Esta es la tercera entrega de nuestra serie sobre carga de datos en Snowflake. A modo de repaso, en el primer post recorrimos las cinco opciones disponibles para cargar datos. El segundo se enfocó en la carga por lotes, la técnica de ingesta más común.
Este post le da continuidad con un análisis a fondo del siguiente método de ingesta: la carga continua con Snowpipe.
¿Qué es Snowpipe?
Snowpipe es un servicio de ingesta de datos totalmente administrado por Snowflake.
Si ya conoces la carga por lotes con el comando COPY, puedes pensar en Snowpipe como un "comando copy automatizado". Los Snowpipes son un objeto de primera clase en Snowflake, por lo que se crean y administran mediante SQL, como cualquier otro objeto.
Snowpipe carga automáticamente los archivos desde un stage externo a partir de notificaciones que avisan cuando llegan nuevos archivos. La notificación dispara el procesamiento del lado de Snowflake, donde se ejecuta el comando COPY definido en el Snowpipe. Las notificaciones se apoyan en el servicio de mensajería del proveedor de nube, como AWS SQS/SNS.
¿Cuál es la diferencia entre Snowpipe y COPY?
La diferencia principal está en el modelo de cómputo y la automatización. Snowpipe es una funcionalidad serverless, así que no tienes que preocuparte por el virtual warehouse que ejecuta el código (dimensionamiento, reanudar, suspender, etc.). Snowflake provee automáticamente un cluster de cómputo para Snowpipe. En cuanto a la automatización, el comando COPY requiere de un calendario que garantice su ejecución a una hora exacta. Snowpipe, en cambio, se dispara automáticamente al recibir notificaciones, lo que reduce la latencia.
¿Cómo crear un Snowpipe?
Antes de crear un Snowpipe, conviene entender la arquitectura general de la carga de datos. El objeto Snowpipe no funciona de manera aislada: además de él, vas a necesitar definiciones de storage integration, stage y file format. La creación de estos objetos la cubrimos en el post anterior sobre carga por lotes.
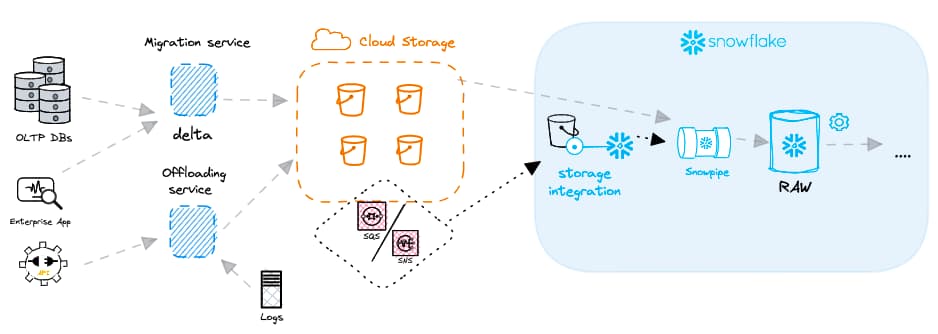
Una vez creados los objetos necesarios de stage, storage integration y file format, puedes crear un objeto Snowpipe con el siguiente código:
CREATE OR REPLACE PIPE mypipe
AUTO_INGEST = TRUE AS
COPY INTO snowpipe_landing_table
FROM @my_s3_stage/snowpipe/
FILE_FORMAT = csv_file_format;
Uno de los parámetros clave es AUTO_INGEST, que indica si quieres cargar archivos a partir de notificaciones recibidas (TRUE) o llamar a la API REST de Snowpipe con una lista de archivos para la ingesta (FALSE).
Configurar notificaciones de eventos para Snowpipe en AWS
Además de la definición del objeto Snowpipe, también debes configurar una integración de notificaciones. Para que pueda cargar archivos automáticamente, Snowpipe necesita recibir notificaciones del proveedor de nube sobre los archivos nuevos.
Cuando creas un objeto Snowpipe con AUTO_INGEST = TRUE, Snowflake le asigna automáticamente un canal de notificación. Si usas Amazon Web Services (AWS), Snowflake utiliza Amazon Simple Queue Service (SQS) para recibir las notificaciones. El ID de SQS lo encuentras en la columna notification_channel del resultado del comando DESC PIPE mypipe.

Para que el auto ingest de Snowpipe funcione, las notificaciones sobre archivos nuevos deben llegar a esta cola. Por suerte, este sistema se puede armar usando la función de notificaciones de eventos de S3 para enviar mensajes a la cola.
Crear la notificación de eventos
Abre el bucket de S3 que contiene los archivos que quieres cargar con Snowpipe. Ve a la pestaña de propiedades y busca la configuración de notificaciones de eventos. Crea una nueva con el nombre que prefieras y, si hace falta, configura el prefijo para limitar la notificación a los archivos relevantes. Si tienes varios directorios y Snowpipe debe cargar archivos solo desde uno, defínelo así para reducir costos, latencia y ruido de eventos.
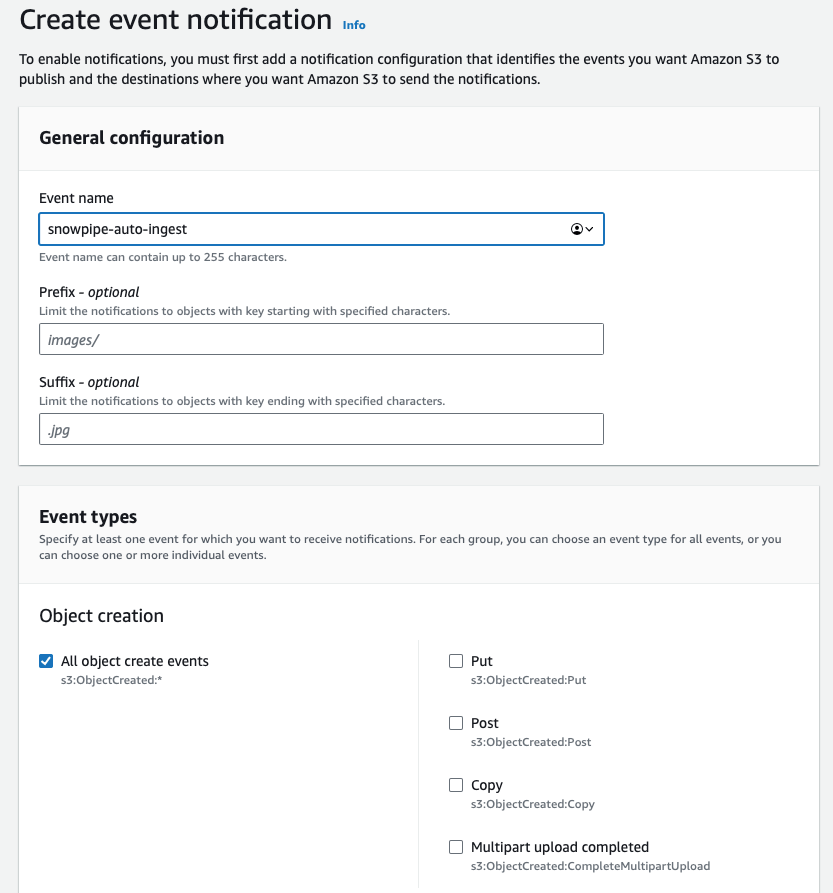
Baja hasta el final de la pantalla, donde está la configuración del destino. Selecciona SQS y pega el valor que obtuviste con el comando DESC PIPE mypipe que vimos arriba.
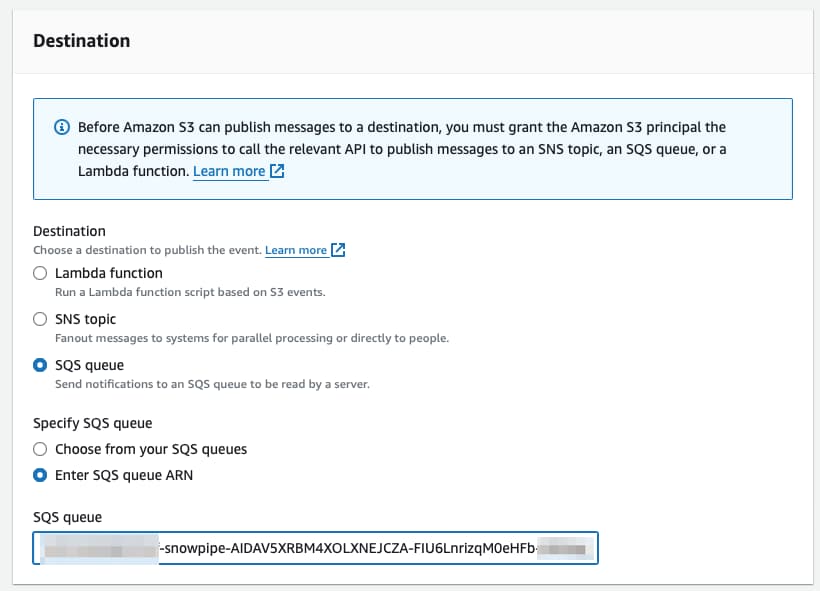
¡Y listo! Ahora, cada vez que llegue un archivo nuevo a S3, Snowpipe será notificado y podrá disparar el comando COPY de forma automágica 🪄.
Administrar Snowpipes
Existen varios comandos útiles para administrar Snowpipes. Veámoslos en detalle.
Listar y describir Snowpipes
Más arriba ya usamos DESC PIPE mypipe, que entrega información básica sobre un pipe puntual. La misma salida, pero sin filtrar por un solo pipe, se obtiene con el comando SHOW PIPES.
Estado del Snowpipe
La función de sistema PIPE_STATUS ofrece un panorama del estado actual del pipe. La salida incluye varios valores: el estado actual, información sobre el último archivo ingerido y si hay archivos pendientes.
Para obtenerlo, ejecuta SELECT SYSTEM$PIPE_STATUS('mypipe');
El resultado de la función es una estructura JSON:
{
"executionState": "RUNNING",
"lastForwardedFilePath": "source_bucket/ingestion/snowpipe/orders-3.csv",
"lastForwardedMessageTimestamp": "2024-01-16T15:45:00.262Z",
"lastIngestedFilePath": "orders-3.csv",
"lastIngestedTimestamp": "2024-01-16T15:45:00.101Z",
"lastPulledFromChannelTimestamp": "2024-01-26T11:01:14.901Z",
"lastReceivedMessageTimestamp": "2024-01-16T17:52:29.645Z",
"notificationChannelName": "arn:aws:sqs:eu-central-1:XXXXXXXXXXXX:sf-snowpipe-AIDAV5XuBMEXOLXcEJCZA-FIU6Lnri5qM0eVFb-D9Hwm",
"numOutstandingMessagesOnChannel": 0,
"pendingFileCount": 0
}
Pausar un pipe
Un pipe tiene un estado de ejecución. Cuando creas un Snowpipe, queda automáticamente en estado RUNNING. No hace falta activarlo, como sí ocurre con un Snowflake task. Aun así, hay situaciones en las que quizás te interese pausarlo por un tiempo:
- Cambiar el propietario del pipe
- Manipular los archivos del directorio de origen
- Probar el proceso upstream que genera los archivos
- Para pausar la ejecución del pipe, Snowflake ofrece el parámetro
PIPE_EXECUTION_PAUSED.
Pausa la ejecución de un Snowpipe con la sentencia ALTER:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = TRUE;
Esta sentencia ALTER cambia el estado del pipe a PAUSED. Los archivos nuevos pueden seguir llegando al directorio del stage, pero no se procesarán hasta que se reanude el pipe. Ten en cuenta que un pipe puede quedar obsoleto si se mantiene pausado más tiempo que el período de retención de los mensajes de eventos recibidos (14 días por defecto). Para reanudarlo, vuelve a poner el parámetro en FALSE:
1ALTER PIPE MYPIPE SET PIPE_EXECUTION_PAUSED = FALSE;
Notificaciones de error en Snowpipe
Snowpipe también puede integrarse con servicios de mensajería en la nube (por ejemplo, AWS SNS) y enviar notificaciones ante fallos. El equipo de operaciones puede reaccionar a esos avisos y resolver el problema antes de que lo detecten los usuarios de negocio. Para habilitar la integración de errores, hay varios pasos de configuración, tanto del lado de Snowflake como del proveedor de nube:
- Crear un AWS SNS Topic
- Crear una AWS IAM Policy
- Crear un AWS IAM Role
- Crear la integración de notificaciones (lado de Snowflake)
- Otorgar a Snowflake acceso al SNS topic
- Habilitar las notificaciones de error en Snowpipe
Para habilitar las notificaciones de error en Snowpipe, puedes usar el comando ALTER PIPE:
1ALTER PIPE mypipe SET ERROR_INTEGRATION = my_notification_int;
Para profundizar en la configuración, revisa nuestros posts anteriores sobre cómo crear notificaciones de error para Snowflake Tasks o nuestro panorama más general sobre alertas en Snowflake.
Costos de Snowflake Snowpipe
Dado que la gestión de costos en Snowflake es una prioridad clave para todos los clientes, conviene entender cómo se factura Snowpipe.
Snowpipe es una funcionalidad serverless, así que no tienes que preocuparte por aprovisionar ni dimensionar el cluster de cómputo para la carga. En Snowflake, cada funcionalidad serverless usa un modelo de Precios distinto al de los virtual warehouses.
Los costos de cómputo de Snowpipe equivalen a 1.25x los costos regulares de cómputo de un virtual warehouse (referencia: Snowflake Credit Consumption Table). Por ejemplo, si Snowflake utiliza el equivalente a un warehouse X-Small para cargar tus datos, se te cobrarán 1.25 créditos en lugar de 1 crédito por hora de cómputo.
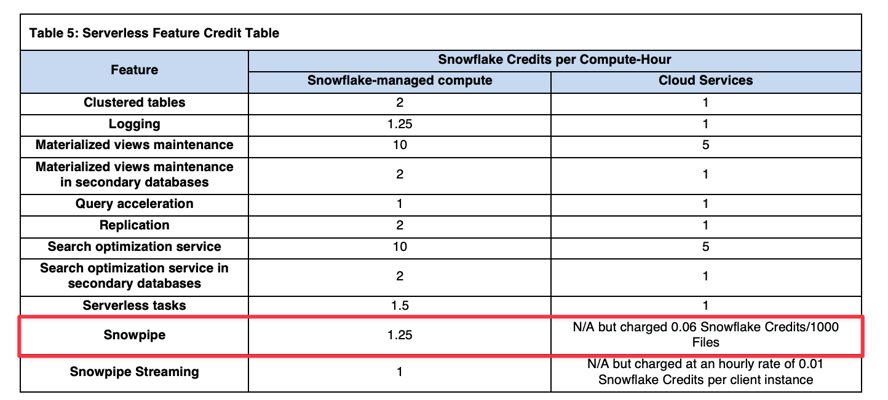
Además de los costos de cómputo administrados por Snowflake, hay un cargo adicional por archivo: 0.06 créditos por cada 1000 archivos cargados. Por eso es muy importante asegurarte de que tus archivos tengan un tamaño óptimo al usar Snowpipe.
Si usas una herramienta como SELECT, podrás detectar fácilmente cuándo hay oportunidades importantes para optimizar los costos de Snowpipe según el tamaño de tus archivos:
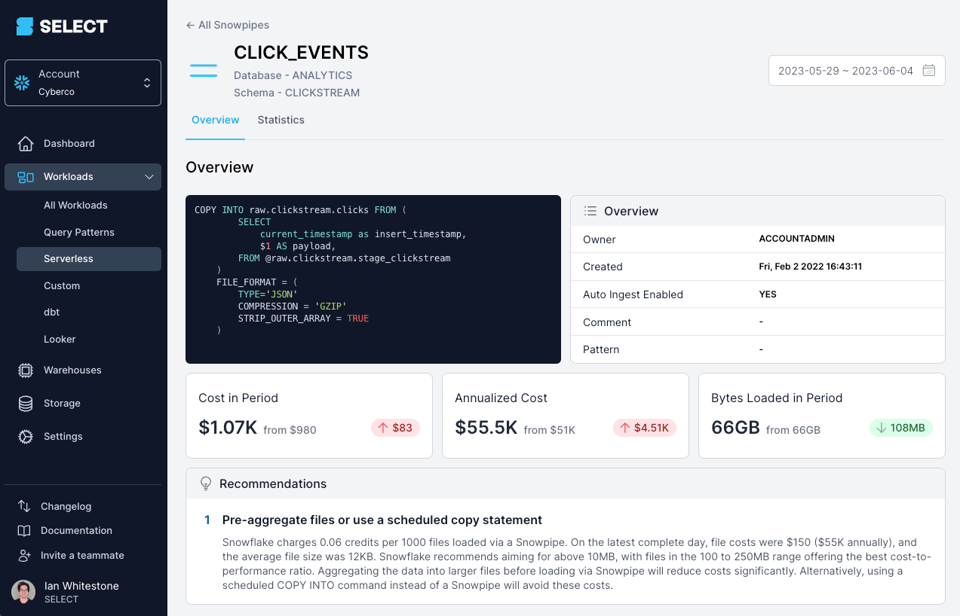
También puedes identificarlo por tu cuenta usando las vistas de metadatos que se comentan más abajo.
¿Cómo monitorear los costos de Snowpipe?
Snowflake guarda metadatos detallados sobre tu uso de Snowpipe. Estos datos te sirven para tener un panorama de los costos. Veamos algunas vistas de ACCOUNT_USAGE con información de Snowpipe. Si quieres obtener detalles de todos tus Snowpipes, puedes usar la vista PIPES con la siguiente consulta:
SELECT
PIPE_ID,
PIPE_NAME AS NAME,
PIPE_SCHEMA_ID AS SCHEMA_ID,
PIPE_SCHEMA AS SCHEMA_NAME,
PIPE_CATALOG_ID AS DATABASE_ID,
PIPE_CATALOG AS DATABASE_NAME,
IS_AUTOINGEST_ENABLED,
NOTIFICATION_CHANNEL_NAME,
PIPE_OWNER,
DEFINITION,
CREATED,
LAST_ALTERED,
COMMENT,
PATTERN,
Expandir código
Esto entrega la lista completa, incluidos los pipes eliminados. Puedes agregar la condición WHERE DELETED IS NULL para obtener solo los pipes que existen actualmente.
Usar la vista de historial de Snowpipe
Para calcular el costo de Snowpipe, puedes usar PIPE_USAGE_HISTORY. Hacen falta cálculos personalizados para incluir los créditos cobrados como cargo adicional por archivo.
SELECT
START_TIME,
PIPE_ID,
COALESCE(PIPE_NAME, 'External table refreshes') AS NAME, -- External table refreshes do not have a pipe name
FILES_INSERTED,
BYTES_INSERTED,
CREDITS_USED AS TOTAL_CREDITS,
0.06 * FILES_INSERTED / 1000 AS FILES_CREDITS, -- 0.06 credits per 1000 files
TOTAL_CREDITS - FILES_CREDITS AS COMPUTE_CREDITS
FROM SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY
ORDER BY START_TIME DESC;
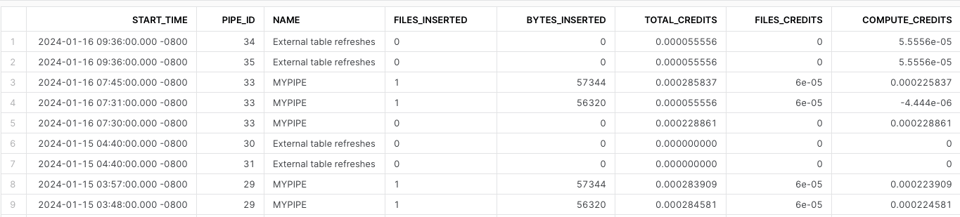
Mejores prácticas para Snowpipe
Repasemos algunas mejores prácticas para usar Snowpipes. Como ya comentamos, el factor más importante es asegurar que tus archivos tengan el tamaño correcto. Snowpipe puede ser muy ineficiente y costoso cuando se ingieren muchos archivos pequeños. Se puede demostrar con un ejemplo sencillo: la carga diaria de 100 GB de datos:
| Tamaño de datos | Tamaño de archivo individual | Número de archivos | Créditos/día (cargo por archivo) | Costo/año (cargo por archivo) |
|---|---|---|---|---|
| 100 GB | 25 KB | 4.2 millones | 251 | $275K |
| 100 GB | 250 MB | 410 | 0.06 | $66 |
Como ves, cargar una enorme cantidad de archivos muy pequeños puede disparar los costos solo por el cargo por archivo. Cuando se dimensionan según la recomendación (100 - 250 MB), el costo anual es insignificante.
Una recomendación similar es usar formatos de archivo comprimidos (por ejemplo, gzip) en lugar de sin comprimir (como CSV). Snowflake rinde mejor con formatos comprimidos y obtienes otros beneficios, como transferir mucho menos volumen de datos por la red y reducir los requisitos de almacenamiento.
También vale la pena implementar filtros en las notificaciones de archivos, de modo que se envíen solo las relativas a los archivos relevantes y no a todo lo que ocurre dentro de tu bucket.
Ventajas y desventajas de Snowpipe
Para cerrar, repasemos los principales beneficios de usar Snowpipe en lugar del comando COPY.
Snowpipe ofrece simplicidad y reduce la carga de administración. Aporta automatización e ingesta de datos en tiempo casi real. Con su modelo serverless, te evita los dolores de cabeza de hacer right-sizing del cluster de cómputo y se adapta mejor a los cambios en el tamaño de los workloads. Para la mayoría de los casos de uso, Snowpipe será mejor opción que el comando COPY. Donde no rinde bien, sobre todo desde el punto de vista del costo, es cuando los archivos no están dimensionados correctamente.
Revisa nuestro post anterior si quieres una comparación más detallada de las distintas opciones de carga de datos en Snowflake.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME en Norlys
Tomas es Snowflake Data SuperHero desde hace años y un experto integral en Snowflake. Su trayectoria en el mundo de los datos supera la década, durante la cual se ha desempeñado como data engineer, arquitecto y admin de Snowflake en proyectos de diversas industrias y tecnologías. Es un miembro activo de la comunidad, donde comparte su experiencia e inspira a otros. También es instructor de O'Reilly y dicta sesiones de capacitación en vivo en línea.