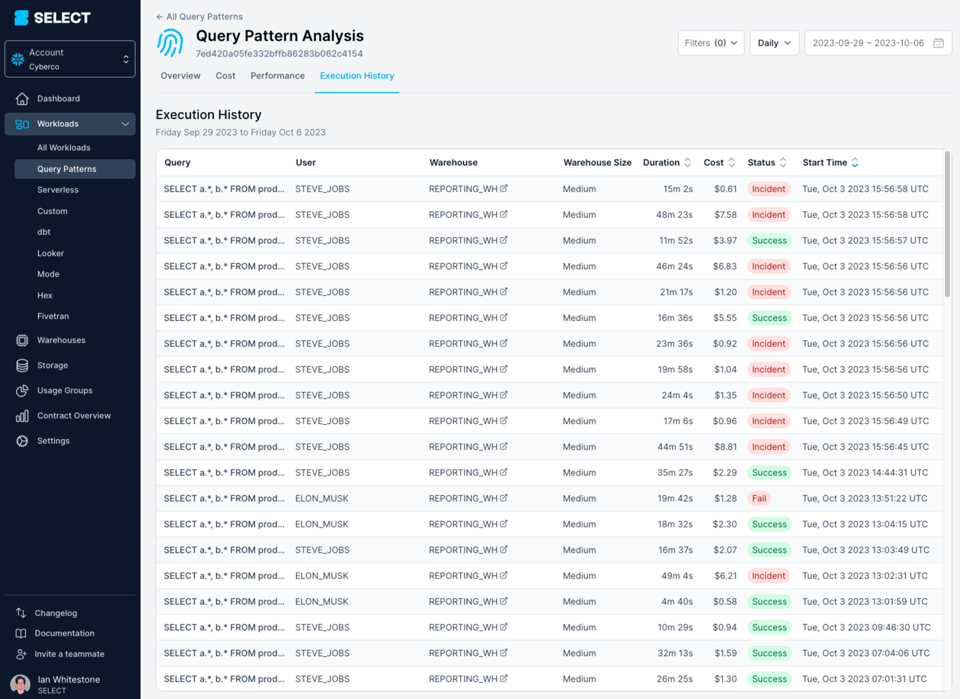
Scavando nel query profile (detto anche "query plan") si vede che i modelli interrogati erano in realtà viste complesse, costruite su centinaia di tabelle.
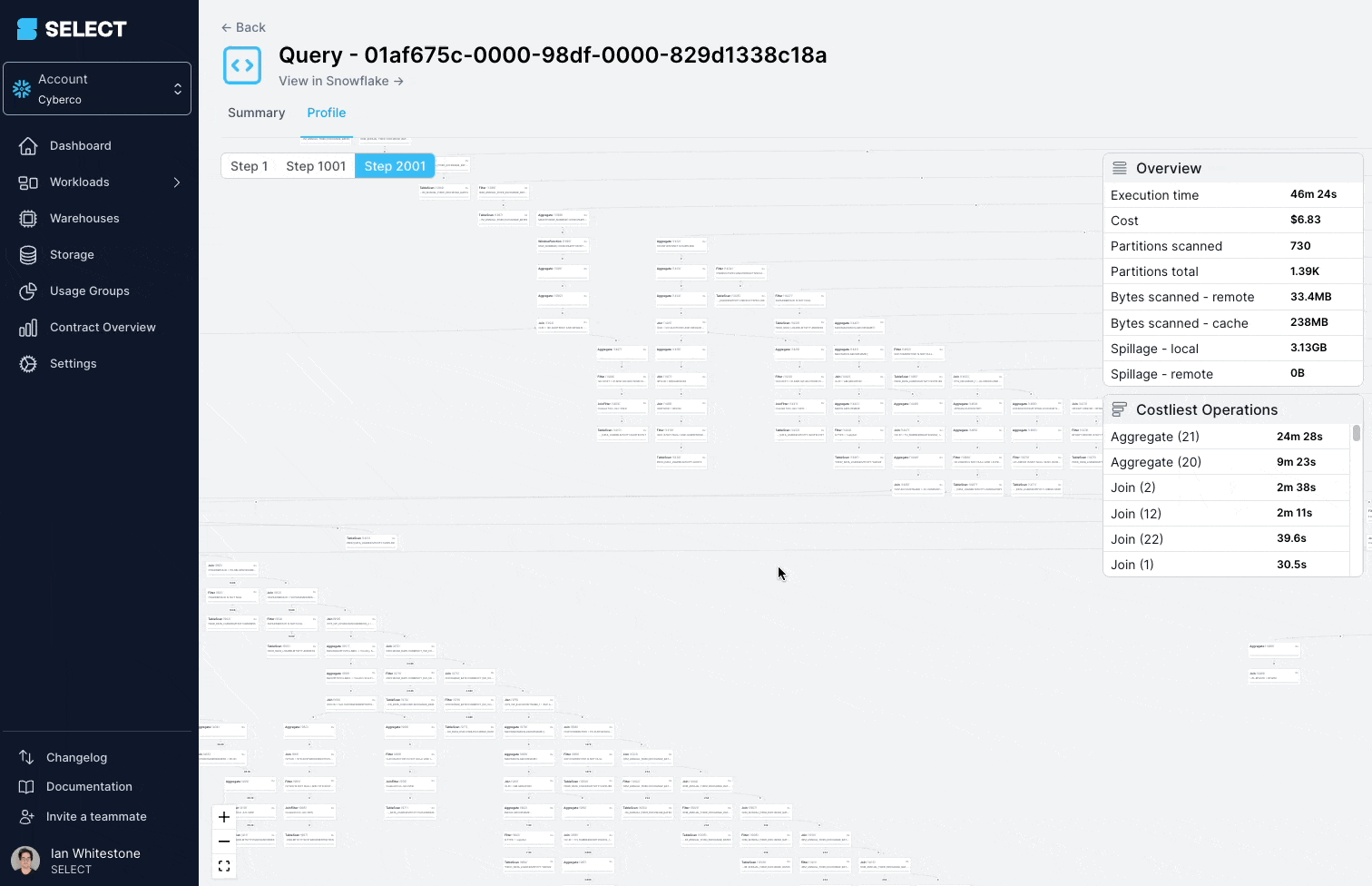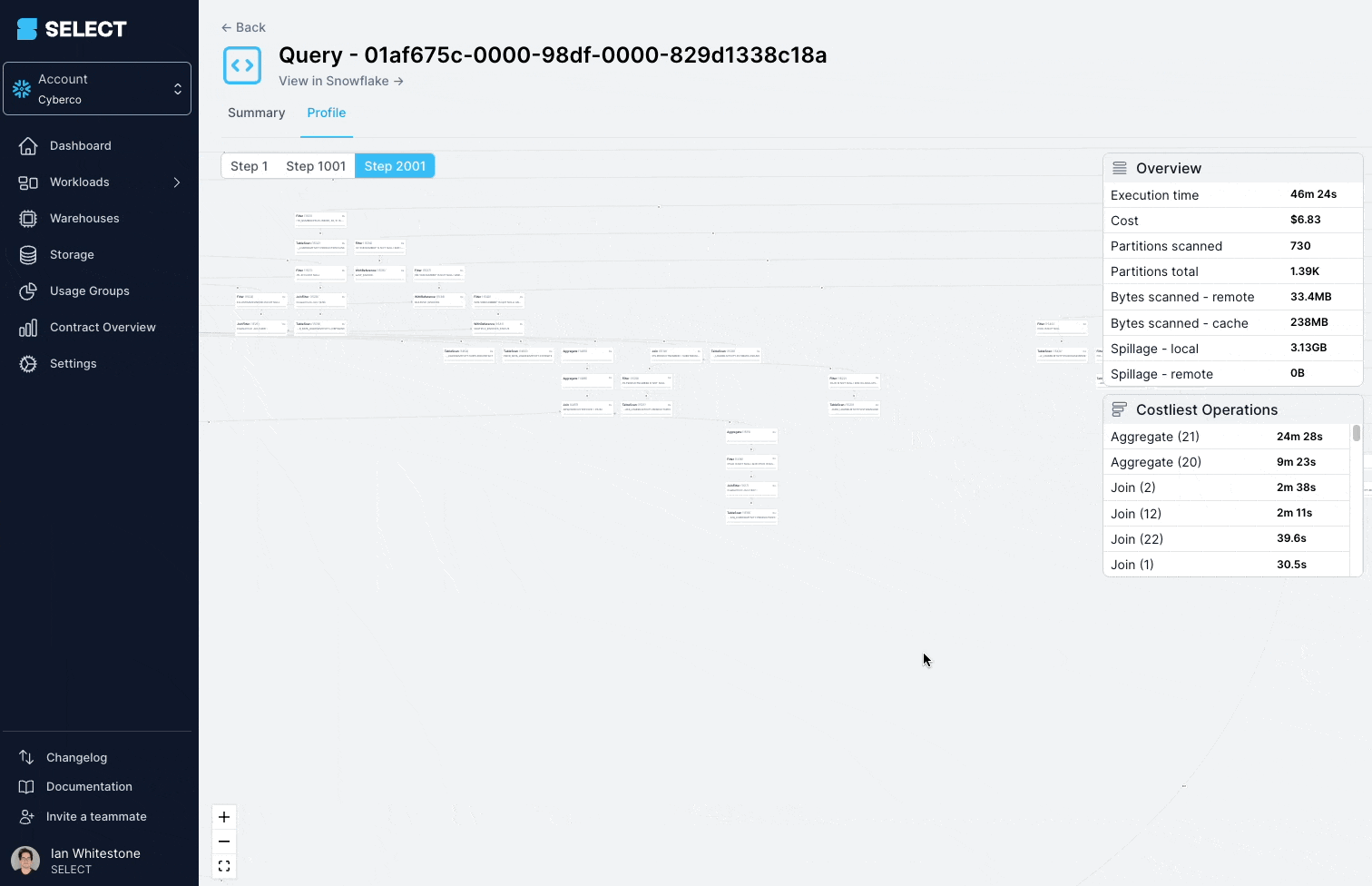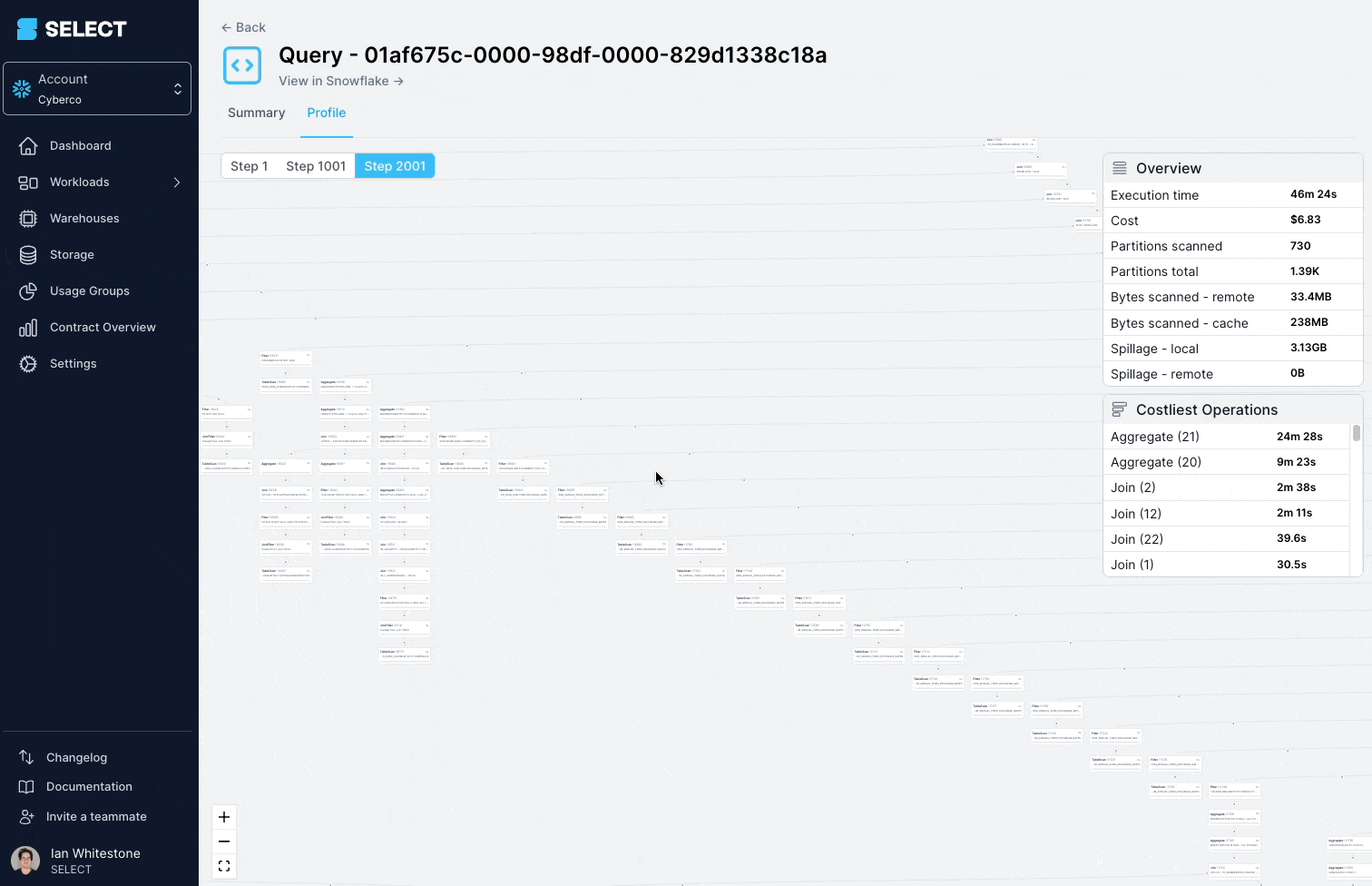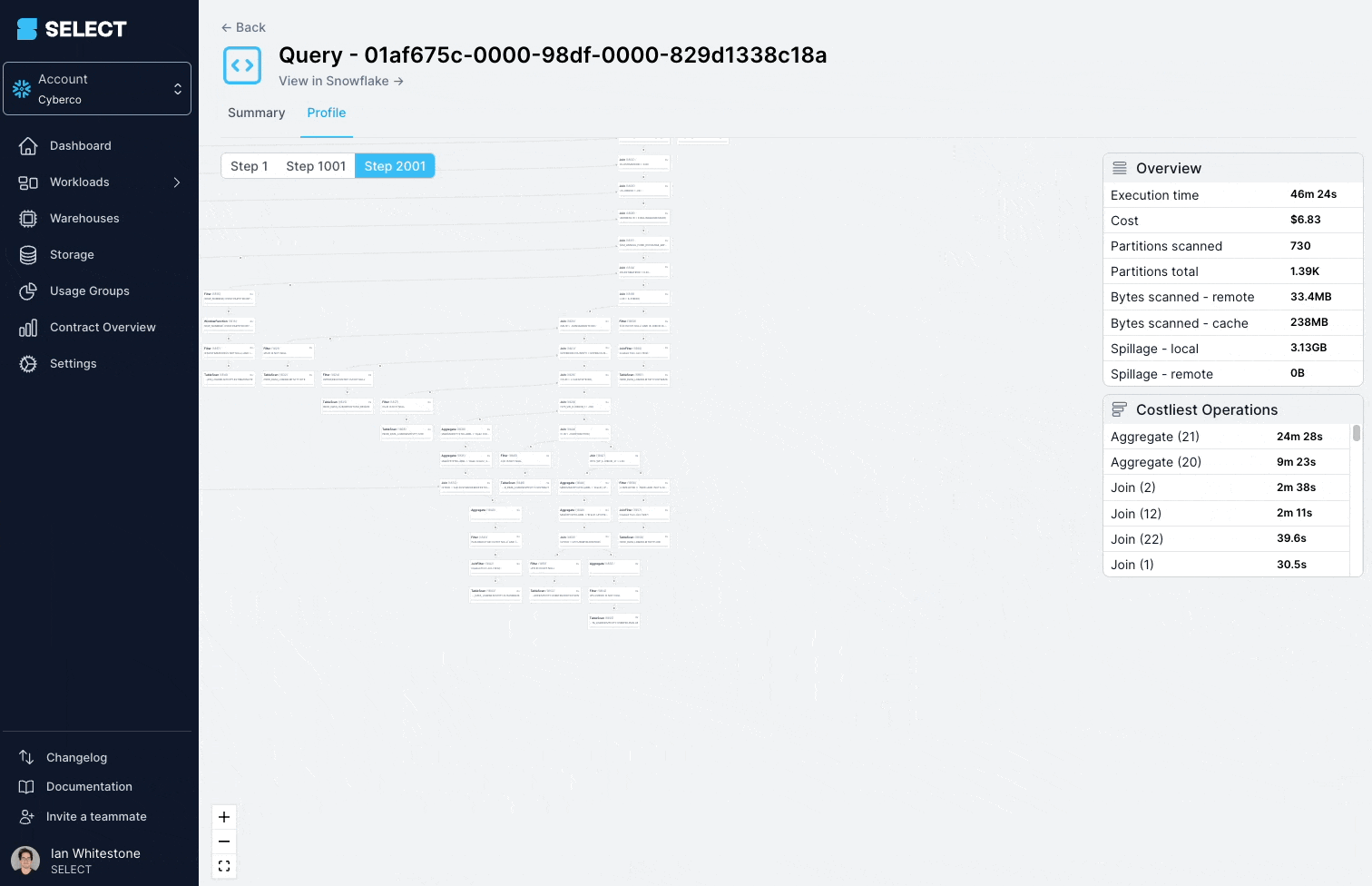
La soluzione è scomporre la vista complessa in parti più piccole e semplici e persisterle come tabelle.
13\. Garantire un uso efficace delle query cache
Ogni nodo di un virtual warehouse dispone di storage su disco locale, utilizzabile come cache delle micro-partizioni lette dallo storage remoto. Se più query accedono allo stesso insieme di dati di una tabella, possono leggerli dalla cache su disco locale invece che dallo storage remoto: un vantaggio notevole quando il collo di bottiglia principale è proprio la lettura dei dati.
Quando il warehouse viene sospeso, Snowflake non garantisce che la cache si conservi al riavvio. La conseguenza è che le query devono riscansionare i dati dallo storage delle tabelle, anziché leggerli dalla cache locale, molto più veloce. Se la perdita di cache del warehouse sta penalizzando le query, aumentare la soglia di auto-suspend può aiutare.
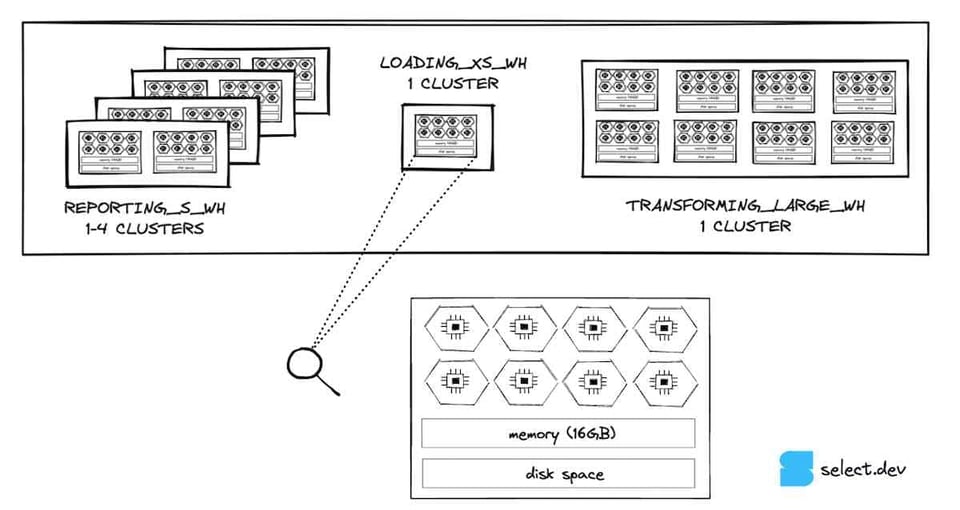
Snowflake dispone inoltre di una global result cache che restituisce i risultati di query identiche eseguite nelle ultime 24 ore, a patto che i dati nelle tabelle interrogate non siano cambiati. Alcune situazioni possono impedire di sfruttare la global result cache (per esempio se la query contiene una funzione non deterministica), quindi verifichi di colpirla quando se lo aspetta. In caso contrario, potrebbe dover modificare la query o contattare il supporto per aprire un bug.
14\. Aumentare la dimensione del warehouse
La dimensione del warehouse determina la potenza computazionale totale a disposizione delle query in esecuzione sul warehouse, cioè il cosiddetto vertical scaling.
Aumenti la dimensione del virtual warehouse quando:
- Le query effettuano spilling su disco remoto (lo si vede dal query profile)
- Servono risultati più rapidi (tipicamente per applicazioni rivolte agli utenti finali)
Le query che fanno spilling su disco remoto sono inefficienti per via dei grandi volumi di traffico di rete tra il warehouse che esegue la query e il disco remoto dove sono memorizzati i dati. Aumentare la dimensione del warehouse raddoppia sia la RAM disponibile sia il disco locale, molto più veloci da accedere rispetto al disco remoto. In presenza di spilling su disco remoto, l'aumento della dimensione del warehouse può più che raddoppiare la velocità di una query. Abbiamo approfondito il dimensionamento dei warehouse Snowflake in passato e abbiamo anche illustrato come configurare la dimensione dei warehouse in dbt.
Nota: se la maggior parte delle query sul warehouse non ha bisogno di un warehouse più grande e vuole evitare di aumentarne la dimensione per tutte, può valutare in alternativa il Query Acceleration Service di Snowflake. Questo servizio, disponibile dalla Enterprise edition in su, fornisce risorse di calcolo aggiuntive alle query che scansionano grandi quantità di dati.
15\. Aumentare il Max Cluster Count
I multi-cluster warehouse, disponibili dalla Enterprise edition in su, permettono di creare più istanze di un warehouse della stessa dimensione.
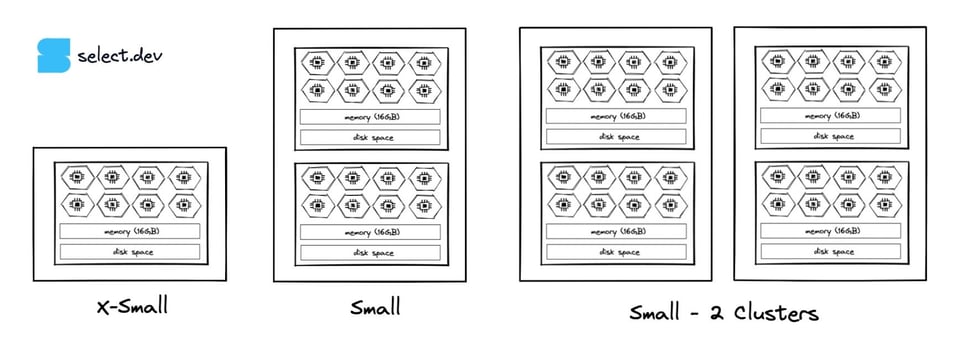
Se ci sono periodi in cui il queuing del warehouse impedisce alle query di raggiungere la velocità di elaborazione richiesta, valuti il multi-clustering o l'aumento del cluster count massimo del warehouse. In questo modo il warehouse potrà seguire i volumi di query aggiungendo o rimuovendo cluster.
A differenza del cluster count, Snowflake non è in grado di adattare automaticamente la dimensione dei virtual warehouse ai volumi di query. Per questo i multi-cluster warehouse risultano più cost-effective quando si gestiscono volumi di query volatili, dato che ogni cluster viene fatturato solo mentre è attivo.
16\. Modificare la Cluster Scaling Policy
Snowflake offre due policy di scaling: Standard ed Economy. Per tutti i virtual warehouse che servono query user-facing, usi la policy Standard. Se è molto attento ai costi, provi la policy Economy sui workloads che tollerano il queuing, come il data loading, per verificare se riduce i costi mantenendo il throughput richiesto. Per tutti gli altri warehouse, consigliamo la Standard.
Altre risorse
Se cerca altri contenuti sull'ottimizzazione delle query Snowflake, le consigliamo di esplorare le risorse video qui sotto.
Behind the Cape: serie in 3 parti sull'ottimizzazione dei costi Snowflake (2023)
In questa serie video in 3 parti, Ian ha incontrato la Snowflake data superhero Keith Belanger per Behind the Cape, la serie in cui esperti di Snowflake approfondiscono i temi più vari.
Parte 1
In questo episodio abbiamo affrontato il tema corposo dell'ottimizzazione dei costi Snowflake. Avendo a disposizione solo 30 minuti, è stata una conversazione di alto livello su come iniziare, sul modello di fatturazione di Snowflake e sugli strumenti che la piattaforma mette a disposizione per controllare i costi.
Ecco l'elenco completo dei temi affrontati:
- Come iniziare con l'ottimizzazione dei costi Snowflake? (TL;DR: costruisca prima una visione complessiva dei suoi cost driver, poi passi all'ottimizzazione)
- A che punto è oggi la maggior parte dei clienti nella comprensione del proprio utilizzo di Snowflake
- Come funziona il modello di fatturazione di Snowflake (sapeva che archiviare i dati in Snowflake è in realtà più economico?)
- Gli strumenti offerti da Snowflake per la visibilità sui costi
- I metodi a disposizione per controllare i costi (resource monitor, query timeout e ACCESS CONTROL — a cui non pensa mai nessuno!)
- Da dove iniziare a tagliare i costi? Dall'ottimizzazione delle query? Oppure da un livello più alto?
- Risorse per approfondire.
Per chi vuole una panoramica su ottimizzazione, monitoraggio e controllo dei costi, è un ottimo punto di partenza. Il video è qui sotto. Su questo tema ci sarebbe tanto da dire e non siamo riusciti ad andare davvero a fondo, quindi a breve faremo un seguito!
Play
Parte 2
In questo episodio approfondiamo alcuni concetti fondamentali sull'ottimizzazione delle query Snowflake:
- Il ciclo di vita di una query Snowflake
- Dimensionamento dei virtual warehouse Snowflake
- Come usare il query profile di Snowflake e individuare i colli di bottiglia
Play
Parte 3
Nell'episodio finale della serie entriamo nel vivo delle tecniche di ottimizzazione delle query più importanti:
- Capire le micro-partizioni Snowflake
- Come sfruttare il query pruning
- Come fare in modo che le sue tabelle siano clusterizzate in modo efficace
Play
Snowflake Optimization Power Hour Video (2022)
Il 28 settembre 2022, Ian ha tenuto una presentazione allo Snowflake Toronto User Group sul performance tuning e sull'ottimizzazione dei costi Snowflake. Sono stati trattati i seguenti contenuti:
- L'architettura di Snowflake
- Il ciclo di vita di una query Snowflake
- Il modello di fatturazione di Snowflake
- Un framework semplice per l'ottimizzazione dei costi, insieme a una metodologia dettagliata per calcolare il costo per query
- Best practice per la configurazione dei warehouse
- Consigli sul clustering delle tabelle
Slide
Le slide sono consultabili qui. Per navigarle, può cliccare sulle frecce in basso a destra oppure usare i tasti freccia della tastiera. Prema "esc" o "o" per fare zoom out e passare alla modalità "overview", dove vedrà tutte le slide. Da lì può nuovamente spostarsi con le frecce e cliccare su una slide oppure premere "esc"/"o" per metterla a fuoco.
Registrazione della presentazione
La registrazione della presentazione è disponibile su YouTube. La presentazione inizia al minuto 3:29.
Play
Se le interessa, sarò felice di tenere questa presentazione (o una sua variante) al suo team, così potrete fare domande dal vivo. Per organizzarla, basta scrivere a [email protected].
Query Optimization at Snowflake (2020)
Se vuole capire meglio come funziona internamente il query optimizer di Snowflake, le consiglio caldamente questo intervento di Jiaqi Yan, uno dei database engineer più senior di Snowflake:
Play
Ian Whitestone·Co-founder & CEO of SELECT
Ian è Co-founder e CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi Snowflake. Prima di fondare SELECT, Ian ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato le iniziative per ottimizzare il data warehouse e aumentare l'osservabilità dei costi.
Niall Woodward·Co-founder & CTO of SELECT
Niall è Co-Founder e CTO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi Snowflake. Prima di fondare SELECT, Niall è stato data engineer in Brooklyn Data Company e in diverse startup. Appassionato di open source, è inoltre maintainer di SQLFluff e creatore di tre pacchetti dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.