A enorme popularidade do Snowflake vem da sua capacidade de processar grandes volumes de dados com latência muito baixa e configuração mínima. Não à toa, virou queridinho dos times de dados em milhares de empresas. Neste guia, reunimos técnicas de otimização para extrair o máximo de desempenho e eficiência do Snowflake. Siga estas boas práticas para acelerar suas queries e, de quebra, reduzir custos.
Todas as técnicas de performance tuning do Snowflake abordadas neste post vêm de estratégias reais que a SELECT ajudou mais de 100 clientes do Snowflake a colocar em prática. Se você acha que ficou algo de fora, queremos saber! Fale com a gente por e-mail ou pelo chat no canto da tela.
Este post trata de técnicas de otimização de queries e de como aproveitá-las para deixar suas consultas no Snowflake mais rápidas. Isso pode ajudar a reduzir custos, mas, se esse for o seu foco principal, há pontos de partida melhores. Não deixe de conferir o nosso post sobre otimização de custos no Snowflake com estratégias práticas para gastar menos.
Técnicas de otimização de queries no Snowflake
As técnicas de otimização de desempenho de queries no Snowflake abordadas neste post se enquadram, de modo geral, em três categorias:
1. Melhorar a eficiência de leitura dos dados
Em alguns casos, as queries gastam um tempo considerável lendo dados do armazenamento das tabelas. Essa etapa aparece como TableScan no query profile. O TableScan envolve baixar dados pela rede, do local de armazenamento da tabela até os nós de trabalho do virtual warehouse. Para acelerar esse processo, é preciso reduzir o volume de dados baixados ou aumentar o tamanho do virtual warehouse.
O Snowflake lê apenas as colunas selecionadas em uma query e as micro-partições relevantes para os filtros da query — desde que as micro-partições da tabela estejam bem clusterizadas pela condição do filtro.
As quatro técnicas para reduzir os dados baixados por uma query e, assim, acelerar os TableScans são:
- Reduzir o número de colunas acessadas
- Aproveitar o query pruning e o clustering de tabelas
- Usar colunas clusterizadas nos predicados de join
- Usar tabelas pré-agregadas
2. Melhorar a eficiência de processamento dos dados
Operações como Joins, Sorts e Aggregates acontecem depois dos TableScans e costumam ser o gargalo das queries. Entre as estratégias para otimizar o processamento estão reduzir o número de etapas da query, processar os dados de forma incremental e usar o seu conhecimento dos dados para ganhar desempenho.
As técnicas para melhorar a eficiência de processamento incluem:
- Simplificar e reduzir o número de operações da query
- Reduzir o volume de dados processados aplicando filtros cedo
- Evitar referências repetidas a CTEs
- Remover sorts desnecessários
- Preferir window functions a self-joins
- Evitar joins com condição OR
- Usar seu conhecimento dos dados para ajudar o Snowflake a processá-los com eficiência
- Evitar consultas a views complexas
- Garantir o uso eficaz dos query caches
3. Otimizar a configuração do warehouse
Os virtual warehouses do Snowflake podem ser configurados com facilidade para suportar workloads maiores e com mais concorrência. As principais configurações que melhoram o desempenho são:
- Aumentar o tamanho do warehouse
- Aumentar o cluster count do warehouse
- Alterar a scaling policy do warehouse
Antes de partir para as otimizações, vale relembrar como identificar o que está deixando uma query lenta.
Como otimizar uma query no Snowflake
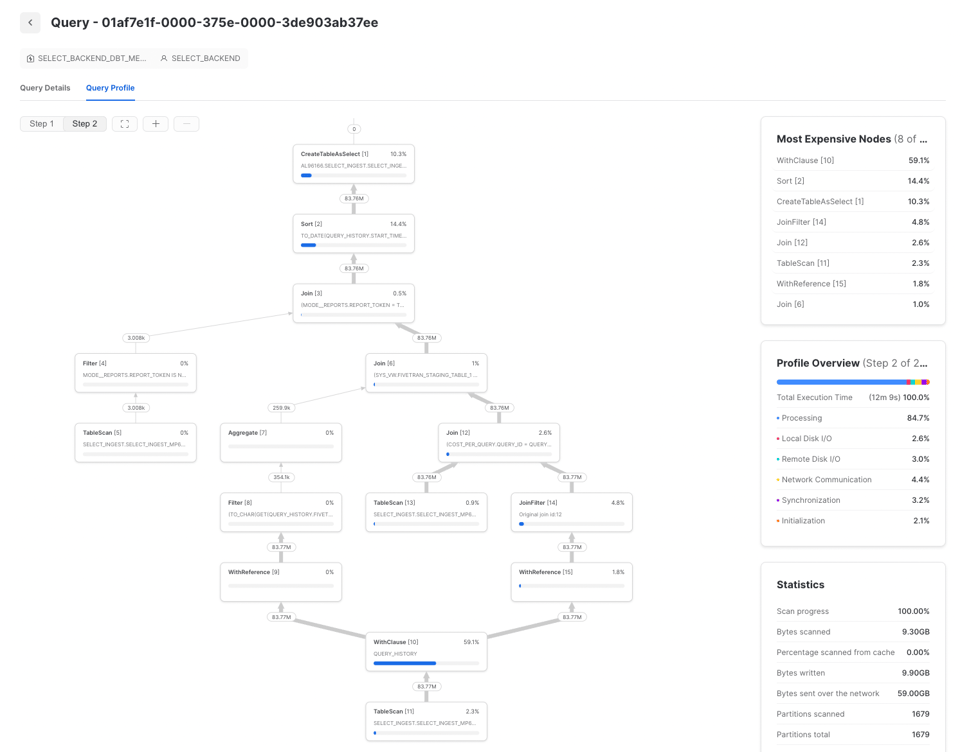
Antes de otimizar uma query no Snowflake, é fundamental entender qual é o gargalo real, e isso se faz com query profiling. Quais operações estão deixando a query lenta e, portanto, onde concentrar os esforços?
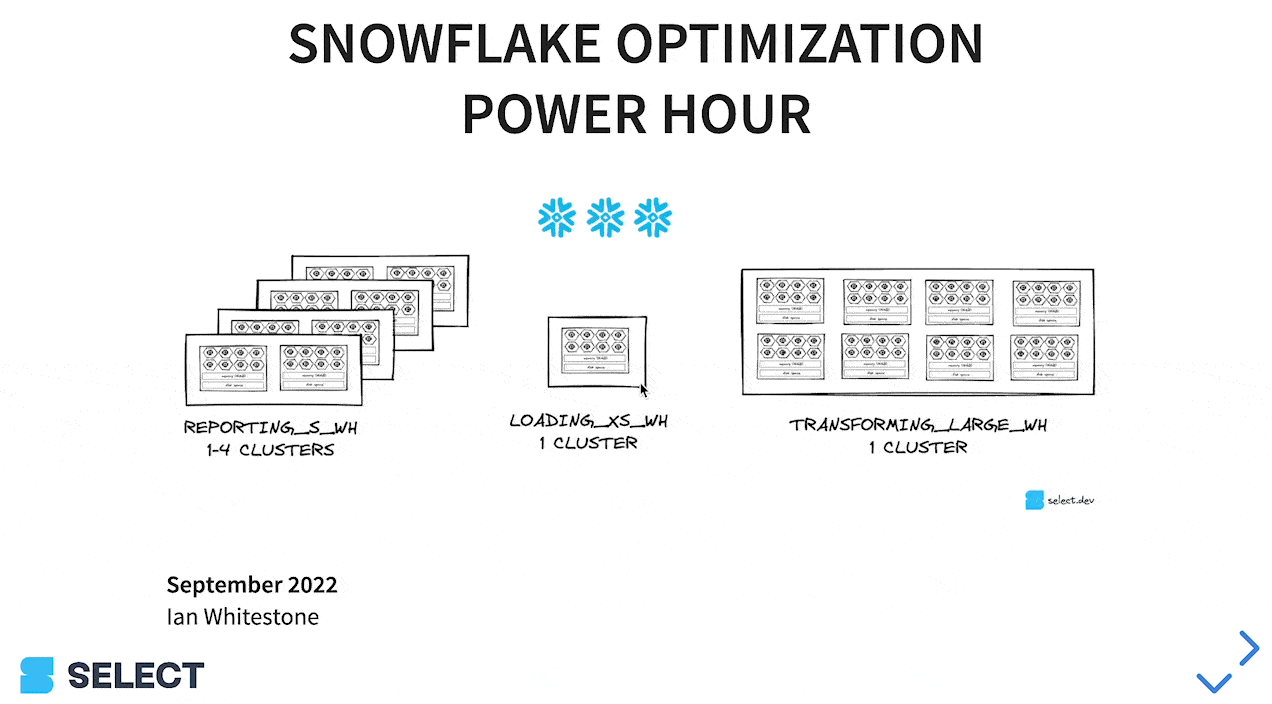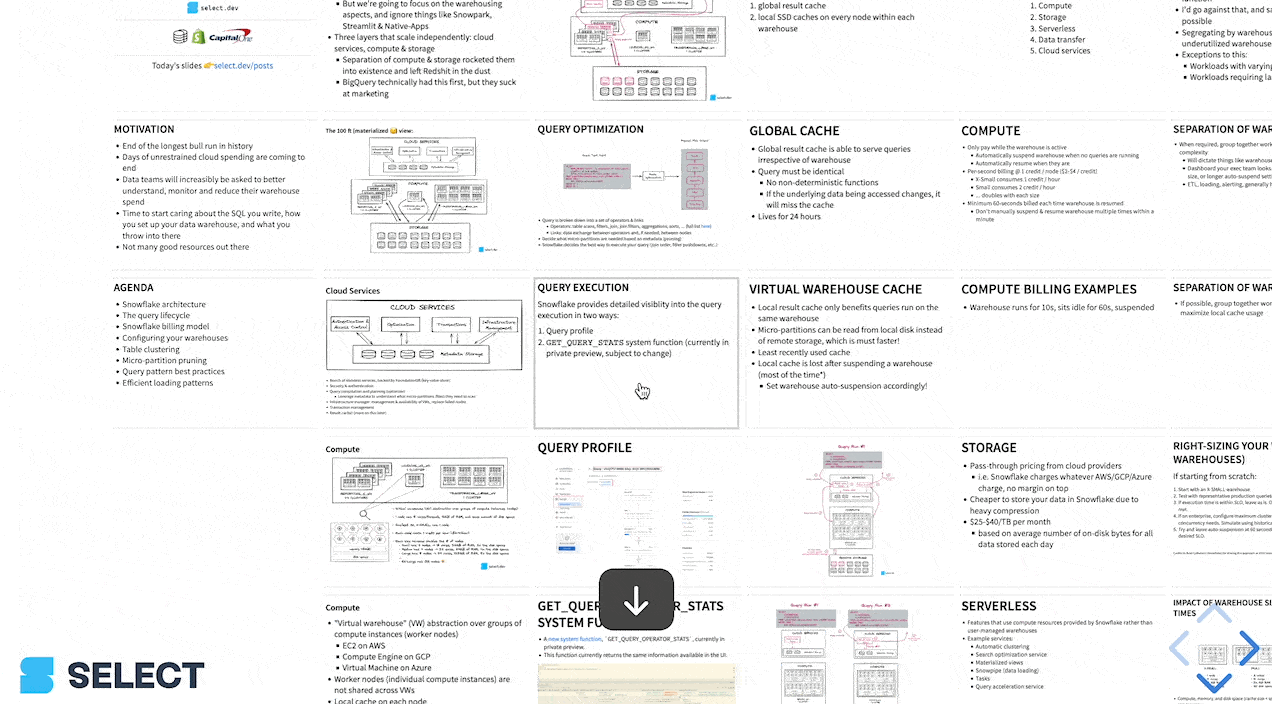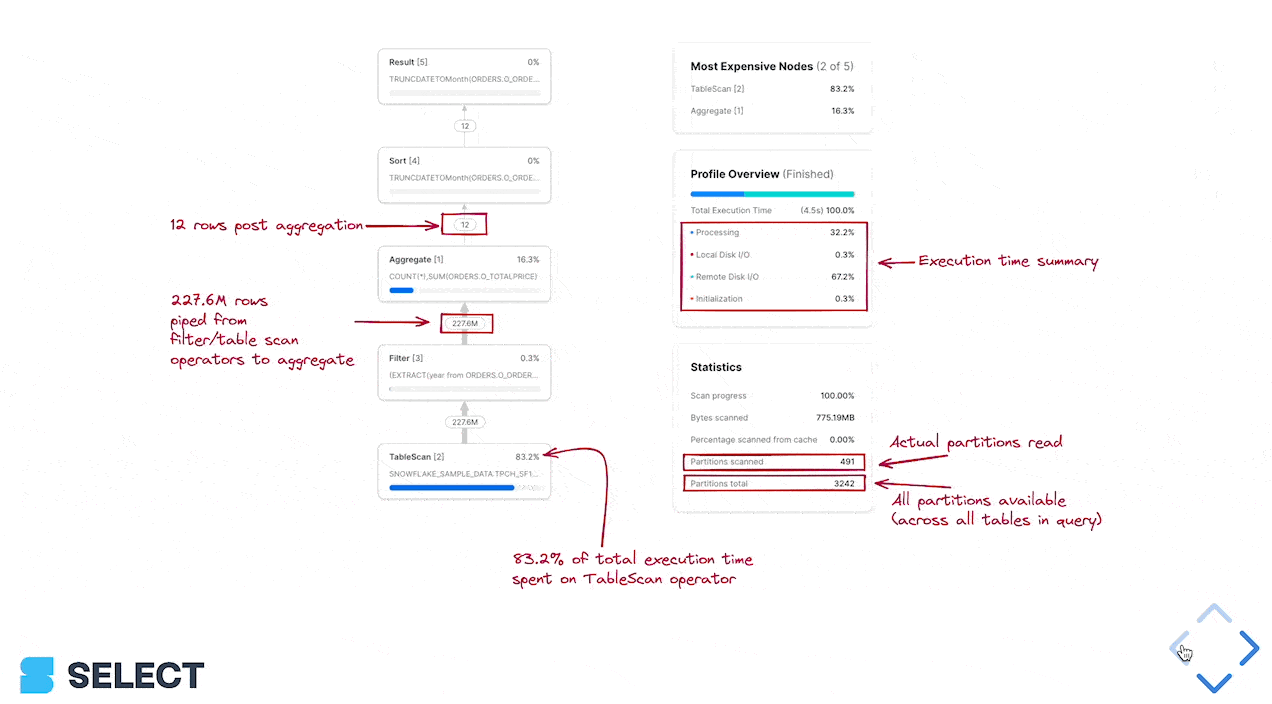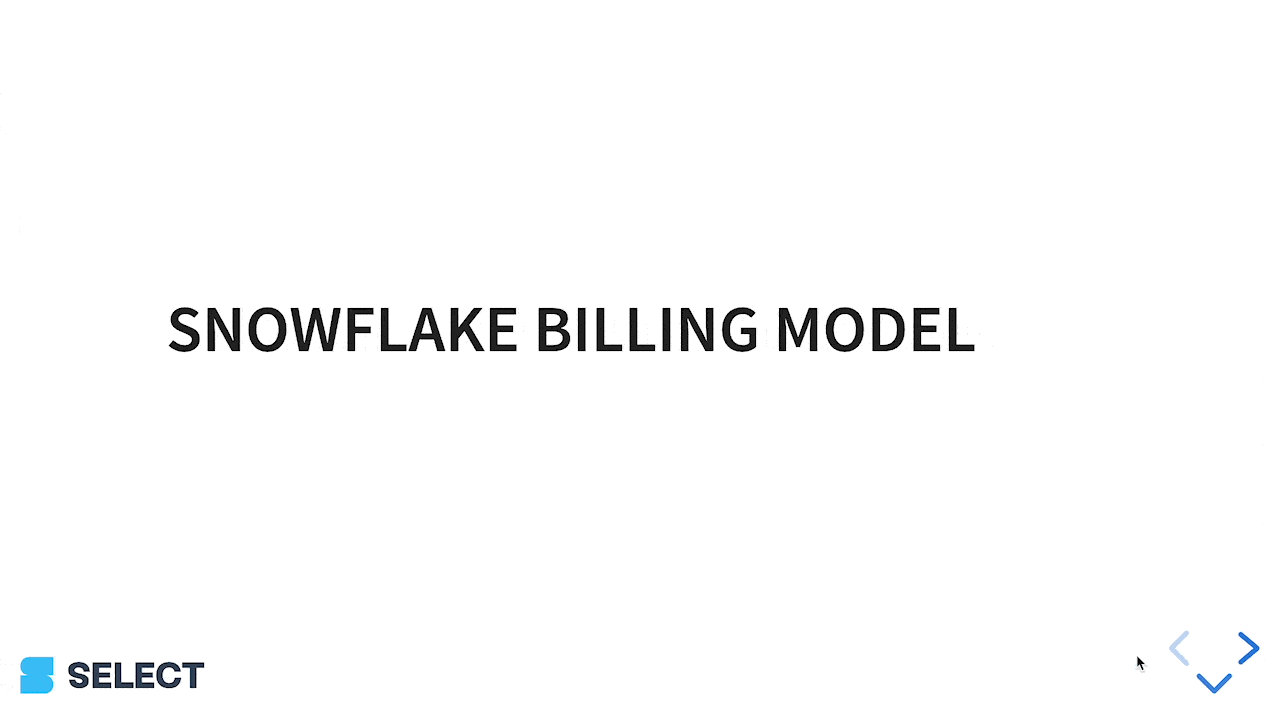
Para descobrir, use o Query Profile (plano de execução) do Snowflake e olhe a seção 'Most Expensive Nodes'. Ela mostra quais partes da query consomem mais tempo de execução.
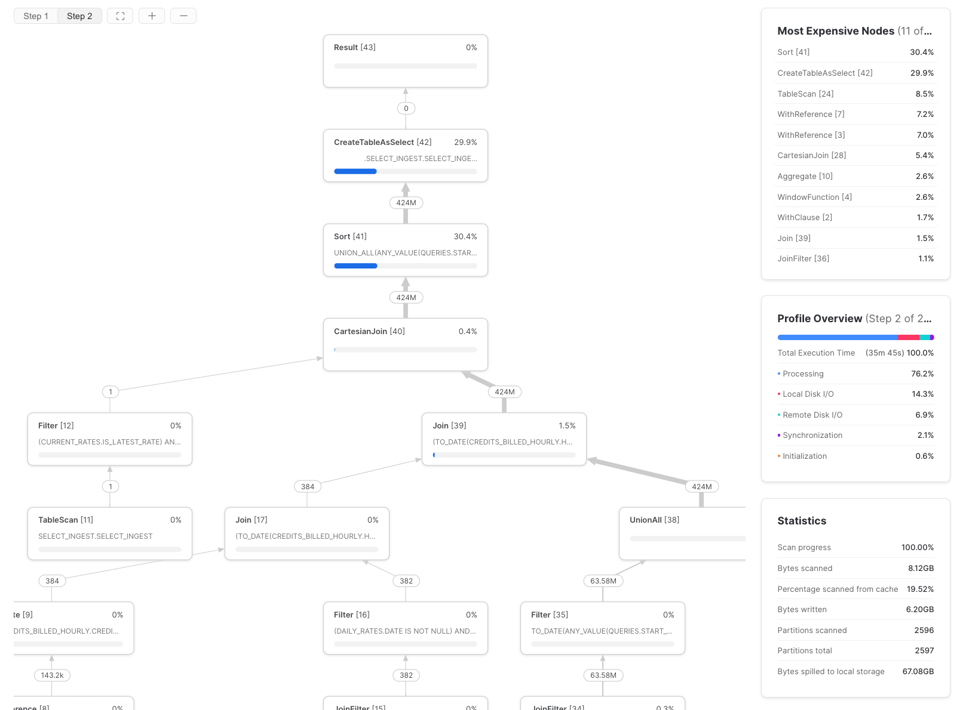
Neste exemplo, dá para ver que o gargalo está na etapa de Sort, o que indica que devemos focar em melhorar a eficiência de processamento e, possivelmente, aumentar o tamanho do warehouse. Quando os nós mais caros são TableScans, o melhor é direcionar o esforço para otimizar a eficiência de leitura dos dados.
1\. Selecione menos colunas
É algo simples, mas, quando dá para fazer, faz uma baita diferença. Os requisitos das queries mudam com o tempo, e colunas que antes eram úteis podem não ser mais necessárias para os processos downstream. O Snowflake armazena dados em um formato de arquivo híbrido-colunar chamado micro-partições. Esse formato permite ao Snowflake reduzir o volume de dados lidos do armazenamento. O processo de baixar dados das micro-partições é chamado de scan, e reduzir o número de colunas significa menos transferência pela rede.
2\. Aproveite o query pruning
Para reduzir o número de micro-partições escaneadas por uma query — técnica conhecida como query pruning —, algumas coisas precisam acontecer:
- A query precisa incluir um filtro que limite os dados necessários. Pode ser um filtro
whereexplícito ou um filtrojoinimplícito. - A tabela precisa estar bem clusterizada pela coluna usada no filtro.
Rodar a query abaixo contra a tabela hipotética orders do diagrama vai gerar query pruning porque (a) a tabela orders está clusterizada por created_at (os dados estão ordenados por created_at) e (b) a cláusula where filtra explicitamente created_at por uma data específica.
select *
from orders
where created_at > '2022/08/14'

Para saber se o desempenho do pruning pode melhorar, olhe as estatísticas Partitions scanned e Partitions total no query profile.
Se a query não usa filtro na cláusula where, adicionar um pode acelerar muito o TableScan (e também os nós downstream, que vão processar menos dados). Se ela já tem filtro no where, mas as 'Partitions scanned' estão próximas das 'Partitions total', significa que o where não está sendo efetivamente podado.
Para melhorar o pruning:
- Coloque as cláusulas where o mais cedo possível na query; caso contrário, elas podem não ser 'empurradas para baixo' até a etapa de TableScan (o que também acelera as etapas seguintes)
- Adicione colunas bem clusterizadas nas condições de join e merge — elas podem ser empurradas como JoinFilters e habilitar o pruning
- Garanta que as colunas usadas nos filtros where da query estejam alinhadas com o clustering da tabela (saiba mais sobre clustering aqui)
- Evite usar funções nas condições where — elas costumam impedir o Snowflake de podar micro-partições
3\. Use colunas clusterizadas nos predicados de join
A forma mais comum de pruning, e que a maioria dos usuários conhece, é o static query pruning. Aqui vai um exemplo simples, parecido com o anterior:
select *
from orders
where order_date > current_date - 7
Se a tabela orders estiver clusterizada por order_date, o otimizador de queries do Snowflake vai reconhecer que a maioria das micro-partições (arquivos) com dados de mais de 7 dias atrás pode ser ignorada. Como escanear dados remotos exige bastante tempo de processamento, eliminar micro-partições acelera muito a query.
Um recurso menos conhecido do motor de queries do Snowflake é o dynamic pruning. Diferente do static pruning, que acontece antes da execução, na fase de planejamento, o dynamic query pruning ocorre em tempo real, conforme a query é executada.
Considere um processo que atualiza regularmente registros existentes na tabela orders por meio de um comando MERGE. Por baixo dos panos, um MERGE exige um join entre a tabela source (com os registros novos/atualizados) e a tabela target (orders) que queremos atualizar.
O dynamic pruning entra em ação durante o join. Como funciona? Conforme o motor de queries do Snowflake lê os dados da tabela source, ele identifica o intervalo de registros presentes e empurra automaticamente uma operação de filtro para a tabela target, evitando varreduras desnecessárias.
Vamos a um exemplo. Imagine que temos uma tabela source com 3 registros para atualizar na tabela target orders, clusterizada por data do pedido. Um MERGE típico faria a correspondência entre os registros das duas tabelas usando uma chave única, como a order key. Como essas chaves únicas costumam ser aleatórias, elas não forçam nenhum query pruning. Mas se modificarmos a condição do MERGE para casar registros por order key e order date, o dynamic query pruning pode entrar em cena. Conforme o Snowflake lê os dados da tabela source, ele detecta o intervalo de datas coberto pelos 3 pedidos que estamos atualizando. Em seguida, empurra esse intervalo como filtro no lado target, evitando escanear a tabela grande inteira.

Como aplicar isso no dia a dia? Se você tem operações MERGE ou JOIN em que muito tempo é gasto escaneando a tabela target (à direita), avalie se dá para introduzir predicados adicionais na cláusula de join que forcem o query pruning. Atenção: isso só funciona se (a) a tabela target estiver clusterizada por alguma chave e (b) a tabela source (à esquerda) com a qual você está fazendo o join tiver um intervalo bem restrito de registros na chave de cluster (ou seja, um subconjunto de datas de pedido).
Ao usar a estratégia de materialização incremental no dbt, uma query MERGE é executada por baixo dos panos. Para adicionar uma condição extra de join que force o dynamic pruning, atualize o array unique_key incluindo a coluna adicional (por exemplo, updated_at).
{{ config(
materialized='incremental',
unique_key=['order_id', 'updated_at'],
) }}
select *
from {{ ref('stg_orders') }}
...
4\. Use tabelas pré-agregadas
Crie tabelas de 'rollup' ou 'derivadas' com menos linhas. Tabelas pré-agregadas costumam ser projetadas para entregar as informações que a maioria das queries precisa, ocupando menos espaço de armazenamento. Isso as deixa muito mais rápidas de consultar. No varejo, uma estratégia comum é usar uma tabela diária de rollup de pedidos para relatórios financeiros e de estoque, consultando a tabela bruta de pedidos só quando é preciso ter a granularidade por pedido.
5\. Simplifique!
Cada operação de uma query consome tempo para movimentar dados entre as worker threads. Consolidar e remover operações desnecessárias diminui a transferência pela rede para executar a query. Também ajuda o Snowflake a reaproveitar cálculos e economizar trabalho. Na maior parte do tempo, CTEs e subqueries não impactam o desempenho, então use à vontade para melhorar a legibilidade.
De modo geral, fazer cada query realizar menos coisas facilita o debug. E ainda reduz a chance de o otimizador de queries do Snowflake tomar a decisão errada (por exemplo, escolher a ordem errada de joins).
6\. Reduza o volume de dados processados
Quanto menos dados, mais rápido cada etapa de processamento termina. Reduzir o número de colunas e linhas processadas em cada etapa de uma query melhora o desempenho.
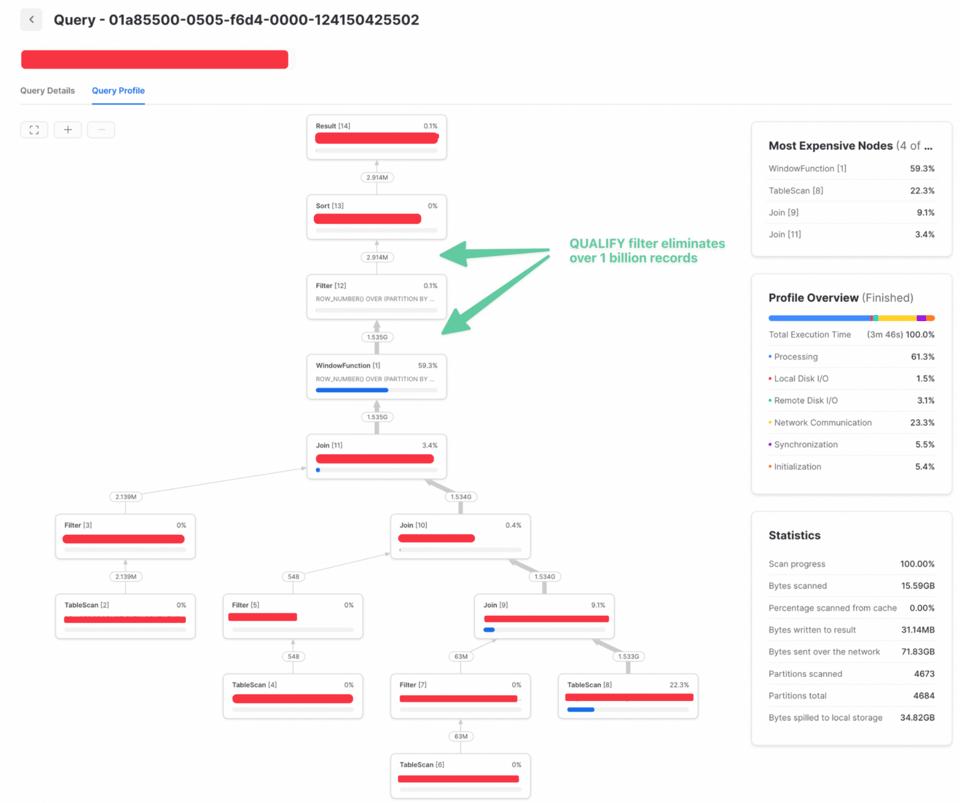
Veja um exemplo em que mover um filtro qualify para mais cedo na query rendeu um ganho de 3x no tempo de execução. O primeiro query profile mostra o tempo de execução quando o filtro QUALIFY acontecia depois de um join.
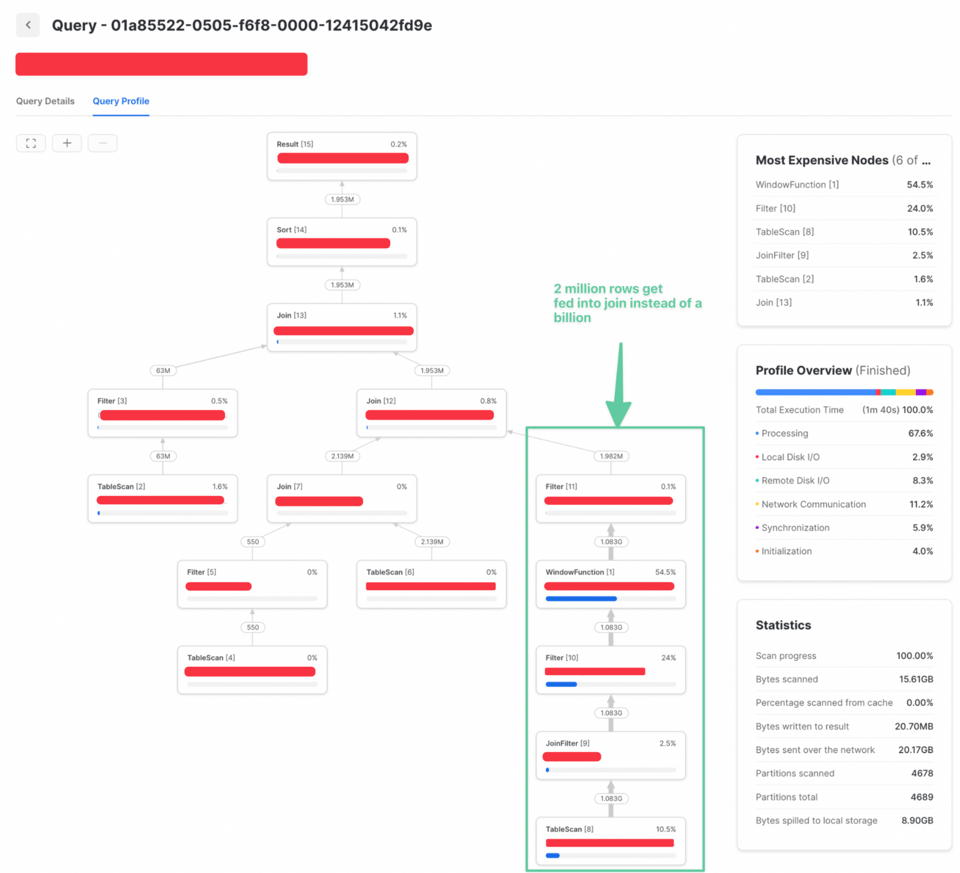
Como o filtro QUALIFY não dependia de informações posteriores ao join, foi possível movê-lo para mais cedo na query. Isso reduz bastante o volume de dados sendo unido e melhora muito o desempenho:
Para queries de transformação que gravam em outra tabela, uma forma poderosa de reduzir o volume de dados processados é a incrementalização. No exemplo da tabela orders, dá para configurar a query para processar apenas pedidos novos ou atualizados e fazer o merge desses resultados na tabela existente.
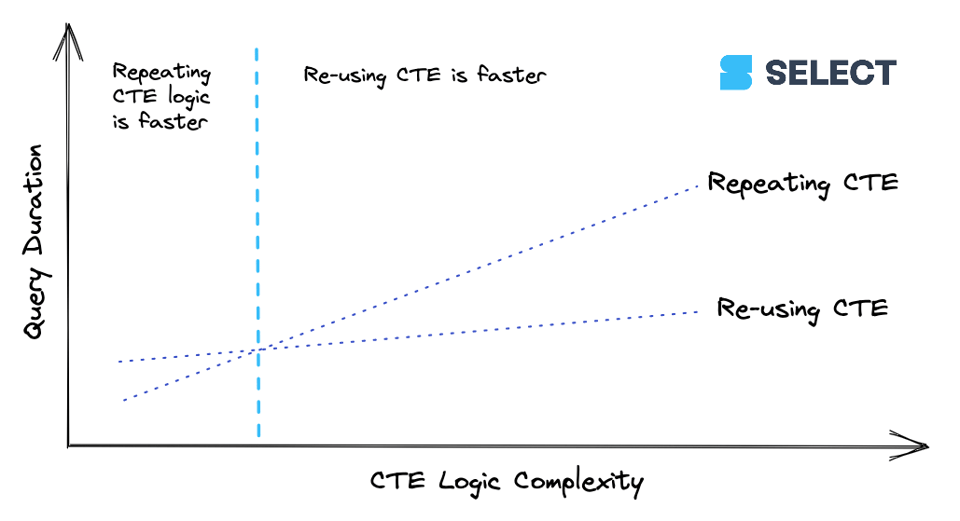
7\. Repetir CTEs pode ser mais rápido, em alguns casos
Já escrevemos antes sobre se vale a pena usar CTEs no Snowflake. Sempre que você referencia uma CTE mais de uma vez na sua query, aparece uma operação WithClause no query profile (veja o exemplo abaixo). Em certos cenários, isso pode deixar a query mais lenta, e pode ser mais eficiente reescrever a CTE a cada referência.
Quando uma CTE atinge certo nível de complexidade, sai mais barato calculá-la uma vez e passar os resultados para as referências downstream do que recalculá-la várias vezes. Esse comportamento, porém, não é consistente, então o melhor é testar. Aqui vai uma forma de visualizar essa relação:
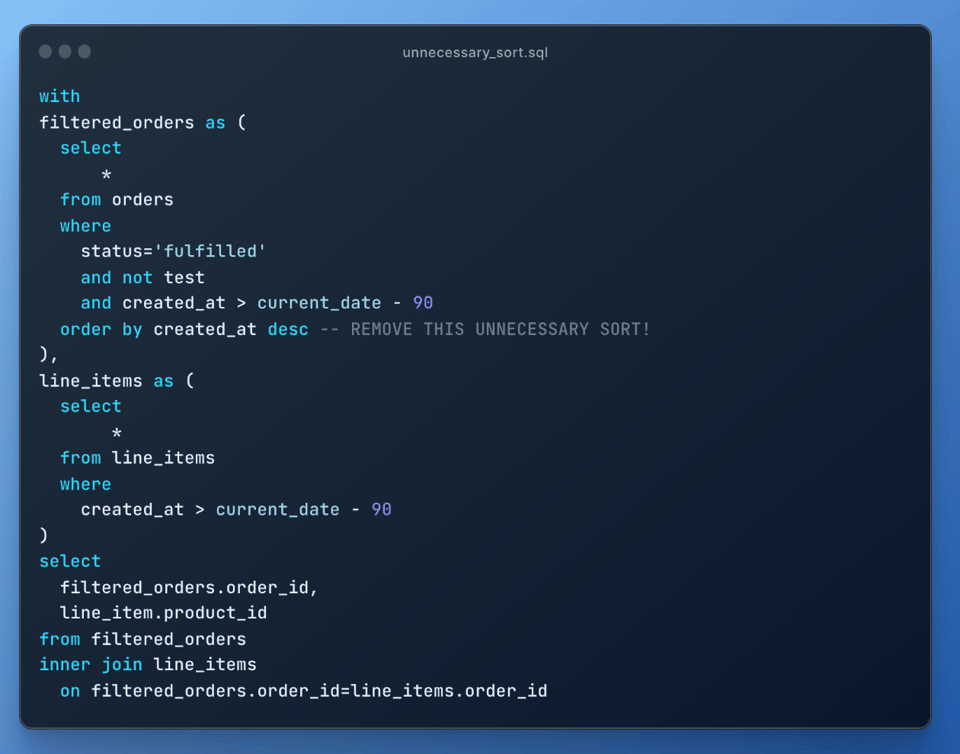
8\. Remova sorts desnecessários
Ordenação é uma operação cara, então certifique-se de remover qualquer sort que não seja necessário:
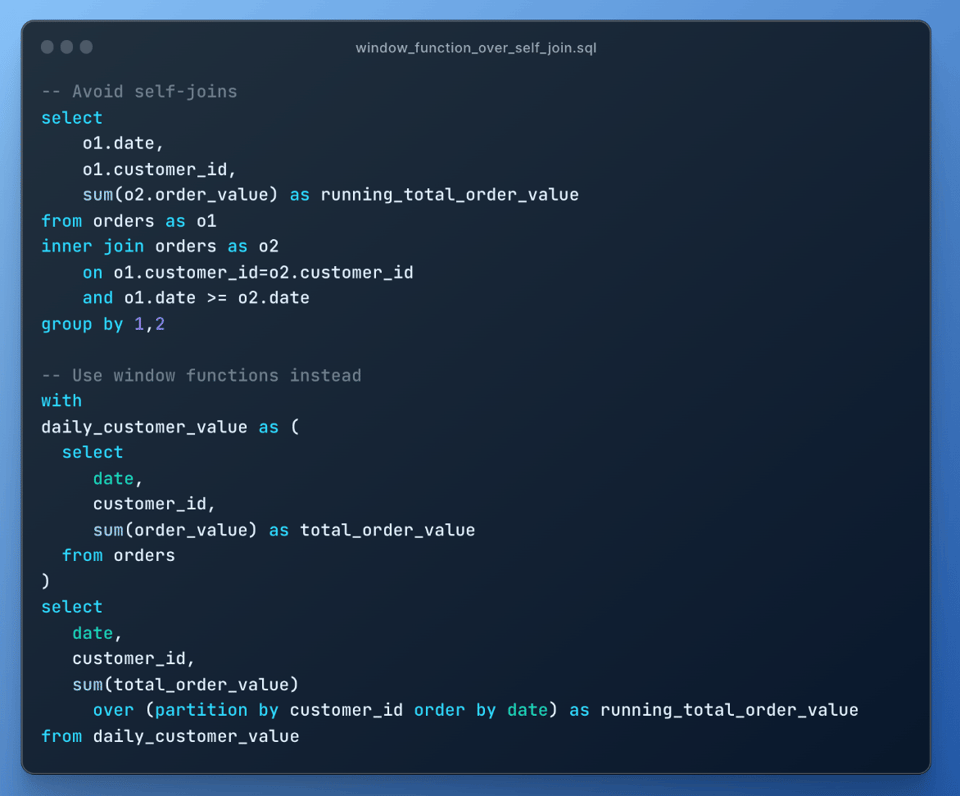
9\. Prefira window functions a self-joins
Em vez de usar um self join, prefira window functions sempre que possível, já que self joins são muito caros e geram uma explosão de join:
10\. Evite joins com condição OR
Assim como os self-joins, joins com condição OR causam explosão de join, pois são executados como um join cartesiano com um pós-filtro. Use dois left joins no lugar:
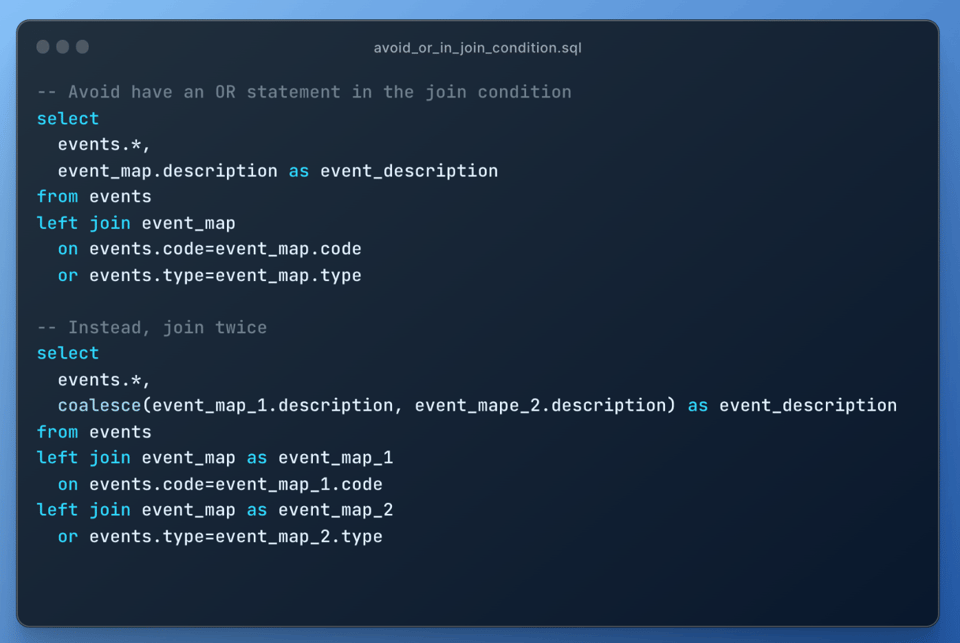
11\. Use seu conhecimento dos dados para ajudar o Snowflake a processá-los com eficiência
O seu próprio conhecimento dos dados pode ser usado para melhorar o desempenho das queries. Por exemplo, se uma query faz group by em muitas colunas e você sabe que algumas são redundantes (porque outras já representam a mesma granularidade ou uma maior), pode ser mais rápido tirá-las do group by e voltar a juntá-las em uma etapa separada.
Se uma coluna usada para agrupamento ou join é fortemente desbalanceada (ou seja, poucos valores distintos aparecem com muito mais frequência que os demais), isso pode prejudicar a velocidade do Snowflake. Um exemplo clássico é agrupar por uma coluna com muitos valores nulos. Filtrar as linhas com esses valores e processá-las em uma operação à parte pode deixar a query mais rápida.
Por fim, range joins podem ser lentos em qualquer data warehouse, inclusive no Snowflake. Seu conhecimento sobre o tamanho dos intervalos nos dados pode ser usado para reduzir a explosão de join que ocorre. Confira o nosso post recente se você estiver enfrentando baixo desempenho em range joins.
12\. Evite views complexas
Como boa prática, evite criar e usar views complexas nas suas queries. As views devem ser usadas para persistir transformações simples — como renomear colunas, fazer cálculos básicos ou modelos de dados com joins leves.
Para entender o estrago que views complexas podem causar, considere a seguinte query, aparentemente inofensiva:
select
a.*,
b.*
from model_a as a
left join model_b as b
on a.id=b.id
Essa query estava demorando mais de 45 minutos para rodar e falhando com um "Incident".
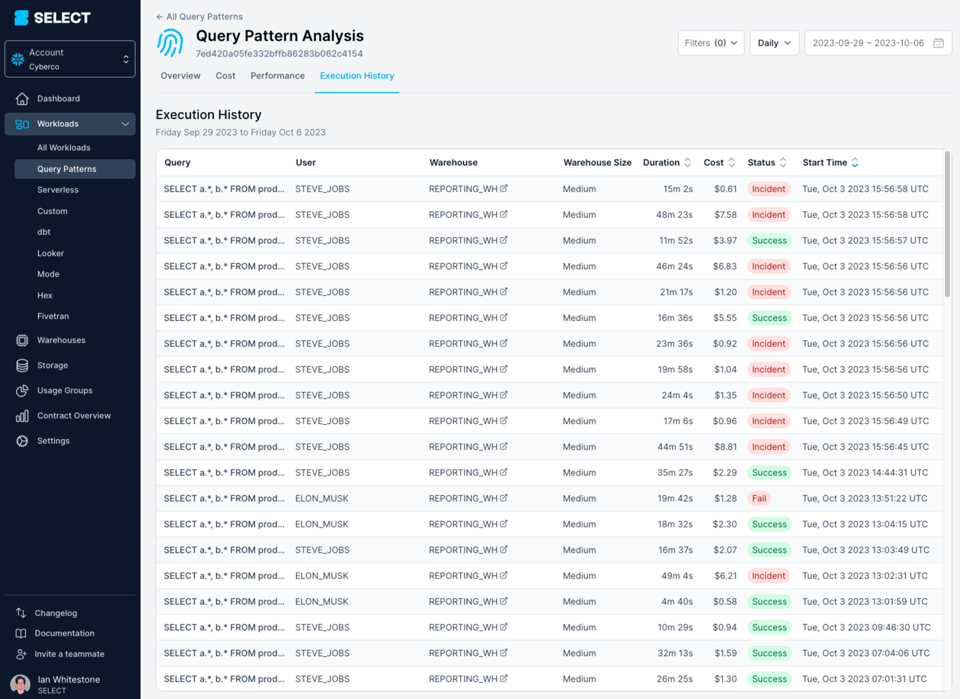
Ao mergulhar no query profile (também chamado de "query plan"), dá para ver que os modelos consultados eram, na verdade, views complexas, com centenas de tabelas.
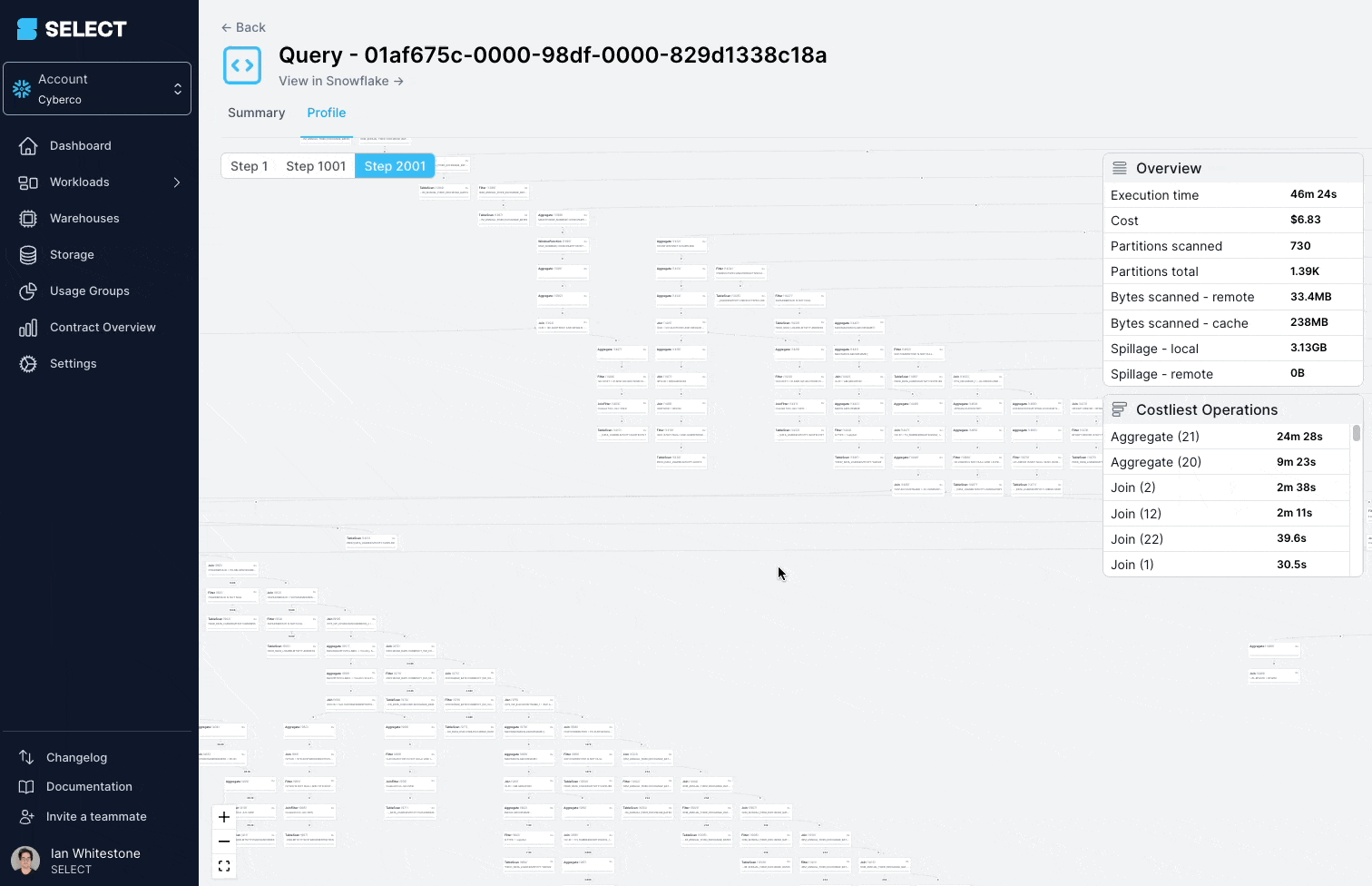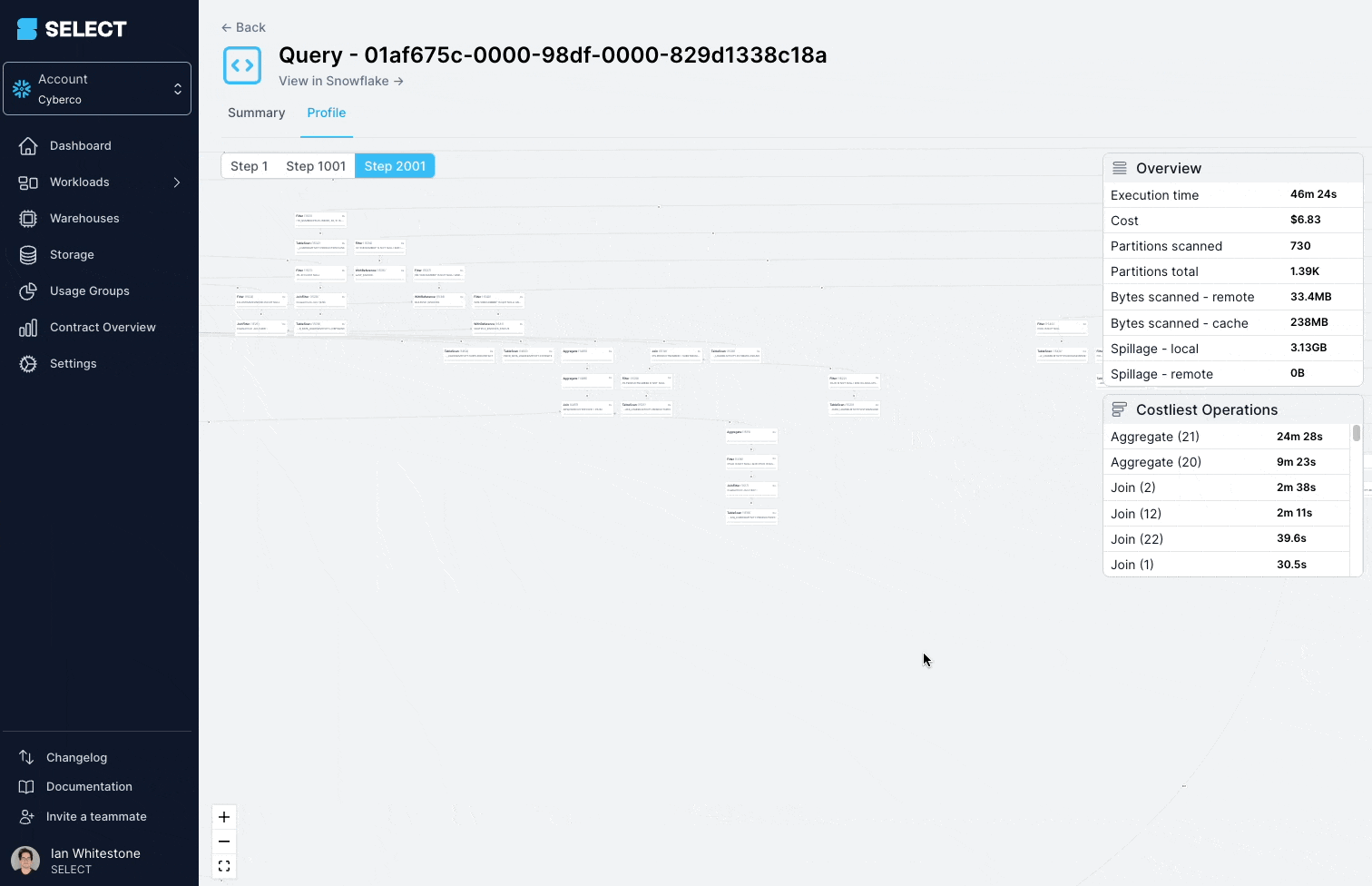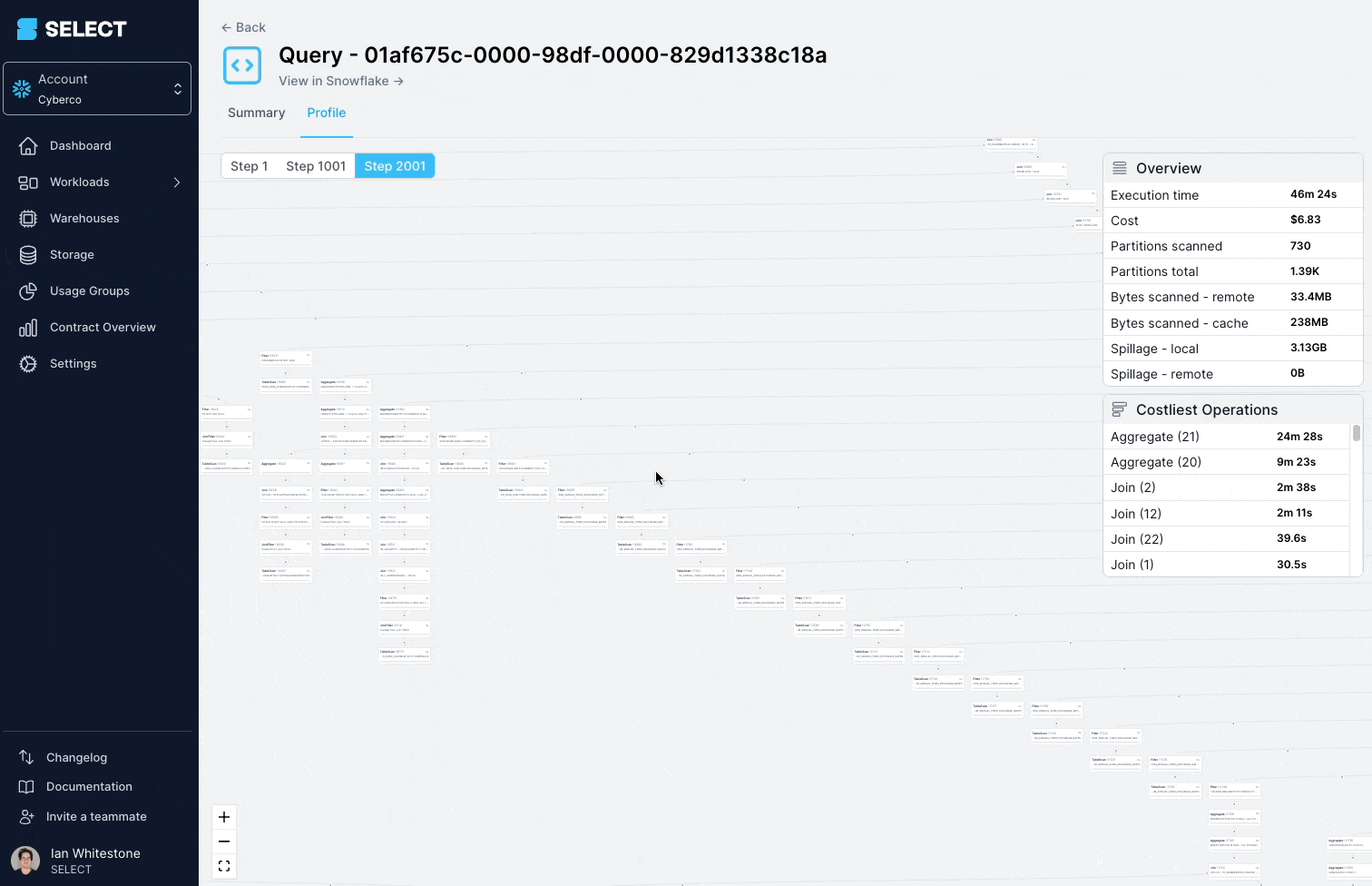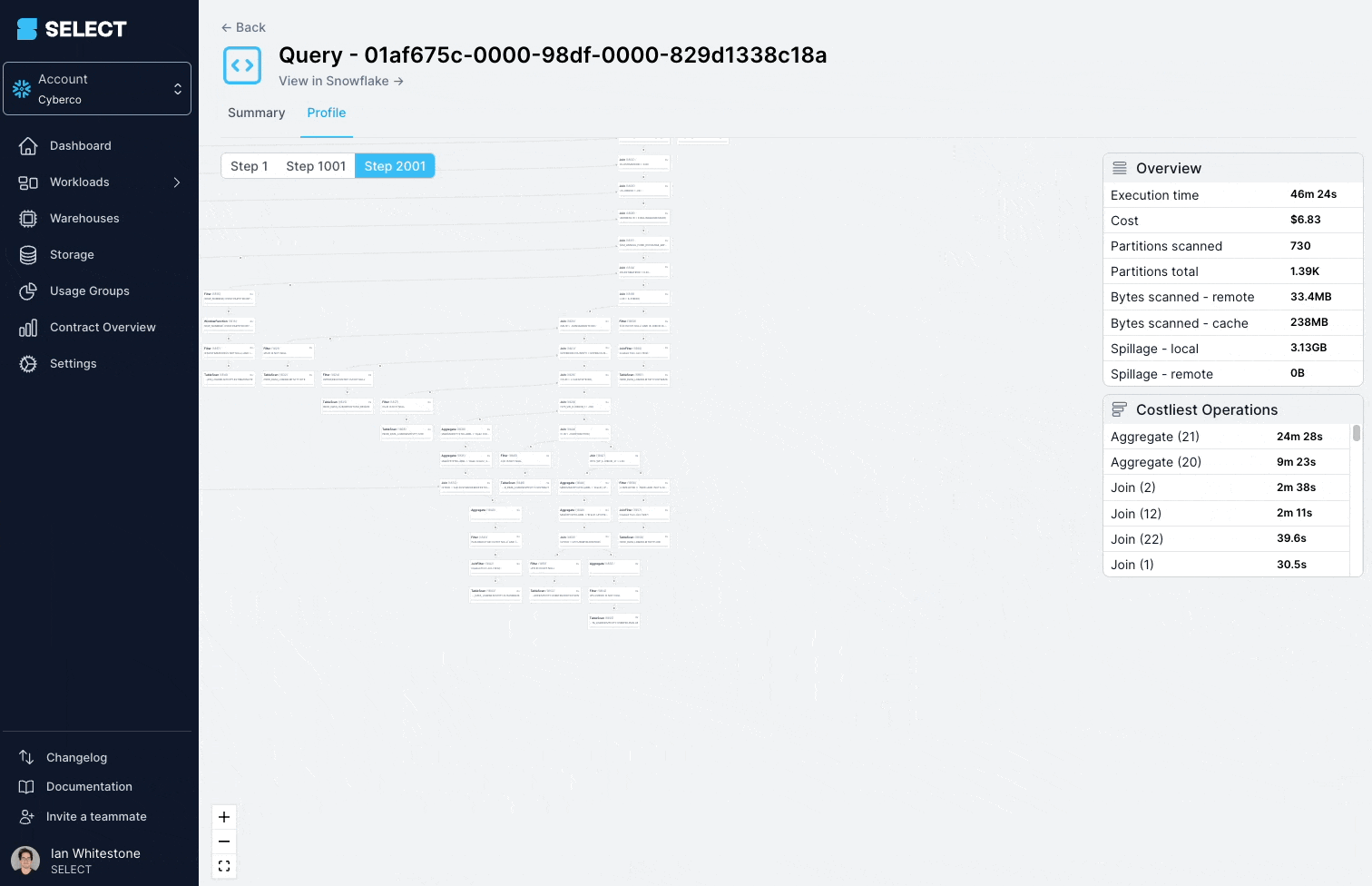
A solução aqui é quebrar a view complexa em partes menores e mais simples e persisti-las como tabelas.
13\. Garanta o uso eficaz dos query caches
Cada nó de um virtual warehouse tem armazenamento em disco local que pode ser usado para cachear micro-partições lidas do armazenamento remoto. Se várias queries acessam o mesmo conjunto de dados em uma tabela, elas podem escanear os dados do cache em disco local em vez do armazenamento remoto, o que acelera a query quando o principal gargalo é a leitura.
Quando o warehouse é suspenso, o Snowflake não garante que o cache vai persistir ao retomar. O impacto da perda de cache é que as queries precisam reescanear os dados do armazenamento da tabela, em vez de ler do cache local, que é muito mais rápido. Se a perda de cache do warehouse estiver afetando suas queries, aumentar o limite de auto-suspend pode ajudar.
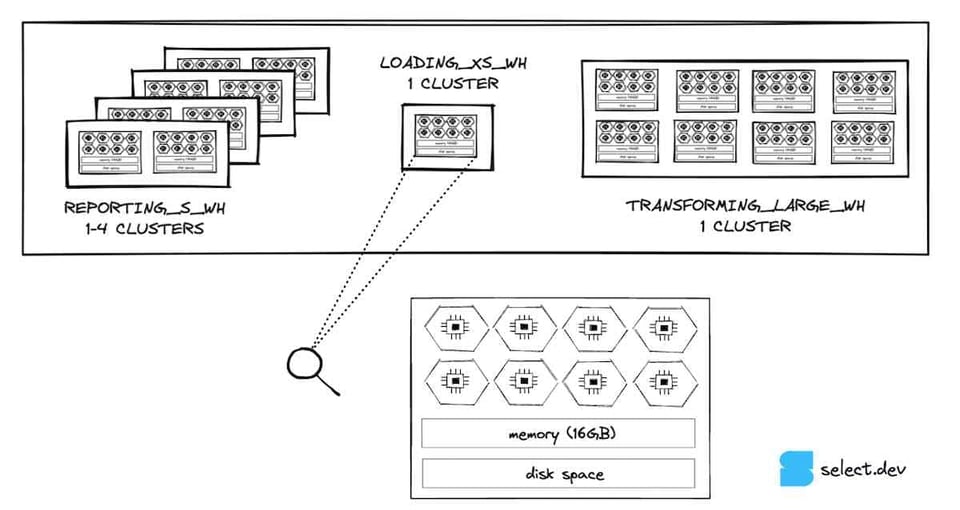
Em paralelo, o Snowflake tem um global result cache que retorna resultados de queries idênticas executadas em até 24 horas, desde que os dados nas tabelas consultadas sejam os mesmos. Algumas situações impedem o uso do global result cache (por exemplo, se a query usa uma função não determinística), então verifique se você está acertando o global result cache quando esperado. Se não, talvez seja preciso ajustar a query ou abrir um chamado de bug no suporte.
14\. Aumente o tamanho do warehouse
O tamanho do warehouse define o poder computacional total disponível para as queries que rodam nele — também conhecido como escalonamento vertical.
Aumente o tamanho do virtual warehouse quando:
- As queries estão fazendo spill para disco remoto (visível no query profile)
- Os resultados precisam chegar mais rápido (geralmente em aplicações voltadas ao usuário final)
Queries que fazem spill para disco remoto rodam de forma ineficiente por causa do grande volume de tráfego de rede entre o warehouse que executa a query e o disco remoto que armazena os dados usados. Aumentar o tamanho do warehouse dobra tanto a RAM disponível quanto o disco local, que são bem mais rápidos que o disco remoto. Quando há spill para disco remoto, aumentar o tamanho do warehouse pode mais que dobrar a velocidade da query. Já entramos em mais detalhes sobre o sizing de warehouses no Snowflake e também cobrimos como configurar tamanhos de warehouse no dbt.
Observação: se a maioria das queries que rodam no warehouse não precisa de um warehouse maior, e você quer evitar aumentar o tamanho para todas, considere usar o Query Acceleration Service do Snowflake. Esse serviço, disponível na Enterprise edition e superiores, dá recursos de computação adicionais a queries que escaneiam grandes volumes de dados.
15\. Aumente o Max Cluster Count
Multi-cluster warehouses, disponíveis na Enterprise edition e superiores, permitem criar mais instâncias de warehouse do mesmo tamanho.
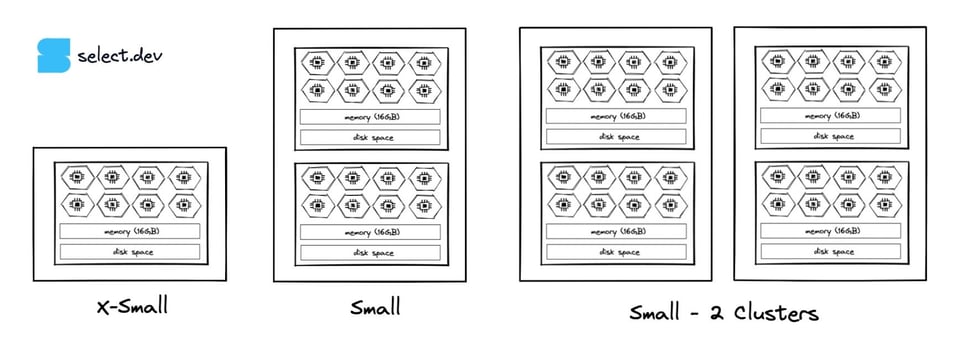
Se houver períodos em que o queuing do warehouse impede as queries de atingirem a velocidade necessária, considere usar multi-clustering ou aumentar o número máximo de clusters do warehouse. Assim, o warehouse acompanha o volume de queries adicionando ou removendo clusters.
Diferentemente do cluster count do warehouse, o Snowflake não consegue ajustar automaticamente o tamanho dos virtual warehouses conforme o volume de queries. Por isso, multi-cluster warehouses são mais custo-eficientes para volumes voláteis de queries, já que cada cluster só é cobrado enquanto está ativo.
16\. Ajuste a Cluster Scaling Policy
O Snowflake oferece duas scaling policies — Standard e Economy. Para todos os virtual warehouses que atendem queries voltadas ao usuário final, use a Standard. Se você tem foco grande em custos, experimente a Economy em workloads tolerantes a queuing, como data loading, para ver se reduz custos mantendo o throughput necessário. Fora isso, recomendamos a Standard para todos os warehouses.
Outros recursos
Se você quer mais conteúdo sobre otimização de queries no Snowflake, recomendamos os recursos em vídeo abaixo.
Behind the Cape: série em 3 partes sobre otimização de custos no Snowflake (2023)
Nesta série de vídeos em 3 partes, Ian participou de Behind the Cape com o data superhero do Snowflake Keith Belanger — uma série em que especialistas do Snowflake mergulham em diversos temas.
Parte 1
Neste episódio, encaramos o tema robusto da otimização de custos no Snowflake. Como tínhamos só 30 minutos, acabou virando uma conversa em alto nível sobre como começar, o modelo de cobrança do Snowflake e as ferramentas que ele oferece para controlar custos.
Veja a lista completa dos tópicos discutidos:
- Como começar a otimização de custos no Snowflake? (Resumo: construa um entendimento holístico dos seus drivers de custo antes de partir para qualquer esforço de otimização)
- Em que ponto está hoje a maioria dos clientes no entendimento do uso do Snowflake
- Como funciona o modelo de cobrança do Snowflake (sabia que, na verdade, é mais barato armazenar dados no Snowflake?)
- As ferramentas que o Snowflake oferece para visibilidade de custos
- Métodos para controlar custos (resource monitors, query timeouts e ACCESS CONTROL — o que ninguém lembra!)
- Por onde começar a cortar custos? Otimizar queries? Ou ir num nível mais alto?
- Recursos para aprender mais.
Para quem quer um panorama de otimização, monitoramento e controle de custos, este é um ótimo ponto de partida. A gravação está abaixo. Tem muita coisa para discutir e não deu para aprofundar tudo, então em breve faremos um follow-up!
Play
Parte 2
Neste episódio, aprofundamos alguns conceitos fundamentais sobre otimização de queries no Snowflake:
- O ciclo de vida de uma query no Snowflake
- Sizing de virtual warehouses no Snowflake
- Como usar o query profile do Snowflake e identificar gargalos
Play
Parte 3
No episódio final da série, mergulhamos nas técnicas mais importantes de otimização de queries:
- Entendendo as micro-partições do Snowflake
- Como aproveitar o query pruning
- Como garantir que suas tabelas estejam efetivamente clusterizadas
Play
Vídeo Snowflake Optimization Power Hour (2022)
Em 28/09/2022, Ian fez uma apresentação para o Snowflake Toronto User Group sobre performance tuning e otimização de custos no Snowflake. Os seguintes assuntos foram abordados:
- Arquitetura do Snowflake
- O ciclo de vida de uma query no Snowflake
- O modelo de cobrança do Snowflake
- Um framework simples para otimização de custos, com uma metodologia detalhada para calcular o custo por query
- Boas práticas de configuração de warehouse
- Dicas de clustering de tabelas
Slides
Os slides podem ser vistos aqui. Para navegar, clique nas setas no canto inferior direito ou use as setas do teclado. Pressione "esc" ou "o" para entrar no modo "overview", onde dá para ver todos os slides. A partir daí, navegue de novo com as setas e clique em um slide ou pressione "esc"/"o" para focar nele.
Gravação da apresentação
A gravação da apresentação está disponível no YouTube. A apresentação começa em 3:29.
Play
Se quiser, terei o maior prazer em ir até aí apresentar isso (ou uma variação) para o seu time, com espaço para tirar dúvidas. Mande um e-mail para [email protected] para combinarmos.
Query Optimization at Snowflake (2020)
Se você quer entender melhor as entranhas do otimizador de queries do Snowflake, recomendo muito esta palestra de Jiaqi Yan, um dos engenheiros de banco de dados mais sêniores do Snowflake:
Play
Ian Whitestone·Co-founder & CEO of SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.
Niall Woodward·Co-founder & CTO of SELECT
Niall é Co-Founder & CTO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Niall foi data engineer na Brooklyn Data Company e em várias startups. Entusiasta do open-source, também é mantenedor do SQLFluff e criador de três pacotes dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.