Snowflake Tasks sind ein mächtiges Feature, das häufig für Data Pipelines, administrative Jobs (etwa Backups oder Datenqualitätschecks) und Alerts zum Einsatz kommt. In diesem umfassenden Leitfaden zeige ich alles Wissenswerte rund um Snowflake Tasks – von Setup und Erstellung über die verschiedenen Compute-Modelle bis hin zu Management und Observability.
Was sind Snowflake Tasks?
Mit Snowflake Tasks führen Sie SQL nach Zeitplan aus. Der SQL-Befehl kann alles Mögliche sein: ein einzelnes SQL-Statement oder der Aufruf einer Stored Procedure, die wiederum mehrere SQL-Statements anstößt. Tasks sind in Snowflake First-Class-Objekte – sie haben einen Owner, und Sie steuern den Zugriff über Privilegien, genau wie bei jedem anderen Snowflake-Objekt.
So legen Sie einen Snowflake Task an
Wie andere Snowflake-Objekte lassen sich Tasks programmatisch per SQL anlegen und verwalten. Die wichtigsten Parameter beim Anlegen eines neuen Tasks sind:
schedule: Wann soll der Task ausgelöst werden?warehouse: Welches Compute-Cluster soll genutzt werden?code: der auszuführende SQL-Befehlcondition: ein boolescher Ausdruck, der beim Auslösen des Tasks ausgewertet wird. Er entscheidet, ob der Task ausgeführt oder übersprungen wird, wenn die Bedingung nicht erfüllt ist.
Eine vollständige Übersicht aller Parameter und Einstellungen finden Sie in der zugehörigen Snowflake-Dokumentation.
Beispiel: einen Task anlegen
Einer der zentralen Parameter beim Anlegen eines Tasks ist schedule. Er legt fest, wann der Task ausgelöst wird. Den Zeitplan können Sie auf verschiedene Arten definieren: per CRON-Syntax, über ein Minutenintervall (z. B. alle 5 Minuten) oder so, dass der Task nach einem anderen Task läuft.
Legen wir einen einfachen Task an, der ein Dimensionsmodell mit Fahrradstationen aktualisiert. Wir planen ihn so, dass er jede Nacht um 4 Uhr läuft:
create or replace task t_dim_station
warehouse = compute_wh
schedule = 'USING CRON 0 4 * * * UTC'
as
merge into dim_station t using
(select distinct
start_station_id station_id,
start_station_name station_name,
start_station_latitude station_latitude,
start_station_longitude station_longitude
from raw_trips
union
select distinct
end_station_id station_id,
end_station_name station_name,
Code ausklappen
In diesem Beispiel kommt CRON-Syntax zum Einsatz. Wer mit CRON nicht vertraut ist, tut sich beim Lesen mitunter schwer. Ich empfehle Tools wie crontab, die die passende Syntax samt Erklärung für Sie erzeugen.
Jeder neu angelegte Task startet im Status "suspended" – er ist also nicht eingeplant und muss zuerst aktiviert werden. Das geht so:
1alter task t_dim_station resume;
Bei jeder Änderung an der Task-Definition (etwa über ein alter task-Kommando) wechselt der Task zurück in den Status "suspended" und muss erneut aktiviert werden! Erfahrungsgemäß steckt genau das oft hinter dem Problem, dass Data Pipelines nicht laufen. Prüfen Sie beim Debuggen daher stets, ob der Task aktiv ist. Den Status finden Sie in der Ausgabe von show tasks.
Task-Abhängigkeiten
Tasks lassen sich verketten, um komplexere Data Pipelines aus mehreren Tasks aufzubauen. In der Praxis spricht man dabei oft von "DAGs" – Directed Acyclic Graphs. Ein Beispiel sehen Sie unten.
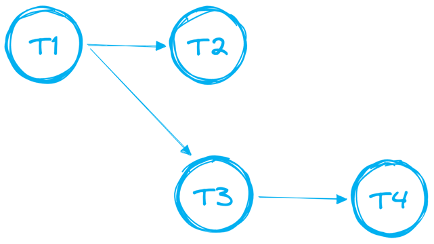
Für DAGs gelten dabei bestimmte Regeln und Grenzen:
- Ein DAG muss genau einen Root-Task haben.
- Es ist nur eine Vorwärtsrichtung erlaubt. Ihr DAG darf keine Schleifen enthalten.
- Ein DAG kann insgesamt bis zu 1000 Tasks umfassen.
- Ein einzelner Task kann bis zu 100 Vorgänger und bis zu 100 Nachfolger haben.
Erweitern wir unsere Pipeline um einen weiteren Task und bauen daraus einen DAG. Unser bisheriger Task t_dim_station aktualisiert die Dimensionstabelle aus einer Rohdatentabelle. Wir ergänzen einen Vorgänger-Task, der die Rohdatentabelle aus einem External Stage befüllt. Außerdem passen wir den Zeitplan an: Statt 4 Uhr UTC nutzen wir eine AFTER-Bedingung, sodass der Task ausgelöst wird, sobald der Vorgänger erfolgreich abgeschlossen ist.
Zuerst definieren wir den neuen Vorgänger-Task t_raw_trips:
create task t_raw_trips
warehouse = compute_wh
schedule = 'using cron 0 4 * * * utc'
as
copy into raw_trips from @s3_source_data
on_error = skip_file
Jetzt passen wir unseren ursprünglichen Task an. Zunächst entfernen wir den Parameter SCHEDULE und ergänzen anschließend die AFTER-Bedingung.
alter task t_dim_station unset schedule;
alter task t_dim_station add after t_raw_trips;
Damit haben wir einen DAG aus zwei Tasks gebildet, bei dem t_raw_trips der "Root-Task" ist.
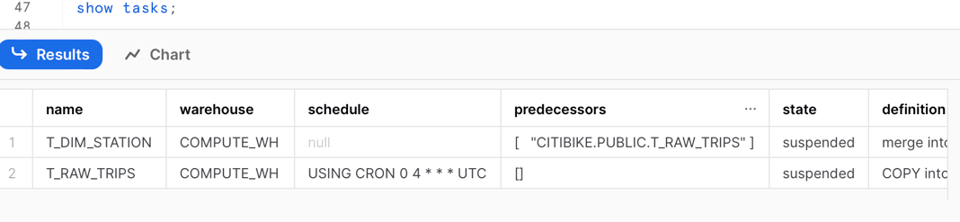
Führen wir show task erneut aus, fallen folgende Änderungen auf:
- Der ursprüngliche Task hat keinen Zeitplan mehr.
- Der ursprüngliche Task hat nun einen Vorgänger-Task.
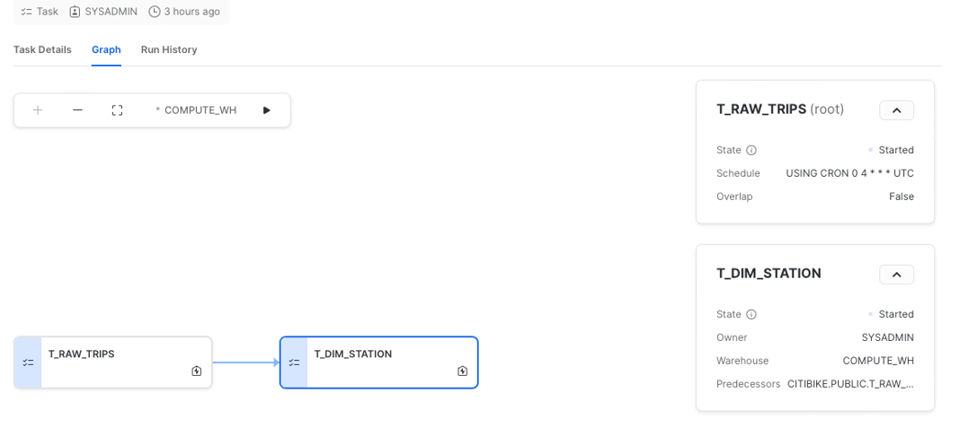
Snowflake bietet zudem eine sehr gute UI für die Arbeit mit Tasks – besonders mit DAGs. Im Tab "Graph" visualisieren Sie die gesamte Pipeline, springen in Task-Details oder sehen sich die Run-Historie an.
Compute-Modelle für Tasks
Selbstverwaltete Warehouses
Beide Beispiel-Tasks von oben waren so konfiguriert, dass sie auf einem selbstverwalteten Warehouse laufen, COMPUTE_WH. Die von den Tasks ausgeführten SQL-Befehle laufen also auf unserem eigenen COMPUTE_WH, und wir kümmern uns selbst um den Betrieb dieses Warehouses (passende Größe, Cluster-Anzahl, Auto-Suspend usw.).
Eine Alternative dazu sind Serverless Tasks.
Serverless Tasks
Statt auf einem Ihrer eigenen Virtual Warehouses laufen Serverless Tasks auf Compute-Ressourcen, die Snowflake bereitstellt. Um einen Serverless Task zu erstellen, lassen Sie beim Anlegen einfach den Parameter warehouse weg.
Ein Vorteil von Serverless Tasks: Snowflake ermittelt automatisch die optimale Warehouse-Größe für den Task. Der Parameter USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE legt fest, welche Warehouse-Größe für den ersten Task-Lauf verwendet wird. Nach einigen Läufen ignoriert Snowflake diesen Parameter und wählt die Größe anhand der Erkenntnisse aus erfolgreich abgeschlossenen Läufen. Snowflake lernt mit der Zeit, welche Warehouse-Größe für einen bestimmten Task am besten passt, und passt sie dynamisch an.
Wenn ein bestehender Task auf einem Ihrer eigenen Warehouses läuft, können Sie ihn per ALTER TASK-Statement in einen Serverless Task umwandeln:
1alter task t_dim_station unset warehouse;
Wann Serverless Tasks, wann ein verwaltetes Warehouse?
Laut Snowflake Credit Consumption Table kosten Serverless Tasks das 1,5-Fache von Tasks, die auf Ihrem eigenen verwalteten Warehouse laufen.
Eine kurze Rechnung zeigt: Serverless lohnt sich für Tasks, die weniger als 40 Sekunden brauchen. Darüber hinaus ist die Variante mit verwaltetem Warehouse günstiger.
Serverless Tasks haben den Vorteil, automatisch die passende Menge an Compute-Ressourcen zu wählen. Das kann sich in Sachen Kosten und Performance auszahlen, wenn Sie ansonsten eine zu kleine Warehouse-Größe gewählt hätten.
Tasks managen
Beim Management von Snowflake Tasks gibt es mehrere Aspekte, die Sie im Blick behalten sollten:
- Wie oft läuft der Task?
- Wie lange dauert ein Lauf?
- Wie oft schlägt er fehl?
- Können wir Alerts auslösen, wenn Tasks fehlschlagen?
Mit der Snowflake-UI arbeiten
Sehen wir uns an, wie Sie Tasks über die Snowflake-UI managen.
Um Ihre Tasks zu finden, navigieren Sie zur Datenbank und zum Schema, in denen Sie sie angelegt haben.
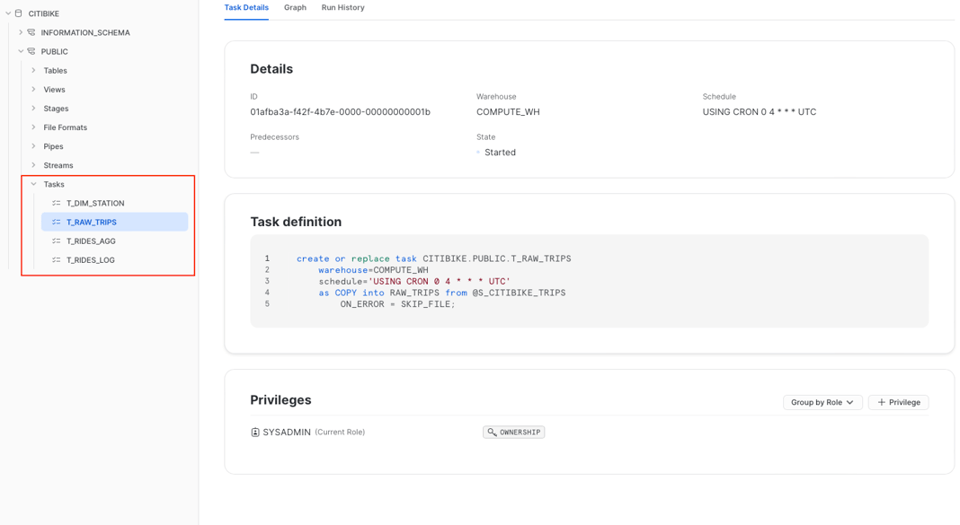
Der Tab "Details" gibt Ihnen einen Überblick über den gesamten Task. Sie sehen die Definition mitsamt den wichtigsten Parametern wie zugewiesenem Warehouse, Schedule und vergebenen Privilegien. Der Tab "Graph" liefert anschließend die Gesamtsicht auf den DAG, wie oben gezeigt.
Möchten Sie die Run-Historie prüfen, öffnen Sie den Tab "Run History".
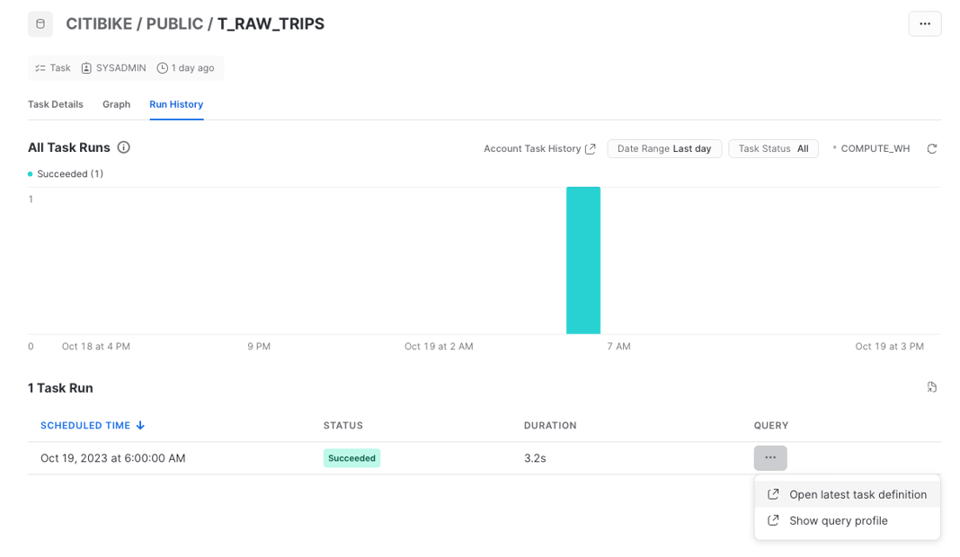
Die Task-Historie wird als Balkendiagramm mit der Anzahl der Läufe im Zeitverlauf dargestellt. Die einzelnen Läufe finden Sie in der Tabelle darunter. Beachten Sie: Diese Seite enthält nur Daten der letzten 7 Tage.
Wollen Sie Tasks accountweit verstehen und überwachen, navigieren Sie zu Activity -> Task History.
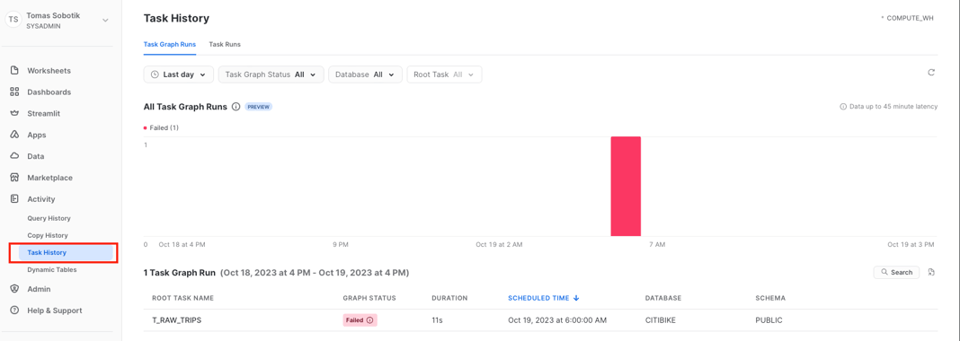
Von hier aus öffnen Sie einzelne Graph-Runs und prüfen den Status jedes Tasks und jedes Laufs. Diese accountweite Graph-History-UI befindet sich derzeit in der Public Preview.

Tasks programmatisch überwachen
Wer lieber per Code als über die Snowflake-UI arbeitet oder eine eigene Visualisierung rund um Tasks bauen möchte, findet bei Snowflake mehrere Views mit Daten zu Task-Läufen, Status und mehr. Schauen wir uns ein paar Beispiele an.
Den Befehl show tasks haben wir bereits genutzt – er liefert einen Basisüberblick über die Tasks in Ihrem Account, etwa Status, Definition, Vorgänger, Warehouse und vieles mehr.
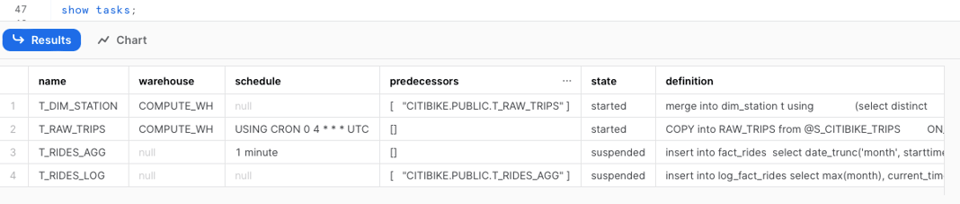
Wenn Sie die Task-Historie per SQL auswerten möchten, stehen Ihnen zwei Wege offen: die Tabellenfunktion TASK_HISTORY() aus dem INFORMATION_SCHEMA oder die View TASK_HISTORY aus ACCOUNT_USAGE in der Datenbank SNOWFLAKE.
Die Tabellenfunktion liefert die Task-Läufe der letzten 7 Tage und arbeitet ohne Latenz – damit ist sie eine perfekte Quelle für ein eigenes Monitoring laufender Ausführungen. Die View in ACCOUNT_USAGE hat dagegen eine Latenz von bis zu 45 Minuten und enthält Daten bis zu 365 Tage zurück. Sie eignet sich daher besser für historische Auswertungen als für die Beobachtung aktueller Läufe.
Hier ein Beispiel-Query mit der Task-History-Tabellenfunktion aus dem Information Schema, das alle Tasks ausgibt, die im angegebenen Zeitraum fehlgeschlagen sind.
select *
from table(information_schema.task_history(
scheduled_time_range_start=>to_timestamp_ltz('2023-10-18 00:00:00.000'),
error_only => TRUE
))
order by scheduled_time desc

Im Ergebnis finden Sie Informationen zum Fehler sowie die zugehörige query_id. Bei Bedarf können Sie in die Query History-Details oder ins Query Profile springen, um mehr über den Fehler zu erfahren. Ohne Parameter aufgerufen, liefert die Tabellenfunktion alle Task-Ausführungen der letzten 7 Tage einschließlich der geplanten Läufe.
select *
from table(information_schema.task_history())
order by scheduled_time desc

Dieser Ansatz funktioniert gut, wenn Ihr Task nur ein einzelnes SQL-Statement auslöst. Was aber, wenn Ihr Task eine Stored Procedure ausführt, die wiederum mehrere Statements anstößt? Wie identifiziert man alle zugehörigen Statements?
Dafür greifen wir auf das Attribut SESSION_ID in der View QUERY_HISTORY zurück. Alle von einer Stored Procedure ausgelösten Queries laufen mit hoher Wahrscheinlichkeit innerhalb derselben Session. Sie müssen also zunächst TASK_HISTORY() und QUERY_HISTORY kombinieren, um die SESSION_ID des Stored-Procedure-Aufrufs zu ermitteln:
select
b.session_id,
a.name,
a.query_text,
a.query_start_time,
a.completed_time
from table(information_schema.task_history(task_name => 't_dim_station')) t
inner join snowflake.account_usage.query_history q
on t.query_id = q.query_id

Anschließend führen Sie eine weitere Query aus, um alle Queries mit derselben SESSION_ID zu finden.
select *
from query_history
where session_id = <<session id from previous step>>
and start_time >= '<<task start time>>'
and start_time <= '<<task end time>>';
Alerts bei Task-Fehlern erhalten
Automatische Benachrichtigungen bei fehlgeschlagenen Tasks sind für die meisten Task-Deployments ein Muss.
Snowflake bietet rund um Alerting und Notifications verschiedene Features, die sich auch für Tasks nutzen lassen. Diese Optionen habe ich in separaten Blogposts ausführlich behandelt – die Links finden Sie hier:
Grenzen von Tasks
Einige Einschränkungen rund um Tasks haben wir bereits im Abschnitt zu DAGs angesprochen. Hier eine Zusammenfassung aller Grenzen:
- Ein Task kann ein einzelnes SQL-Statement oder einen Stored-Procedure-Aufruf ausführen.
- Ein einzelner Task kann bis zu 100 Vorgänger haben.
- Ein einzelner Task kann bis zu 100 Nachfolger haben.
- Ein DAG kann bis zu 1000 Tasks umfassen.
- Ein DAG benötigt genau einen Root-Task.
- DAGs unterstützen keine Schleifen.
- Tasks lassen sich nicht über die Data-Sharing-Funktionen von Snowflake teilen.
Wie werden Tasks abgerechnet?
Für die Nutzung von Tasks fallen keine zusätzlichen Gebühren oder Overhead-Kosten an. Abgerechnet werden ausschließlich die Compute-Ressourcen, die für die Ausführung der SQL-Statements eines Tasks anfallen. Laufen Ihre Tasks auf Ihren eigenen verwalteten Warehouses, werden diese Compute-Ressourcen genauso abgerechnet wie reguläre SQL-Queries auf einem Warehouse. Bei Serverless Tasks zahlen Sie für die von Snowflake verwalteten Compute-Ressourcen. Zur Erinnerung: Serverless-Task-Compute ist 1,5-mal teurer als die entsprechenden Compute-Kosten auf Ihren eigenen Virtual Warehouses.
Kosten von Serverless Tasks überwachen
Die Kosten von Serverless Tasks lassen sich über die View serverless_task_history aus dem Schema account_usage überwachen. Hier ein Beispiel-Query:
select
start_time,
end_time,
task_name,
credits_used
from snowflake.account_usage.serverless_task_history
where
start_time > current_date - 30
order by start_time desc
Tomáš Sobotík · Senior Data Engineer & Snowflake SME bei Norlys
Tomas ist langjähriger Snowflake Data SuperHero und ein ausgewiesener Snowflake-Experte. Seine Erfahrung in der Datenwelt umfasst über ein Jahrzehnt, in dem er als Snowflake Data Engineer, Architect und Admin in zahlreichen Projekten unterschiedlicher Branchen und Technologien tätig war. Tomas ist ein zentrales Community-Mitglied, teilt sein Wissen aktiv und inspiriert andere. Außerdem ist er O'Reilly-Instructor und leitet Live-Online-Trainings.