本記事は、Snowflakeへのデータロードをテーマにしたシリーズの第3回です。簡単におさらいすると、第1回では5つのデータロード手法を比較し、第2回では最も一般的な取り込み方法であるバッチロードを取り上げました。
今回はその続きとして、次の取り込み方式であるSnowpipeによる継続的ロードを深掘りしていきます。
Snowpipeとは
Snowpipeは、Snowflakeが提供するフルマネージドのデータ取り込みサービスです。
COPYコマンドによるバッチロードに馴染みがあれば、Snowpipeは「自動化されたCOPYコマンド」と考えるとイメージしやすいでしょう。SnowpipeはSnowflakeのファーストクラスオブジェクトで、他のオブジェクトと同じようにSQLで作成・管理できます。
Snowpipeは、新しく到着したファイルに関する通知を受け取ると、外部ステージからそのファイルを自動的にロードします。通知が届くとSnowflake側で処理が起動し、Snowpipeに定義されたCOPYコマンドが実行される仕組みです。通知には、AWSのSQS/SNSなどクラウドプロバイダー側の通知サービスを利用します。
SnowpipeとCOPYの違い
大きな違いは、コンピュートモデルと自動化の仕組みにあります。Snowpipeはサーバーレス機能のため、実行用の仮想ウェアハウス(サイズ設定、再開、停止など)を意識する必要がありません。Snowflakeが自動的にコンピュートクラスタを用意してくれます。自動化の面では、COPYコマンドが決まった時刻に確実に動くようスケジューリングを要するのに対し、Snowpipeは通知をトリガーに自動で動くため、レイテンシも低く抑えられます。
Snowpipeの作成方法
Snowpipeを作成する前に、データロード全体のアーキテクチャを把握しておくことが大切です。Snowpipeオブジェクトは単独では機能せず、ストレージ統合、ステージ、ファイル形式の定義もあわせて必要になります。これらの作成方法は前回のバッチロードの記事で解説しています。
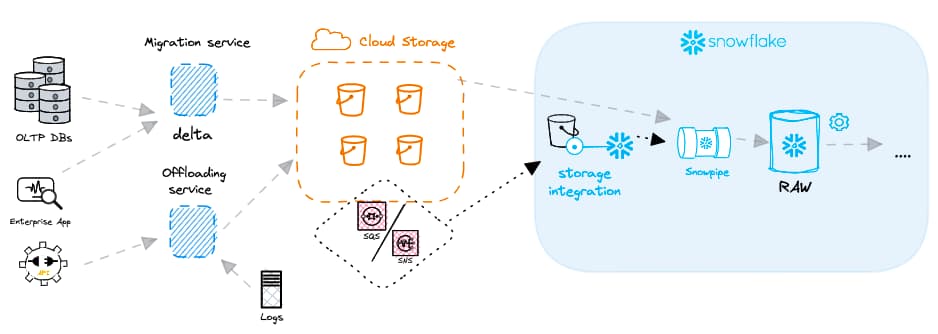
必要なステージ、ストレージ統合、ファイル形式の各オブジェクトを準備できたら、以下のコードでSnowpipeオブジェクトを作成できます。
CREATE OR REPLACE PIPE mypipe
AUTO_INGEST = TRUE AS
COPY INTO snowpipe_landing_table
FROM @my_s3_stage/snowpipe/
FILE_FORMAT = csv_file_format;
ここで押さえておきたい重要なパラメーターが AUTO_INGEST です。通知を受けてファイルをロードする(TRUE)か、取り込み対象のファイル一覧を指定してSnowpipe REST APIを呼び出す(FALSE)かを切り替えます。
AWSでのSnowpipe用イベント通知の設定
Snowpipeオブジェクトの定義に加えて、通知統合(notification integration)の設定も必要です。ファイルを自動でロードするには、Snowpipeが新しいファイルに関する通知をクラウドプロバイダーから受け取れるようにしておかなければなりません。
AUTO_INGEST = TRUE でSnowpipeを作成すると、Snowflakeが自動的に通知チャネルを割り当てます。AWS(Amazon Web Services)を使っている場合、通知の受信にはAmazon Simple Queue Service(SQS)が使われます。SQS IDは DESC PIPE mypipe の出力結果の notification_channel 列で確認できます。

自動取り込みを動作させるには、新しいファイルに関する通知をこのキューへ送る必要があります。幸い、S3のイベント通知機能を使えば、キューにメッセージを送信する仕組みを簡単に構築できます。
イベント通知の作成
Snowpipeでロードしたいファイルが置かれているS3バケットを開きます。「プロパティ」タブからイベント通知の設定項目を探し、任意の名前で新規通知を作成しましょう。必要に応じてprefixを設定し、対象を関連ファイルだけに絞り込みます。複数のディレクトリがあり、Snowpipeで読み込みたいのが特定の1つだけであれば、prefixを指定してコスト・レイテンシ・余計なイベントを抑えられます。
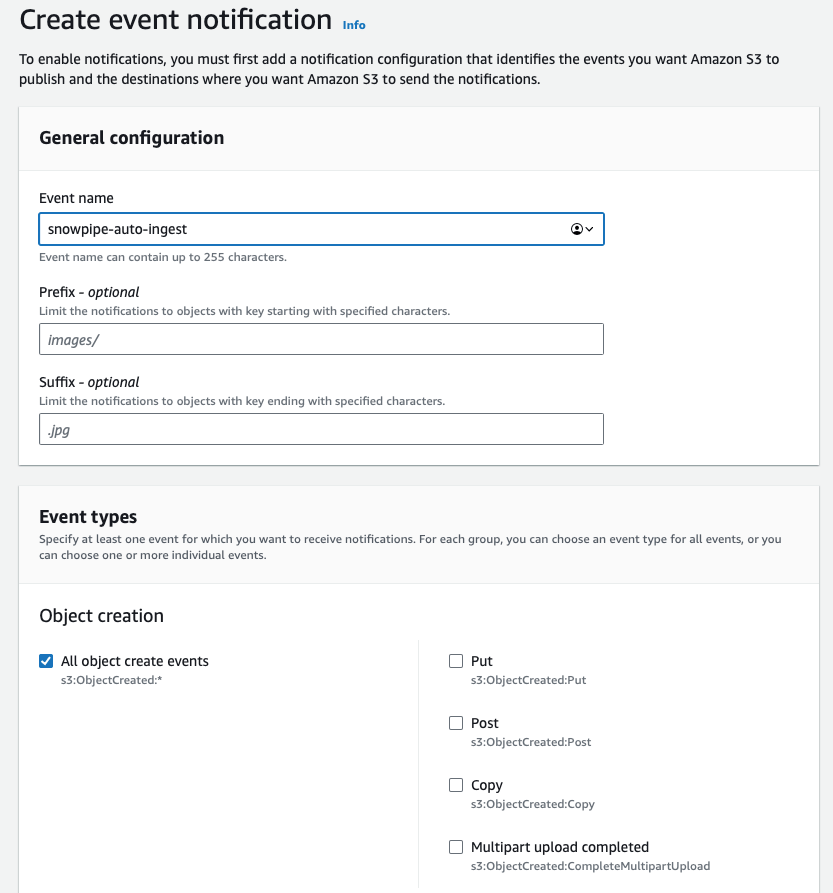
画面下部の宛先設定までスクロールし、SQSを選択して、先ほど DESC PIPE mypipe で取得した値を貼り付けます。
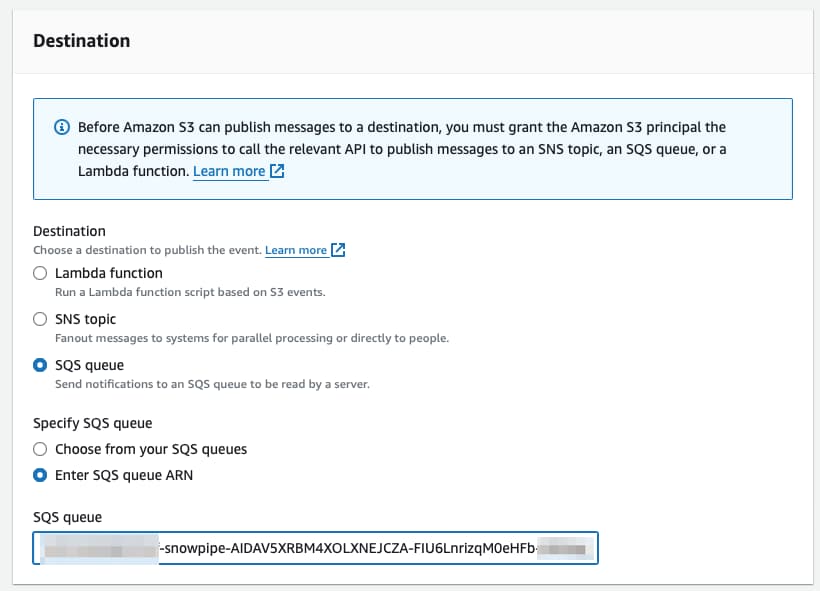
設定は以上です。これでS3に新しいファイルが置かれるたびにSnowpipeへ通知が届き、COPY コマンドが自動的に実行されます🪄。
Snowpipeの管理
Snowpipeを管理するうえで便利なコマンドがいくつもあります。順番に見ていきましょう。
Snowpipeの一覧表示と詳細確認
先ほども DESC PIPE mypipe で特定パイプの基本情報を取得しました。同様の情報を、特定のパイプに絞らずまとめて確認したい場合は SHOW PIPES コマンドが使えます。
Snowpipeのステータス
システム関数 PIPE_STATUS を使うと、パイプの現在の状態を一目で把握できます。出力には、現在のステート、直近に取り込んだファイルの情報、保留中のファイルの有無など、複数の値が含まれます。
確認したいときは、SELECT SYSTEM$PIPE_STATUS('mypipe') を実行します。
戻り値はJSON構造です。
{
"executionState": "RUNNING",
"lastForwardedFilePath": "source_bucket/ingestion/snowpipe/orders-3.csv",
"lastForwardedMessageTimestamp": "2024-01-16T15:45:00.262Z",
"lastIngestedFilePath": "orders-3.csv",
"lastIngestedTimestamp": "2024-01-16T15:45:00.101Z",
"lastPulledFromChannelTimestamp": "2024-01-26T11:01:14.901Z",
"lastReceivedMessageTimestamp": "2024-01-16T17:52:29.645Z",
"notificationChannelName": "arn:aws:sqs:eu-central-1:XXXXXXXXXXXX:sf-snowpipe-AIDAV5XuBMEXOLXcEJCZA-FIU6Lnri5qM0eVFb-D9Hwm",
"numOutstandingMessagesOnChannel": 0,
"pendingFileCount": 0
}
パイプの一時停止
パイプには実行ステートがあります。Snowpipeを作成した時点で自動的に RUNNING 状態となり、Snowflakeタスクのように改めて有効化する必要はありません。とはいえ、次のような場面ではパイプを一時的に止めたいことがあります。
- パイプの所有者を変更したいとき
- ソースディレクトリ内のファイルを操作したいとき
- ファイルを生成する上流プロセスをテストしたいとき
- パイプの実行を止めるために、Snowflakeには
PIPE_EXECUTION_PAUSEDパラメーターが用意されています。
ALTER文でSnowpipeの実行を一時停止します。
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = TRUE;
このALTER文を実行すると、パイプのステートが PAUSED に変わります。ステージディレクトリには引き続きファイルを置けますが、パイプを再開するまで処理されません。なお、受信したイベントメッセージの保持期間(デフォルトは14日間)を超えて停止し続けると、パイプが古くなって動かせなくなる場合があるので注意してください。再開するには、パラメーターを FALSE に戻します。
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = FALSE;
Snowpipeのエラー通知
Snowpipeは、AWS SNSなどのクラウドメッセージングサービスと連携し、障害発生時に通知を送ることもできます。運用チームが通知に素早く対応できれば、ビジネスユーザーに気付かれる前に問題を解消できます。エラー連携を有効化するには、Snowflake側とクラウドプロバイダー側の双方で次の設定が必要です。
- AWS SNSトピックの作成
- AWS IAMポリシーの作成
- AWS IAMロールの作成
- 通知統合の作成(Snowflake側)
- SnowflakeへのSNSトピックアクセス権の付与
- Snowpipeでのエラー通知の有効化
Snowpipeでエラー通知を有効化するには、ALTER PIPEコマンドを使います。
1ALTER PIPE mypipe SET ERROR_INTEGRATION = my_notification_int;
設定手順の詳細は、過去記事のSnowflakeタスクのエラー通知の作成や、Snowflakeアラートの全体像をまとめた記事をあわせてご覧ください。
Snowflake Snowpipeのコスト
Snowflakeのコスト管理はすべてのSnowflakeユーザーにとって重要な課題であり、Snowpipeの課金体系を正しく理解しておく必要があります。
Snowpipeはサーバーレス機能のため、ロード用のコンピュートクラスタをプロビジョニングしたりサイズ設定したりする必要はありません。一方でSnowflakeでは、サーバーレス機能ごとに仮想ウェアハウスとは異なる料金モデルが適用されます。
Snowpipeのコンピュートコストは、通常の仮想ウェアハウスの1.25倍です(参考:Snowflake Credit Consumption Table)。たとえば、ロードにX-Small相当のウェアハウスが使われた場合、1コンピュート時間あたり1クレジットではなく1.25クレジットが課金されます。
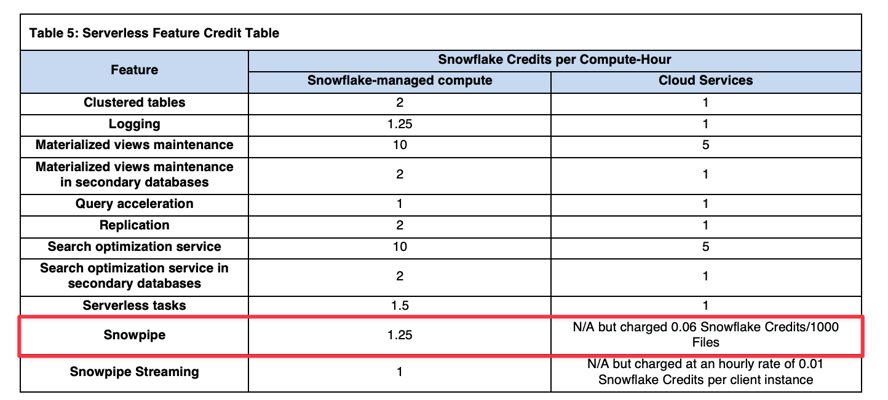
Snowflake側のコンピュートコストに加えて、ファイル件数に応じたオーバーヘッド料金として、1,000ファイルのロードごとに0.06クレジットが課金されます。そのため、Snowpipeを使う際はファイルサイズを適切に揃えることが非常に重要です。
SELECTのようなツールを使えば、ファイルサイズに起因するSnowpipeのコスト最適化の余地を簡単に確認できます。
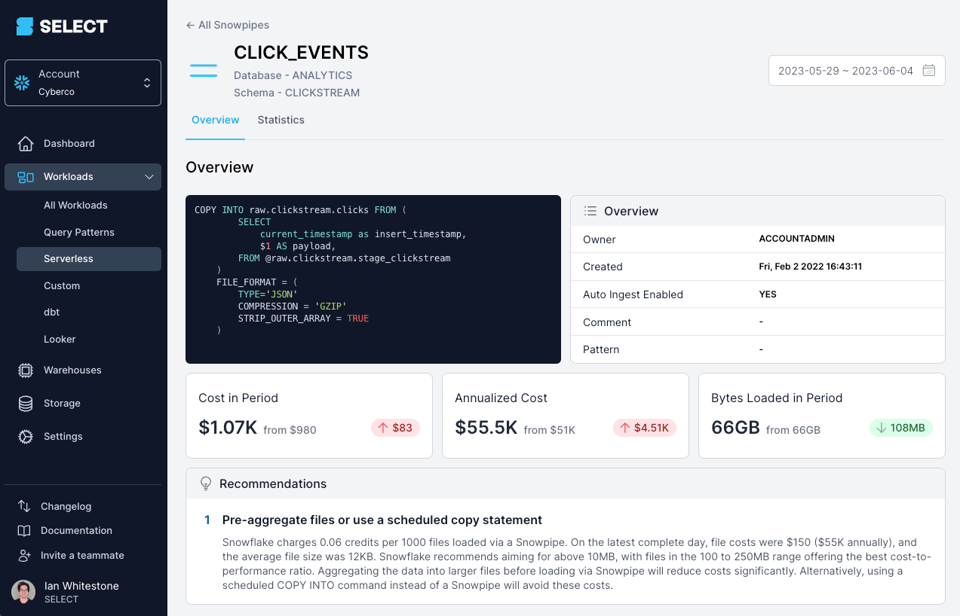
もちろん、後述するメタデータビューを使って自分で調べることもできます。
Snowpipeのコストをモニタリングするには
Snowflakeは、Snowpipeの利用状況に関する詳細なメタデータを保持しています。これを活用すれば、コストの全体像を把握できます。Snowpipeに関するデータを提供する ACCOUNT_USAGE ビューをいくつか見ていきましょう。すべてのSnowpipeの詳細を取得したい場合は、PIPES ビューと次のクエリが便利です。
SELECT
PIPE_ID,
PIPE_NAME AS NAME,
PIPE_SCHEMA_ID AS SCHEMA_ID,
PIPE_SCHEMA AS SCHEMA_NAME,
PIPE_CATALOG_ID AS DATABASE_ID,
PIPE_CATALOG AS DATABASE_NAME,
IS_AUTOINGEST_ENABLED,
NOTIFICATION_CHANNEL_NAME,
PIPE_OWNER,
DEFINITION,
CREATED,
LAST_ALTERED,
COMMENT,
PATTERN,
コードを展開
このクエリでは、削除済みのパイプも含めた完全な一覧が取得できます。現在存在するパイプだけに絞り込みたい場合は、WHERE DELETED IS NULL の条件を追加してください。
Snowpipe履歴ビューの活用
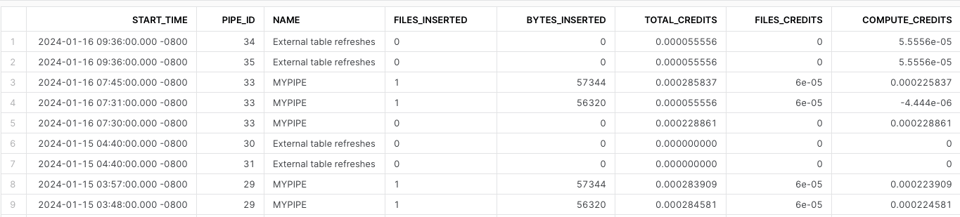
Snowpipeのコスト算出には、PIPE_USAGE_HISTORY が役立ちます。ファイルオーバーヘッド料金として課金されるクレジットも含めるには、独自に計算する必要があります。
SELECT
START_TIME,
PIPE_ID,
COALESCE(PIPE_NAME, 'External table refreshes') AS NAME, -- External table refreshes do not have a pipe name
FILES_INSERTED,
BYTES_INSERTED,
CREDITS_USED AS TOTAL_CREDITS,
0.06 * FILES_INSERTED / 1000 AS FILES_CREDITS, -- 0.06 credits per 1000 files
TOTAL_CREDITS - FILES_CREDITS AS COMPUTE_CREDITS
FROM SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY
ORDER BY START_TIME DESC;
Snowpipeのベストプラクティス
ここでは、Snowpipeを使ううえで押さえておきたいベストプラクティスをいくつか紹介します。先ほど触れたとおり、最も重要なのはファイルサイズを適切に揃えることです。小さなファイルを大量に取り込ませると、Snowpipeは非効率かつ高コストになりがちです。1日あたり100GBのデータをロードする簡単な例で見てみましょう。
| データサイズ | 1ファイルあたりのサイズ | ファイル数 | 1日あたりのクレジット(ファイルオーバーヘッド料金) | 年間コスト(ファイルオーバーヘッド料金) |
|---|---|---|---|---|
| 100 GB | 25 KB | 420万 | 251 | $275K |
| 100 GB | 250 MB | 410 | 0.06 | $66 |
このとおり、極端に小さなファイルを大量にロードすると、ファイルオーバーヘッド料金だけで多額のコストが発生します。推奨サイズ(100〜250 MB)に揃えれば、年間コストはごくわずかに収まります。
もうひとつ、非圧縮形式(CSVなど)よりも圧縮ファイル形式(gzipなど)の利用もおすすめです。Snowflakeは圧縮形式の方が処理性能が高く、ネットワーク経由のデータ転送量やストレージ要件を大きく削減できるなど、副次的なメリットもあります。
あわせて、ファイル通知にフィルターを設定し、バケット内のすべてのイベントではなく、関連するファイルにだけ通知を絞り込むことも忘れずに実施しましょう。
Snowpipeのメリットとデメリット
最後に、COPYコマンドと比べたSnowpipeの主なメリットを整理しておきましょう。
Snowpipeはシンプルで、管理の手間を大幅に減らせます。自動化とほぼリアルタイムの取り込みを実現し、サーバーレスモデルのおかげでコンピュートクラスタのライトサイジングに悩む必要もありません。workloadsの規模変動にも柔軟に対応できます。多くのユースケースでは COPY コマンドよりSnowpipeが有力な選択肢になりますが、ファイルサイズが適切でない場合は、特にコスト面で力を発揮しきれません。
Snowflakeで使えるデータロード手法のより詳しい比較は、過去記事をご覧ください。
Tomáš Sobotík・Senior Data Engineer & Snowflake SME at Norlys
Tomasは長年にわたりSnowflake Data SuperHeroとして活躍してきた、Snowflakeの第一人者です。データ業界での10年以上にわたるキャリアの中で、多様な業界・技術領域のプロジェクトでSnowflakeのデータエンジニア、アーキテクト、管理者として携わってきました。コミュニティの中核メンバーとして積極的に知見を発信し、多くの人に刺激を与えています。さらにO'Reillyのインストラクターとして、オンラインのライブトレーニングも担当しています。