Voici le troisième volet de notre série consacrée au chargement de données dans Snowflake. Pour rappel, nous avons passé en revue les cinq options de chargement de données dans le premier article. Le deuxième portait sur le chargement par lots, la technique d'ingestion la plus répandue.
Ce nouvel article prend la suite et explore en profondeur la méthode d'ingestion suivante : le chargement continu avec Snowpipe.
Qu'est-ce que Snowpipe ?
Snowpipe est un service d'ingestion de données entièrement managé proposé par Snowflake.
Si vous connaissez déjà le chargement par lots via la commande COPY, vous pouvez voir Snowpipe comme une commande COPY automatisée. Les Snowpipes sont des objets Snowflake à part entière : vous les créez et les gérez en SQL, comme n'importe quel autre objet Snowflake.
Snowpipe charge automatiquement les fichiers depuis un stage externe à partir de notifications signalant l'arrivée de nouveaux fichiers. La notification reçue déclenche un traitement côté Snowflake, qui exécute alors la commande COPY définie dans le Snowpipe. Ces notifications s'appuient sur le service de notification du fournisseur cloud, par exemple AWS SQS/SNS.
Quelle différence entre Snowpipe et COPY ?
La principale différence tient au modèle de calcul et à l'automatisation. Snowpipe étant une fonctionnalité serverless, vous n'avez pas à vous préoccuper du virtual warehouse qui exécute le code Snowpipe (dimensionnement, reprise, suspension, etc.). Snowflake provisionne automatiquement un cluster de calcul pour Snowpipe. Côté automatisation, la commande COPY doit être planifiée pour s'exécuter à un instant précis. Snowpipe, à l'inverse, se déclenche automatiquement à la réception des notifications, ce qui réduit la latence.
Comment créer un Snowpipe ?
Avant de créer un Snowpipe, il faut comprendre l'architecture globale de chargement des données. L'objet Snowpipe ne fonctionne pas seul. Il vous faudra également définir une storage integration, un stage et un file format. Nous avons détaillé la création de ces objets dans l'article précédent sur le chargement par lots.
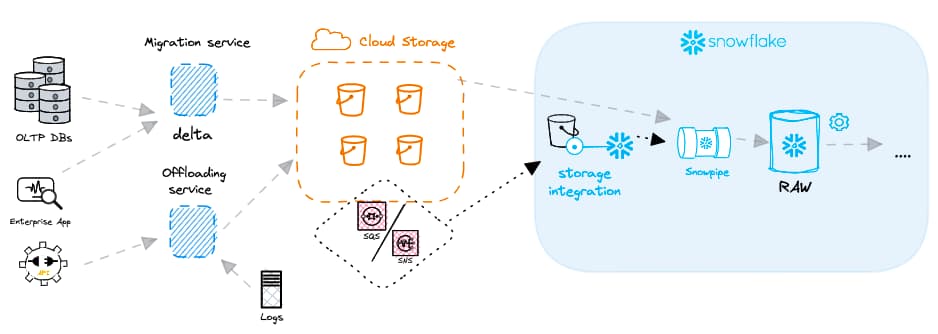
Une fois les objets stage, storage integration et file format en place, vous pouvez créer un objet Snowpipe avec le code suivant :
CREATE OR REPLACE PIPE mypipe
AUTO_INGEST = TRUE AS
COPY INTO snowpipe_landing_table
FROM @my_s3_stage/snowpipe/
FILE_FORMAT = csv_file_format;
L'un des paramètres clés à retenir est AUTO_INGEST. Il indique si vous souhaitez charger les fichiers à partir des notifications reçues (TRUE) ou appeler l'API REST de Snowpipe avec une liste de fichiers à ingérer (FALSE).
Configurer les notifications d'événements pour Snowpipe sur AWS
En complément de la définition de l'objet Snowpipe, vous devez configurer une intégration de notification. Pour charger automatiquement les fichiers, Snowpipe doit recevoir du fournisseur cloud les notifications signalant les nouveaux fichiers.
Lorsque vous créez un objet Snowpipe avec AUTO_INGEST = TRUE, Snowflake lui attribue automatiquement un canal de notification. Sur Amazon Web Services (AWS), Snowflake s'appuie sur Amazon Simple Queue Service (SQS) pour recevoir les notifications. L'ID SQS est disponible dans la colonne notification_channel du résultat de DESC PIPE mypipe.

Pour que l'auto ingest de Snowpipe fonctionne, les notifications relatives aux nouveaux fichiers doivent être envoyées vers cette file. Bonne nouvelle : ce mécanisme peut être mis en place via la fonctionnalité event notification de S3, qui transmet les messages à la file.
Créer la notification d'événement
Ouvrez le bucket S3 qui contient les fichiers à charger avec Snowpipe. Allez dans l'onglet properties et repérez la configuration des event notifications. Créez-en une nouvelle, donnez-lui un nom et, si besoin, définissez un préfixe pour cibler uniquement les fichiers pertinents. Si vous avez plusieurs répertoires et que Snowpipe ne doit charger qu'un seul d'entre eux, précisez-le pour réduire les coûts, la latence et le bruit d'événements.
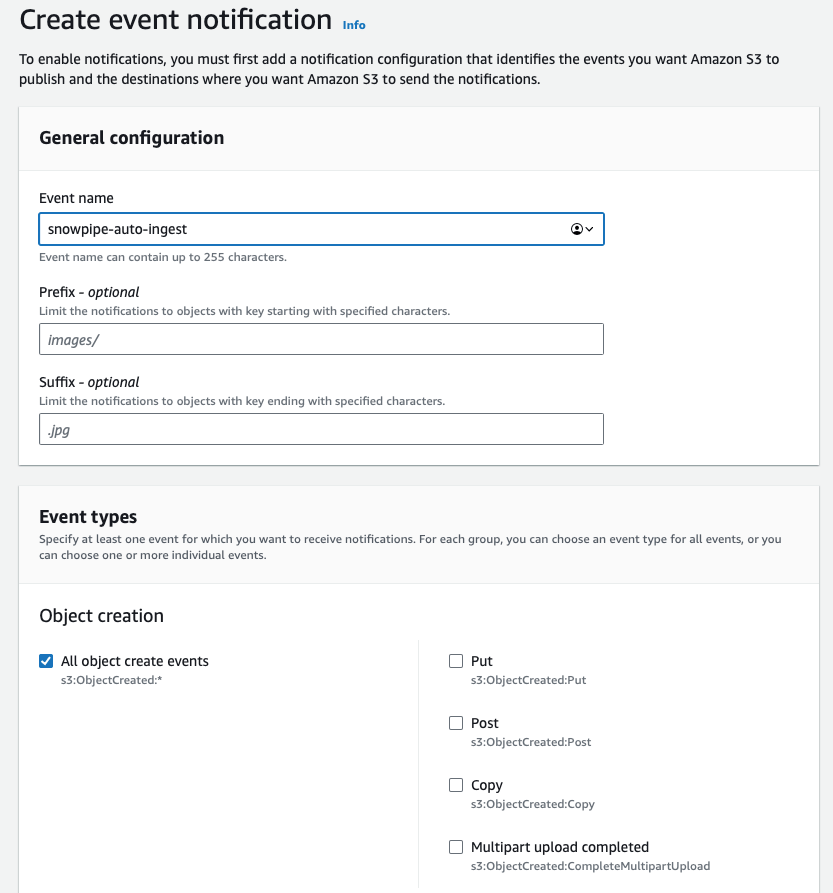
Faites défiler jusqu'en bas de l'écran, à la section de configuration de la destination. Sélectionnez SQS et collez la valeur récupérée via la commande DESC PIPE mypipe évoquée plus haut.
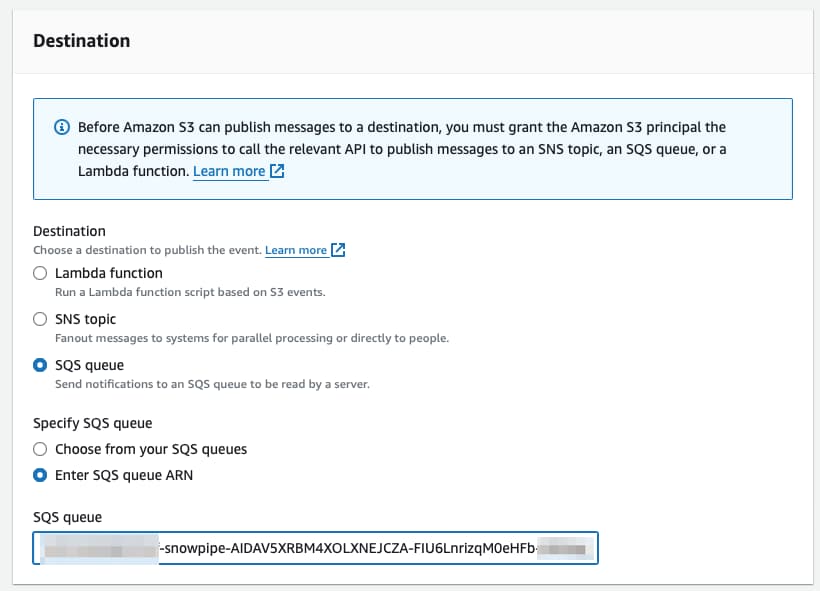
Et c'est tout ! Désormais, dès qu'un nouveau fichier atterrit dans S3, Snowpipe en est notifié et déclenche la commande COPY comme par magie 🪄.
Gérer les Snowpipes
Plusieurs commandes pratiques facilitent la gestion des Snowpipes. Passons-les en revue.
Lister et décrire les Snowpipes
Nous avons déjà utilisé DESC PIPE mypipe plus haut, qui fournit les informations de base sur un pipe donné. Pour obtenir le même résultat sans filtre sur un pipe précis, utilisez la commande SHOW PIPES.
Statut d'un Snowpipe
La fonction système PIPE_STATUS offre une vue d'ensemble de l'état actuel du pipe. La sortie contient plusieurs informations : état courant, détails sur le dernier fichier ingéré et présence éventuelle de fichiers en attente.
Pour obtenir cet aperçu, exécutez SELECT SYSTEM$PIPE_STATUS('mypipe');
La fonction renvoie une structure JSON :
{
"executionState": "RUNNING",
"lastForwardedFilePath": "source_bucket/ingestion/snowpipe/orders-3.csv",
"lastForwardedMessageTimestamp": "2024-01-16T15:45:00.262Z",
"lastIngestedFilePath": "orders-3.csv",
"lastIngestedTimestamp": "2024-01-16T15:45:00.101Z",
"lastPulledFromChannelTimestamp": "2024-01-26T11:01:14.901Z",
"lastReceivedMessageTimestamp": "2024-01-16T17:52:29.645Z",
"notificationChannelName": "arn:aws:sqs:eu-central-1:XXXXXXXXXXXX:sf-snowpipe-AIDAV5XuBMEXOLXcEJCZA-FIU6Lnri5qM0eVFb-D9Hwm",
"numOutstandingMessagesOnChannel": 0,
"pendingFileCount": 0
}
Mettre un pipe en pause
Un pipe possède un état d'exécution. À sa création, un Snowpipe passe automatiquement à l'état RUNNING : nul besoin de l'activer comme c'est le cas pour une Snowflake task. Plusieurs situations peuvent toutefois justifier sa mise en pause :
- Changement de propriétaire du pipe
- Manipulation des fichiers dans le répertoire source
- Test du processus amont qui génère les fichiers
- Pour suspendre l'exécution du pipe, Snowflake propose le paramètre
PIPE_EXECUTION_PAUSED.
Suspendez l'exécution d'un Snowpipe avec l'instruction ALTER :
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = TRUE;
Cette instruction fait passer le pipe à l'état PAUSED. De nouveaux fichiers peuvent toujours arriver dans le répertoire du stage, mais ils ne seront traités qu'après reprise du pipe. Attention : un pipe peut devenir obsolète s'il reste en pause au-delà de la durée de rétention des messages d'événements (14 jours par défaut). Pour le relancer, repassez le paramètre à FALSE :
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = FALSE;
Notifications d'erreur Snowpipe
Snowpipe peut aussi être intégré aux services de messagerie cloud (AWS SNS, par exemple) pour envoyer des notifications en cas d'échec. L'équipe d'exploitation peut alors réagir et résoudre l'incident avant qu'il ne soit détecté par les utilisateurs métier. L'activation de cette intégration d'erreurs nécessite plusieurs étapes de configuration, côté Snowflake comme côté fournisseur cloud :
- Créer un AWS SNS Topic
- Créer une AWS IAM Policy
- Créer un AWS IAM Role
- Créer la Notification Integration (côté Snowflake)
- Accorder à Snowflake l'accès au topic SNS
- Activer la notification d'erreur dans Snowpipe
Pour activer la notification d'erreur dans Snowpipe, utilisez la commande ALTER PIPE :
1ALTER PIPE mypipe SET ERROR_INTEGRATION = my_notification_int;
Pour la mise en place pas à pas, consultez nos articles précédents sur la création de notifications d'erreur pour les Snowflake Tasks ou notre tour d'horizon plus général des alertes Snowflake.
Coûts de Snowflake Snowpipe
La gestion des coûts Snowflake étant une priorité pour tous les clients Snowflake, il est essentiel de comprendre comment Snowpipe est facturé.
Snowpipe étant une fonctionnalité serverless, vous n'avez ni à provisionner ni à dimensionner le cluster de calcul utilisé pour le chargement. Chez Snowflake, chaque fonctionnalité serverless suit un modèle de tarification distinct de celui des virtual warehouses.
Les coûts de calcul de Snowpipe sont 1,25x supérieurs à ceux d'un virtual warehouse standard (référence : Snowflake Credit Consumption Table). Par exemple, si Snowflake mobilise l'équivalent d'un warehouse X-Small pour charger vos données, vous serez facturé 1,25 crédit au lieu de 1 crédit par heure de calcul.
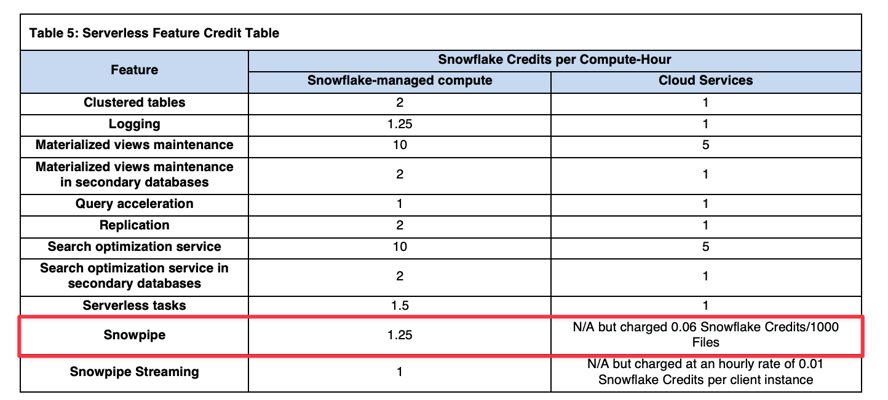
S'ajoutent aux coûts de calcul managés par Snowflake des frais par fichier : 0,06 crédit pour 1 000 fichiers chargés. Il est donc crucial de veiller à ce que vos fichiers soient correctement dimensionnés avec Snowpipe.
Avec un outil comme SELECT, vous repérez en un clin d'œil les opportunités d'optimisation des coûts Snowpipe liées à la taille de vos fichiers :
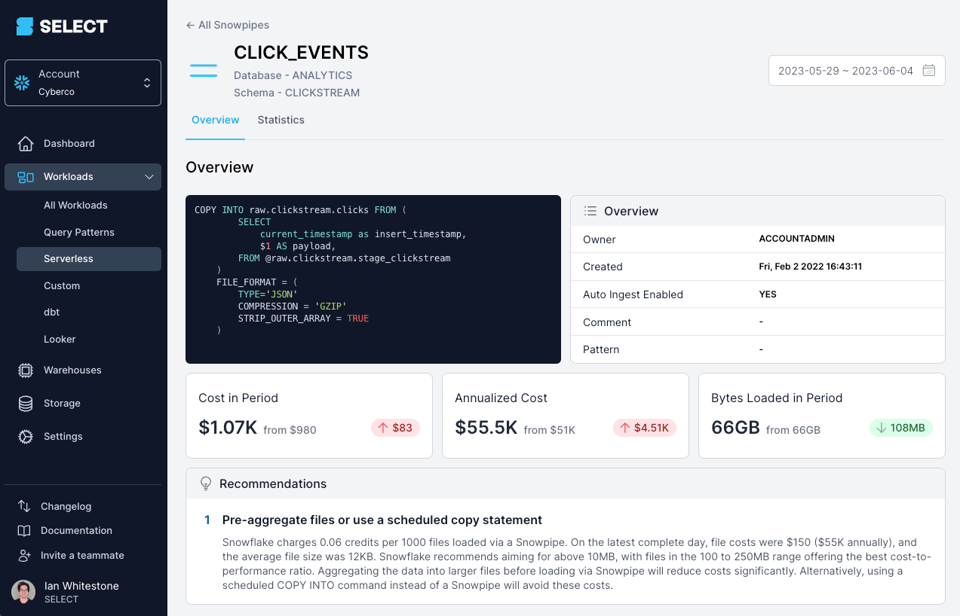
Vous pouvez aussi les identifier vous-même grâce aux vues de métadonnées présentées ci-dessous.
Comment suivre les coûts de Snowpipe ?
Snowflake conserve des métadonnées détaillées sur votre usage de Snowpipe. Vous pouvez les exploiter pour obtenir une vision claire de vos coûts. Examinons quelques vues ACCOUNT_USAGE qui fournissent ces informations. Pour obtenir le détail de tous vos Snowpipes, utilisez la vue PIPES avec la requête suivante :
SELECT
PIPE_ID,
PIPE_NAME AS NAME,
PIPE_SCHEMA_ID AS SCHEMA_ID,
PIPE_SCHEMA AS SCHEMA_NAME,
PIPE_CATALOG_ID AS DATABASE_ID,
PIPE_CATALOG AS DATABASE_NAME,
IS_AUTOINGEST_ENABLED,
NOTIFICATION_CHANNEL_NAME,
PIPE_OWNER,
DEFINITION,
CREATED,
LAST_ALTERED,
COMMENT,
PATTERN,
Développer le code
Cette requête renvoie la liste complète, y compris les pipes supprimés. Ajoutez la condition WHERE DELETED IS NULL pour ne récupérer que les pipes existants.
Utiliser la vue Snowpipe History
Pour calculer le coût de Snowpipe, vous pouvez exploiter PIPE_USAGE_HISTORY. Des calculs personnalisés sont nécessaires pour intégrer les crédits facturés au titre des frais par fichier.
SELECT
START_TIME,
PIPE_ID,
COALESCE(PIPE_NAME, 'External table refreshes') AS NAME, -- External table refreshes do not have a pipe name
FILES_INSERTED,
BYTES_INSERTED,
CREDITS_USED AS TOTAL_CREDITS,
0.06 * FILES_INSERTED / 1000 AS FILES_CREDITS, -- 0.06 credits per 1000 files
TOTAL_CREDITS - FILES_CREDITS AS COMPUTE_CREDITS
FROM SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY
ORDER BY START_TIME DESC;
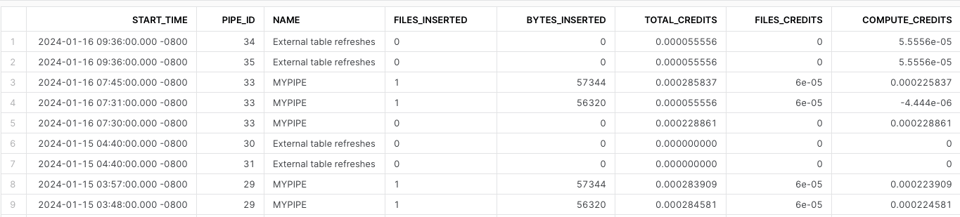
Bonnes pratiques Snowpipe
Voici quelques bonnes pratiques pour tirer le meilleur de Snowpipe. Comme nous l'avons vu, le facteur décisif est le bon dimensionnement des fichiers. Snowpipe peut s'avérer très inefficace et coûteux lorsqu'il ingère une multitude de petits fichiers. Illustrons-le avec un exemple simple : un chargement quotidien de 100 Go de données.
| Volume de données | Taille de fichier | Nombre de fichiers | Crédits/jour (frais par fichier) | Coût/an (frais par fichier) |
|---|---|---|---|---|
| 100 Go | 25 Ko | 4,2 millions | 251 | 275 000 $ |
| 100 Go | 250 Mo | 410 | 0,06 | 66 $ |
Comme vous le constatez, charger une multitude de très petits fichiers peut générer des coûts élevés rien qu'au titre des frais par fichier. Avec des fichiers dimensionnés selon les recommandations (100 à 250 Mo), le coût annuel devient négligeable.
Autre recommandation du même ordre : privilégier les formats compressés (gzip, par exemple) plutôt que non compressés (CSV). Snowflake est plus performant sur les formats compressés, sans compter d'autres bénéfices comme des volumes transférés sur le réseau bien moindres et des besoins de stockage réduits.
Je recommande également de mettre en place des filtres sur les notifications de fichiers, pour ne déclencher des notifications que sur les fichiers pertinents et non sur toute l'activité du bucket.
Avantages et inconvénients de Snowpipe
Pour conclure, voyons les principaux atouts de Snowpipe face à la commande COPY.
Snowpipe apporte simplicité et allège la charge de gestion. Il offre l'automatisation et une ingestion quasi temps réel. Grâce à son modèle serverless, il vous épargne les écueils du right-sizing du cluster de calcul. Il s'adapte mieux aux variations de volume des workloads. Dans la plupart des cas d'usage, Snowpipe sera un meilleur choix que la commande COPY. Là où il montre ses limites, surtout côté coûts, c'est lorsque les fichiers sont mal dimensionnés.
Consultez notre article précédent pour une comparaison plus détaillée des différentes options de chargement de données dans Snowflake.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME chez Norlys
Tomas est un Snowflake Data SuperHero de longue date et un expert reconnu de Snowflake. Sa solide expérience dans l'univers de la donnée s'étend sur plus d'une décennie, durant laquelle il a occupé les rôles de data engineer, architecte et administrateur Snowflake sur des projets variés couvrant de nombreux secteurs et technologies. Membre actif de la communauté, Tomas partage volontiers son expertise et inspire ses pairs. Il est également formateur O'Reilly et anime des sessions de formation en direct en ligne.