Questa è la terza parte della nostra serie dedicata al caricamento dei dati in Snowflake. Per fare un breve riepilogo, nel primo articolo abbiamo analizzato le cinque opzioni disponibili per il caricamento dei dati. Il secondo è stato dedicato al batch data loading, la tecnica di ingestion più diffusa.
In questo articolo proseguiamo il percorso con un approfondimento sul metodo di ingestion successivo: il caricamento continuo con Snowpipe.
Che cos'è Snowpipe?
Snowpipe è un servizio di data ingestion completamente gestito offerto da Snowflake.
Se conosci già il batch data loading tramite il comando COPY, puoi immaginare Snowpipe come una sorta di "comando copy automatizzato". Le Snowpipe sono oggetti Snowflake di prima classe: si creano e si gestiscono tramite SQL, esattamente come ogni altro oggetto Snowflake.
Snowpipe carica automaticamente i file da uno stage esterno sulla base delle notifiche relative ai nuovi file in arrivo. La notifica innesca l'elaborazione lato Snowflake, che esegue il comando COPY definito nella Snowpipe. Le notifiche si appoggiano al servizio di notifica del cloud provider, ad esempio AWS SQS/SNS.
Qual è la differenza tra Snowpipe e COPY?
La differenza principale sta nel modello di compute e nel livello di automazione. Snowpipe è una funzionalità serverless: non devi occuparti del virtual warehouse per eseguire il codice di Snowpipe (sizing, avvio, sospensione e così via). È Snowflake stesso a fornire automaticamente il cluster di compute per Snowpipe. Sul fronte dell'automazione, il comando COPY richiede una pianificazione che garantisca l'esecuzione a un orario preciso. Snowpipe, al contrario, si attiva automaticamente in base alle notifiche ricevute, con una latenza decisamente inferiore.
Come creare una Snowpipe?
Prima di creare una Snowpipe è fondamentale comprendere l'architettura complessiva del caricamento dei dati. L'oggetto Snowpipe non funziona in modo isolato: oltre ad esso, dovrai definire anche una storage integration, uno stage e un file format. Abbiamo trattato la creazione di questi oggetti nell'articolo precedente dedicato al batch data loading.
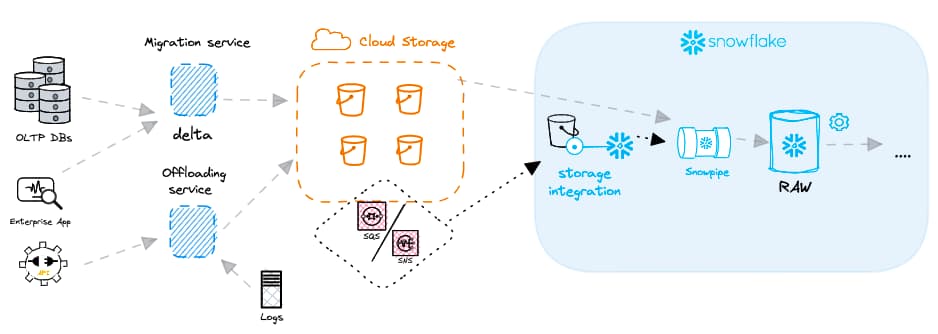
Una volta creati gli oggetti stage, storage integration e file format, puoi creare un oggetto Snowpipe con il seguente codice:
CREATE OR REPLACE PIPE mypipe
AUTO_INGEST = TRUE AS
COPY INTO snowpipe_landing_table
FROM @my_s3_stage/snowpipe/
FILE_FORMAT = csv_file_format;
Uno dei parametri più importanti da considerare è AUTO_INGEST, che indica se vuoi caricare i file in base alle notifiche ricevute (TRUE) oppure invocare la REST API di Snowpipe passando un elenco di file da ingerire (FALSE).
Configurare le notifiche degli eventi per Snowpipe in AWS
Oltre alla definizione dell'oggetto Snowpipe, è necessario configurare anche una notification integration. Per poter caricare i file in automatico, Snowpipe deve ricevere dal cloud provider le notifiche sui nuovi file.
Quando crei un oggetto Snowpipe con AUTO_INGEST = TRUE, Snowflake gli assegna automaticamente un canale di notifica. Se utilizzi Amazon Web Services (AWS), Snowflake si appoggia ad Amazon Simple Queue Service (SQS) per ricevere le notifiche. Il valore dell'ID SQS è disponibile nella colonna notification_channel dell'output di DESC PIPE mypipe.

Perché l'auto ingest di Snowpipe funzioni, le notifiche sui nuovi file devono essere inviate a questa coda. Per fortuna possiamo realizzare il tutto sfruttando la funzionalità di event notification di S3, che invia i messaggi direttamente alla coda.
Creare la notifica degli eventi
Apri il bucket S3 che contiene i file da caricare con Snowpipe. Vai alla scheda properties e individua la configurazione delle event notification. Creane una nuova con il nome che preferisci e, se necessario, configura un prefix per limitare la notifica ai soli file rilevanti. Se hai più directory e Snowpipe deve caricare i file da una soltanto, conviene specificarlo per ridurre costi, latenza e rumore sugli eventi.
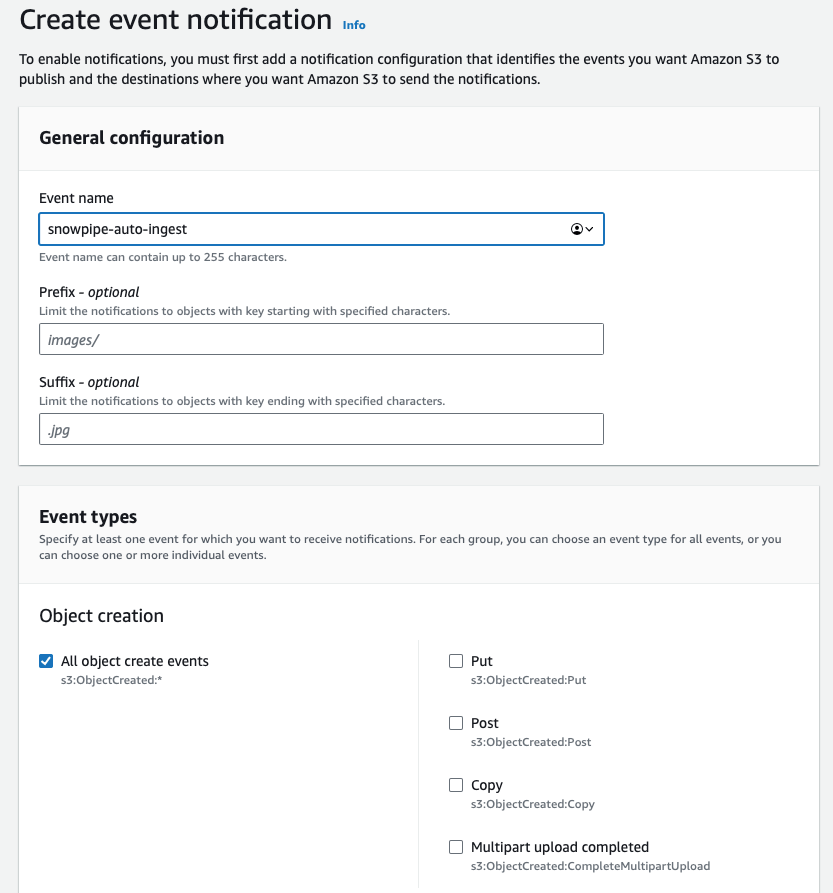
Scorri fino in fondo alla schermata, dove trovi la configurazione della destinazione. Seleziona SQS e incolla il valore ottenuto in precedenza dal comando DESC PIPE mypipe.
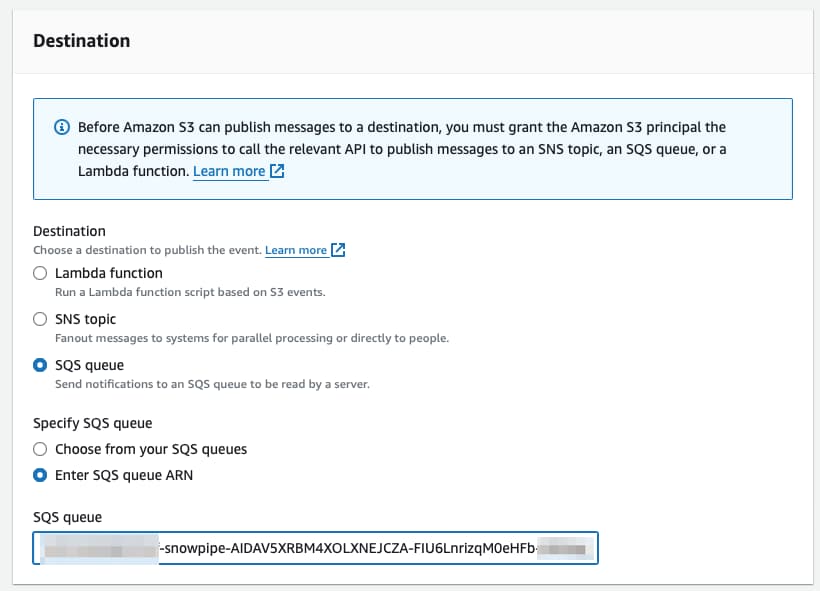
E il gioco è fatto! Da questo momento, ogni volta che un nuovo file arriverà in S3, Snowpipe riceverà la notifica e potrà eseguire automagicamente il comando COPY 🪄.
Gestire le Snowpipe
Esistono diversi comandi utili per gestire le Snowpipe. Vediamoli nel dettaglio.
Elencare e descrivere le Snowpipe
Abbiamo già usato DESC PIPE mypipe, che restituisce le informazioni di base sulla pipe indicata. Lo stesso output, ma non filtrato su una singola pipe, si ottiene con il comando SHOW PIPES.
Stato della Snowpipe
La system function PIPE_STATUS offre una panoramica dello stato attuale della pipe. L'output include vari valori, come lo stato corrente, le informazioni sull'ultimo file ingerito e l'eventuale presenza di file in attesa.
Per ottenere questa panoramica, esegui SELECT SYSTEM$PIPE_STATUS('mypipe');
L'output della funzione è una struttura JSON:
{
"executionState": "RUNNING",
"lastForwardedFilePath": "source_bucket/ingestion/snowpipe/orders-3.csv",
"lastForwardedMessageTimestamp": "2024-01-16T15:45:00.262Z",
"lastIngestedFilePath": "orders-3.csv",
"lastIngestedTimestamp": "2024-01-16T15:45:00.101Z",
"lastPulledFromChannelTimestamp": "2024-01-26T11:01:14.901Z",
"lastReceivedMessageTimestamp": "2024-01-16T17:52:29.645Z",
"notificationChannelName": "arn:aws:sqs:eu-central-1:XXXXXXXXXXXX:sf-snowpipe-AIDAV5XuBMEXOLXcEJCZA-FIU6Lnri5qM0eVFb-D9Hwm",
"numOutstandingMessagesOnChannel": 0,
"pendingFileCount": 0
}
Mettere in pausa una pipe
Ogni pipe ha uno stato di esecuzione. Quando crei una Snowpipe, le viene automaticamente assegnato lo stato RUNNING: non occorre attivarla come si fa con una Snowflake task. Possono però esserci situazioni in cui ti serve metterla in pausa per qualche tempo:
- Cambio dell'ownership della pipe
- Operazioni sui file nella directory di origine
- Test del processo upstream che genera i file
- Per sospendere l'esecuzione della pipe, Snowflake mette a disposizione il parametro
PIPE_EXECUTION_PAUSED.
Per mettere in pausa l'esecuzione di una Snowpipe utilizza lo statement ALTER:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = TRUE;
Questo statement ALTER porta la pipe nello stato PAUSED. I nuovi file possono continuare ad arrivare nella directory dello stage, ma non verranno elaborati finché la pipe non sarà riattivata. Attenzione: una pipe può diventare stale se rimane in pausa più a lungo del periodo di retention dei messaggi degli eventi ricevuti (14 giorni per impostazione predefinita). Per riattivarla, riporta il parametro a FALSE:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = FALSE;
Notifiche di errore di Snowpipe
Snowpipe può essere integrato anche con i servizi di messaggistica cloud (ad esempio AWS SNS) per inviare notifiche in caso di errore. Il team operativo può così intervenire tempestivamente e risolvere il problema prima che venga rilevato dagli utenti di business. Per abilitare l'integrazione degli errori sono necessari diversi passaggi di configurazione, sia lato Snowflake sia lato cloud provider:
- Creare un AWS SNS Topic
- Creare una AWS IAM Policy
- Creare un AWS IAM Role
- Creare la Notification Integration (lato Snowflake)
- Concedere a Snowflake l'accesso al topic SNS
- Abilitare la notifica degli errori nella Snowpipe
Per abilitare la notifica degli errori in Snowpipe puoi usare il comando ALTER PIPE:
1ALTER PIPE mypipe SET ERROR_INTEGRATION = my_notification_int;
Per un approfondimento sulla configurazione, consulta i nostri articoli precedenti su come creare notifiche di errore per le Snowflake Tasks oppure la panoramica più generale sull'alerting in Snowflake.
I costi di Snowflake Snowpipe
Poiché il cost management di Snowflake è una priorità per tutti i clienti Snowflake, è fondamentale capire come viene fatturata Snowpipe.
Snowpipe è una funzionalità serverless: non devi occuparti di predisporre e dimensionare il cluster di compute per il caricamento. In Snowflake, ogni funzionalità serverless adotta un modello di pricing diverso da quello dei virtual warehouse.
I costi di compute di Snowpipe sono pari a 1,25 volte i normali costi di compute di un virtual warehouse (riferimento: Snowflake Credit Consumption Table). Ad esempio, se Snowflake utilizza l'equivalente di un warehouse X-Small per caricare i tuoi dati, l'addebito sarà di 1,25 crediti anziché 1 credito per ora di compute.
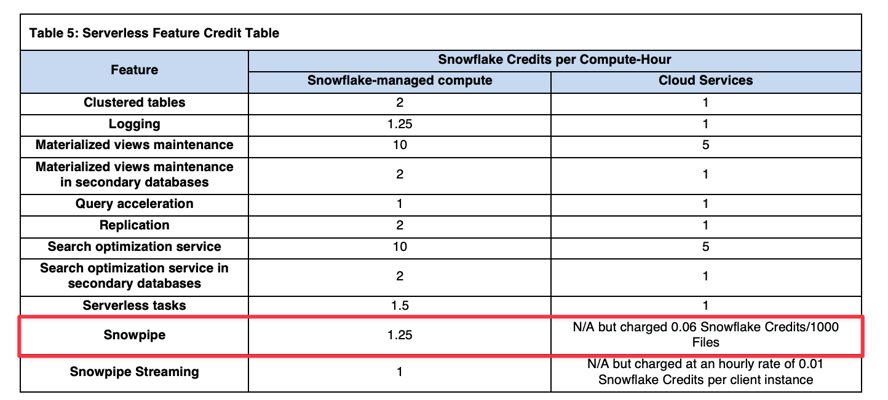
Oltre ai costi di compute gestiti da Snowflake, è prevista una commissione aggiuntiva di overhead sui file: 0,06 crediti ogni 1000 file caricati. Per questo motivo, quando si usa Snowpipe è fondamentale assicurarsi che i file abbiano una dimensione ottimale.
Se utilizzi uno strumento come SELECT, individuerai con facilità le opportunità più significative di ottimizzazione dei costi di Snowpipe legate alla dimensione dei file:
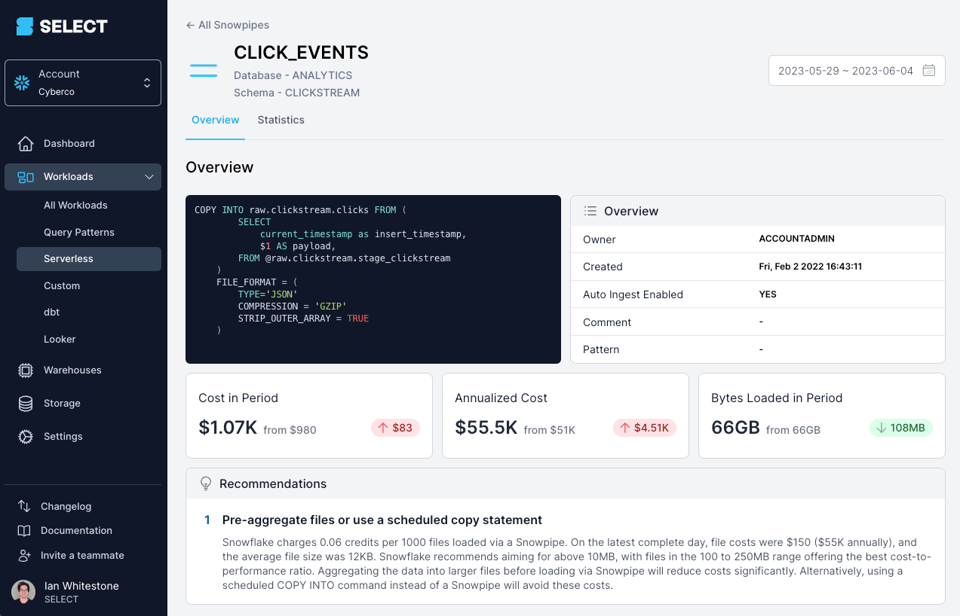
In alternativa, puoi individuarle in autonomia utilizzando le viste di metadati descritte di seguito.
Come monitorare i costi di Snowpipe?
Snowflake conserva metadati dettagliati sull'utilizzo di Snowpipe. Puoi sfruttare questi dati per avere una panoramica dei costi. Vediamo alcune viste di ACCOUNT_USAGE che forniscono dati su Snowpipe. Per ottenere i dettagli di tutte le tue Snowpipe puoi usare la vista PIPES con la seguente query:
SELECT
PIPE_ID,
PIPE_NAME AS NAME,
PIPE_SCHEMA_ID AS SCHEMA_ID,
PIPE_SCHEMA AS SCHEMA_NAME,
PIPE_CATALOG_ID AS DATABASE_ID,
PIPE_CATALOG AS DATABASE_NAME,
IS_AUTOINGEST_ENABLED,
NOTIFICATION_CHANNEL_NAME,
PIPE_OWNER,
DEFINITION,
CREATED,
LAST_ALTERED,
COMMENT,
PATTERN,
Espandi il codice
Si ottiene un elenco completo, comprese le pipe eliminate. Per ricevere solo le pipe attualmente esistenti, puoi aggiungere la condizione WHERE DELETED IS NULL.
Utilizzare la vista Snowpipe History
Per calcolare il costo di Snowpipe puoi utilizzare PIPE_USAGE_HISTORY. Servono calcoli personalizzati per includere i crediti addebitati come overhead aggiuntivo sui file.
SELECT
START_TIME,
PIPE_ID,
COALESCE(PIPE_NAME, 'External table refreshes') AS NAME, -- External table refreshes do not have a pipe name
FILES_INSERTED,
BYTES_INSERTED,
CREDITS_USED AS TOTAL_CREDITS,
0.06 * FILES_INSERTED / 1000 AS FILES_CREDITS, -- 0.06 credits per 1000 files
TOTAL_CREDITS - FILES_CREDITS AS COMPUTE_CREDITS
FROM SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY
ORDER BY START_TIME DESC;
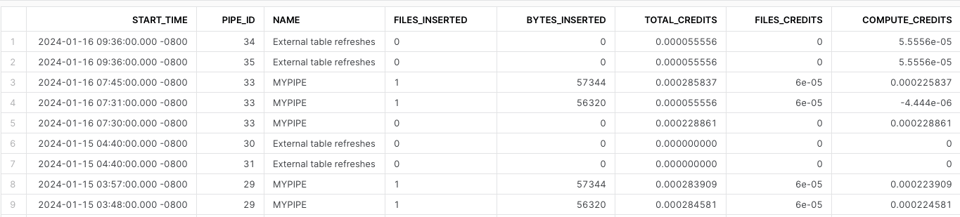
Best practice per Snowpipe
Vediamo alcune best practice per l'utilizzo delle Snowpipe. Come abbiamo già anticipato, il fattore più importante è assicurarsi che i file abbiano la dimensione corretta. Snowpipe può rivelarsi molto inefficiente e costoso quando ingerisce un gran numero di file di piccole dimensioni. Possiamo dimostrarlo con un semplice esempio di caricamento giornaliero di 100 GB di dati:
| Dimensione dati | Dimensione del singolo file | Numero di file | Crediti/giorno (overhead sui file) | Costo/anno (overhead sui file) |
|---|---|---|---|---|
| 100 GB | 25 KB | 4,2 milioni | 251 | 275.000 $ |
| 100 GB | 250 MB | 410 | 0,06 | 66 $ |
Come puoi notare, caricare una grande quantità di file molto piccoli può generare costi elevati legati al solo overhead sui file. Se invece dimensioniamo i file secondo le raccomandazioni (100-250 MB), il costo annuale diventa irrilevante.
Un suggerimento analogo riguarda l'utilizzo di formati compressi (ad esempio gzip) rispetto a quelli non compressi (ad esempio CSV). Snowflake offre prestazioni migliori sui formati compressi e ottieni ulteriori vantaggi, come il trasferimento di volumi di dati nettamente inferiori sulla rete e requisiti di storage più contenuti.
Consiglio inoltre di applicare filtri alle notifiche sui file, in modo da limitarle ai soli file rilevanti e non a tutto ciò che accade all'interno del bucket.
Vantaggi e svantaggi di Snowpipe
Per concludere, vediamo i principali vantaggi di Snowpipe rispetto al comando COPY.
Snowpipe offre semplicità e riduce l'overhead di gestione. Porta automazione e ingestion dei dati quasi in tempo reale. Grazie al modello serverless, ti solleva dalle complessità legate al right-sizing del cluster di compute e si adatta meglio alle variazioni nella dimensione dei workloads. Nella maggior parte dei casi d'uso, Snowpipe è la scelta migliore rispetto al comando COPY. Dove invece non rende al meglio, soprattutto sul fronte dei costi, è quando i file non sono dimensionati correttamente.
Consulta il nostro articolo precedente per un confronto più dettagliato delle diverse opzioni di data loading in Snowflake.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è uno storico Snowflake Data SuperHero e un riconosciuto subject matter expert su Snowflake. La sua esperienza nel mondo dei dati abbraccia oltre un decennio, durante il quale ha ricoperto i ruoli di Snowflake data engineer, architect e admin su progetti in settori e tecnologie molto diversi tra loro. Tomas è un membro attivo della community, dove condivide la propria expertise e ispira gli altri. È inoltre instructor per O'Reilly, dove tiene sessioni di formazione live online.