La enorme popularidad de Snowflake viene de su capacidad para procesar grandes volúmenes de datos con muy baja latencia y configuración mínima. Por eso se ha consolidado como el favorito de los equipos de datos en miles de organizaciones. En esta guía compartimos técnicas de optimización para llevar el rendimiento y la eficiencia de Snowflake al máximo nivel. Sigue estas mejores prácticas para que tus queries corran más rápido y, de paso, reduzcas costos.
Todas las técnicas de performance tuning de Snowflake que se cubren en este post se basan en estrategias reales que SELECT ha implementado con más de 100 clientes de Snowflake. Si crees que se nos quedó algo en el tintero, ¡nos encantaría saberlo! Escríbenos por correo o usa el chat en la parte inferior de la pantalla.
Este post se enfoca en técnicas de optimización de queries y en cómo aprovecharlas para que tus queries de Snowflake corran más rápido. Si bien esto puede ayudar a bajar costos, hay mejores puntos de partida si ese es tu objetivo principal. Revisa nuestro post sobre optimización de costos en Snowflake para conocer estrategias accionables que te ayudarán a reducir gastos.
Técnicas de optimización de queries en Snowflake
Las técnicas de optimización de performance de queries en Snowflake que se cubren en este post se agrupan, a grandes rasgos, en tres categorías:
1. Mejorar la eficiencia en la lectura de datos
A veces las queries dedican un tiempo considerable a leer datos desde el almacenamiento de las tablas. Este paso aparece como un TableScan en el query profile. Un TableScan implica descargar datos por la red, desde la ubicación de almacenamiento de la tabla hacia los nodos worker del virtual warehouse. Este proceso se puede acelerar reduciendo el volumen de datos descargados o aumentando el tamaño del virtual warehouse.
Snowflake solo lee las columnas seleccionadas en una query y las micro-particiones relevantes para los filtros de esa query, siempre que las micro-particiones de la tabla estén bien clusterizadas según la condición de filtro.
Las cuatro técnicas para reducir los datos descargados por una query y, por lo tanto, acelerar los TableScans son:
- Reducir el número de columnas accedidas
- Aprovechar el query pruning y el clustering de tablas
- Usar columnas clusterizadas en los predicados de join
- Usar tablas pre-agregadas
2. Mejorar la eficiencia en el procesamiento de datos
Las operaciones como Joins, Sorts y Aggregates ocurren después de los TableScans y suelen convertirse en el cuello de botella de las queries. Las estrategias para optimizar el procesamiento de datos incluyen reducir la cantidad de pasos de la query, procesar los datos de forma incremental y aprovechar tu conocimiento de los datos para mejorar el rendimiento.
Algunas técnicas para mejorar la eficiencia del procesamiento de datos son:
- Simplificar y reducir el número de operaciones en la query
- Reducir el volumen de datos procesados filtrando temprano
- Evitar referencias repetidas a CTEs
- Eliminar sorts innecesarios
- Preferir funciones de ventana sobre self-joins
- Evitar joins con una condición OR
- Usar tu conocimiento de los datos para ayudar a Snowflake a procesarlos de forma eficiente
- Evitar consultar vistas complejas
- Asegurar un uso efectivo de los cachés de queries
3. Optimizar la configuración del warehouse
Los virtual warehouses de Snowflake se configuran fácilmente para soportar workloads más grandes y de mayor concurrencia. Las configuraciones clave que mejoran el rendimiento son:
- Aumentar el tamaño del warehouse
- Aumentar el número de clusters del warehouse
- Cambiar la política de escalado del warehouse
Antes de entrar en las optimizaciones, recordemos primero cómo identificar qué está ralentizando una query.
Cómo optimizar una query de Snowflake
Antes de optimizar una query de Snowflake es importante entender cuál es el verdadero cuello de botella, y para eso se aprovecha el query profiling. ¿Qué operaciones la están ralentizando y en qué deberías enfocar tus esfuerzos?
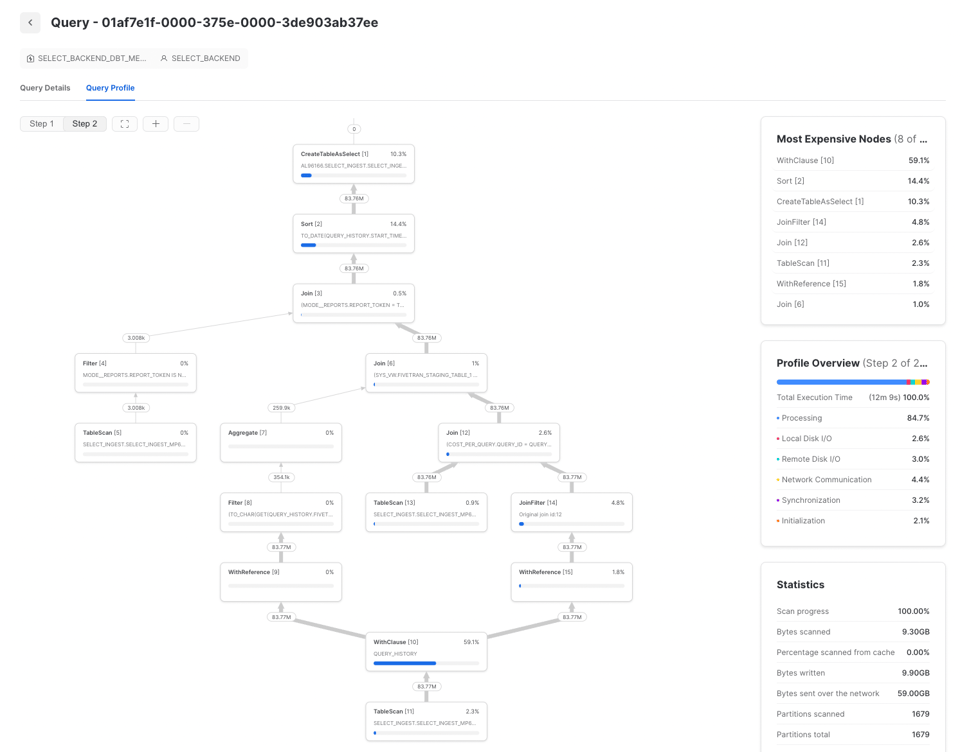
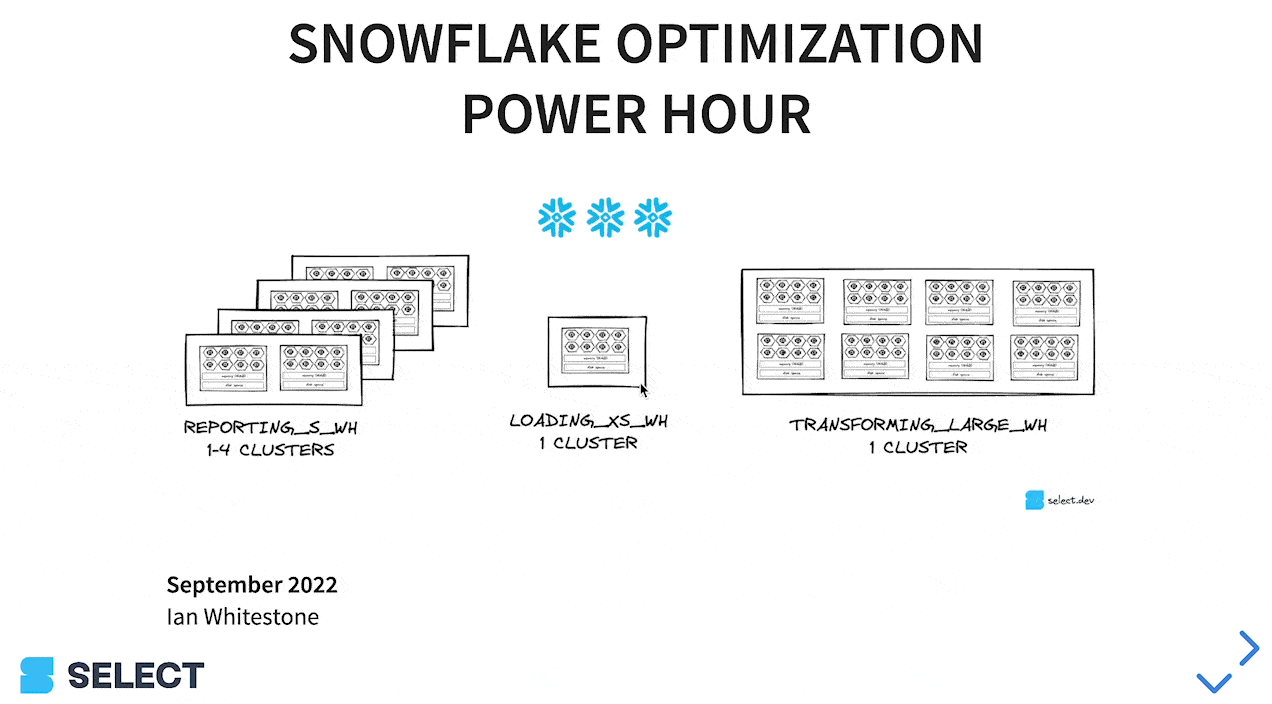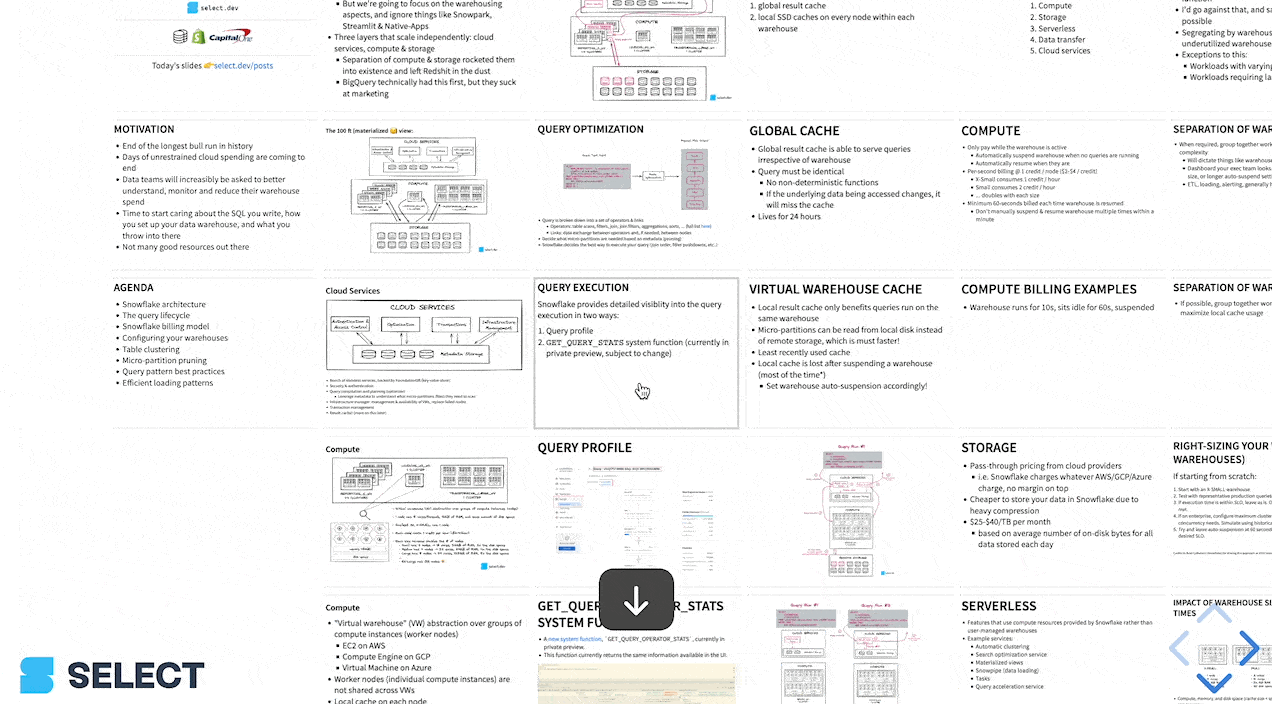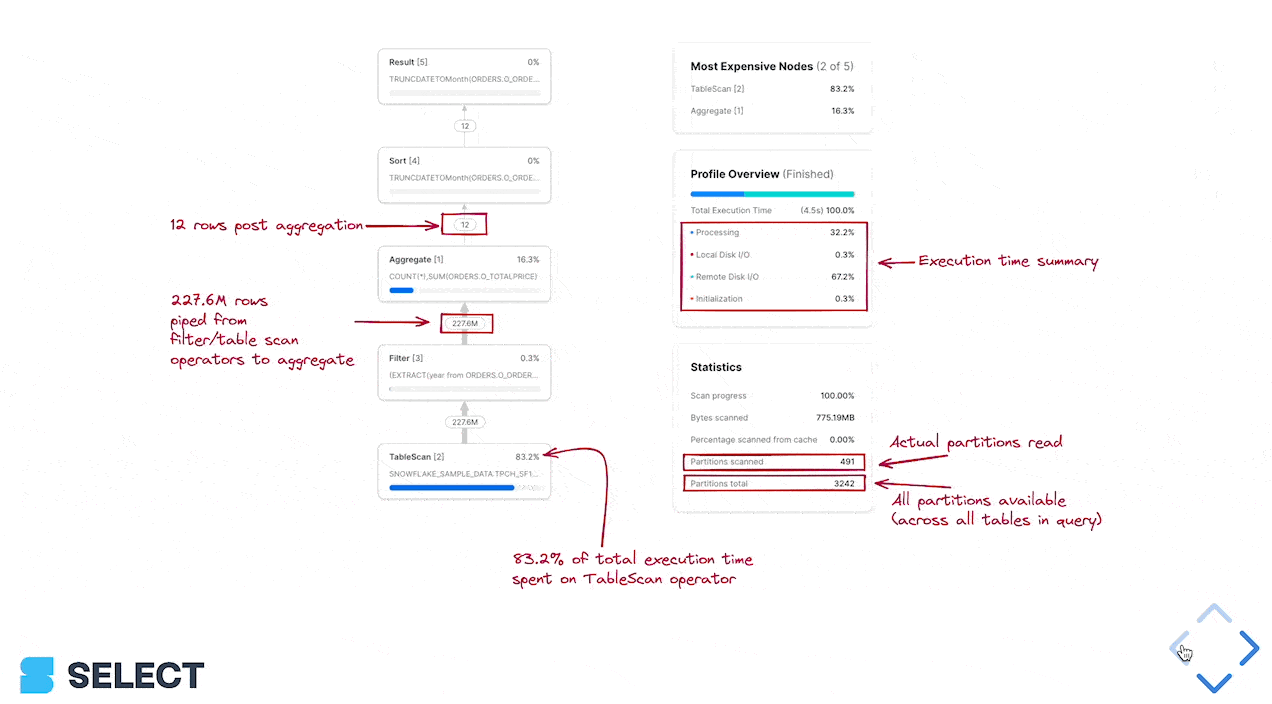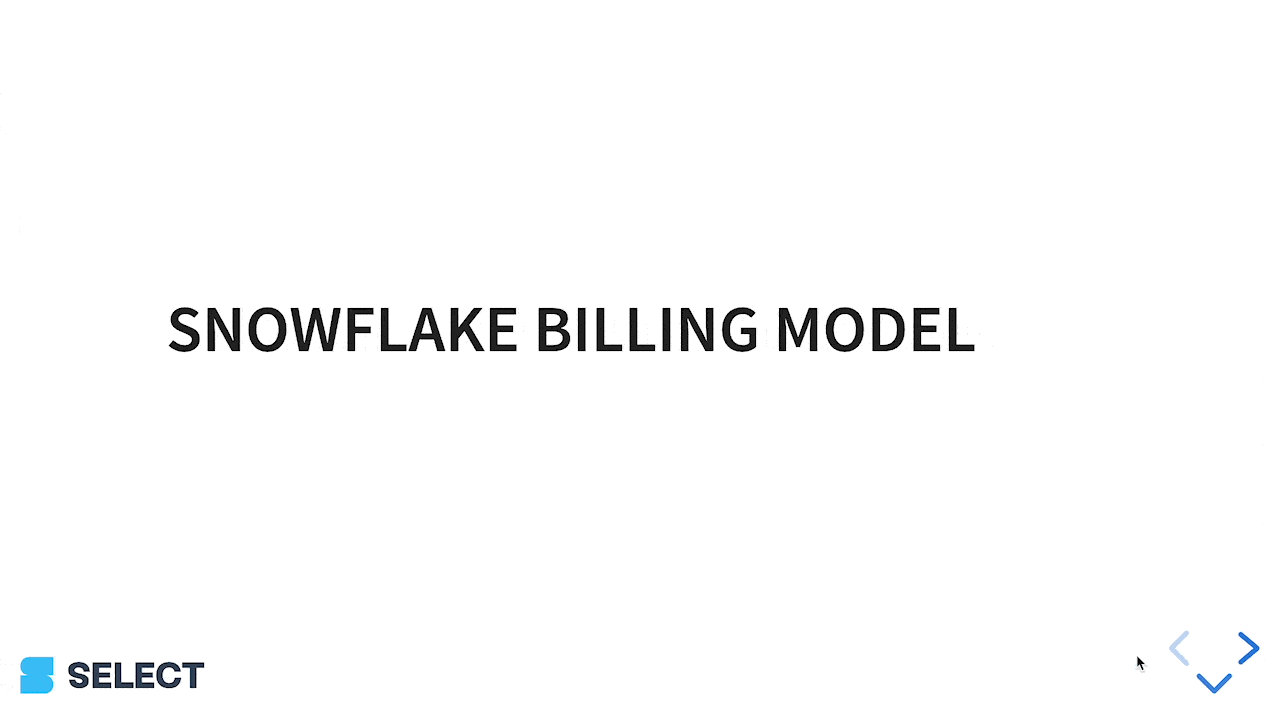
Para averiguarlo, usa el Query Profile (plan de la query) de Snowflake y revisa la sección 'Most Expensive Nodes'. Allí se indica qué partes de la query consumen más tiempo de ejecución.
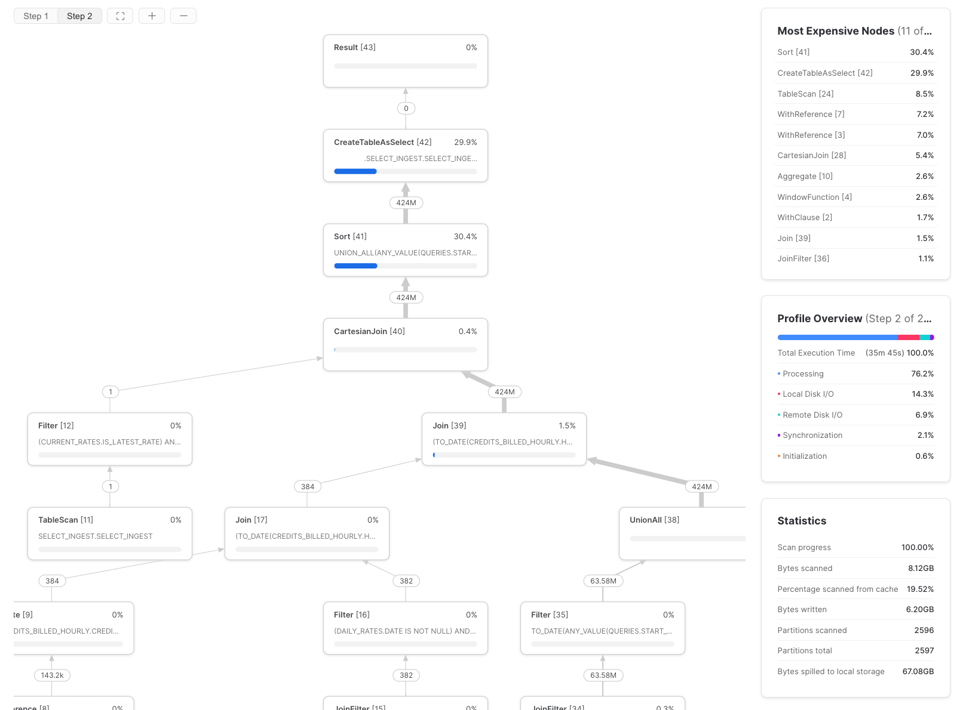
En este ejemplo vemos que el cuello de botella es el paso de Sort, lo que indica que deberíamos enfocarnos en mejorar la eficiencia del procesamiento de datos y, posiblemente, aumentar el tamaño del warehouse. Si los nodos más costosos de una query son TableScans, lo más conveniente será optimizar la eficiencia de lectura de los datos.
1\. Selecciona menos columnas
Es algo sencillo, pero cuando se puede aplicar marca una gran diferencia. Los requisitos de las queries cambian con el tiempo, y columnas que antes eran útiles pueden dejar de ser necesarias para los procesos downstream. Snowflake almacena los datos en un formato de archivo híbrido-columnar llamado micro-particiones. Este formato le permite a Snowflake reducir la cantidad de datos que debe leer del almacenamiento. El proceso de descargar datos de micro-particiones se llama scanning, y reducir el número de columnas implica menos transferencia de datos por la red.
2\. Aprovecha el query pruning
Para reducir la cantidad de micro-particiones que escanea una query (una técnica conocida como query pruning), deben darse algunas condiciones:
- Tu query debe incluir un filtro que limite los datos requeridos. Puede ser un filtro explícito
whereo uno implícito víajoin. - Tu tabla debe estar bien clusterizada según la columna usada para filtrar.
Ejecutar la siguiente query contra la tabla hipotética orders del diagrama producirá query pruning porque (a) la tabla orders está clusterizada por created_at (los datos están ordenados por created_at) y (b) la cláusula where filtra explícitamente created_at con una fecha específica.
select *
from orders
where created_at > '2022/08/14'

Para saber si se puede mejorar el rendimiento del pruning, revisa en el query profile las estadísticas Partitions scanned y Partitions total.
Si tu query no tiene un filtro con cláusula where, agregar uno puede acelerar significativamente el TableScan (y también los nodos downstream, ya que procesan menos datos). Si tu query ya tiene un filtro where pero el valor de 'Partitions scanned' es cercano al de 'Partitions total', significa que el filtro no está logrando un pruning efectivo.
Para mejorar el pruning:
- Asegúrate de que las cláusulas where se ubiquen lo antes posible en las queries; de lo contrario, podrían no aplicarse ("push down") sobre el paso de TableScan (esto también acelera los pasos posteriores).
- Agrega columnas bien clusterizadas a las condiciones de join y merge, para que puedan empujarse como JoinFilters y habilitar el pruning.
- Asegúrate de que las columnas usadas en los filtros where de una query estén alineadas con el clustering de la tabla (aprende más sobre clustering aquí).
- Evita el uso de funciones en las condiciones where; suelen impedir que Snowflake aplique pruning a las micro-particiones.
3\. Usa columnas clusterizadas en los predicados de join
La forma de pruning más común, y con la que la mayoría de los usuarios está familiarizada, es el static query pruning. Aquí va un ejemplo simple, similar al anterior:
select *
from orders
where order_date > current_date - 7
Si la tabla orders está clusterizada por order_date, el optimizador de Snowflake reconocerá que la mayoría de las micro-particiones (archivos) con datos de hace más de 7 días se pueden ignorar. Como escanear datos remotos toma un tiempo de procesamiento considerable, descartar micro-particiones acelera mucho la query.
Una funcionalidad menos conocida del motor de queries de Snowflake es el dynamic pruning. A diferencia del static pruning, que se aplica antes de la ejecución durante la fase de planificación, el dynamic query pruning ocurre al vuelo, mientras la query se está ejecutando.
Imagina un proceso que actualiza con frecuencia registros existentes en la tabla orders mediante un comando MERGE. Por debajo, un MERGE requiere un join entre la tabla fuente (con los registros nuevos o actualizados) y la tabla destino (orders) que queremos actualizar.
El dynamic pruning entra en acción durante el join. ¿Cómo funciona? A medida que el motor de queries de Snowflake lee los datos de la tabla fuente, identifica el rango de registros presentes y empuja automáticamente una operación de filtro hacia la tabla destino para evitar escaneos de datos innecesarios.
Veámoslo con un ejemplo. Supongamos que tenemos una tabla fuente con 3 registros que debemos actualizar en la tabla destino orders, la cual está clusterizada por order date. Un MERGE típico haría match entre las dos tablas usando una clave única, como order key. Como esas claves únicas suelen ser aleatorias, no fuerzan ningún pruning. Si en cambio modificamos la condición del MERGE para emparejar por order key y order date, el dynamic query pruning sí puede entrar en juego. Al leer los datos de la tabla fuente, Snowflake detecta el rango de fechas que cubren los 3 órdenes que vamos a actualizar. Luego empuja ese rango de fechas como filtro hacia el lado destino, evitando escanear toda esa tabla grande.

¿Cómo aplicar esto en tu día a día? Si tienes operaciones MERGE o JOIN donde se gasta mucho tiempo escaneando la tabla destino (a la derecha), evalúa si puedes incluir predicados adicionales en la cláusula de join que fuercen el query pruning. Ten en cuenta que esto solo funcionará si (a) tu tabla destino está clusterizada por alguna clave y (b) la tabla fuente (a la izquierda) que estás joineando contiene un rango acotado de registros sobre esa clave de cluster (es decir, un subconjunto de order dates).
Cuando uses la estrategia de materialización incremental en dbt, por debajo se ejecutará una query MERGE. Para agregar una condición de join adicional que fuerce el dynamic pruning, actualiza el array unique_key e incluye la columna extra (por ejemplo, updated_at).
{{ config(
materialized='incremental',
unique_key=['order_id', 'updated_at'],
) }}
select *
from {{ ref('stg_orders') }}
...
4\. Usa tablas pre-agregadas
Crea tablas tipo 'rollup' o 'derivadas' que contengan menos filas. Las tablas pre-agregadas suelen poder diseñarse de modo que entreguen la información que necesita la mayoría de las queries, ocupando menos espacio de almacenamiento. Eso las vuelve mucho más rápidas de consultar. En el retail, una estrategia común es usar una tabla de rollup diaria de órdenes para reportes financieros y de stock, y dejar la tabla cruda de órdenes solo para los casos donde se necesita granularidad por orden.
5\. ¡Simplifica!
Cada operación dentro de una query toma tiempo en mover datos entre los hilos worker. Consolidar y eliminar operaciones innecesarias reduce la transferencia de red requerida para ejecutarla. Además, le permite a Snowflake reutilizar cómputos y ahorrarse trabajo adicional. La mayoría de las veces los CTEs y subqueries no afectan el rendimiento, así que úsalos para mejorar la legibilidad.
En general, que cada query haga menos cosas las vuelve más fáciles de depurar. Además, reduce la probabilidad de que el optimizador de Snowflake tome una decisión incorrecta (por ejemplo, elegir el orden de join equivocado).
6\. Reduce el volumen de datos procesados
Mientras menos datos haya, más rápido se completa cada paso de procesamiento. Reducir tanto la cantidad de columnas como la de filas que procesa cada paso mejorará el rendimiento.
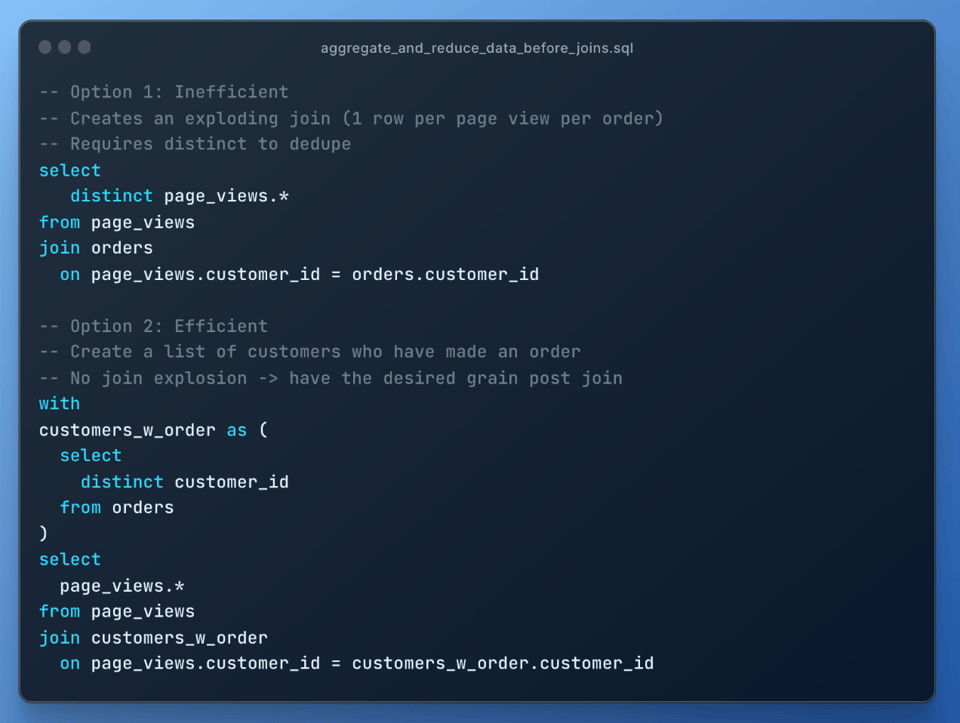
Aquí tienes un ejemplo donde mover un filtro qualify a un punto más temprano de la query redujo el tiempo de ejecución 3X. El primer query profile muestra el tiempo de ejecución cuando el filtro QUALIFY se aplicaba después de un join.
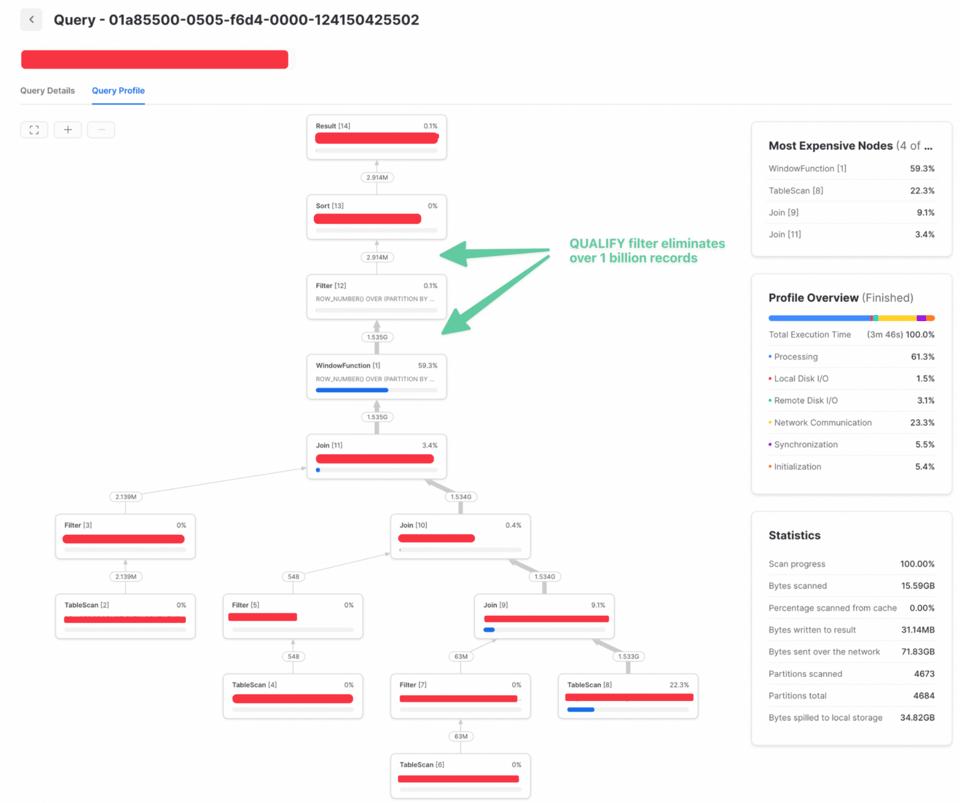
Como el filtro QUALIFY no requería información posterior al join, se pudo mover a un punto más temprano de la query. Así se joinean muchos menos datos y el rendimiento mejora notablemente:
Para queries de transformación que escriben en otra tabla, una forma poderosa de reducir el volumen de datos procesados es la incrementalización. En el ejemplo de la tabla orders, podríamos configurar la query para procesar solo órdenes nuevas o actualizadas y mezclar (merge) esos resultados con la tabla existente.
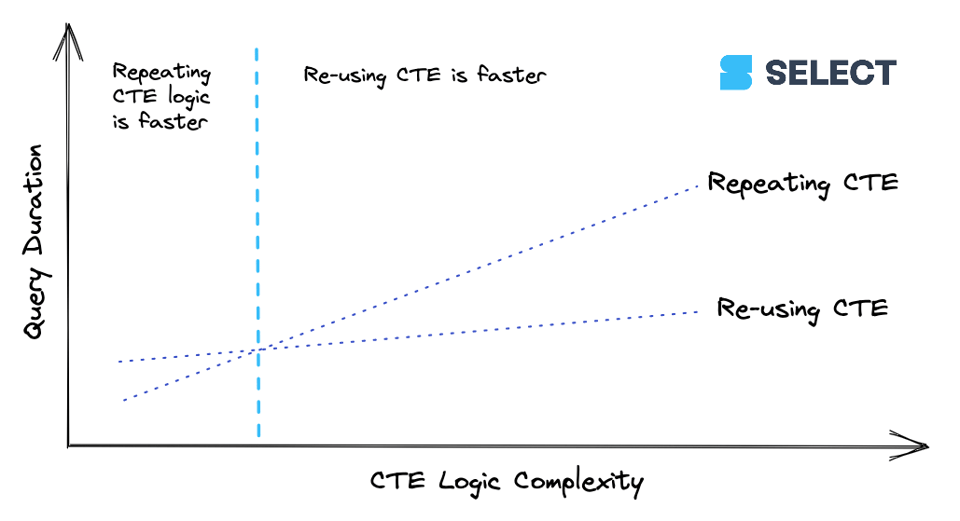
7\. Repetir CTEs puede ser más rápido, a veces
Ya escribimos antes sobre si deberías usar CTEs en Snowflake. Cada vez que referencias un CTE más de una vez en tu query, verás una operación WithClause en el query profile (mira el ejemplo abajo). En ciertos escenarios, esto puede hacer la query más lenta, y resulta más eficiente reescribir el CTE cada vez que lo necesitas referenciar.
Cuando un CTE alcanza cierto nivel de complejidad, sale más barato calcularlo una sola vez y pasar sus resultados a las referencias downstream, en lugar de recomputarlo varias veces. Eso sí, este comportamiento no es consistente, así que lo mejor es experimentar. Aquí tienes una forma de visualizar la relación:
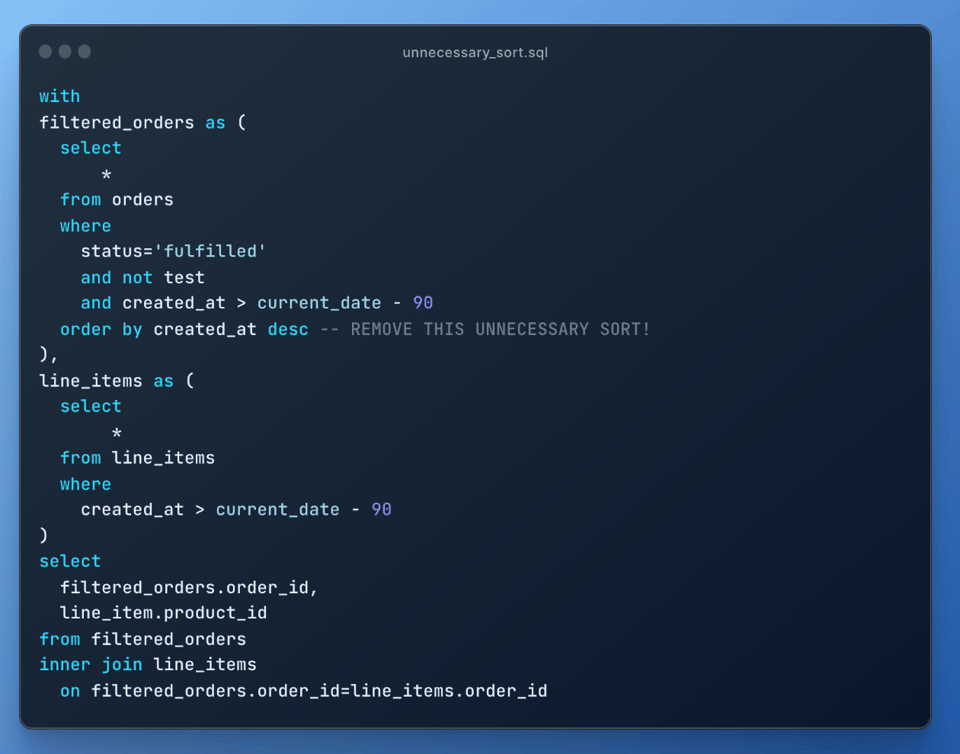
8\. Elimina los sorts innecesarios
El sorting es una operación costosa, así que asegúrate de eliminar cualquier sort que no sea necesario:
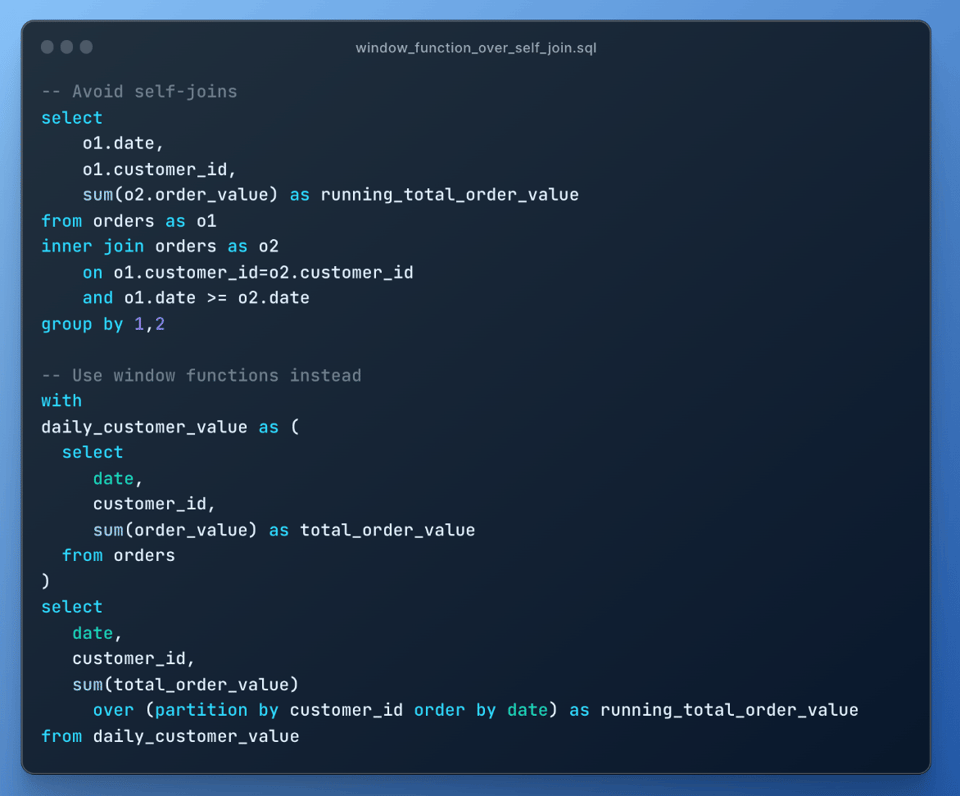
9\. Prefiere funciones de ventana sobre self-joins
En lugar de usar un self join, intenta usar funciones de ventana siempre que sea posible, ya que los self joins son muy costosos porque generan una explosión en el join:
10\. Evita joins con una condición OR
Al igual que los self-joins, los joins con una condición OR generan una explosión de join, porque se ejecutan como un cartesian join con una operación de filtrado posterior. Usa dos left joins en su lugar:
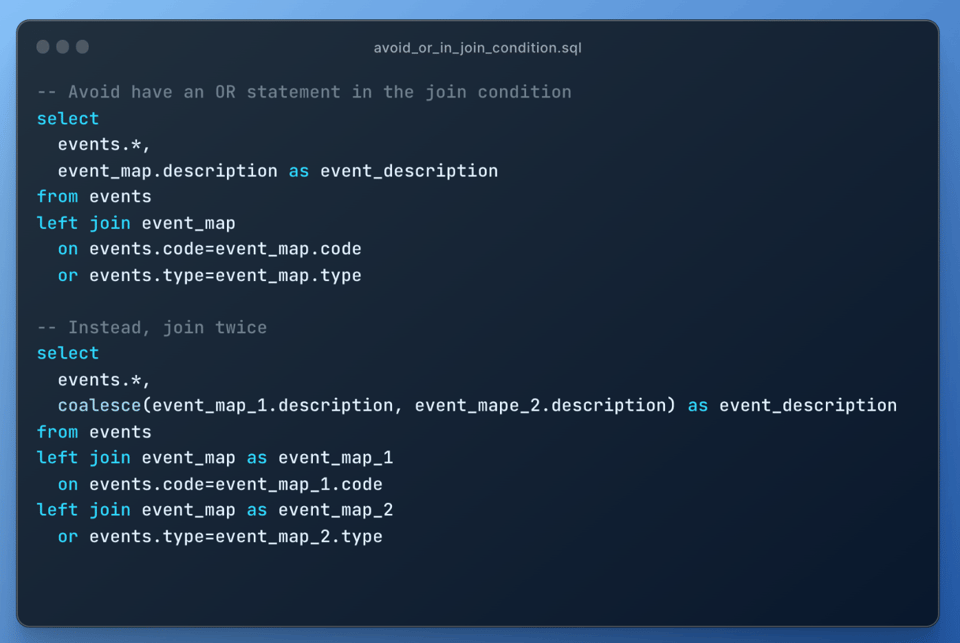
11\. Usa tu conocimiento de los datos para que Snowflake los procese de forma eficiente
Tu propio conocimiento de los datos sirve para mejorar el rendimiento de las queries. Por ejemplo, si una query agrupa por muchas columnas y sabes que algunas son redundantes porque otras ya representan la misma granularidad (o una mayor), puede ser más rápido sacarlas del group by y reincorporarlas en un paso aparte.
Si una columna agrupada o joineada está muy sesgada (es decir, hay un número pequeño de valores distintos que aparecen con mucha frecuencia), eso puede impactar negativamente la velocidad de Snowflake. Un ejemplo común es agrupar por una columna que contiene un número significativo de valores nulos. Filtrar esos valores y procesarlos en una operación aparte puede acelerar la query.
Por último, los range joins pueden ser lentos en todos los data warehouses, incluido Snowflake. Tu conocimiento sobre la longitud de los intervalos en los datos se puede aprovechar para reducir la explosión de joins que ocurre. Revisa nuestro post reciente si estás viendo rendimiento lento en range joins.
12\. Evita las vistas complejas
Como buena práctica, evita crear y usar vistas complejas en tus queries. Las vistas deberían usarse para persistir transformaciones simples, como renombrar columnas, hacer cálculos básicos sobre columnas, o para modelos de datos con joins ligeros.
Para entender cómo las vistas complejas pueden causar estragos, mira la siguiente query, aparentemente inocente:
select
a.*,
b.*
from model_a as a
left join model_b as b
on a.id=b.id
Esta query tardaba sistemáticamente más de 45 minutos en correr y terminaba fallando con un "Incident".
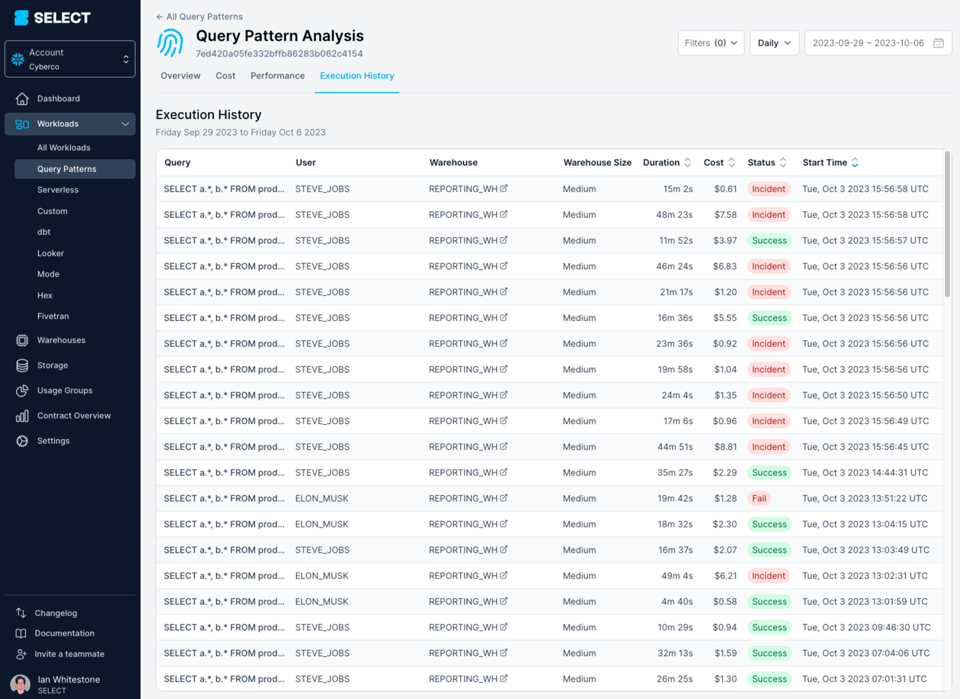
Al revisar el query profile (también conocido como el "query plan"), se ve que los modelos consultados eran en realidad vistas complejas, con cientos de tablas.
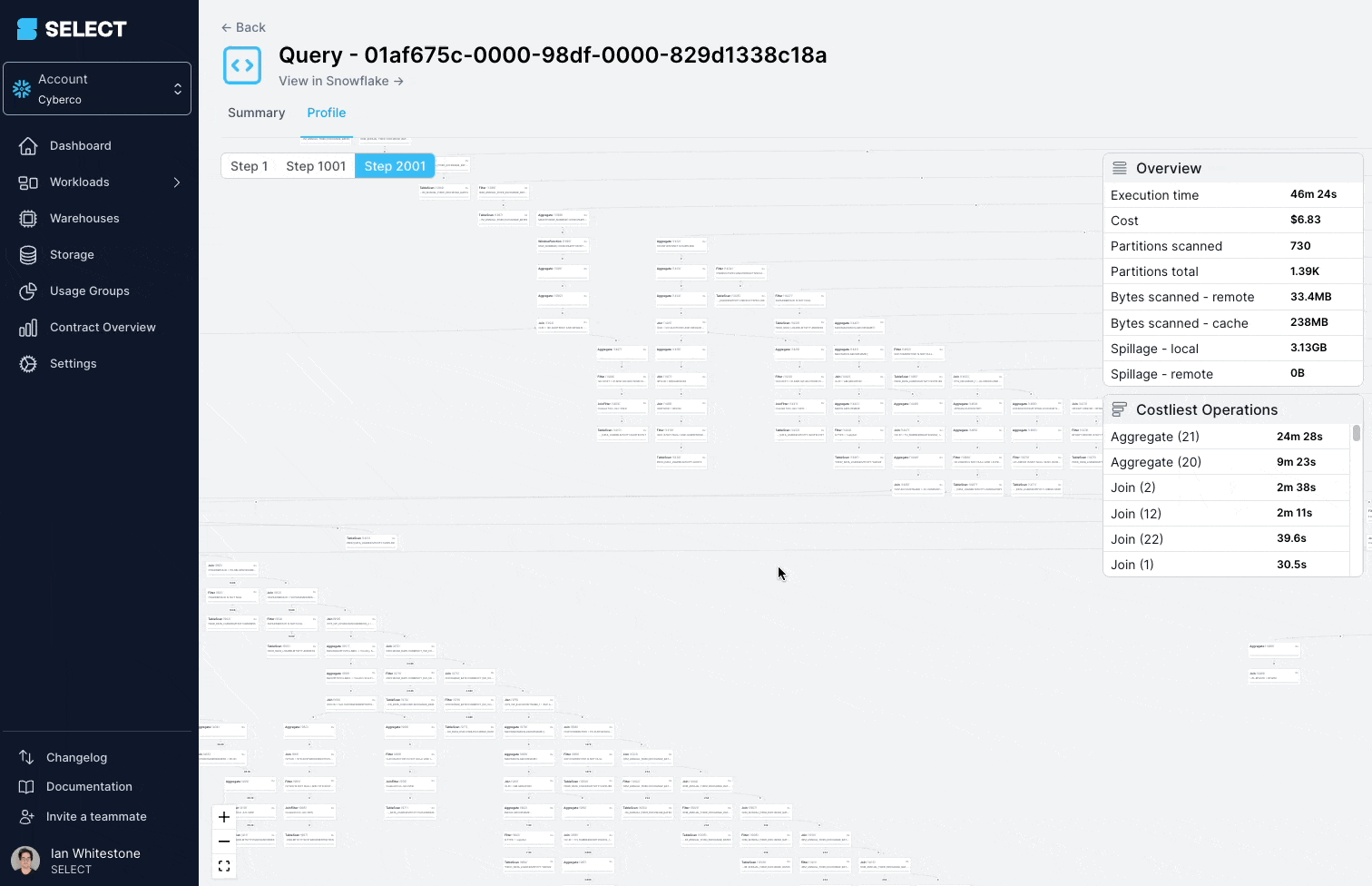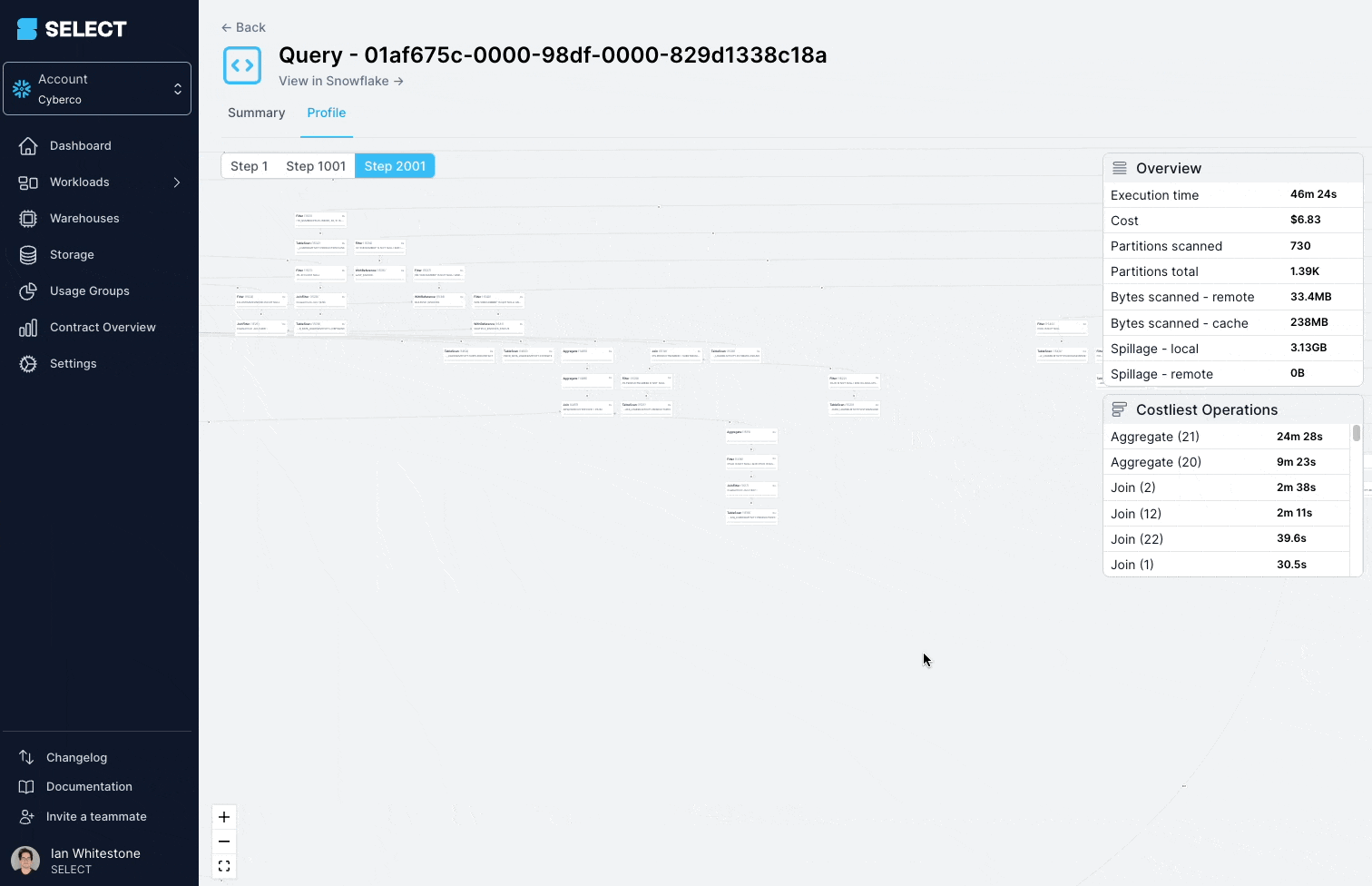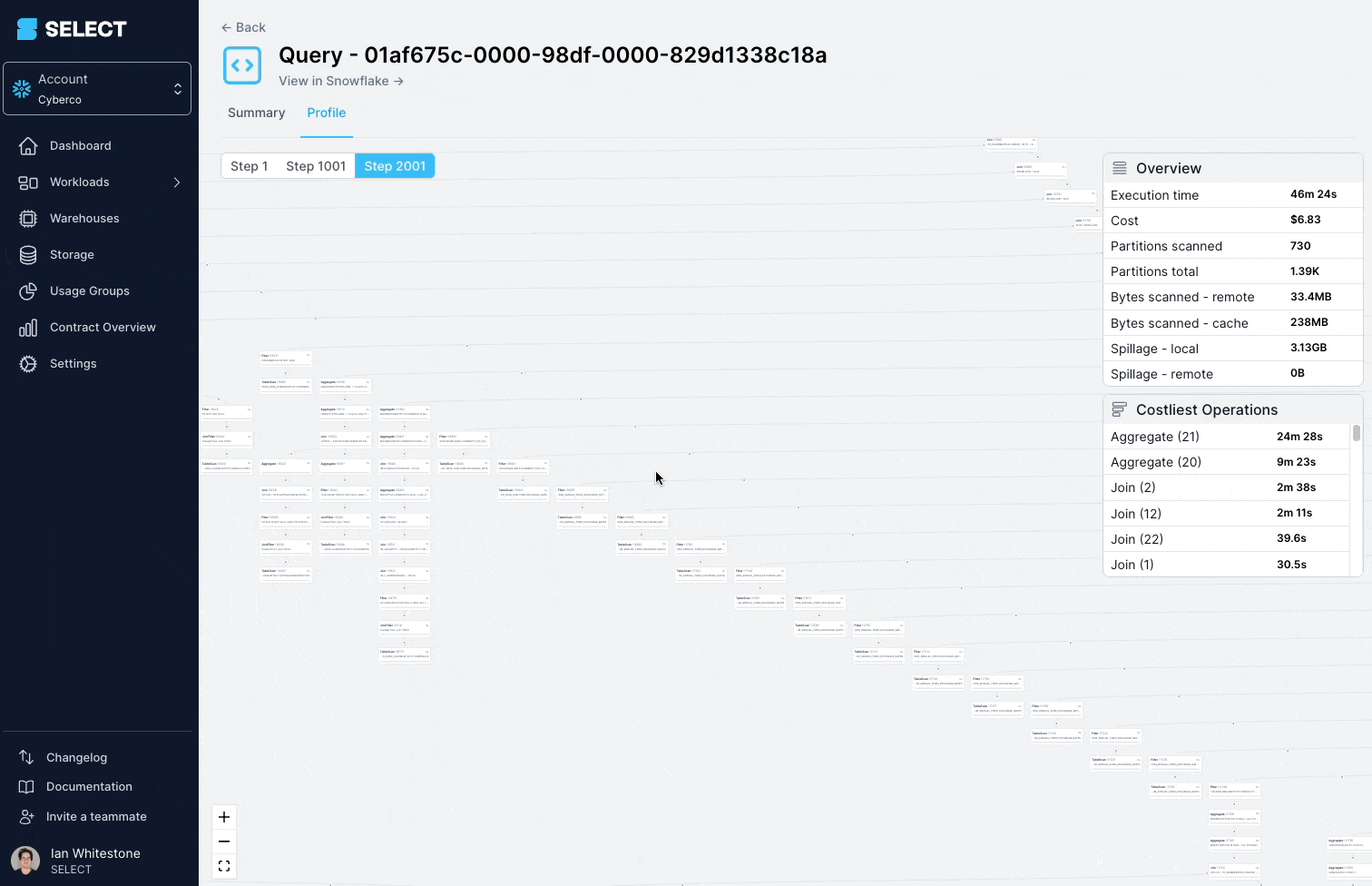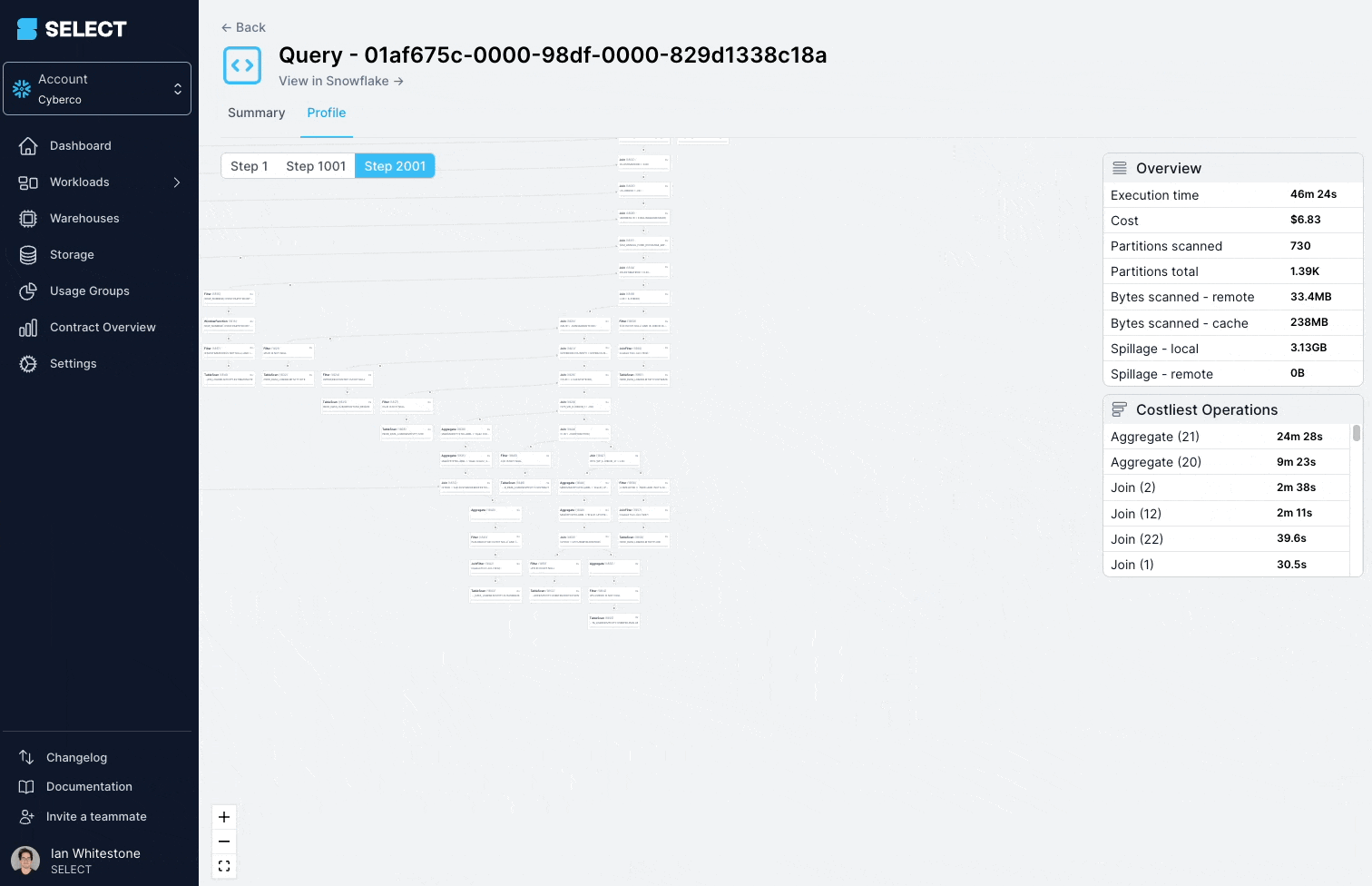
La solución acá es dividir la vista compleja en partes más simples y pequeñas, y persistirlas como tablas.
13\. Asegura un uso efectivo de los cachés de queries
Cada nodo de un virtual warehouse cuenta con almacenamiento local en disco que se puede usar para cachear las micro-particiones leídas desde el almacenamiento remoto. Si múltiples queries acceden al mismo conjunto de datos en una tabla, pueden escanearlos desde la caché local en lugar del almacenamiento remoto, lo cual acelera la query si el principal cuello de botella es la lectura de datos.
Cuando el warehouse se suspende, Snowflake no garantiza que la caché persista al reanudarse. El impacto de perder la caché es que las queries tienen que volver a escanear los datos desde el almacenamiento de las tablas, en lugar de leerlos desde la caché local, que es mucho más rápida. Si la pérdida de caché del warehouse está afectando tus queries, aumentar el umbral de auto-suspend ayudará.
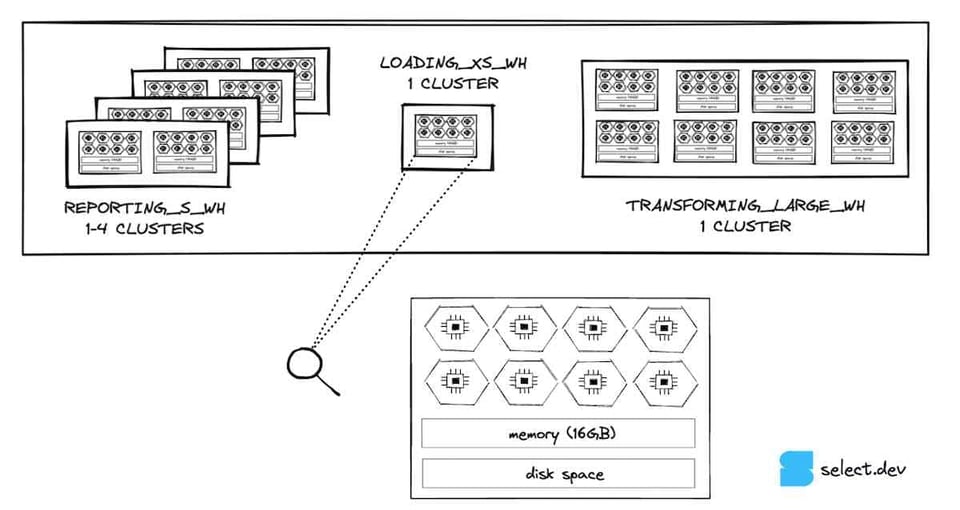
Por otro lado, Snowflake tiene una caché global de resultados que devuelve los resultados de queries idénticas ejecutadas en las últimas 24 horas, siempre que los datos en las tablas consultadas sean los mismos. Hay ciertas situaciones que pueden impedir aprovecharla (por ejemplo, si tu query usa una función no determinista), así que asegúrate de estar pegándole a la caché global cuando esperas hacerlo. Si no, puede que tengas que ajustar tu query o contactar al soporte para reportar un bug.
14\. Aumenta el tamaño del warehouse
El tamaño del warehouse determina la potencia computacional total disponible para las queries que corren en él, también conocido como escalado vertical.
Aumenta el tamaño del virtual warehouse cuando:
- Las queries están haciendo spill a disco remoto (se identifica en el query profile).
- Se necesitan resultados de la query más rápido (típicamente en aplicaciones de cara al usuario).
Las queries que hacen spill a disco remoto corren de forma ineficiente debido al gran volumen de tráfico de red entre el warehouse que ejecuta la query y el disco remoto donde se almacenan los datos. Aumentar el tamaño del warehouse duplica la RAM y el disco local disponibles, que son mucho más rápidos de acceder que el disco remoto. Cuando ocurre spillage a disco remoto, aumentar el tamaño del warehouse puede más que duplicar la velocidad de la query. Ya entramos en más detalle sobre el sizing de warehouses de Snowflake en el pasado, y también cubrimos cómo configurar tamaños de warehouse en dbt.
Ten en cuenta que si la mayoría de las queries que corren en el warehouse no requieren un warehouse más grande y quieres evitar aumentar el tamaño para todas, puedes considerar usar el Query Acceleration Service de Snowflake. Este servicio, disponible desde la edición Enterprise en adelante, se puede usar para darles recursos de cómputo adicionales a las queries que escanean grandes volúmenes de datos.
15\. Aumenta el Max Cluster Count
Los warehouses multi-cluster, disponibles desde la edición Enterprise en adelante, permiten crear más instancias de un warehouse del mismo tamaño.
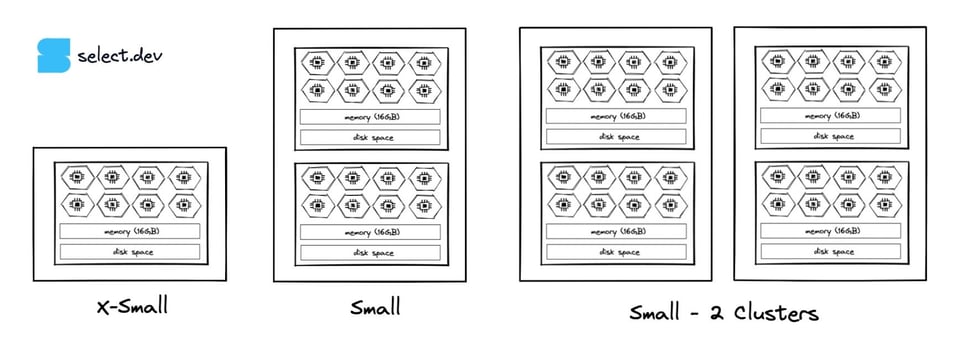
Si hay periodos en los que el queuing del warehouse hace que las queries no alcancen la velocidad de procesamiento requerida, considera usar multi-clustering o aumentar el número máximo de clusters en el warehouse. Así el warehouse podrá acompañar el volumen de queries agregando o quitando clusters.
A diferencia del cluster count, Snowflake no puede ajustar automáticamente el tamaño de los virtual warehouses según el volumen de queries. Por eso los warehouses multi-cluster son más rentables para procesar volúmenes de queries variables, ya que cada cluster solo se cobra mientras está activo.
16\. Ajusta la política de escalado de clusters
Snowflake ofrece dos políticas de escalado: Standard y Economy. Para todos los virtual warehouses que atienden queries de cara al usuario, usa la política Standard. Si tienes una preocupación fuerte por el costo, experimenta con la política Economy en workloads tolerantes a queuing como la carga de datos para ver si reduce costos manteniendo el throughput requerido. En el resto de los casos, recomendamos usar Standard en todos los warehouses.
Otros recursos
Si buscas más contenido sobre optimización de queries en Snowflake, te recomendamos explorar los recursos en video adicionales que verás a continuación.
Behind the Cape: serie de 3 partes sobre Snowflake Cost Optimization (2023)
En esta serie de 3 videos, Ian se unió al data superhero de Snowflake, Keith Belanger, para Behind the Cape, una serie en la que expertos de Snowflake abordan distintos temas en profundidad.
Parte 1
En este episodio abordamos el tema central de la optimización de costos en Snowflake. Como solo teníamos 30 minutos, terminó siendo una conversación a un nivel más alto sobre cómo empezar, el modelo de billing de Snowflake y las herramientas que ofrece Snowflake para controlar costos.
Aquí tienes una lista completa de los temas que tratamos:
- ¿Cómo deberías empezar con la optimización de costos en Snowflake? (TL;DR: arma un entendimiento integral de tus drivers de costo antes de meterte en cualquier esfuerzo de optimización).
- Dónde están hoy la mayoría de los clientes en cuanto a su comprensión del uso de Snowflake.
- Cómo funciona el modelo de billing de Snowflake (¿sabías que en realidad es más barato almacenar datos en Snowflake?).
- Las herramientas que ofrece Snowflake para tener visibilidad de costos.
- Los métodos disponibles para controlar costos (resource monitors, query timeouts y ACCESS CONTROL, ¡en el que nadie piensa!).
- ¿Por dónde empezar a recortar costos? ¿Optimizar queries? ¿O ir a un nivel más alto?
- Recursos para seguir aprendiendo.
Para quienes quieran tener una visión general de la optimización, el monitoreo y el control de costos, este es un excelente punto de partida. La grabación del video la encuentras abajo. ¡Hay tanto por discutir sobre este tema y no alcanzamos a profundizar mucho, así que pronto haremos un follow-up!
Play
Parte 2
En este episodio profundizamos en algunos conceptos fundamentales de la optimización de queries en Snowflake:
- El ciclo de vida de una query en Snowflake.
- El sizing de virtual warehouses en Snowflake.
- Cómo usar el query profile de Snowflake e identificar cuellos de botella.
Play
Parte 3
En el episodio final de la serie nos sumergimos en las técnicas más importantes de optimización de queries:
- Entender las micro-particiones de Snowflake.
- Cómo aprovechar el query pruning.
- Cómo asegurar que tus tablas estén bien clusterizadas.
Play
Video Snowflake Optimization Power Hour (2022)
El 28 de septiembre de 2022, Ian dio una presentación al Snowflake Toronto User Group sobre performance tuning y optimización de costos en Snowflake. Se cubrió el siguiente contenido:
- Arquitectura de Snowflake.
- El ciclo de vida de una query en Snowflake.
- El modelo de billing de Snowflake.
- Un framework simple para optimización de costos, junto con una metodología detallada para calcular el costo por query.
- Mejores prácticas de configuración de warehouses.
- Tips para el clustering de tablas.
Diapositivas
Las diapositivas se pueden ver aquí. Para navegarlas, haz clic en las flechas de la esquina inferior derecha o usa las teclas de flecha del teclado. Presiona la tecla "esc" o la tecla "o" para hacer zoom out al modo "overview", donde puedes ver todas las diapositivas. Desde ahí, navega de nuevo con las flechas y haz clic en una diapositiva o presiona "esc"/"o" para enfocarla.
Grabación de la presentación
La grabación de la presentación está disponible en YouTube. La presentación empieza en el minuto 3:29.
Play
Si lo deseas, con gusto puedo dar esta presentación (o una variación) a tu equipo, donde tendrán la oportunidad de hacer preguntas. Envía un correo a [email protected] si quieres coordinarla.
Query Optimization at Snowflake (2020)
Si quieres entender mejor el funcionamiento interno del optimizador de queries de Snowflake, te recomiendo mucho ver esta charla de Jiaqi Yan, uno de los ingenieros de bases de datos más senior de Snowflake:
Play
Ian Whitestone·Co-founder & CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, Ian lideró los esfuerzos para optimizar el data warehouse y aumentar la observabilidad de costos.
Niall Woodward·Co-founder & CTO de SELECT
Niall es Co-Founder y CTO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y en varias startups. Como entusiasta del open source, también es maintainer de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.