Snowflakeが幅広く支持されているのは、最小限の設定で大量データを極めて低レイテンシで処理できるからです。その結果、何千もの組織のデータチームに定番ツールとして選ばれています。本ガイドでは、Snowflakeのパフォーマンスと効率を最大限に引き出す最適化テクニックをご紹介します。これらのベストプラクティスを実践すれば、クエリの高速化とコスト削減を同時に実現できます。
本記事で取り上げるSnowflakeのパフォーマンスチューニング手法は、SELECTが100社を超えるSnowflakeユーザーの支援を通じて実証してきた戦略に基づいています。「これも入れてほしい」というご意見があれば、ぜひお寄せください。メールまたは画面下部のチャットからお気軽にご連絡ください。
本記事のテーマはクエリ最適化テクニックであり、それをどのように活用してSnowflakeクエリを高速化するかを解説します。結果としてコスト削減にもつながりますが、コスト削減が主目的であれば、より効果的な出発点があります。実践的なコスト削減戦略は、Snowflakeコスト最適化の記事をぜひご覧ください。
Snowflakeクエリ最適化テクニック
本記事で紹介するSnowflakeのクエリパフォーマンス最適化テクニックは、大きく3つのカテゴリに分けられます。
1. データ読み取り効率の改善
クエリは、テーブルストレージからのデータ読み取りに大きな時間を取られることがあります。このステップはクエリプロファイル上で「TableScan」として表示されます。TableScanとは、テーブルの格納先からネットワーク経由で仮想ウェアハウスのワーカーノードにデータをダウンロードする処理です。ダウンロードするデータ量を減らすか、仮想ウェアハウスのサイズを大きくすることで、この処理を高速化できます。
Snowflakeは、クエリで選択された列のみを読み取り、テーブルのマイクロパーティションがフィルター条件に対して適切にクラスタリングされている場合に限り、クエリのフィルターに関連するマイクロパーティションのみを読み取ります。
クエリがダウンロードするデータ量を減らし、TableScanを高速化するための4つの手法は次のとおりです。
- アクセスする列の数を減らす
- クエリプルーニングとテーブルクラスタリングを活用する
- 結合述語にクラスタリング済みの列を使う
- 事前集計テーブルを使う
2. データ処理効率の改善
結合(Join)、ソート、集計といった処理はTableScanの下流で実行され、クエリのボトルネックになりがちです。データ処理を最適化するには、クエリステップを減らす、データを増分処理する、データに関する知識を活かしてパフォーマンスを高めるといった手段があります。
データ処理効率を高める手法は次のとおりです。
- クエリ処理をシンプルにし、操作数を減らす
- 早い段階でフィルタリングし、処理対象データ量を減らす
- CTEの繰り返し参照を避ける
- 不要なソートを削除する
- セルフ結合よりウィンドウ関数を優先する
- OR条件を含む結合を避ける
- データに関する知識を活かし、Snowflakeに効率よく処理させる
- 複雑なビューに対するクエリを避ける
- クエリキャッシュを効果的に活用する
3. ウェアハウス構成の最適化
Snowflakeの仮想ウェアハウスは、大規模なワークロードや高並行性のワークロードに対応できるよう簡単に設定できます。パフォーマンス改善に効く主な設定は次のとおりです。
- ウェアハウスサイズを大きくする
- ウェアハウスのクラスター数を増やす
- ウェアハウスのスケーリングポリシーを変更する
最適化に取りかかる前に、まずクエリが遅くなっている原因を特定する方法を確認しておきましょう。
Snowflakeクエリの最適化方法
Snowflakeクエリを最適化するには、クエリプロファイリングを使って実際のボトルネックがどこにあるのかを把握することが先決です。どの処理が遅延の原因となっており、どこに注力すべきかを見極める必要があります。
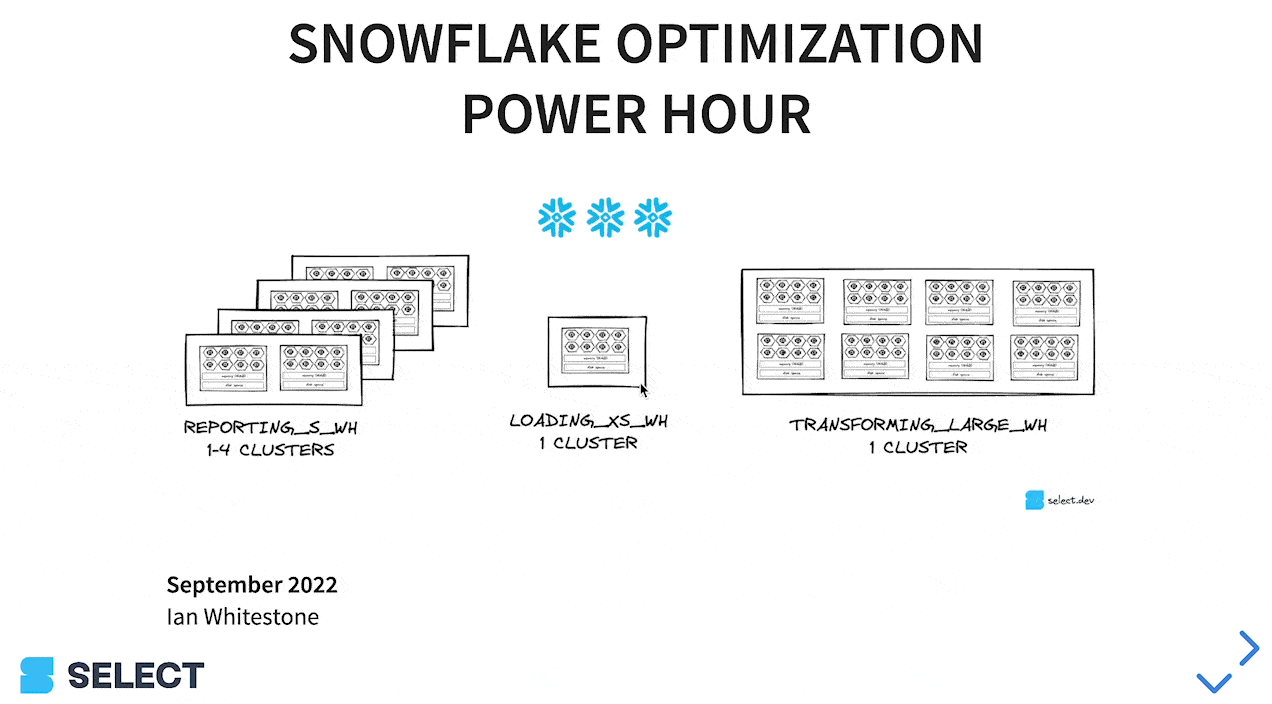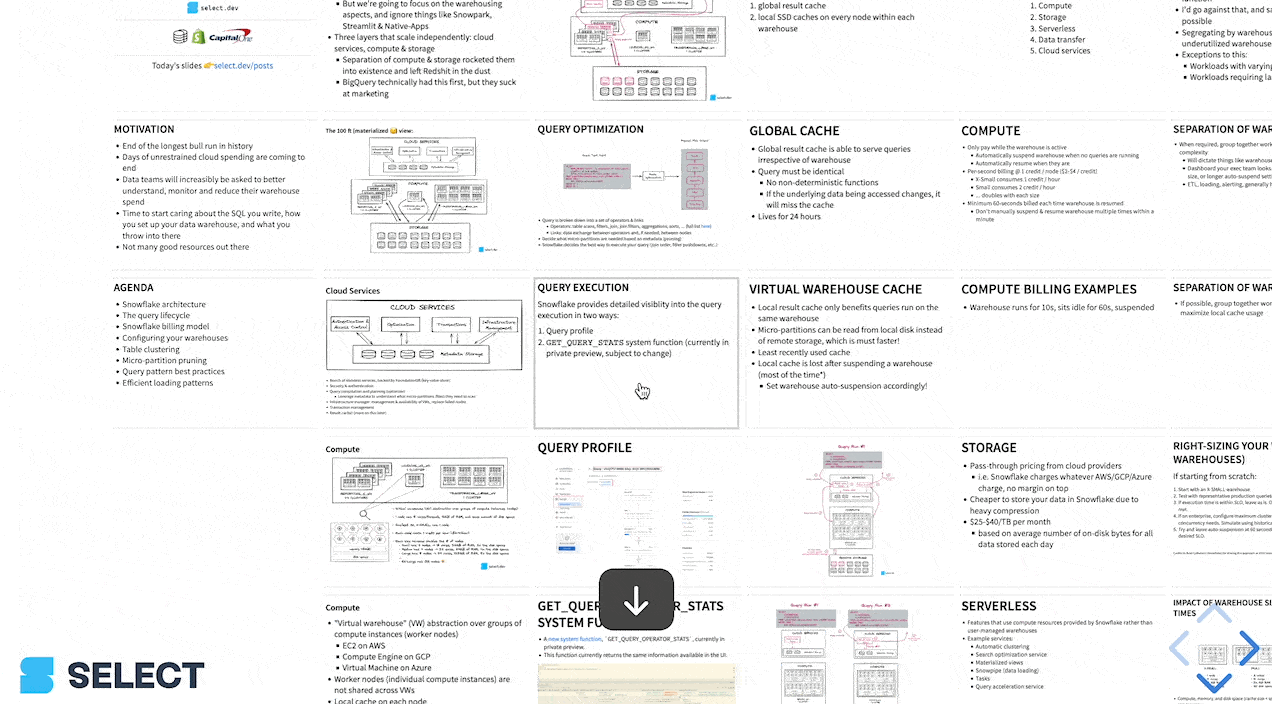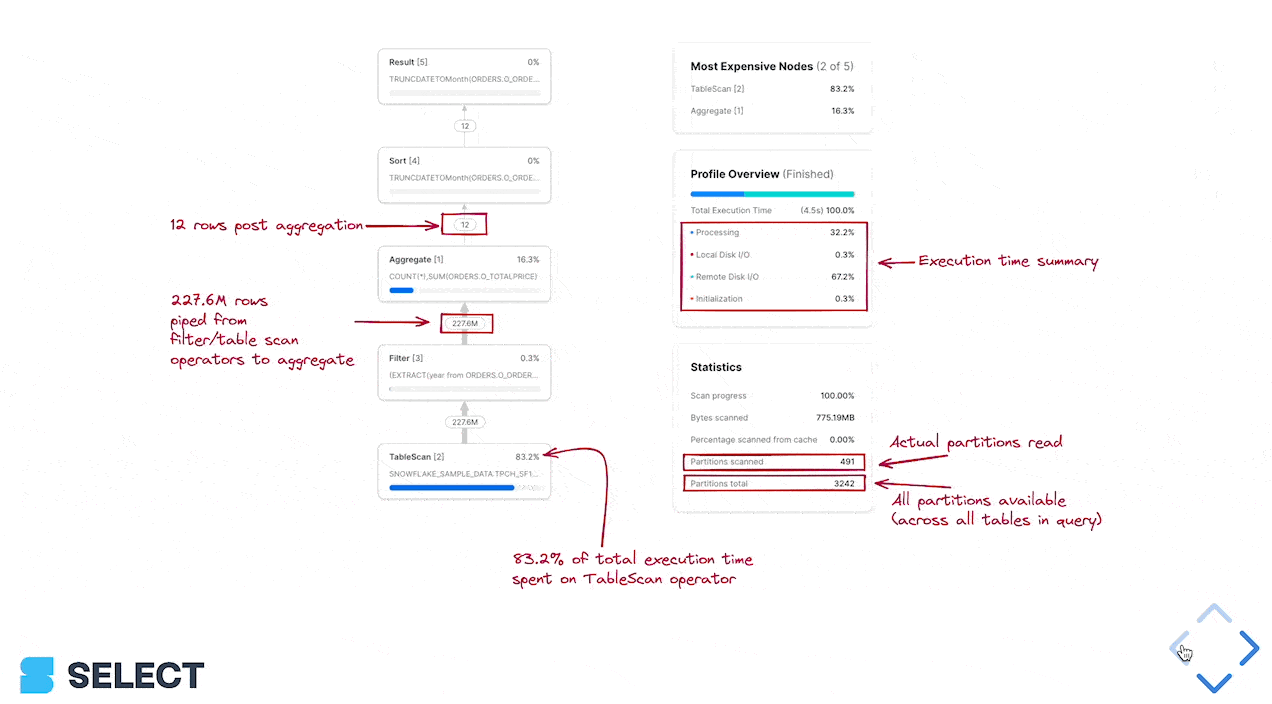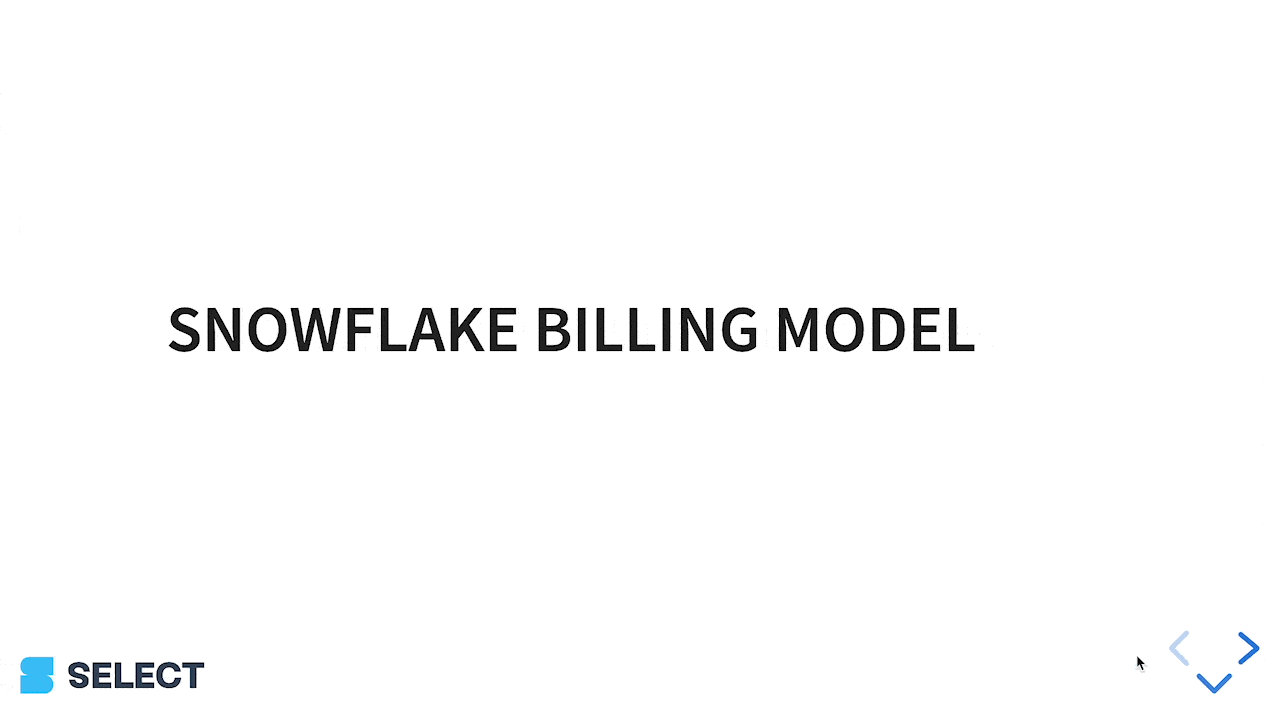
そのためにはSnowflakeのクエリプロファイル(クエリプラン)を開き、「Most Expensive Nodes(最もコストの高いノード)」セクションを確認します。ここで、クエリの実行時間を最も多く消費している処理がわかります。
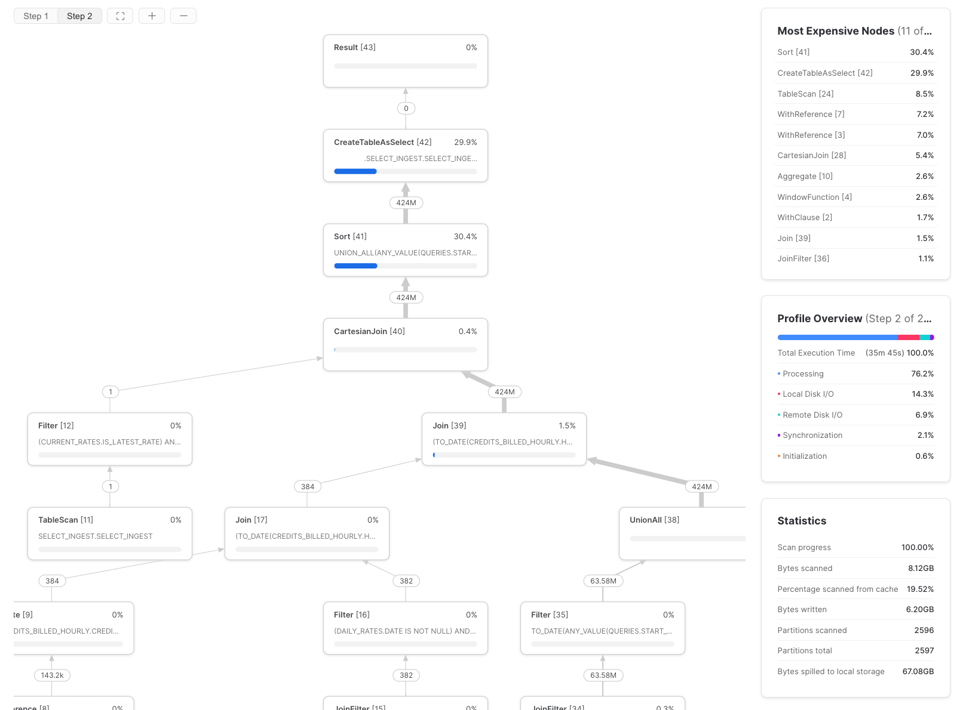
この例では、ボトルネックがSortステップであることがわかります。これはデータ処理効率の改善に注力すべきであり、必要に応じてウェアハウスサイズを引き上げるべきだという示唆です。最もコストの高いノードがTableScanの場合は、データ読み取り効率の最適化に注力するのが最善です。
1\. 列を絞り込む
当たり前のようでいて、できる場面で実践すれば大きな効果があります。クエリの要件は時間とともに変わり、かつて必要だった列が下流処理で使われなくなることもあります。Snowflakeはデータをマイクロパーティションと呼ばれるハイブリッド列指向のファイル形式で保存しており、これによりストレージから読み取るデータ量を削減できます。マイクロパーティションのデータをダウンロードする処理はスキャンと呼ばれ、列数を減らすほどネットワーク経由のデータ転送量も減ります。
2\. クエリプルーニングを活用する
クエリがスキャンするマイクロパーティション数を減らす手法はクエリプルーニングと呼ばれ、これを成立させるにはいくつかの条件があります。
- クエリに、必要なデータ範囲を絞り込むフィルターが含まれていること。明示的な
whereフィルターでも、暗黙的なjoinフィルターでも構いません。 - フィルターに使う列で、テーブルが適切にクラスタリングされていること。
下図の仮想ordersテーブルに対して次のクエリを実行すると、(a) ordersテーブルがcreated_atでクラスタリングされており(データがcreated_atでソートされている)、(b) where句でcreated_atを特定日付で明示的にフィルタリングしているため、クエリプルーニングが発生します。
select *
from orders
where created_at > '2022/08/14'

プルーニング性能を改善できるかどうかは、クエリプロファイルのPartitions scannedとPartitions totalの値で判断できます。
クエリでwhere句のフィルターを使っていない場合、追加するだけでTableScanが大幅に高速化されることがあります(下流ノードも処理データ量が減るため高速化されます)。すでにwhere句フィルターを使っているのに「Partitions scanned」が「Partitions total」とほぼ同じ値であれば、where句が効果的にプルーニングされていないことを意味します。
プルーニングを改善するには、次の方法があります。
3\. 結合述語にクラスタリング済みの列を使う
多くのユーザーになじみがあるのは、静的クエリプルーニングです。先ほどに似た、シンプルな例を見てみましょう。
select *
from orders
where order_date > current_date - 7
ordersテーブルがorder_dateでクラスタリングされていれば、Snowflakeのクエリオプティマイザーは、7日以上前のデータを含むマイクロパーティション(ファイル)の大部分を無視できると判断します。リモートデータのスキャンには相当な処理時間がかかるため、マイクロパーティションを除外できればクエリ速度は大きく向上します。
あまり知られていないSnowflakeクエリエンジンの機能に、動的プルーニングがあります。実行前のクエリプランニング段階で行われる静的プルーニングと異なり、動的クエリプルーニングはクエリ実行中にオンザフライで発生します。
MERGEコマンドを使ってordersテーブルの既存レコードを定期的に更新する処理を考えてみましょう。内部的には、MERGEは新規・更新レコードを含むソーステーブルと、更新対象のターゲットテーブル(orders)との結合を必要とします。
動的プルーニングはこの結合の最中に働きます。仕組みはこうです。Snowflakeクエリエンジンがソーステーブルからデータを読み込む際、そこに含まれるレコードの範囲を把握し、不要なデータスキャンを避けるためにターゲットテーブル側へフィルター処理を自動的にプッシュダウンします。
具体例で見てみましょう。order dateでクラスタリングされたターゲットのordersテーブルに対して、3件のレコードを更新したいソーステーブルがあるとします。一般的なMERGE処理では、order keyのような一意キーで両テーブルのレコードを突き合わせます。こうした一意キーは通常ランダムなので、クエリプルーニングは発生しません。しかし、MERGE条件をorder keyとorder dateの両方で突き合わせるよう変更すれば、動的クエリプルーニングが機能します。Snowflakeはソーステーブルからデータを読み込む際、更新対象3件の注文がカバーする日付範囲を検出できます。そしてその日付範囲をターゲット側のフィルターとしてプッシュダウンし、巨大なテーブル全体をスキャンせずに済みます。

これを日々の業務にどう活かせばよいでしょうか。ターゲットテーブル(右側)のスキャンに大きな時間を要するMERGEやJOIN処理がある場合、結合句にクエリプルーニングを誘発する述語を追加できないか検討してみてください。なお、この手法が機能するのは、(a) ターゲットテーブルが何らかのキーでクラスタリングされており、(b) 結合元のソーステーブル(左側)がそのクラスタリングキー上で狭い範囲のレコード(例:order dateの一部)を含む場合に限られます。
dbtでincrementalマテリアライゼーション戦略を使うと、内部でMERGEクエリが実行されます。動的プルーニングを誘発する結合条件を追加するには、unique_key配列を更新して追加の列(例:updated_at)を含めます。
{{ config(
materialized='incremental',
unique_key=['order_id', 'updated_at'],
) }}
select *
from {{ ref('stg_orders') }}
...
4\. 事前集計テーブルを使う
行数の少ない「ロールアップ」テーブルや「派生」テーブルを作りましょう。事前集計テーブルは、多くのクエリが必要とする情報をより少ないストレージ容量で提供できるよう設計でき、クエリ速度を大きく高められます。小売業では、財務・在庫レポートには日次注文ロールアップテーブルを使い、注文単位の粒度が必要なときだけ生のordersテーブルにクエリを投げる、というのが定石です。
5\. シンプルに保つ
クエリ内の各処理は、ワーカースレッド間でデータを移動させるための時間がかかります。不要な処理を統合・削除すれば、クエリ実行に必要なネットワーク転送量が減ります。さらに、Snowflakeが計算結果を再利用し、余計な処理を省くのにも役立ちます。CTEやサブクエリは通常パフォーマンスに影響しないため、可読性を高める用途で積極的に活用しましょう。
一般に、各クエリで行う処理を減らすほどデバッグも容易になります。加えて、Snowflakeのクエリオプティマイザーが誤った判断(誤った結合順序の選択など)を下す可能性も低くなります。
6\. 処理データ量を減らす
データ量が少ないほど、各データ処理ステップは速く完了します。クエリの各ステップで処理する列数と行数の両方を減らせば、パフォーマンスが向上します。
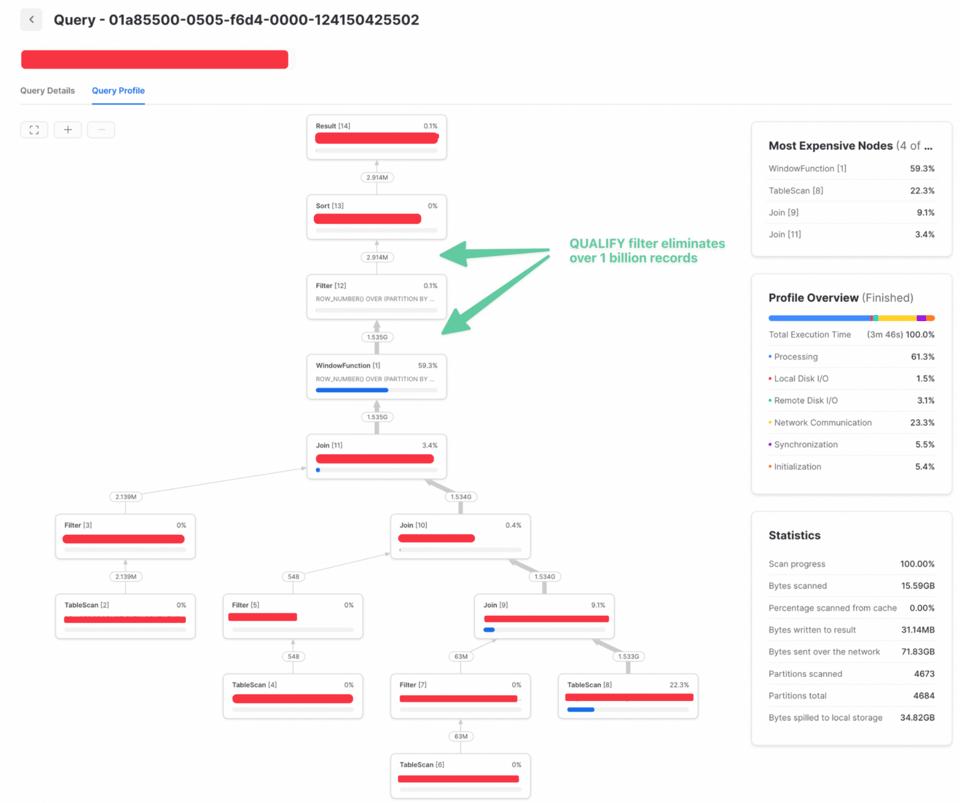
qualifyフィルターをクエリの前段に移動させたところ、実行時間が3倍速くなった事例です。最初のクエリプロファイルは、QUALIFYフィルターが結合の後にあった場合の実行時間を示しています。
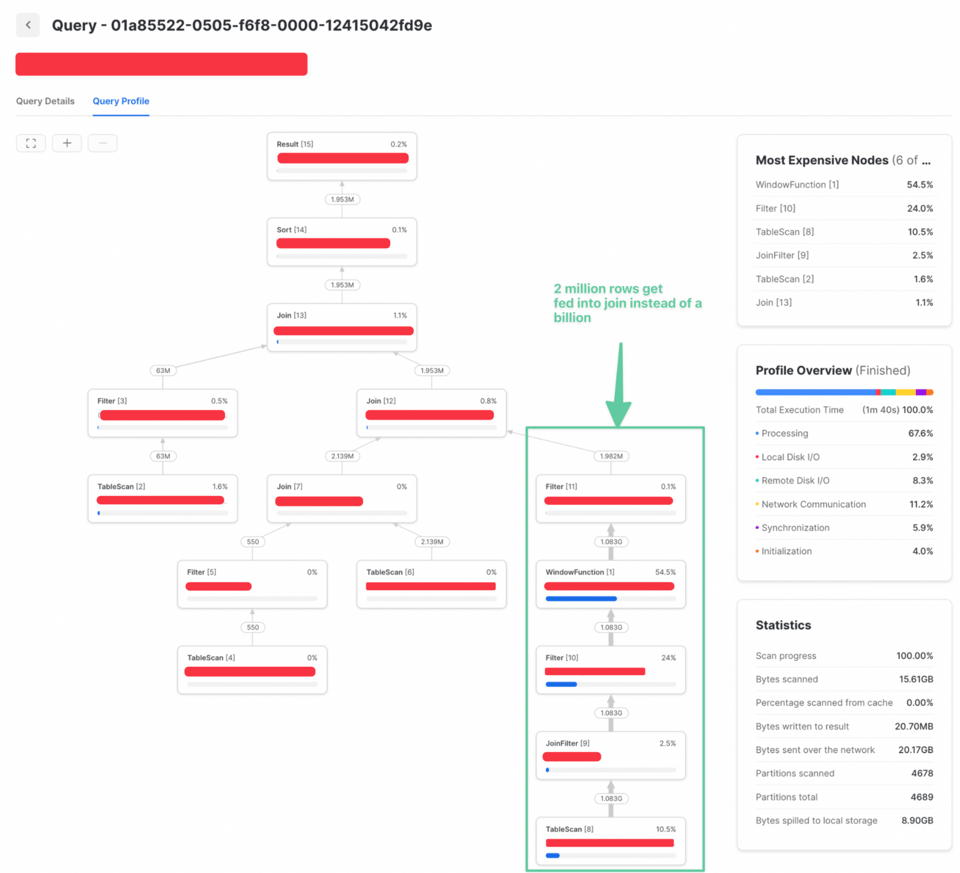
QUALIFYフィルターは結合後の情報を必要としなかったため、クエリの前段に移動できました。その結果、結合されるデータが大幅に減り、パフォーマンスが劇的に改善しています。
別テーブルへ書き込む変換クエリでは、増分処理(インクリメンタル化)が処理データ量を減らす強力な手段になります。ordersテーブルの例なら、新規または更新された注文だけを処理し、その結果を既存テーブルにマージするように構成できます。
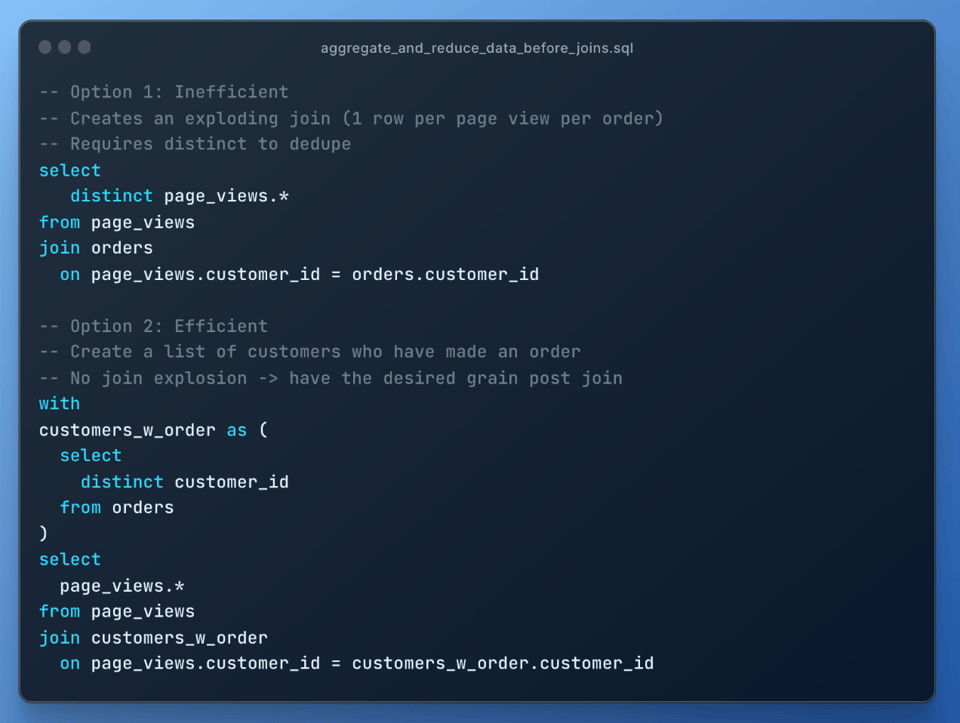
7\. CTEを繰り返した方が速くなることもある
以前、SnowflakeでCTEを使うべきかについて書いたことがあります。クエリ内でCTEを2回以上参照すると、クエリプロファイルにWithClause操作が現れます(下記の例を参照)。ケースによっては、これが原因でクエリがかえって遅くなることがあり、参照のたびにCTEを書き直した方が効率的な場合もあります。
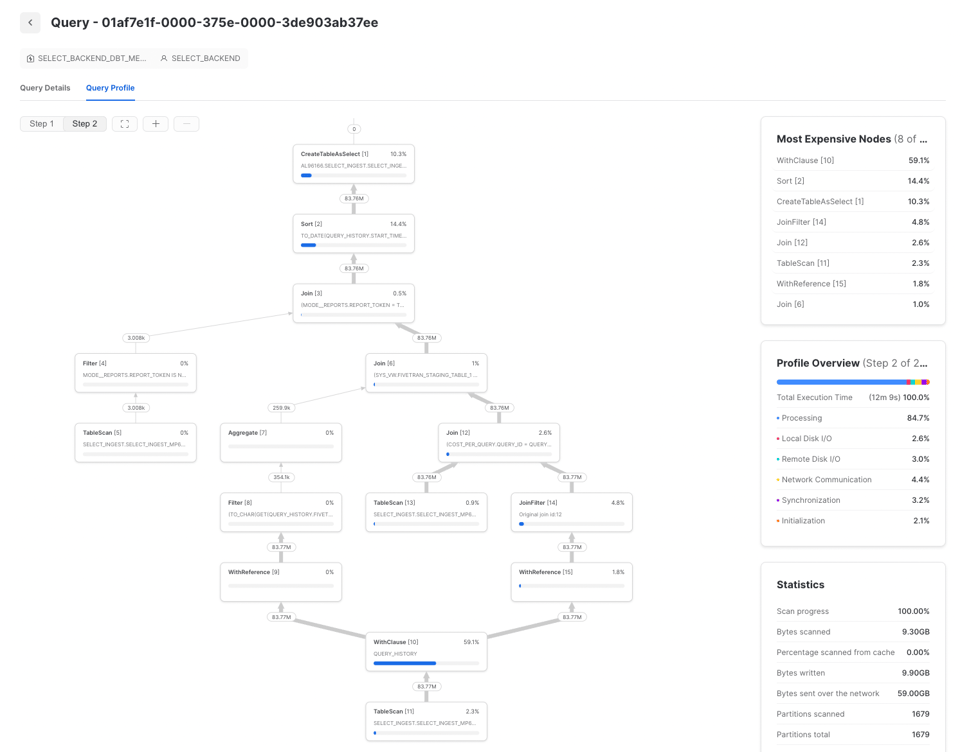
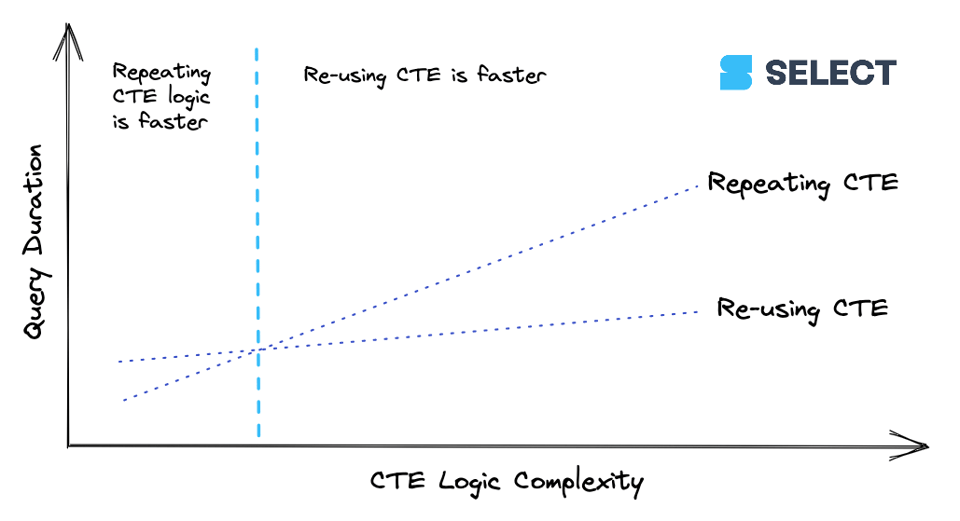
CTEが一定の複雑度を超えると、何度も再計算するより一度だけ計算してその結果を下流の参照に渡す方がコストを抑えられます。ただしこの挙動は一貫しないので、実際に試してみるのが一番です。関係性は次のように可視化できます。
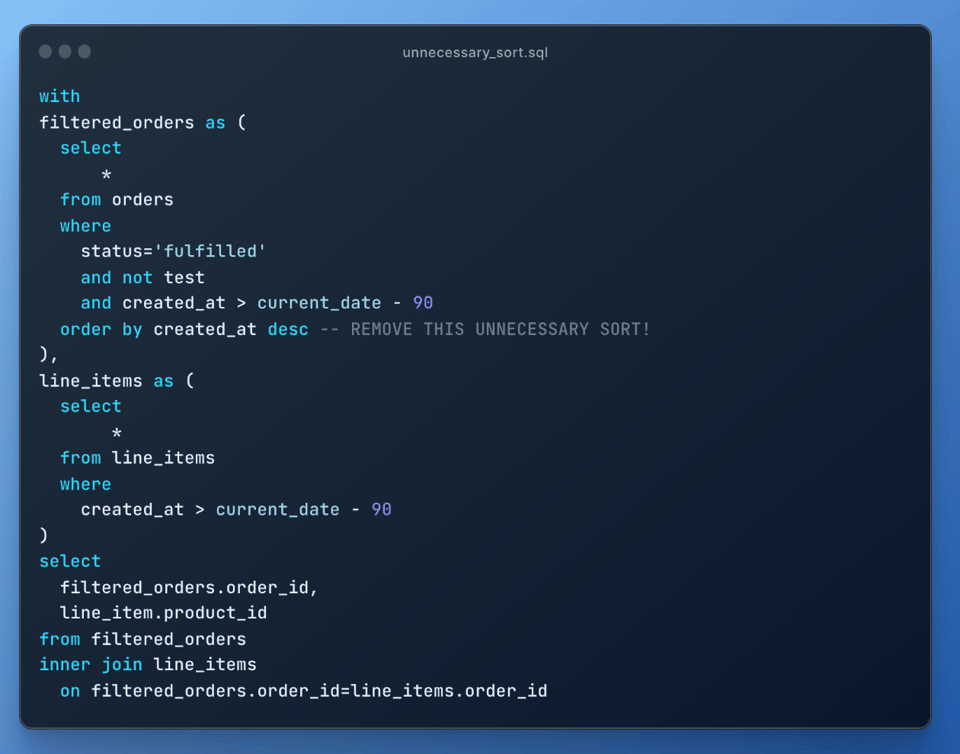
8\. 不要なソートを削除する
ソートはコストの高い処理です。不要なソートはすべて削除しましょう。
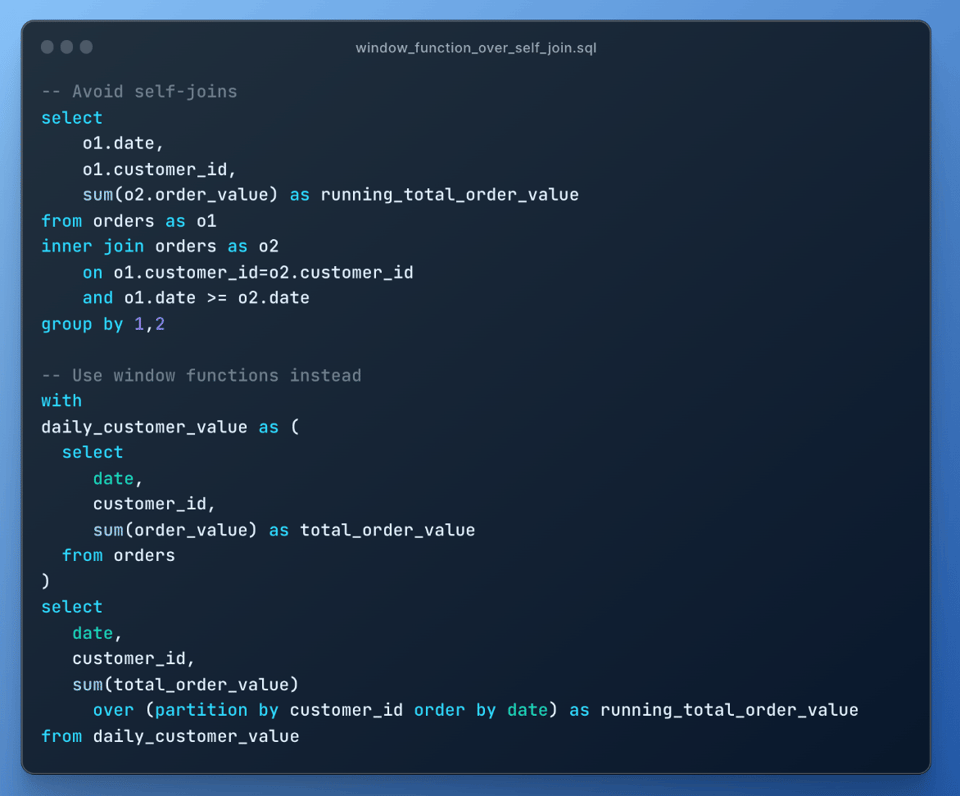
9\. セルフ結合よりウィンドウ関数を優先する
セルフ結合は結合爆発を引き起こすため非常にコストが高くなります。可能な限り、セルフ結合の代わりにウィンドウ関数を使いましょう。
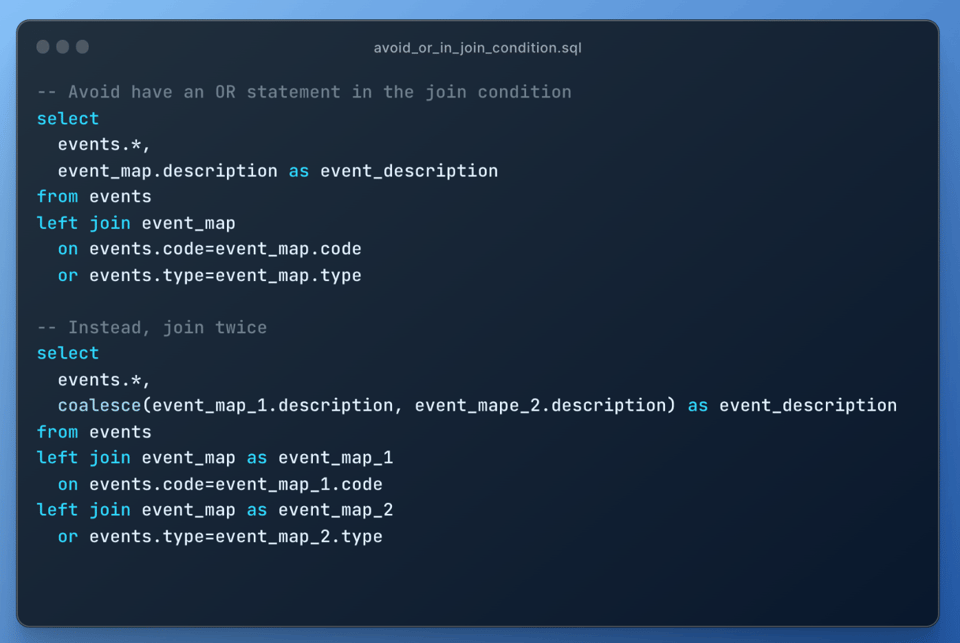
10\. OR条件を含む結合を避ける
セルフ結合と同様に、OR条件を含む結合は、後続フィルター付きのデカルト結合として実行されるため結合爆発を引き起こします。代わりに2つのLEFT JOINを使いましょう。
11\. データに関する知識を活かし、Snowflakeに効率よく処理させる
データに対する自分の知識は、クエリパフォーマンスの改善に活かせます。たとえば、多数の列でグループ化しているクエリで、いくつかの列が冗長(他の列がすでに同じか、より粗い粒度を表している)だとわかっているなら、それらの列をGROUP BYから外し、別ステップで結合し直す方が速くなる場合があります。
グループ化または結合に使う列の値が大きく偏っている(少数の値が圧倒的多数を占める)と、Snowflakeの速度に悪影響を及ぼします。よくある例は、NULL値を多く含む列でのグループ化です。そうした値を持つ行を除外して別処理で扱えば、クエリ速度を引き上げられます。
最後に、範囲結合(range join)はSnowflakeを含むあらゆるデータウェアハウスで遅くなりがちです。データ内の区間長に関する知識を使えば、結合爆発を抑えられます。範囲結合のパフォーマンスが遅い場合は、ぜひこちらの最新記事をご覧ください。
12\. 複雑なビューを避ける
ベストプラクティスとして、クエリで複雑なビューを作成・使用するのは避けましょう。ビューは、列名の変更、基本的な列の計算、軽量な結合を伴うデータモデルなど、シンプルなデータ変換を永続化する目的で使うべきです。
複雑なビューがいかに大きな問題を引き起こすか、一見何の変哲もない次のクエリで考えてみましょう。
select
a.*,
b.*
from model_a as a
left join model_b as b
on a.id=b.id
このクエリは45分以上かかって完了せず、最終的に「Incident」エラーで失敗することが繰り返されていました。
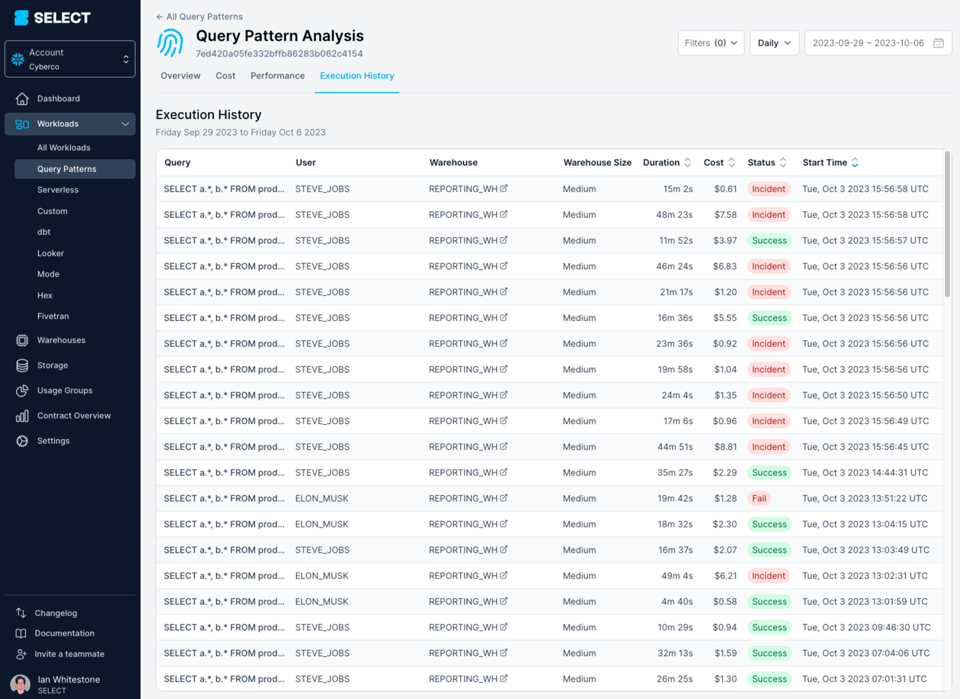
クエリプロファイル(別名「クエリプラン」)を掘り下げてみると、対象モデルが実は数百ものテーブルからなる複雑なビューだったことがわかりました。
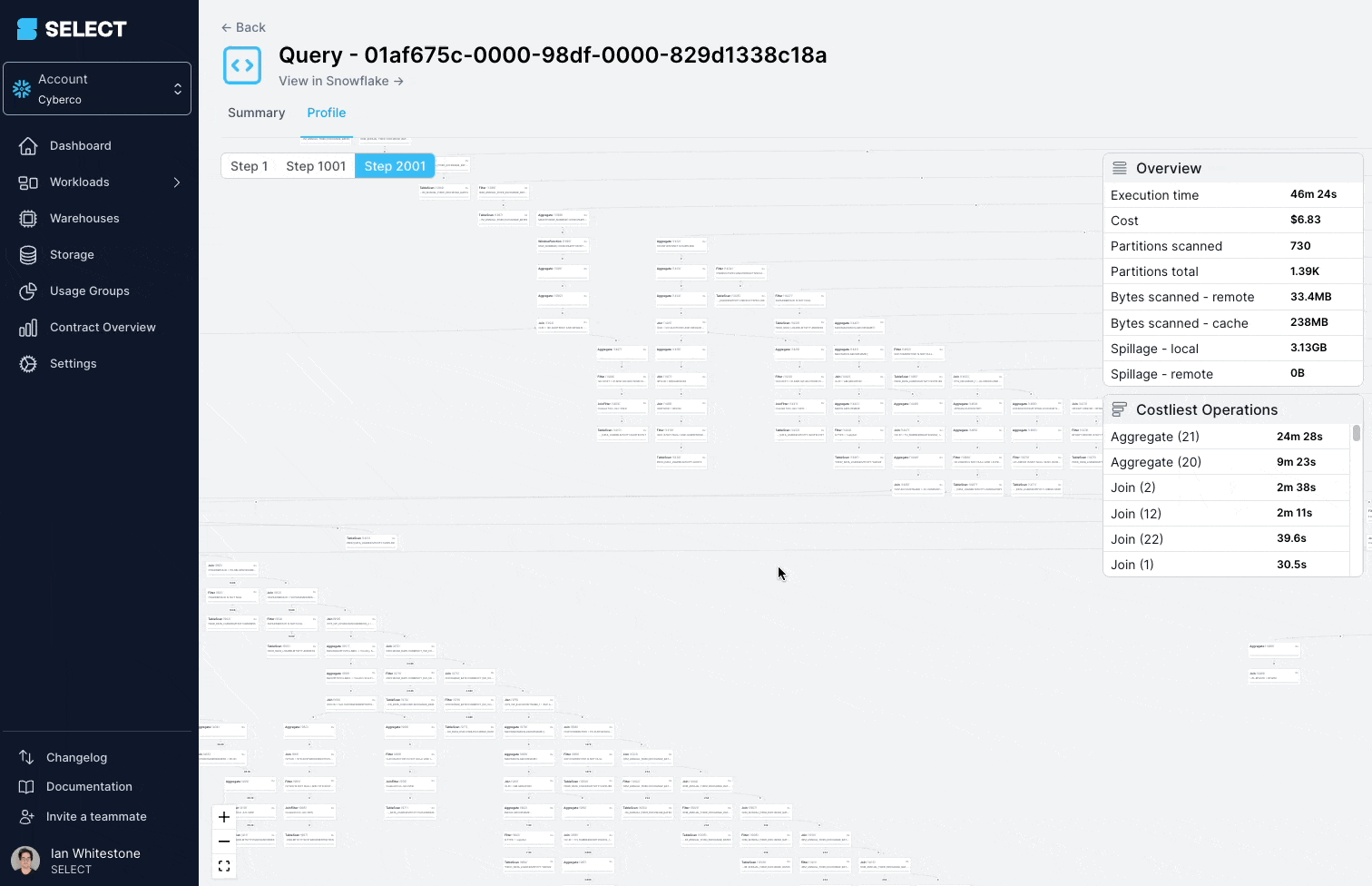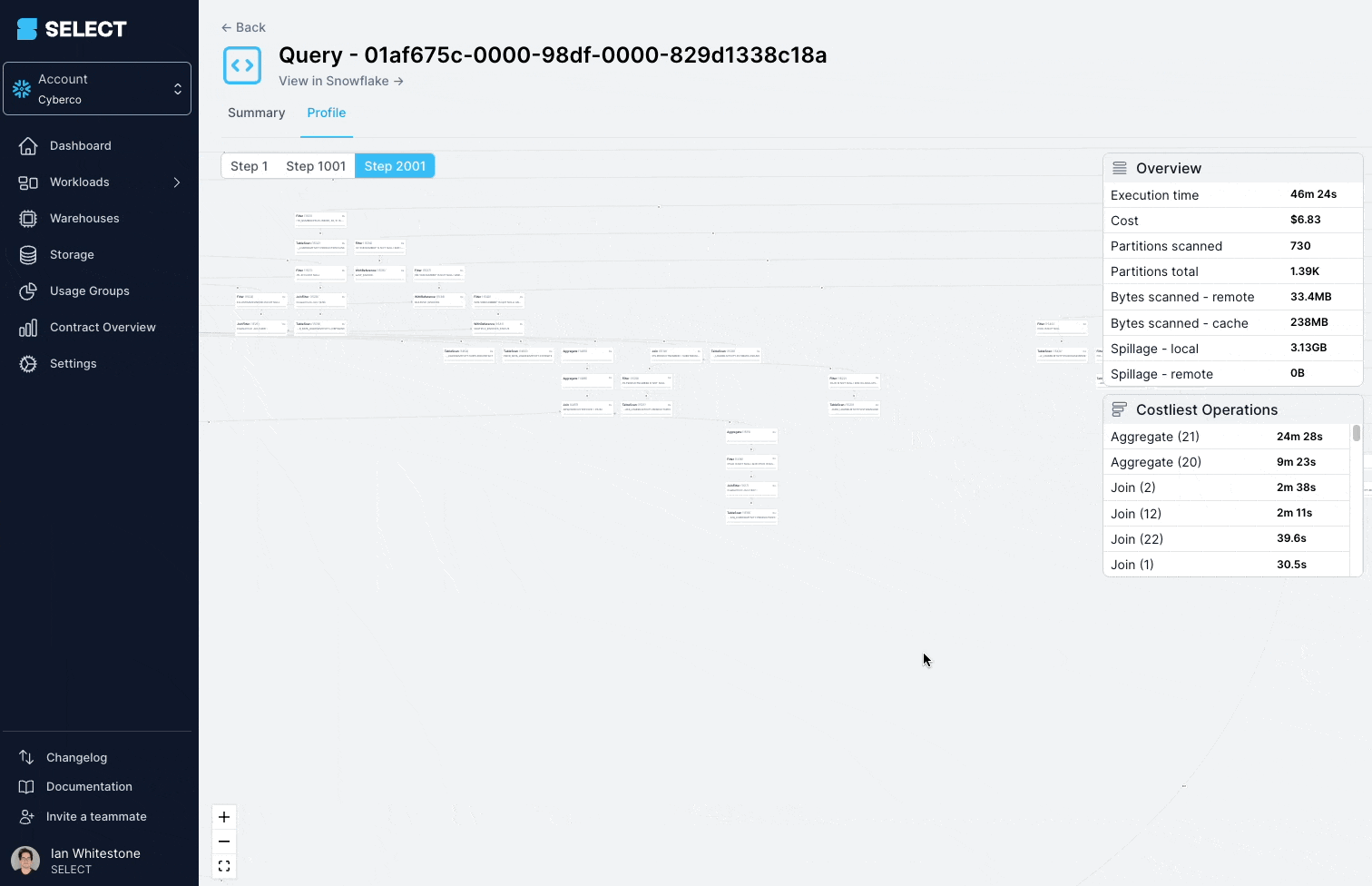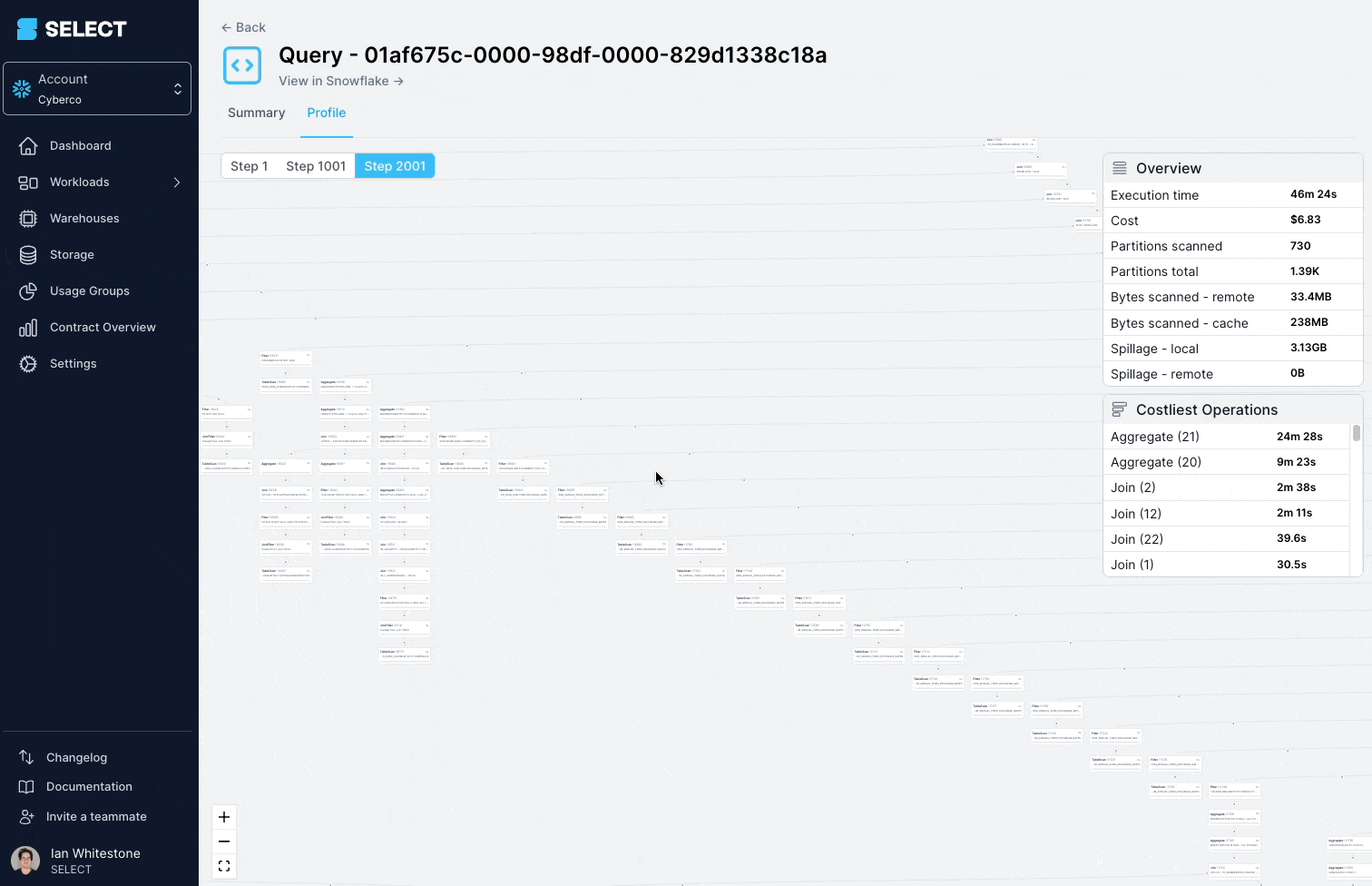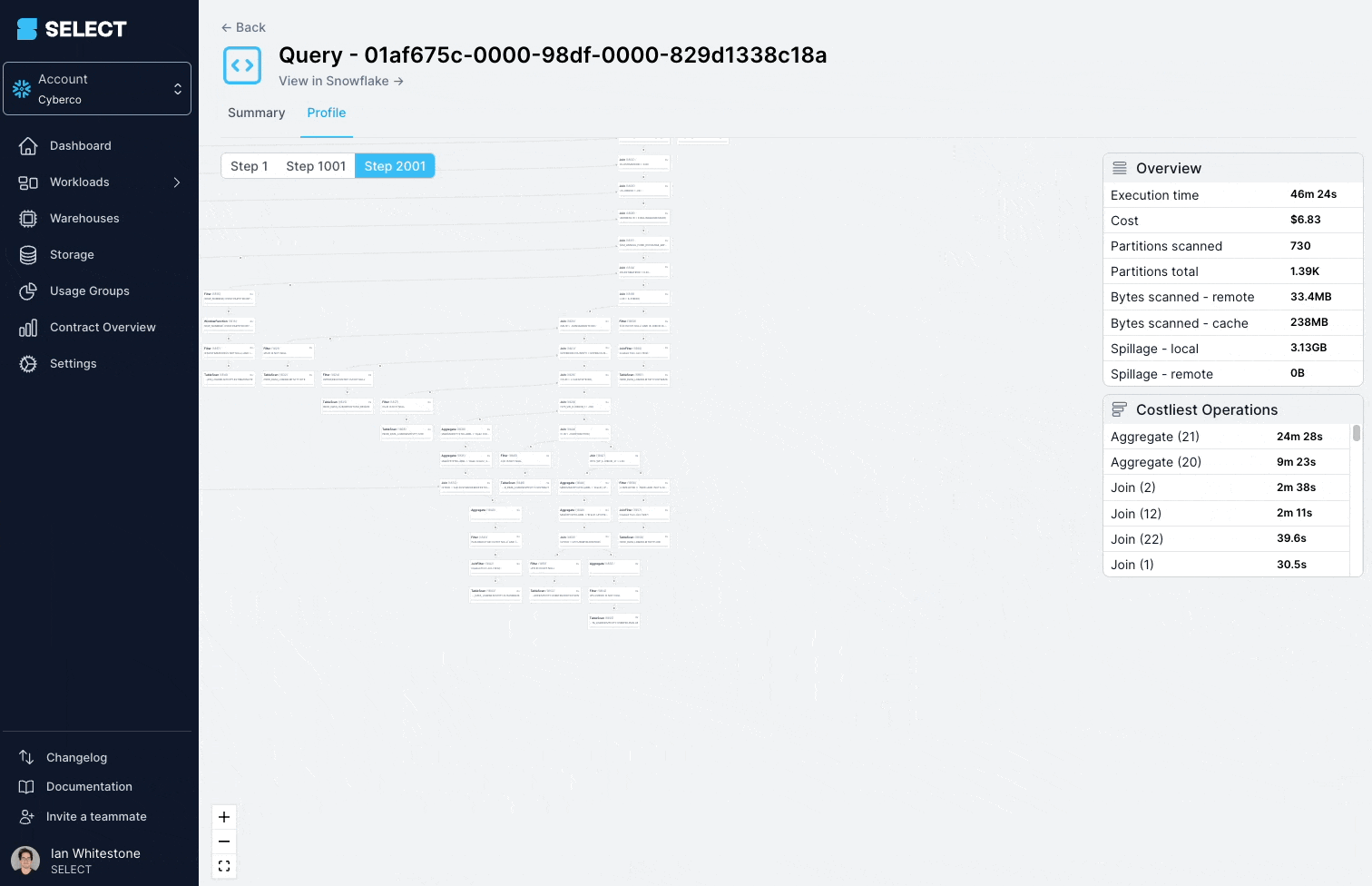
解決策は、複雑なビューをよりシンプルで小さなパーツに分割し、テーブルとして永続化することです。
13\. クエリキャッシュを効果的に活用する
仮想ウェアハウスの各ノードはローカルディスクストレージを備えており、リモートストレージから読み取ったマイクロパーティションのキャッシュとして使えます。複数のクエリが同じテーブル内のデータセットにアクセスする場合、リモートストレージではなくローカルディスクキャッシュからスキャンできるため、読み取りが主なボトルネックであればクエリの高速化につながります。
ウェアハウスを一時停止すると、再開時にキャッシュが保持される保証はありません。キャッシュが失われると、クエリは高速なローカルキャッシュではなくテーブルストレージから再スキャンする必要があります。ウェアハウスのキャッシュ消失がクエリに影響している場合は、自動一時停止のしきい値を引き上げると効果的です。
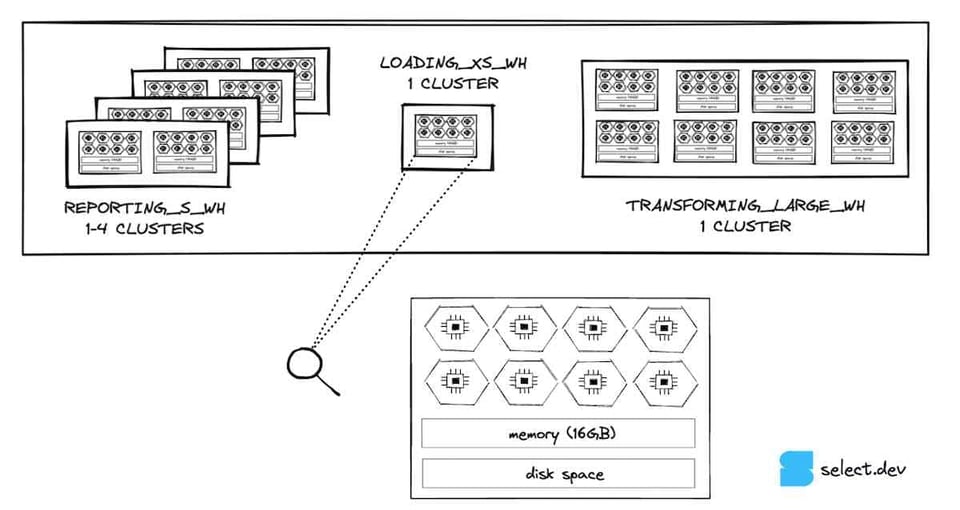
これとは別に、Snowflakeにはグローバル結果キャッシュがあり、対象テーブルのデータが変わっていない限り、24時間以内に実行された同一クエリの結果を返します。ただし、グローバル結果キャッシュを利用できない状況もあるため(例:クエリに非決定的な関数が含まれる場合など)、想定どおりにキャッシュにヒットしているかを必ず確認しましょう。ヒットしていなければ、クエリの調整が必要か、サポートに連絡してバグ報告する必要があるかもしれません。
14\. ウェアハウスサイズを大きくする
ウェアハウスサイズは、そのウェアハウス上で動作するクエリが使える総計算能力を決めるもので、垂直スケーリングとも呼ばれます。
仮想ウェアハウスのサイズを大きくすべきタイミングは次のとおりです。
- クエリがリモートディスクへスピル(書き出し)している(クエリプロファイルで確認可能)
- クエリ結果をより速く得る必要がある(通常はユーザー向けアプリケーションなど)
リモートディスクにスピルするクエリは、クエリを実行するウェアハウスと、データを格納するリモートディスクの間で大量のネットワーク通信が発生するため非効率です。ウェアハウスサイズを上げれば、利用可能なRAMとローカルディスクが両方とも倍増し、いずれもリモートディスクより格段に高速にアクセスできます。リモートディスクへのスピルが発生している場合、ウェアハウスサイズを上げることでクエリ速度が2倍以上になることもあります。Snowflakeウェアハウスサイジングとdbtでのウェアハウスサイズ設定方法については、過去記事で詳しく解説しています。
なお、ウェアハウス上のクエリの大半は大きなサイズを必要としないが、全クエリに対してサイズを上げたくないという場合は、SnowflakeのQuery Acceleration Serviceの活用も検討できます。Enterprise edition以上で利用できるこのサービスは、大量のデータをスキャンするクエリに追加の計算リソースを割り当てます。
15\. 最大クラスター数を増やす
Enterprise edition以上で使えるマルチクラスターウェアハウスを利用すると、同じサイズのウェアハウスのインスタンスを複数立ち上げられます。
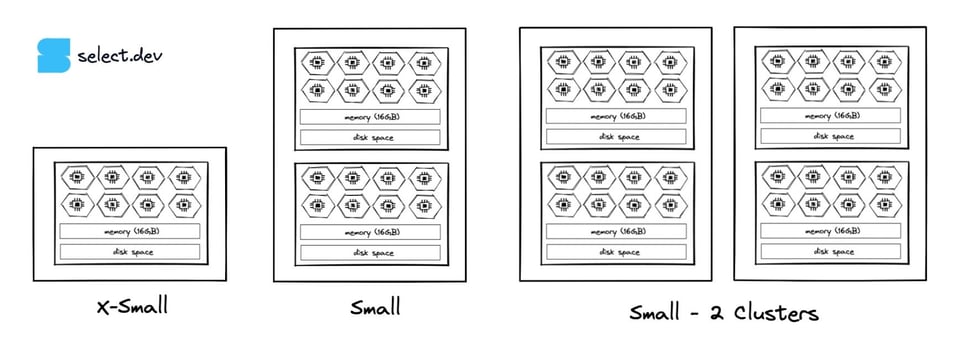
ウェアハウスのキューイングが原因でクエリが必要な処理速度を満たせない時間帯があるなら、マルチクラスタリングの導入やウェアハウスの最大クラスター数の引き上げを検討してください。これにより、クラスターを追加・削除しながらクエリ量に追随できます。
ウェアハウスのクラスター数とは異なり、Snowflakeはクエリ量に応じて仮想ウェアハウスのサイズを自動調整することはできません。そのため、変動の大きいクエリ量を処理する場合は、各クラスターがアクティブな間だけ課金されるマルチクラスターウェアハウスの方がコスト効率に優れます。
16\. クラスタースケーリングポリシーを調整する
Snowflakeには、StandardとEconomyの2つのスケーリングポリシーがあります。ユーザー向けクエリを処理するすべての仮想ウェアハウスにはStandardポリシーを使ってください。コストを強く意識する場合は、データロードのようなキューイングを許容できるワークロードに対してEconomyポリシーを試し、必要なスループットを維持しつつコストを下げられるか検証してみましょう。それ以外のウェアハウスにはStandardをおすすめします。
その他のリソース
Snowflakeクエリ最適化についてさらに学びたい方は、以下の動画リソースもぜひご覧ください。
Behind the Cape:Snowflakeコスト最適化の全3回シリーズ(2023年)
この全3回の動画シリーズでは、IanがSnowflake Data SuperheroのKeith Belanger氏とともにBehind the Capeに出演しました。Snowflakeの専門家がさまざまなテーマを掘り下げる動画シリーズです。
第1回
このエピソードでは、Snowflakeコスト最適化という大きなテーマに取り組みました。時間が30分しかなかったため、進め方、Snowflakeの課金モデル、Snowflakeが提供するコスト管理ツールについて、概観を整理する内容となりました。
取り上げたトピックの一覧です。
- Snowflakeコスト最適化はどう始めるべきか?(要約:最適化に着手する前に、まずコストドライバーを総合的に把握する)
- 多くのユーザーが現状どこまでSnowflake利用を理解しているか
- Snowflakeの課金モデルの仕組み(Snowflakeでデータを保管する方が実は安いことをご存じでしたか?)
- Snowflakeが提供するコスト可視化ツール
- コストをコントロールする方法(リソースモニター、クエリタイムアウト、そして誰も思いつかないACCESS CONTROL!)
- コスト削減はどこから始めるべきか?クエリ最適化から?それともより上位レベルから?
- さらに学ぶためのリソース
コスト最適化、モニタリング、コントロールの全体像を知りたい方には最適な出発点です。録画は以下からご覧いただけます。このテーマは語り尽くせないほど内容が多く、深掘りしきれなかったので、近いうちに続編を予定しています!
Play
第2回
このエピソードでは、Snowflakeクエリ最適化における重要な基礎概念をさらに掘り下げます。
- Snowflakeクエリのライフサイクル
- Snowflake仮想ウェアハウスのサイジング
- Snowflakeクエリプロファイルの使い方とボトルネックの特定
Play
第3回
シリーズ最終回では、最も重要なクエリ最適化テクニックを掘り下げます。
Play
Snowflake Optimization Power Hour動画(2022年)
2022年9月28日、IanはSnowflake Toronto User Groupで、Snowflakeのパフォーマンスチューニングとコスト最適化について発表しました。取り上げた内容は次のとおりです。
- Snowflakeのアーキテクチャ
- Snowflakeクエリのライフサイクル
- Snowflakeの課金モデル
- コスト最適化のシンプルなフレームワークと、クエリ単位のコスト算出方法の詳細
- ウェアハウス設定のベストプラクティス
- テーブルクラスタリングのコツ
スライド
スライドはこちらからご覧いただけます。スライドの操作には、右下の矢印をクリックするか、キーボードの矢印キーを使ってください。「esc」または「o」キーを押すと「概要」モードに切り替わり、全スライドを一覧できます。そこから再び矢印キーで移動し、スライドをクリックするか「esc」/「o」を押せばそのスライドにフォーカスできます。
プレゼンテーション録画
プレゼンの録画はYouTubeで視聴可能です。プレゼンは3:29から始まります。
Play
ご希望であれば、皆さまのチームに直接お伺いしてこのプレゼン(またはそのバリエーション)を行い、質疑応答の機会を設けることも可能です。ご興味があれば[email protected]までメールでご連絡ください。
Query Optimization at Snowflake(2020年)
Snowflakeのクエリオプティマイザー内部をもっと深く理解したい方には、Snowflakeの上級データベースエンジニアであるJiaqi Yan氏によるこちらの講演を強くおすすめします。
Play
Ian Whitestone・Co-founder & CEO of SELECT
Ianは、SaaS型のSnowflakeコスト管理・最適化プラットフォームSELECTの共同創業者兼CEOです。SELECTを立ち上げる前は、ShopifyとCapital Oneでフルスタックのデータサイエンス&エンジニアリングチームを6年間率いていました。Shopifyでは、データウェアハウスの最適化とコスト可視化の推進を主導しました。
Niall Woodward・Co-founder & CTO of SELECT
Niallは、SaaS型のSnowflakeコスト管理・最適化プラットフォームSELECTの共同創業者兼CTOです。SELECTを立ち上げる前は、Brooklyn Data Companyや複数のスタートアップでデータエンジニアを務めていました。オープンソース愛好家でもあり、SQLFluffのメンテナーを務めるほか、dbt_artifacts、dbt_snowflake_monitoring、dbt_query_tagsという3つのdbtパッケージの作者でもあります。