Dies ist der dritte Teil unserer Serie zum Thema Daten laden in Snowflake. Kurzer Rückblick: Im ersten Beitrag haben wir die fünf verschiedenen Optionen zum Laden von Daten vorgestellt. Der zweite Beitrag widmete sich dem Batch-Loading, der gängigsten Methode der Datenaufnahme.
Dieser Beitrag knüpft daran an und nimmt die nächste Methode genau unter die Lupe: das kontinuierliche Laden mit Snowpipe.
Was ist Snowpipe?
Snowpipe ist ein vollständig gemanagter Service für die Datenaufnahme von Snowflake.
Wer mit dem Batch-Loading über den COPY-Befehl vertraut ist, kann sich Snowpipe als "automatisierten COPY-Befehl" vorstellen. Snowpipes sind First-Class-Objekte in Snowflake – Sie erstellen und verwalten sie per SQL wie jedes andere Snowflake-Objekt.
Snowpipe lädt Dateien automatisch aus einem External Stage, sobald Benachrichtigungen über neu eingegangene Dateien vorliegen. Diese Benachrichtigung stößt die Verarbeitung auf Snowflake-Seite an, wobei Snowflake den im Snowpipe definierten COPY-Befehl ausführt. Die Benachrichtigungen basieren auf dem Notification-Service des jeweiligen Cloud-Anbieters, etwa AWS SQS/SNS.
Was ist der Unterschied zwischen Snowpipe und COPY?
Der wesentliche Unterschied liegt im Compute-Modell und in der Automatisierung. Snowpipe ist ein Serverless-Feature – Sie müssen sich also nicht um das Virtual Warehouse für die Ausführung des Snowpipe-Codes kümmern (Größe, Starten, Pausieren etc.). Snowflake stellt automatisch ein Compute-Cluster für Snowpipe bereit. Bei der Automatisierung erfordert der COPY-Befehl ein Scheduling, damit er zum exakten Zeitpunkt läuft. Snowpipe hingegen wird automatisch durch eingehende Benachrichtigungen ausgelöst – mit entsprechend geringerer Latenz.
Wie erstellt man eine Snowpipe?
Bevor Sie eine Snowpipe anlegen, sollten Sie die gesamte Architektur des Datenladens verstehen. Das Snowpipe-Objekt funktioniert nicht für sich allein. Zusätzlich benötigen Sie Definitionen für Storage Integration, Stage und File Format. Wie Sie diese Objekte erstellen, haben wir im vorherigen Beitrag zum Batch-Loading behandelt.
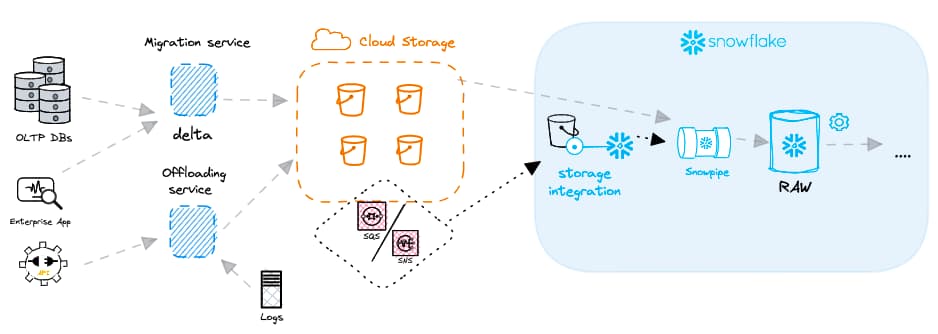
Sind die nötigen Stage-, Storage-Integration- und File-Format-Objekte erstellt, lässt sich ein Snowpipe-Objekt mit folgendem Code anlegen:
CREATE OR REPLACE PIPE mypipe
AUTO_INGEST = TRUE AS
COPY INTO snowpipe_landing_table
FROM @my_s3_stage/snowpipe/
FILE_FORMAT = csv_file_format;
Ein wichtiger Parameter ist hier AUTO_INGEST. Er legt fest, ob Dateien anhand empfangener Benachrichtigungen geladen werden (TRUE) oder ob die Snowpipe REST API mit einer Liste der zu ladenden Dateien aufgerufen wird (FALSE).
Event-Benachrichtigungen für Snowpipe in AWS konfigurieren
Zusätzlich zur Snowpipe-Objektdefinition müssen Sie eine Notification Integration einrichten. Damit Dateien automatisch geladen werden können, muss Snowpipe vom Cloud-Anbieter Benachrichtigungen über neue Dateien erhalten.
Sobald Sie ein Snowpipe-Objekt mit AUTO_INGEST = TRUE erstellen, weist Snowflake ihm automatisch einen Notification Channel zu. Wenn Sie Amazon Web Services (AWS) nutzen, verwendet Snowflake Amazon Simple Queue Service (SQS) für den Empfang der Benachrichtigungen. Die SQS-ID finden Sie in der Spalte notification_channel in der Ausgabe von DESC PIPE mypipe.

Damit Snowpipe Auto Ingest funktioniert, müssen Benachrichtigungen über neue Dateien an diese Queue gesendet werden. Glücklicherweise lässt sich das mit der Event-Notification-Funktion von S3 umsetzen, die Nachrichten an die Queue schickt.
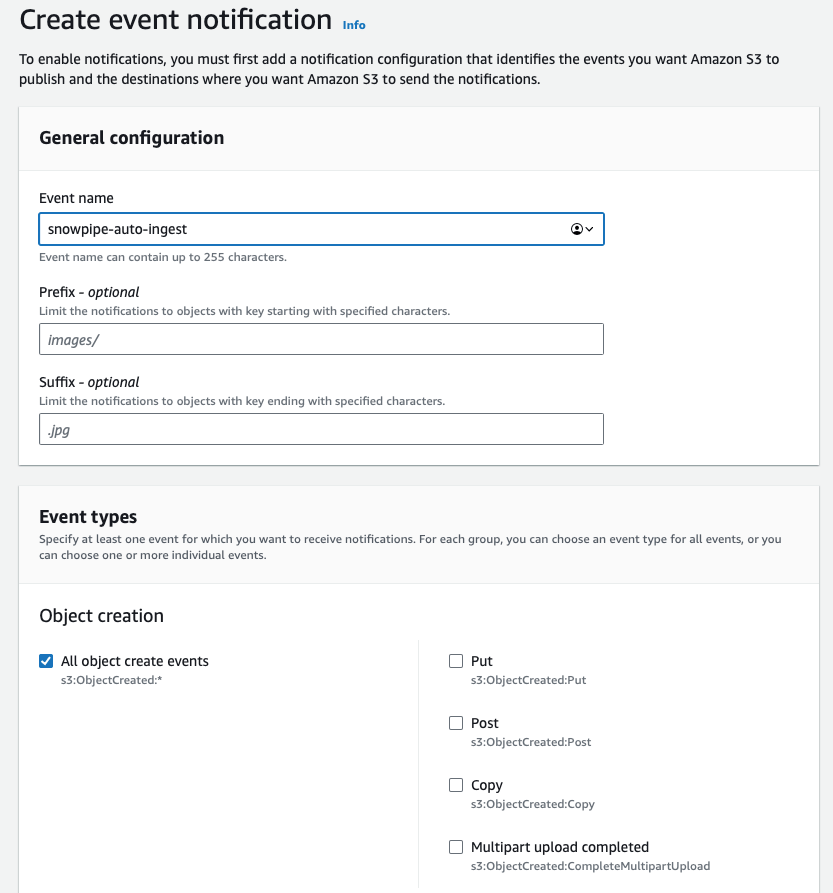
Event-Benachrichtigung anlegen
Öffnen Sie den S3-Bucket mit den Dateien, die Sie per Snowpipe laden möchten. Wechseln Sie zum Tab "Properties" und suchen Sie die Konfiguration für Event-Benachrichtigungen. Legen Sie eine neue mit dem gewünschten Namen an und definieren Sie bei Bedarf ein Prefix, um die Benachrichtigung auf relevante Dateien einzuschränken. Falls Sie mehrere Verzeichnisse haben und Snowpipe nur Dateien aus einem davon laden soll, definieren Sie das entsprechend, um Kosten, Latenz und Event-Rauschen zu reduzieren.
Scrollen Sie ans untere Ende der Seite, wo die Zielkonfiguration (Destination) folgt. Wählen Sie SQS aus und fügen Sie den Wert ein, den Sie aus dem oben gezeigten Befehl DESC PIPE mypipe erhalten haben.
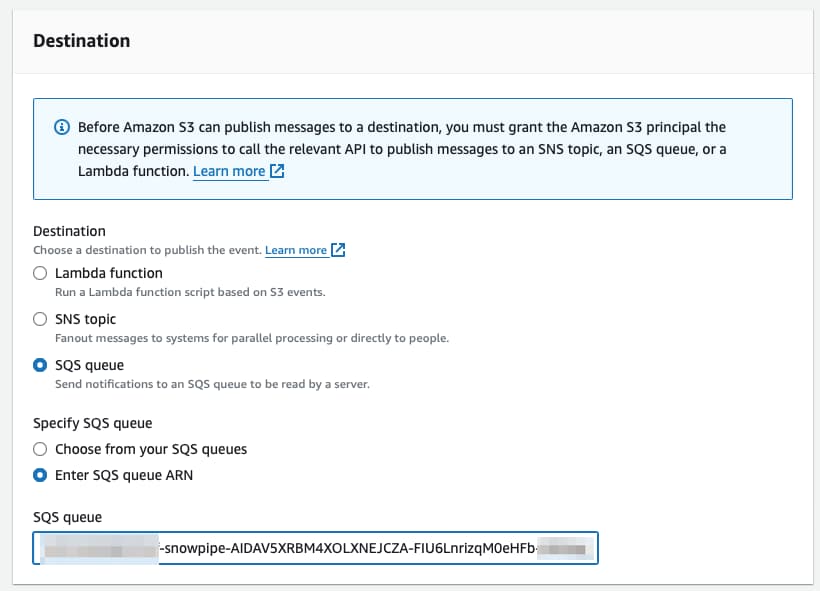
Und das war's! Sobald nun eine neue Datei in S3 ankommt, wird Snowpipe benachrichtigt und führt den COPY-Befehl wie von Zauberhand aus 🪄.
Snowpipes verwalten
Für die Verwaltung von Snowpipes gibt es eine ganze Reihe nützlicher Befehle. Sehen wir sie uns im Detail an.
Snowpipes auflisten & beschreiben
Oben haben wir bereits DESC PIPE mypipe verwendet, das grundlegende Informationen zur jeweiligen Pipe liefert. Dieselbe Ausgabe – jedoch nicht auf eine einzelne Pipe gefiltert – erhalten Sie mit dem Befehl SHOW PIPES.
Snowpipe-Status
Die Systemfunktion PIPE_STATUS gibt einen Überblick über den aktuellen Zustand der Pipe. Die Ausgabe enthält mehrere Werte, etwa den aktuellen Status, Informationen zur zuletzt geladenen Datei sowie den Hinweis, ob ausstehende Dateien vorliegen.
Für diesen Überblick führen Sie SELECT SYSTEM$PIPE_STATUS('mypipe') aus.
Die Funktion liefert eine JSON-Struktur zurück:
{
"executionState": "RUNNING",
"lastForwardedFilePath": "source_bucket/ingestion/snowpipe/orders-3.csv",
"lastForwardedMessageTimestamp": "2024-01-16T15:45:00.262Z",
"lastIngestedFilePath": "orders-3.csv",
"lastIngestedTimestamp": "2024-01-16T15:45:00.101Z",
"lastPulledFromChannelTimestamp": "2024-01-26T11:01:14.901Z",
"lastReceivedMessageTimestamp": "2024-01-16T17:52:29.645Z",
"notificationChannelName": "arn:aws:sqs:eu-central-1:XXXXXXXXXXXX:sf-snowpipe-AIDAV5XuBMEXOLXcEJCZA-FIU6Lnri5qM0eVFb-D9Hwm",
"numOutstandingMessagesOnChannel": 0,
"pendingFileCount": 0
}
Eine Pipe pausieren
Eine Pipe hat einen Ausführungsstatus. Wenn Sie eine Snowpipe erstellen, erhält sie automatisch den Status RUNNING. Anders als bei einem Snowflake Task ist keine zusätzliche Aktivierung nötig. Es kann jedoch Situationen geben, in denen Sie die Pipe vorübergehend pausieren möchten:
- Wechsel des Eigentümers der Pipe
- Eingriffe an den Dateien im Quellverzeichnis
- Test des vorgelagerten Prozesses, der die Dateien erzeugt
- Zum Pausieren der Ausführung bietet Snowflake den Parameter
PIPE_EXECUTION_PAUSED.
Pausieren Sie die Ausführung einer Snowpipe mit dem ALTER-Statement:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = TRUE;
Dieses ALTER-Statement setzt die Pipe in den Status PAUSED. Neue Dateien können weiterhin im Stage-Verzeichnis landen, werden aber erst verarbeitet, sobald die Pipe wieder fortgesetzt wird. Beachten Sie: Eine Pipe kann veralten (stale werden), wenn sie länger als die Aufbewahrungsdauer der empfangenen Event-Nachrichten pausiert ist (standardmäßig 14 Tage). Um eine Pipe fortzusetzen, setzen Sie den Parameter zurück auf FALSE:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = FALSE;
Fehlerbenachrichtigungen in Snowpipe
Snowpipe lässt sich auch mit Cloud-Messaging-Diensten (z. B. AWS SNS) verknüpfen und im Fehlerfall Benachrichtigungen versenden. Das Operations-Team kann auf solche Meldungen reagieren und das Problem beheben, bevor es Fachanwendern auffällt. Für die Fehler-Integration sind mehrere Konfigurationsschritte sowohl auf Snowflake- als auch auf Cloud-Anbieter-Seite nötig:
- AWS SNS Topic anlegen
- AWS IAM Policy anlegen
- AWS IAM Role anlegen
- Notification Integration anlegen (Snowflake-Seite)
- Snowflake Zugriff auf das SNS Topic gewähren
- Fehlerbenachrichtigung in Snowpipe aktivieren
Zum Aktivieren der Fehlerbenachrichtigung in Snowpipe nutzen Sie den Befehl ALTER PIPE:
1ALTER PIPE mypipe SET ERROR_INTEGRATION = my_notification_int;
Eine ausführliche Anleitung zur Einrichtung finden Sie in unseren früheren Beiträgen zum Anlegen von Fehlerbenachrichtigungen für Snowflake Tasks oder im allgemeineren Überblick zu Snowflake Alerting.
Kosten von Snowflake Snowpipe
Da Snowflake-Kostenmanagement für alle Snowflake-Kunden hohe Priorität hat, lohnt es sich zu verstehen, wie Snowpipe abgerechnet wird.
Snowpipe ist ein Serverless-Feature – Sie müssen sich also weder um die Bereitstellung noch um die Dimensionierung des Compute-Clusters für das Laden mit Snowpipe kümmern. In Snowflake gilt für jedes Serverless-Feature ein anderes Preismodell als für Virtual Warehouses.
Die Compute-Kosten für Snowpipe betragen das 1,25-Fache der regulären Virtual-Warehouse-Compute-Kosten (Referenz: Snowflake Credit Consumption Table). Beispiel: Wenn Snowflake zum Laden Ihrer Daten das Äquivalent eines X-Small Warehouse einsetzt, werden Ihnen pro Compute-Stunde 1,25 Credits statt 1 Credit berechnet.
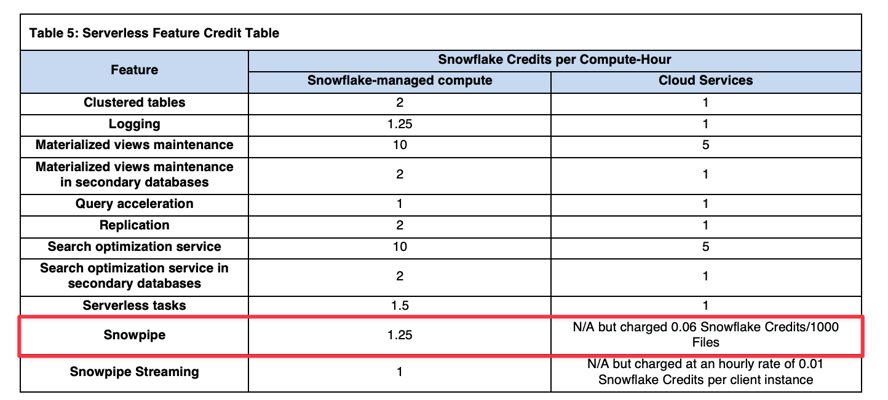
Zusätzlich zu den von Snowflake gemanagten Compute-Kosten fällt eine Datei-Overhead-Gebühr an: 0,06 Credits pro 1.000 geladene Dateien. Daher ist es entscheidend, dass Ihre Dateien optimal dimensioniert sind, wenn Sie Snowpipe nutzen.
Mit einem Tool wie SELECT erkennen Sie auf einen Blick, wann sich aufgrund Ihrer Dateigrößen erhebliche Optimierungspotenziale bei den Snowpipe-Kosten ergeben:
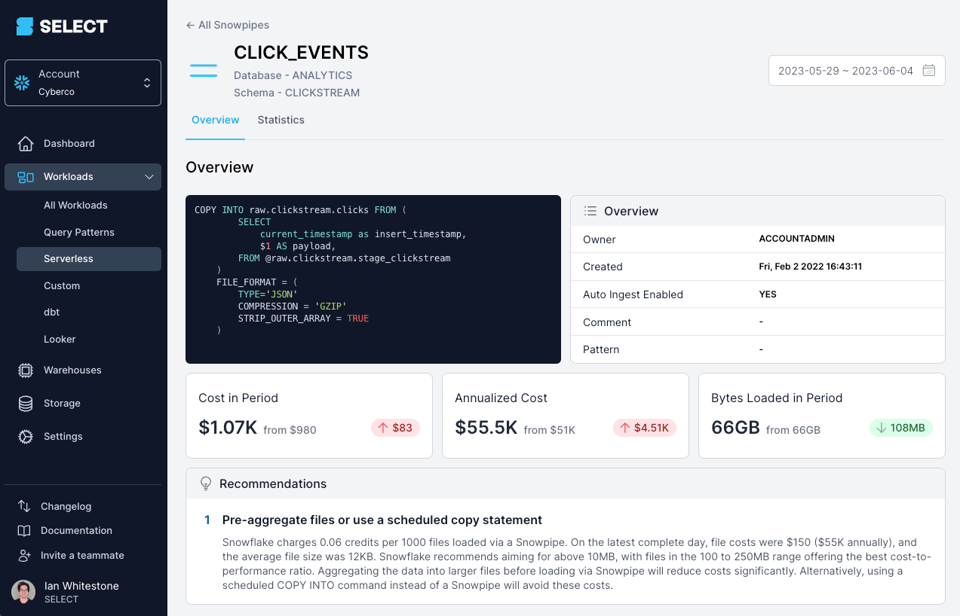
Alternativ können Sie das selbst über die unten beschriebenen Metadaten-Views ermitteln.
Wie überwacht man Snowpipe-Kosten?
Snowflake hält detaillierte Metadaten zu Ihrer Snowpipe-Nutzung vor. Damit verschaffen Sie sich einen guten Überblick über Ihre Kosten. Werfen wir einen Blick auf einige ACCOUNT_USAGE-Views mit Snowpipe-Daten. Wenn Sie Details zu all Ihren Snowpipes erhalten möchten, nutzen Sie den PIPES-View mit folgender Query:
SELECT
PIPE_ID,
PIPE_NAME AS NAME,
PIPE_SCHEMA_ID AS SCHEMA_ID,
PIPE_SCHEMA AS SCHEMA_NAME,
PIPE_CATALOG_ID AS DATABASE_ID,
PIPE_CATALOG AS DATABASE_NAME,
IS_AUTOINGEST_ENABLED,
NOTIFICATION_CHANNEL_NAME,
PIPE_OWNER,
DEFINITION,
CREATED,
LAST_ALTERED,
COMMENT,
PATTERN,
Code aufklappen
Sie erhalten so eine vollständige Liste, inklusive gelöschter Pipes. Mit der Bedingung WHERE DELETED IS NULL beschränken Sie die Ausgabe auf aktuell vorhandene Pipes.
Den Snowpipe History View nutzen
Zur Berechnung der Snowpipe-Kosten verwenden Sie PIPE_USAGE_HISTORY. Für die Credits, die als zusätzliche Datei-Overhead-Gebühr anfallen, sind eigene Berechnungen nötig.
SELECT
START_TIME,
PIPE_ID,
COALESCE(PIPE_NAME, 'External table refreshes') AS NAME, -- External table refreshes do not have a pipe name
FILES_INSERTED,
BYTES_INSERTED,
CREDITS_USED AS TOTAL_CREDITS,
0.06 * FILES_INSERTED / 1000 AS FILES_CREDITS, -- 0.06 credits per 1000 files
TOTAL_CREDITS - FILES_CREDITS AS COMPUTE_CREDITS
FROM SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY
ORDER BY START_TIME DESC;
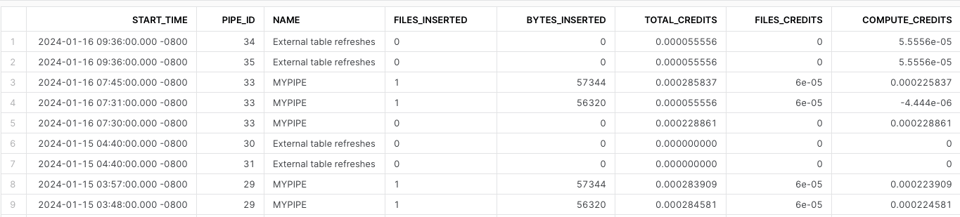
Snowpipe Best Practices
Sehen wir uns einige Best Practices für den Einsatz von Snowpipes an. Wie bereits erwähnt, ist die richtige Dimensionierung Ihrer Dateien der wichtigste Faktor. Snowpipe kann sehr ineffizient und teuer werden, wenn viele kleine Dateien geladen werden. Das lässt sich an einem einfachen Beispiel zeigen, bei dem täglich 100 GB Daten geladen werden:
| Datenmenge | Einzelne Dateigröße | Anzahl Dateien | Credits/Tag (Datei-Overhead-Gebühr) | Kosten/Jahr (Datei-Overhead-Gebühr) |
|---|---|---|---|---|
| 100 GB | 25 KB | 4,2 Millionen | 251 | 275.000 $ |
| 100 GB | 250 MB | 410 | 0,06 | 66 $ |
Wie Sie sehen, kann das Laden riesiger Mengen sehr kleiner Dateien zu hohen Kosten führen – allein durch die Datei-Overhead-Gebühr. Werden die Dateien gemäß Empfehlung dimensioniert (100–250 MB), fallen die jährlichen Kosten kaum ins Gewicht.
Eine ähnliche Empfehlung gilt für komprimierte Dateiformate (z. B. gzip) gegenüber unkomprimierten (z. B. CSV). Snowflake arbeitet mit komprimierten Formaten effizienter, und Sie profitieren zusätzlich von deutlich geringerem Datenvolumen im Netzwerk sowie niedrigerem Speicherbedarf.
Außerdem empfehle ich, Filter für Datei-Benachrichtigungen einzusetzen, sodass nur Meldungen zu relevanten Dateien gesendet werden – und nicht zu allem, was sich in Ihrem Bucket abspielt.
Vor- und Nachteile von Snowpipe
Zum Abschluss noch die wichtigsten Vorteile von Snowpipe gegenüber dem COPY-Befehl.
Snowpipe ist einfach in der Handhabung und reduziert den Verwaltungsaufwand. Es bringt Automatisierung und nahezu Echtzeit-Datenaufnahme mit. Dank des Serverless-Modells entfällt das Right-Sizing des Compute-Clusters. Es reagiert flexibler auf schwankende Workload-Größen. Für die meisten Use Cases ist Snowpipe die bessere Wahl als der COPY-Befehl. Wo es – insbesondere aus Kostensicht – nicht gut funktioniert, ist bei falsch dimensionierten Dateien.
In unserem früheren Beitrag finden Sie einen ausführlicheren Vergleich der verschiedenen Optionen zum Laden von Daten in Snowflake.
Tomáš Sobotík · Senior Data Engineer & Snowflake SME bei Norlys
Tomas ist langjähriger Snowflake Data SuperHero und ausgewiesener Snowflake-Experte. Seine Erfahrung in der Datenwelt reicht über mehr als ein Jahrzehnt, in dem er als Snowflake Data Engineer, Architect und Admin in zahlreichen Projekten in unterschiedlichsten Branchen und Technologien gearbeitet hat. Tomas ist ein zentrales Community-Mitglied, teilt aktiv sein Wissen und inspiriert andere. Außerdem ist er O'Reilly-Instructor und leitet Live-Online-Trainings.