Gli Snowflake Tasks sono una funzionalità potente, comunemente utilizzata per le data pipeline o per orchestrare job amministrativi (backup, controlli di qualità dei dati) e alert. In questa guida definitiva trovate tutto quello che serve sapere sugli Snowflake Tasks: dalla configurazione e creazione, ai diversi modelli di compute, fino alla gestione e all'osservabilità.
Cosa sono gli Snowflake Tasks
Gli Snowflake Tasks consentono di eseguire SQL secondo una pianificazione. Il comando SQL può essere qualsiasi: una singola istruzione SQL oppure la chiamata di una stored procedure che a sua volta richiama più istruzioni SQL. I Tasks sono oggetti di prima classe in Snowflake: hanno un proprietario e l'accesso si controlla concedendo privilegi, esattamente come per qualunque altro oggetto Snowflake.
Come creare uno Snowflake Task
Come per gli altri oggetti Snowflake, i Tasks si creano e si gestiscono in modo programmatico tramite SQL. I parametri più comuni nella creazione di un nuovo task sono:
schedule: quando il task deve essere attivatowarehouse: quale cluster di compute utilizzarecode: il comando SQL da eseguirecondition: un'espressione booleana valutata all'attivazione del Task. Stabilisce se il Task verrà eseguito o saltato qualora la condizione non sia soddisfatta.
Per l'elenco completo dei parametri e delle impostazioni dei tasks, consultate la documentazione Snowflake.
Esempio di creazione di un Task
Uno dei parametri chiave da definire quando si crea un Task è schedule, che stabilisce quando il Task verrà attivato. La pianificazione si può definire in vari modi: con la sintassi CRON, indicando un intervallo in minuti (ad esempio ogni 5 minuti), oppure specificando che il Task deve essere eseguito dopo un altro Task.
Creiamo un semplice Task per aggiornare un modello dimensionale contenente delle stazioni di bike sharing. Lo pianifichiamo per essere eseguito ogni notte alle 4:
create or replace task t_dim_station
warehouse = compute_wh
schedule = 'USING CRON 0 4 * * * UTC'
as
merge into dim_station t using
(select distinct
start_station_id station_id,
start_station_name station_name,
start_station_latitude station_latitude,
start_station_longitude station_longitude
from raw_trips
union
select distinct
end_station_id station_id,
end_station_name station_name,
Espandi codice
Questo esempio usa la sintassi CRON per la pianificazione. Leggere la sintassi CRON può non essere immediato se non ci si è abituati: consiglio di utilizzare siti come crontab, che generano la sintassi corretta accompagnata da una spiegazione.
Ogni nuovo task viene creato in stato sospeso: significa che non è pianificato e va prima riattivato. Lo si può fare con il seguente comando:
1alter task t_dim_station resume;
Ogni volta che si modifica la definizione del Task (ad esempio con un comando alter task), questo torna in stato sospeso e deve essere riattivato! Per esperienza, è spesso la causa principale dei problemi di data pipeline che non partono. Quando fate il debug dei Tasks, verificate sempre che il Task sia attivo. Lo stato è disponibile nell'output del comando show tasks.
Dipendenze tra Tasks
I Tasks possono essere concatenati per costruire data pipeline più complesse formate da più task. In ambito dati, queste catene di dipendenze sono spesso chiamate "DAG" — Directed Acyclic Graphs (grafi aciclici diretti). Di seguito un esempio.
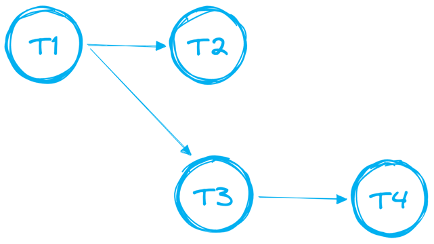
Per i DAG valgono alcune regole e limitazioni:
- Il DAG deve avere un unico task radice
- È supportata una sola direzione in avanti: il DAG non può contenere cicli.
- Un singolo DAG può contenere fino a 1000 Tasks in totale
- Un singolo Task può avere fino a 100 predecessori e fino a 100 task figli
Aggiungiamo un altro task alla nostra pipeline e creiamo un DAG. Il task attuale t_dim_station aggiorna la tabella dimensionale a partire da una tabella raw. Aggiungeremo un task predecessore che popolerà la tabella raw da uno stage esterno. Modificheremo anche la pianificazione: invece di eseguirlo alle 4 UTC, aggiungeremo una condizione AFTER, in modo che il Task venga attivato non appena il predecessore termina con successo.
Definiamo innanzitutto il nuovo Task predecessore t_raw_trips:
create task t_raw_trips
warehouse = compute_wh
schedule = 'using cron 0 4 * * * utc'
as
copy into raw_trips from @s3_source_data
on_error = skip_file
Ora dobbiamo modificare il task iniziale: prima rimuoviamo il parametro SCHEDULE, poi aggiungiamo la condizione AFTER.
alter task t_dim_station unset schedule;
alter task t_dim_station add after t_raw_trips;
Abbiamo così formato un DAG composto da due Tasks, in cui t_raw_trips è il "task radice".
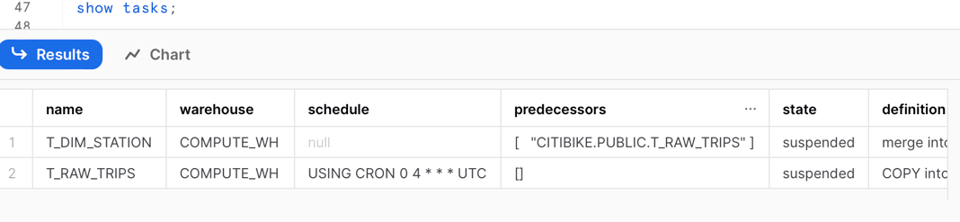
Eseguendo nuovamente il comando show task possiamo notare le seguenti modifiche:
- Il task originale non ha più una pianificazione
- Il task originale ha ora un task predecessore
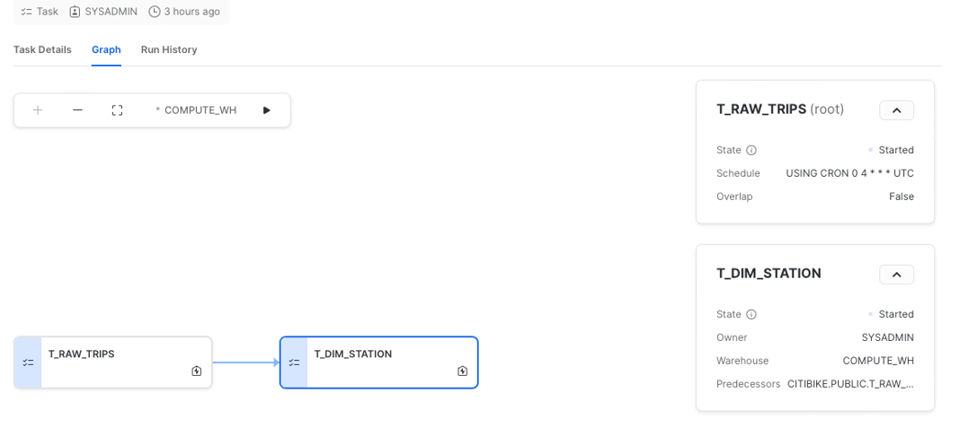
Snowflake mette a disposizione anche un'ottima UI per lavorare con i task, in particolare con i DAG. Dalla scheda "Graph" si può visualizzare l'intera pipeline, accedere ai dettagli del task o consultare lo storico delle esecuzioni.
Modelli di compute per i Tasks
Warehouse gestiti dall'utente
Entrambi i Tasks di esempio visti sopra erano configurati per essere eseguiti su un warehouse gestito dall'utente, COMPUTE_WH. Significa che i comandi SQL eseguiti dai Tasks gireranno sul nostro COMPUTE_WH, e siamo noi a doverlo gestire (scelta della dimensione, numero di cluster, auto-suspend, ecc.).
Un approccio alternativo consiste nell'utilizzare i Serverless Tasks.
Serverless Tasks
Anziché girare su uno dei vostri virtual warehouse, i Serverless Tasks vengono eseguiti su risorse di compute fornite da Snowflake. Per creare un Task serverless basta omettere il parametro warehouse in fase di creazione.
Un vantaggio dei Serverless Tasks è che Snowflake determina automaticamente la dimensione ottimale del warehouse su cui eseguire il Task. Il parametro USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE definisce la dimensione iniziale del warehouse per la prima esecuzione del Task. Dopo qualche esecuzione, Snowflake ignora questo parametro e assegna il warehouse in base alle informazioni ricavate dalle esecuzioni completate con successo. Con il tempo impara qual è la dimensione di warehouse più adatta a un determinato task e la adatta dinamicamente alle esigenze.
Se avete già un Task in esecuzione su uno dei vostri warehouse, potete convertirlo in Serverless Task con l'istruzione ALTER TASK:
1alter task t_dim_station unset warehouse;
Quando conviene usare i Serverless Tasks rispetto a un warehouse gestito?
Secondo la Snowflake Credit Consumption Table, i Serverless Tasks costano 1,5 volte i Tasks eseguiti su un warehouse gestito dall'utente.
Facendo due conti, l'opzione serverless risulta più conveniente per i Tasks che durano meno di 40 secondi. Oltre tale soglia, è più economico usare un warehouse gestito.
I Serverless Tasks hanno il vantaggio di scegliere automaticamente la giusta quantità di risorse di compute per il vostro Task, con possibili benefici in termini di costi e performance qualora abbiate scelto una dimensione di warehouse troppo piccola.
Gestione dei Tasks
Quando si gestiscono gli Snowflake Tasks, ci sono diversi aspetti da tenere sotto controllo:
- Con quale frequenza viene eseguito il task?
- Quanto dura l'esecuzione?
- Con quale frequenza fallisce?
- Possiamo attivare alert quando i Tasks falliscono?
Utilizzo della UI di Snowflake
Vediamo come usare la UI di Snowflake per gestire i Tasks.
Per trovare i vostri Tasks, spostatevi nel database e nello schema in cui li avete creati.
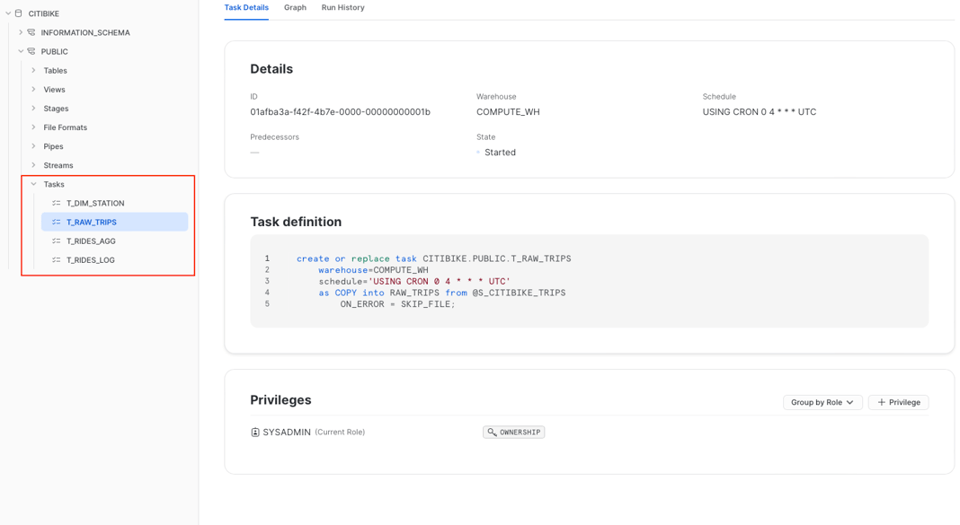
La scheda "Details" del Task offre una panoramica completa: la definizione e i parametri chiave come warehouse assegnato, pianificazione e privilegi concessi. La scheda "Graph" mostra invece la visualizzazione complessiva del DAG, come visto in precedenza.
Per consultare lo storico delle esecuzioni si apre la scheda "Run History".
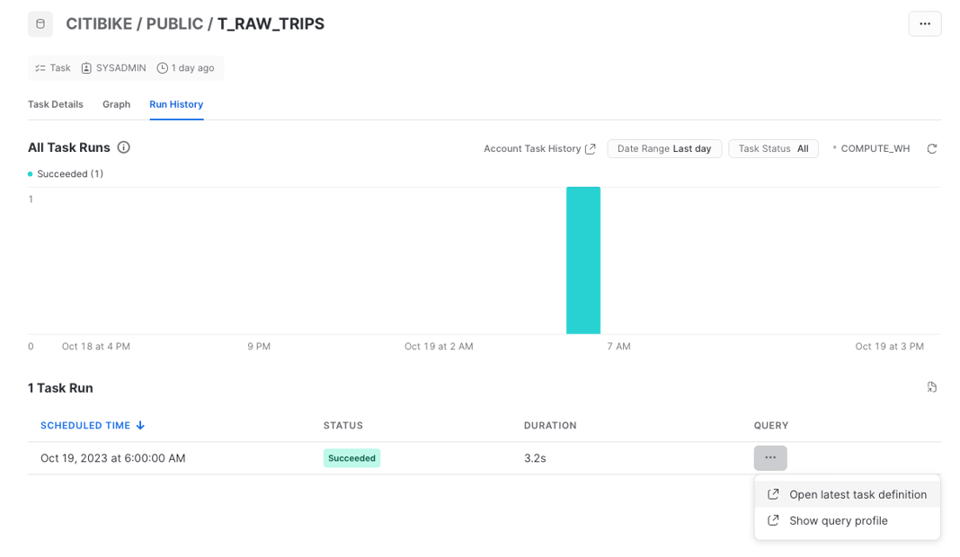
Lo storico del Task è rappresentato da un grafico a barre con il numero di esecuzioni nel tempo. Le singole esecuzioni sono elencate nella tabella sottostante. Attenzione: questa pagina contiene solo i dati delle esecuzioni degli ultimi 7 giorni.
Per analizzare e monitorare i Tasks sull'intero account, andate in Activity -> Task History.
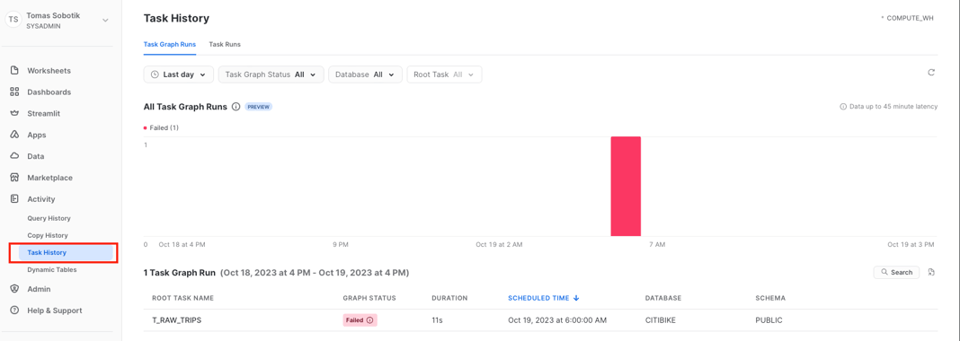
Da qui si possono aprire le esecuzioni dei singoli grafi e verificare lo stato di ciascun Task e di ciascuna esecuzione. La UI dello storico dei grafi a livello di account è al momento in Public Preview.

Monitoraggio programmatico dei Tasks
Per chi preferisce il codice alla UI di Snowflake, o vuole costruire le proprie visualizzazioni sui Tasks, Snowflake mette a disposizione diverse view che forniscono dati su esecuzioni, stati e altro ancora. Vediamo qualche esempio.
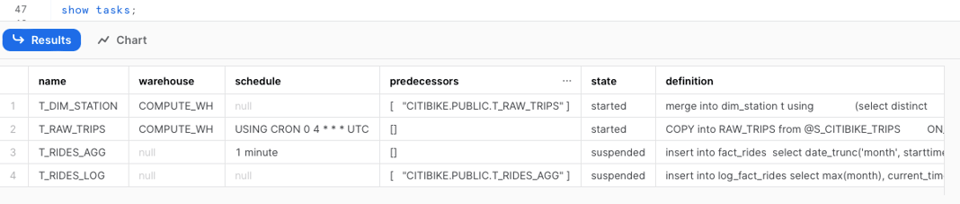
Abbiamo già usato il comando show tasks, che offre una panoramica di base dei Tasks presenti nel vostro account: stato, definizione, predecessori, warehouse e molto altro.
Per consultare lo storico dei task via SQL si può utilizzare la table function TASK_HISTORY() dell'INFORMATION_SCHEMA oppure la view TASK_HISTORY in ACCOUNT_USAGE, all'interno del database SNOWFLAKE.
La table function restituisce le esecuzioni dei task degli ultimi 7 giorni senza alcuna latenza, il che la rende una fonte ideale per il monitoraggio personalizzato delle esecuzioni reali. La view in ACCOUNT_USAGE, invece, ha una latenza fino a 45 minuti e contiene dati fino a 365 giorni indietro: è quindi più adatta all'analisi storica delle esecuzioni dei Tasks che non all'esplorazione di quelle correnti.
Ecco una query di esempio che utilizza la table function dello storico Task dell'information schema per mostrare tutti i Tasks falliti nell'intervallo indicato.
select *
from table(information_schema.task_history(
scheduled_time_range_start=>to_timestamp_ltz('2023-10-18 00:00:00.000'),
error_only => TRUE
))
order by scheduled_time desc

Come si vede, l'output include le informazioni sull'errore insieme al query_id. All'occorrenza si può accedere ai dettagli della Query History o al query profile per approfondire il fallimento. Interrogando la table function senza parametri si ottengono tutte le esecuzioni dei task degli ultimi 7 giorni, comprese quelle pianificate.
select *
from table(information_schema.task_history())
order by scheduled_time desc

Questo approccio funziona bene quando il Task lancia una singola istruzione SQL. Ma se il Task esegue una stored procedure che a sua volta innesca più istruzioni? Come si fa a identificare tutte le istruzioni collegate?
Per riuscirci, dobbiamo sfruttare l'attributo SESSION_ID della view QUERY_HISTORY. Tutte le query attivate da una stored procedure verranno, con tutta probabilità, eseguite nella stessa sessione. Occorre quindi combinare prima TASK_HISTORY() e QUERY_HISTORY per individuare il SESSION_ID della chiamata alla stored procedure:
select
b.session_id,
a.name,
a.query_text,
a.query_start_time,
a.completed_time
from table(information_schema.task_history(task_name => 't_dim_station')) t
inner join snowflake.account_usage.query_history q
on t.query_id = q.query_id

A quel punto si può lanciare un'altra query per trovare tutte le query con lo stesso SESSION_ID.
select *
from query_history
where session_id = <<session id from previous step>>
and start_time >= '<<task start time>>'
and start_time <= '<<task end time>>';
Ricevere alert sui fallimenti dei Tasks
Essere notificati automaticamente quando un Task fallisce è un requisito imprescindibile nella maggior parte degli scenari di utilizzo dei Task.
Snowflake offre diverse funzionalità di alerting e notifica utilizzabili con i Tasks. Ho dedicato dei blog specifici per approfondire queste opzioni. Li trovate qui sotto:
Limitazioni dei Tasks
Abbiamo già accennato ad alcune limitazioni dei Tasks parlando dei DAG. Ecco un riepilogo di tutte le limitazioni:
- Un Task può eseguire una singola istruzione SQL o la chiamata di una stored procedure
- Un singolo task può avere fino a 100 predecessori
- Un singolo task può avere fino a 100 task figli
- Un singolo DAG può contenere fino a 1000 tasks
- Un DAG deve avere un unico task radice
- I DAG non supportano cicli
- I Task non possono essere condivisi tramite le funzionalità di data sharing di Snowflake
Come vengono fatturati i Tasks
Non sono previsti costi aggiuntivi né oneri di overhead per l'utilizzo dei Tasks. Si pagano soltanto le risorse di compute associate all'esecuzione delle istruzioni SQL di ciascun Task. Se i task girano sui vostri warehouse gestiti, le risorse di compute vengono fatturate esattamente come per le normali query SQL eseguite su un warehouse. Se utilizzate i Serverless Tasks, vengono fatturate le risorse di compute gestite da Snowflake. Ricordiamo che il compute dei Serverless Tasks costa 1,5 volte rispetto all'equivalente compute sui propri virtual warehouse.
Monitorare i costi dei Serverless Task
I costi dei Serverless Task si possono monitorare tramite la view serverless_task_history dello schema account_usage. Ecco una query di esempio:
select
start_time,
end_time,
task_name,
credits_used
from snowflake.account_usage.serverless_task_history
where
start_time > current_date - 30
order by start_time desc
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è da anni uno Snowflake Data SuperHero e un esperto a tutto tondo di Snowflake. La sua esperienza nel mondo dei dati copre oltre un decennio, durante il quale ha lavorato come Snowflake data engineer, architect e admin in progetti che hanno spaziato tra settori e tecnologie diverse. Tomas è un membro attivo della community, dove condivide la propria expertise e ispira gli altri. È inoltre istruttore O'Reilly e tiene sessioni di formazione live online.