Esta é a terceira parte da nossa série sobre carregamento de dados no Snowflake. Recapitulando rapidamente: no primeiro post, apresentamos as cinco opções de carregamento de dados. O segundo foi dedicado ao carregamento em lote, a técnica de ingestão mais comum.
Agora vamos a fundo no próximo método: o carregamento contínuo com Snowpipe.
O que é o Snowpipe?
O Snowpipe é um serviço de ingestão de dados totalmente gerenciado pelo Snowflake.
Se você já conhece o carregamento em lote com o comando COPY, pode pensar no Snowpipe como um "COPY automatizado". Os Snowpipes são objetos de primeira classe no Snowflake, ou seja, você os cria e gerencia via SQL como qualquer outro objeto do Snowflake.
O Snowpipe carrega arquivos automaticamente a partir de um stage externo, com base em notificações sobre arquivos recém-chegados. A notificação entregue dispara o processamento no lado do Snowflake, que então executa o comando COPY definido no Snowpipe. As notificações usam o serviço do provedor de nuvem, como o AWS SQS/SNS.
Qual a diferença entre Snowpipe e COPY?
A principal diferença está no modelo de computação e na automação. O Snowpipe é um recurso serverless, ou seja, você não precisa se preocupar com o virtual warehouse que executa o código do Snowpipe (dimensionamento, retomada, suspensão etc.). O Snowflake provisiona automaticamente um cluster de computação para o Snowpipe. Já em automação, o comando COPY exige agendamento para rodar em um horário específico. Em contrapartida, o Snowpipe é acionado automaticamente a partir das notificações recebidas, o que resulta em menor latência.
Como criar um Snowpipe?
Antes de criar um Snowpipe, é importante entender a arquitetura geral de carregamento de dados. O objeto Snowpipe não funciona isolado. Além dele, você também vai precisar de definições de storage integration, stage e file format. A criação desses objetos foi abordada no post anterior sobre carregamento em lote.
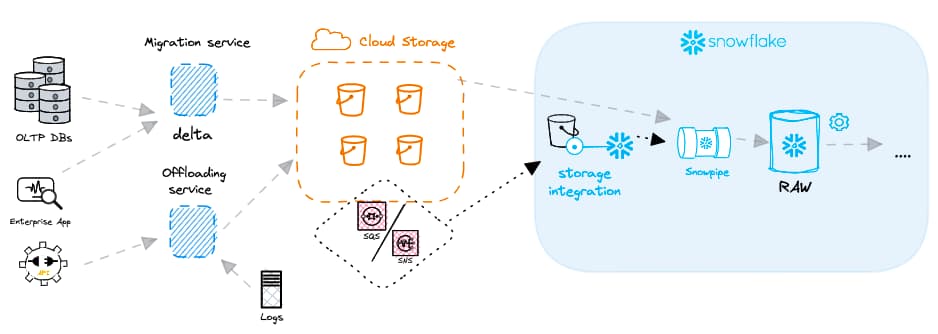
Depois de criar os objetos de stage, storage integration e file format necessários, dá para criar o objeto Snowpipe com o seguinte código:
CREATE OR REPLACE PIPE mypipe
AUTO_INGEST = TRUE AS
COPY INTO snowpipe_landing_table
FROM @my_s3_stage/snowpipe/
FILE_FORMAT = csv_file_format;
Um dos parâmetros importantes a observar aqui é o AUTO_INGEST, que define se você quer carregar arquivos a partir de notificações recebidas (TRUE) ou chamar a API REST do Snowpipe com uma lista de arquivos para ingestão (FALSE).
Configurando notificações de eventos para o Snowpipe na AWS
Além da definição do objeto Snowpipe, você precisa configurar uma integração de notificações. Para carregar arquivos automaticamente, o Snowpipe precisa receber do provedor de nuvem os avisos sobre novos arquivos.
Assim que você cria um objeto Snowpipe com AUTO_INGEST = TRUE, o Snowflake atribui automaticamente um canal de notificação a ele. Se você usa a Amazon Web Services (AWS), o Snowflake recorre ao Amazon Simple Queue Service (SQS) para receber as notificações. O valor do SQS ID está na coluna notification_channel da saída do comando DESC PIPE mypipe.

Para que a ingestão automática do Snowpipe funcione, as notificações sobre novos arquivos precisam chegar a essa fila. Por sorte, dá para montar esse sistema usando o recurso de event notification do S3 para enviar mensagens à fila.
Criar a notificação de evento
Abra o bucket S3 que contém os arquivos que você quer carregar com o Snowpipe. Vá até a aba de propriedades e encontre a configuração de event notification. Crie uma nova com o nome desejado e, se fizer sentido, configure o prefixo para limitar a notificação apenas aos arquivos relevantes. Se você tem vários diretórios e o Snowpipe precisa carregar arquivos de apenas um deles, defina esse filtro para reduzir custos, latência e ruído de eventos.
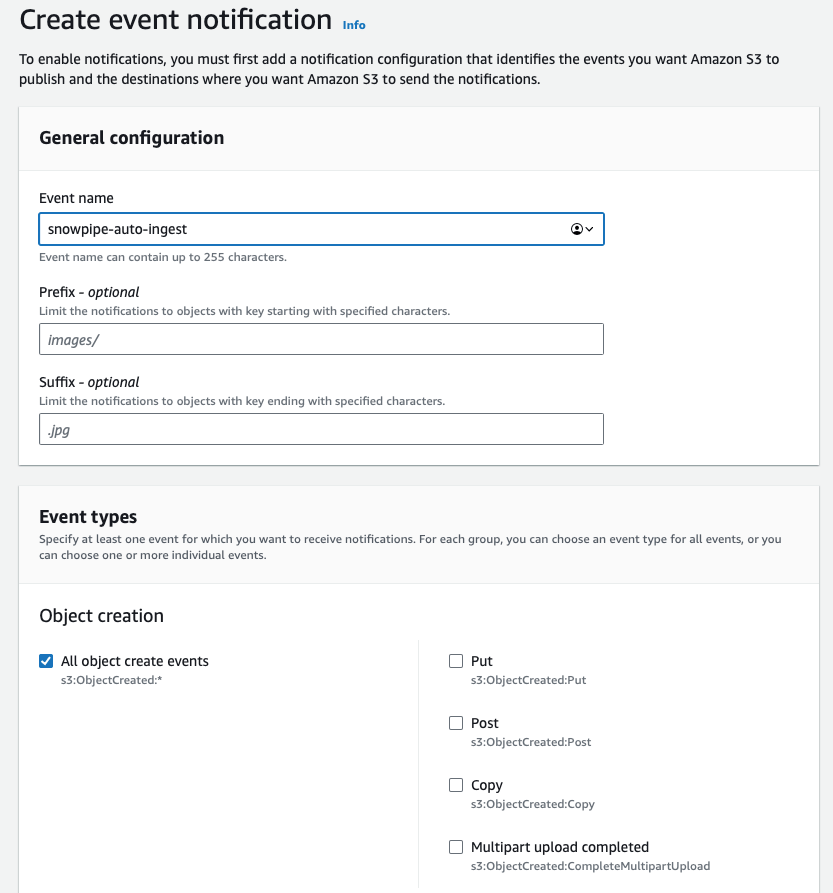
Role até o final da tela, onde fica a configuração de destino. Selecione SQS e cole o valor obtido no comando DESC PIPE mypipe mostrado acima.
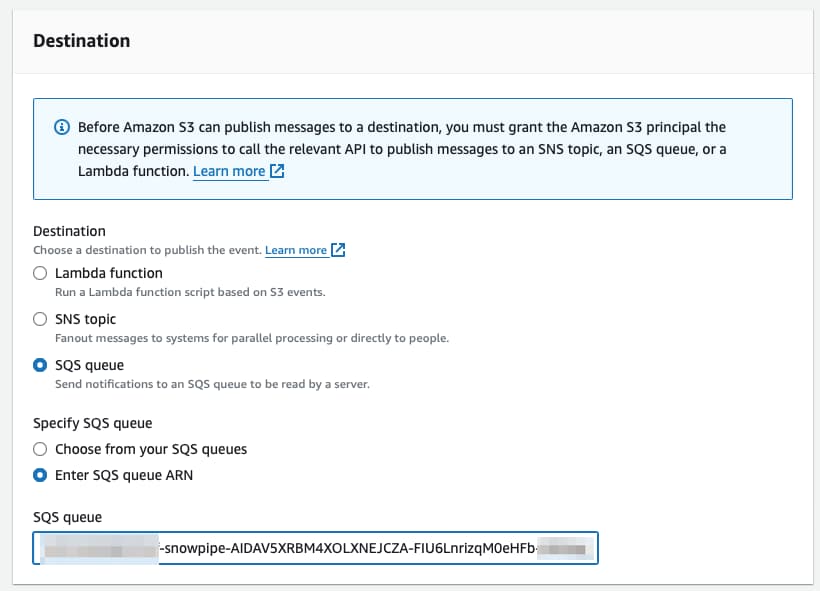
Pronto! Agora, sempre que um novo arquivo chegar ao S3, o Snowpipe é notificado e dispara o comando COPY automagicamente 🪄.
Gerenciando Snowpipes
Existem vários comandos úteis para gerenciar Snowpipes. Vamos explorá-los a fundo.
Listando e descrevendo Snowpipes
Já usamos o DESC PIPE mypipe acima, que mostra informações básicas sobre o pipe em questão. A mesma saída, sem filtrar por um pipe específico, pode ser obtida com o comando SHOW PIPES.
Status do Snowpipe
A função de sistema PIPE_STATUS dá uma visão geral do estado atual do pipe. A saída inclui diversos valores, como o estado atual, informações sobre o último arquivo ingerido e se há arquivos pendentes.
Para ter essa visão geral, execute SELECT SYSTEM$PIPE_STATUS('mypipe');
A saída da função é uma estrutura JSON:
{
"executionState": "RUNNING",
"lastForwardedFilePath": "source_bucket/ingestion/snowpipe/orders-3.csv",
"lastForwardedMessageTimestamp": "2024-01-16T15:45:00.262Z",
"lastIngestedFilePath": "orders-3.csv",
"lastIngestedTimestamp": "2024-01-16T15:45:00.101Z",
"lastPulledFromChannelTimestamp": "2024-01-26T11:01:14.901Z",
"lastReceivedMessageTimestamp": "2024-01-16T17:52:29.645Z",
"notificationChannelName": "arn:aws:sqs:eu-central-1:XXXXXXXXXXXX:sf-snowpipe-AIDAV5XuBMEXOLXcEJCZA-FIU6Lnri5qM0eVFb-D9Hwm",
"numOutstandingMessagesOnChannel": 0,
"pendingFileCount": 0
}
Pausando um pipe
Todo pipe tem um estado de execução. Ao criar um Snowpipe, ele já entra automaticamente no estado RUNNING. Não é preciso ativá-lo, como acontece com uma task do Snowflake. Mesmo assim, pode ser que você queira pausar o pipe por um tempo, em situações como:
- Alterar a propriedade (ownership) do pipe
- Manipular arquivos no diretório de origem
- Testar o processo upstream que gera os arquivos
- Para pausar a execução do pipe, o Snowflake oferece o parâmetro
PIPE_EXECUTION_PAUSED.
Pause a execução de um Snowpipe com o comando ALTER:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = TRUE;
Esse ALTER muda o estado do pipe para PAUSED. Novos arquivos ainda podem chegar ao diretório do stage, mas não são processados enquanto o pipe não for retomado. Atenção: um pipe pode ficar obsoleto (stale) se passar pausado mais tempo que o período de retenção das mensagens de evento recebidas (14 dias por padrão). Para retomar um pipe, volte o parâmetro para FALSE:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = FALSE;
Notificações de erro do Snowpipe
O Snowpipe também pode ser integrado a serviços de mensageria em nuvem (como o AWS SNS) para enviar notificações em caso de falhas. A equipe de operações reage a esses avisos e resolve o problema antes que ele chegue aos usuários de negócio. Para habilitar a integração de erros, há várias etapas de configuração, tanto no Snowflake quanto no provedor de nuvem:
- Criar um tópico SNS na AWS
- Criar uma política IAM na AWS
- Criar um role IAM na AWS
- Criar a integração de notificação (lado do Snowflake)
- Conceder ao Snowflake acesso ao tópico SNS
- Habilitar a notificação de erro no Snowpipe
Para habilitar a notificação de erro no Snowpipe, use o comando ALTER PIPE:
1ALTER PIPE mypipe SET ERROR_INTEGRATION = my_notification_int;
Para ver o passo a passo completo da configuração, dê uma olhada nos nossos posts anteriores sobre notificações de erro para Snowflake Tasks ou na visão mais ampla sobre alertas no Snowflake.
Custos do Snowflake Snowpipe
Como o gerenciamento de custos do Snowflake é prioridade para todos os clientes da plataforma, é fundamental entender como o Snowpipe é cobrado.
O Snowpipe é um recurso serverless, ou seja, você não precisa se preocupar em provisionar e dimensionar o cluster de computação que faz o carregamento. No Snowflake, cada recurso serverless segue um modelo de precificação diferente do usado nos virtual warehouses.
Os custos de computação do Snowpipe são 1,25x os custos regulares de computação de um virtual warehouse (referência: Snowflake Credit Consumption Table). Por exemplo, se o Snowflake usar o equivalente a um warehouse X-Small para carregar seus dados, a cobrança será de 1,25 créditos em vez de 1 crédito por hora de computação.
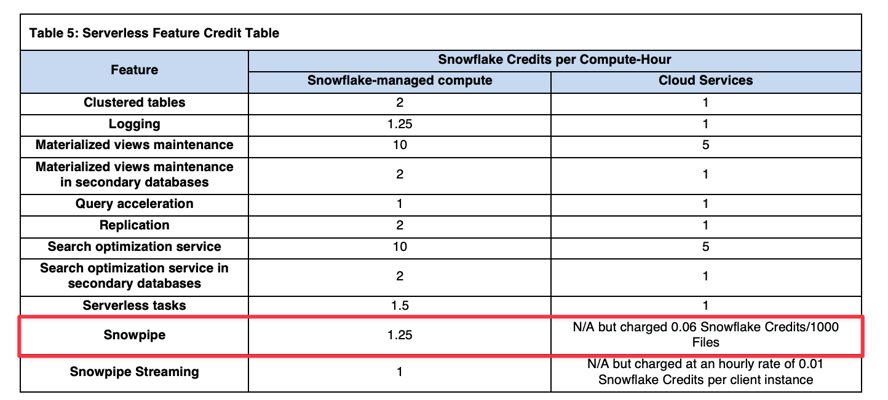
Além dos custos de computação gerenciados pelo Snowflake, há uma taxa adicional por arquivo: 0,06 crédito a cada 1.000 arquivos carregados. Por isso, é muito importante garantir que seus arquivos tenham o tamanho ideal ao usar o Snowpipe.
Se você usa uma ferramenta como o SELECT, fica fácil identificar quando há oportunidades relevantes de otimização de custos do Snowpipe a partir dos tamanhos dos seus arquivos:
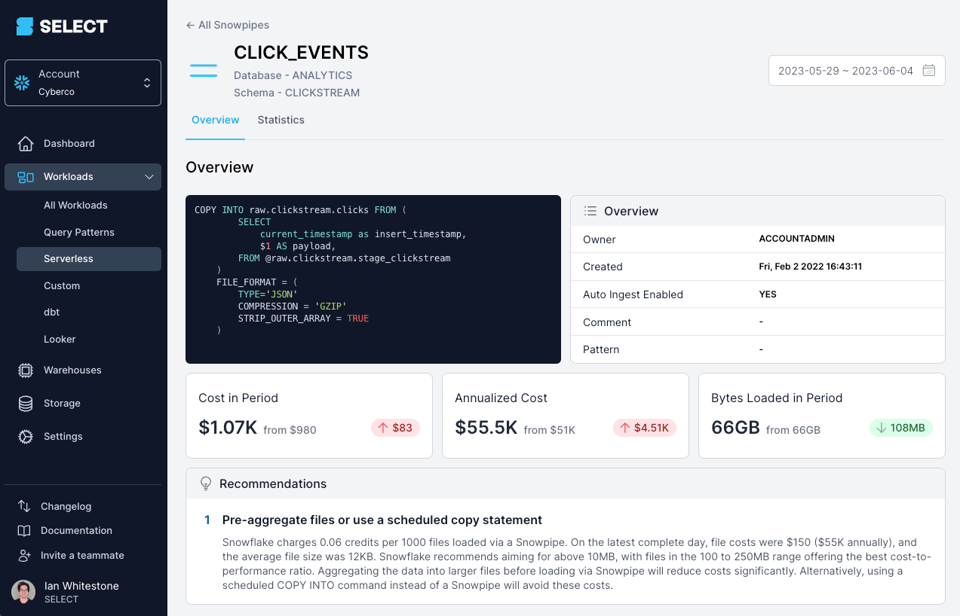
Como alternativa, dá para identificar isso por conta própria usando as views de metadados discutidas a seguir.
Como monitorar os custos do Snowpipe?
O Snowflake mantém metadados detalhados sobre o uso do Snowpipe. Você pode usar esses dados para ter uma visão geral dos seus custos. Vamos olhar algumas views do ACCOUNT_USAGE que trazem dados do Snowpipe. Para obter detalhes sobre todos os seus Snowpipes, use a view PIPES com a seguinte consulta:
SELECT
PIPE_ID,
PIPE_NAME AS NAME,
PIPE_SCHEMA_ID AS SCHEMA_ID,
PIPE_SCHEMA AS SCHEMA_NAME,
PIPE_CATALOG_ID AS DATABASE_ID,
PIPE_CATALOG AS DATABASE_NAME,
IS_AUTOINGEST_ENABLED,
NOTIFICATION_CHANNEL_NAME,
PIPE_OWNER,
DEFINITION,
CREATED,
LAST_ALTERED,
COMMENT,
PATTERN,
Expandir código
Isso retorna uma lista completa, incluindo pipes excluídos. Você pode adicionar a condição WHERE DELETED IS NULL para trazer apenas os pipes existentes.
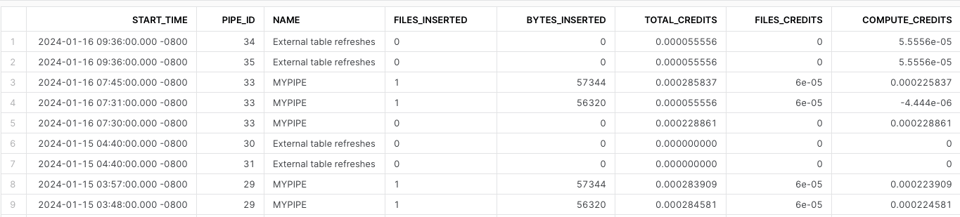
Usando a view de histórico do Snowpipe
Para calcular o custo do Snowpipe, use a PIPE_USAGE_HISTORY. São necessários cálculos personalizados para incluir os créditos cobrados como taxa adicional por arquivo.
SELECT
START_TIME,
PIPE_ID,
COALESCE(PIPE_NAME, 'External table refreshes') AS NAME, -- External table refreshes do not have a pipe name
FILES_INSERTED,
BYTES_INSERTED,
CREDITS_USED AS TOTAL_CREDITS,
0.06 * FILES_INSERTED / 1000 AS FILES_CREDITS, -- 0.06 credits per 1000 files
TOTAL_CREDITS - FILES_CREDITS AS COMPUTE_CREDITS
FROM SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY
ORDER BY START_TIME DESC;
Boas práticas para o Snowpipe
Vamos destacar algumas boas práticas no uso de Snowpipes. Como já comentamos, o fator mais importante para o Snowpipe é garantir que os arquivos estejam com o tamanho correto. O Snowpipe pode ficar bem ineficiente e caro quando ingere muitos arquivos pequenos. Dá para demonstrar isso com um exemplo simples de carregamento diário de 100 GB de dados:
| Volume de dados | Tamanho de cada arquivo | Número de arquivos | Créditos/dia (taxa por arquivo) | Custo/ano (taxa por arquivo) |
|---|---|---|---|---|
| 100 GB | 25 KB | 4,2 milhões | 251 | US$ 275 mil |
| 100 GB | 250 MB | 410 | 0,06 | US$ 66 |
Como dá para ver, carregar uma enorme quantidade de arquivos muito pequenos pode gerar custos altos só pela taxa por arquivo. Quando dimensionamos os arquivos de acordo com a recomendação (100 a 250 MB), o custo anual fica irrisório.
Uma recomendação parecida vale para o uso de formatos compactados (como gzip) no lugar dos não compactados (como CSV). O Snowflake tem desempenho melhor com formatos compactados, e você ainda ganha outros benefícios, como transferir bem menos dados pela rede e reduzir as necessidades de armazenamento.
Outra dica é implementar filtros nas notificações de arquivos, restringindo os envios apenas aos arquivos relevantes em vez de tudo o que acontece dentro do seu bucket.
Vantagens e desvantagens do Snowpipe
Para fechar, vamos falar dos principais benefícios de usar o Snowpipe em vez do comando COPY.
O Snowpipe oferece simplicidade e reduz o trabalho de gerenciamento. Traz automação e ingestão de dados em tempo quase real. Com o modelo serverless, livra você dos desafios de right-sizing do cluster de computação. Também reage melhor a variações no tamanho dos workloads. Na maioria dos casos de uso, o Snowpipe será uma opção melhor que o comando COPY. O cenário em que ele não funciona bem, especialmente do ponto de vista de custo, é quando os arquivos não estão dimensionados corretamente.
Confira nosso post anterior para uma comparação mais detalhada das diferentes opções de carregamento de dados no Snowflake.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME na Norlys
Tomas é Snowflake Data SuperHero de longa data e referência no assunto Snowflake. Sua experiência no mundo de dados passa de uma década, período em que atuou como data engineer, arquiteto e admin do Snowflake em projetos de diversos setores e tecnologias. Tomas é um membro central da comunidade, compartilhando ativamente seu conhecimento e inspirando outras pessoas. Também é instrutor da O'Reilly, conduzindo treinamentos online ao vivo.