Snowflake Tasks são um recurso poderoso, muito usado em pipelines de dados ou para orquestrar rotinas administrativas (como backups e checagens de qualidade) e alertas. Neste guia definitivo, eu cubro tudo o que você precisa saber sobre Snowflake Tasks: da configuração e criação aos diferentes modelos de computação, além de gerenciamento e observabilidade.
O que são Snowflake Tasks
As Snowflake Tasks permitem executar SQL de forma agendada. O comando SQL pode ser qualquer coisa: uma única instrução ou uma chamada a uma stored procedure que dispara várias instruções SQL. As Tasks são cidadãs de primeira classe no Snowflake — ou seja, têm um proprietário e você controla o acesso concedendo privilégios, como em qualquer outro objeto do Snowflake.
Como criar uma Snowflake Task
Assim como outros objetos do Snowflake, as Tasks podem ser criadas e gerenciadas via SQL. Os parâmetros mais comuns ao criar uma nova task são:
schedule: quando a task deve ser disparadawarehouse: qual cluster de computação será usadocode: o comando SQL a ser executadocondition: uma expressão booleana avaliada no momento em que a Task é disparada. Ela define se a Task será executada ou ignorada caso a condição não seja atendida.
Para a lista completa de parâmetros e configurações das tasks, consulte a documentação do Snowflake.
Exemplo de criação de Task
Um dos principais parâmetros que você precisa definir ao criar uma Task é o schedule. Ele determina quando a Task será disparada. Dá pra definir o agendamento de várias formas: usando a sintaxe CRON, definindo um intervalo em minutos (por exemplo, rodar a cada 5 minutos) ou indicando que a Task será executada após outra Task.
Vamos criar uma Task simples para atualizar um modelo dimensional com estações de bicicletas. Vamos agendá-la para rodar todas as madrugadas às 4h:
create or replace task t_dim_station
warehouse = compute_wh
schedule = 'USING CRON 0 4 * * * UTC'
as
merge into dim_station t using
(select distinct
start_station_id station_id,
start_station_name station_name,
start_station_latitude station_latitude,
start_station_longitude station_longitude
from raw_trips
union
select distinct
end_station_id station_id,
end_station_name station_name,
Expandir código
Este exemplo usa a sintaxe CRON para agendar a Task. Pode ser meio complicado ler a sintaxe CRON se você não estiver acostumado. Recomendo sites como o crontab, que geram a sintaxe correta junto com uma explicação.
Toda task criada começa em estado suspenso, ou seja, não fica agendada — você precisa retomá-la primeiro. Isso pode ser feito com o seguinte comando:
1alter task t_dim_station resume;
Sempre que você faz alguma alteração na definição da Task (ou seja, roda um comando alter task), ela volta ao estado suspenso e precisa ser retomada! Pela minha experiência, essa é uma das causas mais comuns de pipelines de dados que param de rodar. Ao depurar Tasks, sempre verifique se a Task está ativa. Você consegue ver o estado da Task na saída do comando show tasks.
Dependências entre Tasks
As Tasks podem ser encadeadas para montar pipelines de dados mais complexos, com várias tasks. O pessoal de dados costuma chamar essa cadeia de dependências de "DAGs" — Directed Acyclic Graphs (Grafos Acíclicos Direcionados). Veja um exemplo abaixo.
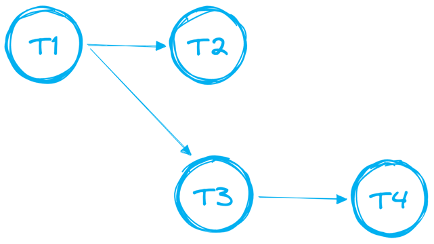
No caso dos DAGs, há algumas regras e limitações a seguir:
- O DAG precisa ter uma única task raiz
- Só há suporte a uma única direção, para frente. Seu DAG não pode ter loops.
- Um único DAG pode ter até 1000 Tasks no total
- Uma única Task pode ter até 100 predecessoras e até 100 tasks filhas
Vamos adicionar mais uma task ao nosso pipeline e formar um DAG. A task atual t_dim_station atualiza a tabela de dimensão a partir de uma tabela raw. Vamos adicionar uma task predecessora que vai popular a tabela raw a partir de um external stage. Também vamos mudar o agendamento dela: em vez de rodar às 4h UTC, vamos usar uma condição AFTER para que a Task seja disparada assim que a Task predecessora terminar com sucesso.
Primeiro, vamos definir a nova Task predecessora t_raw_trips:
create task t_raw_trips
warehouse = compute_wh
schedule = 'using cron 0 4 * * * utc'
as
copy into raw_trips from @s3_source_data
on_error = skip_file
Agora precisamos ajustar a task original. Primeiro removemos o parâmetro SCHEDULE e, depois, adicionamos a condição AFTER.
alter task t_dim_station unset schedule;
alter task t_dim_station add after t_raw_trips;
Pronto: agora temos um DAG formado por duas Tasks, em que t_raw_trips é a "task raiz".
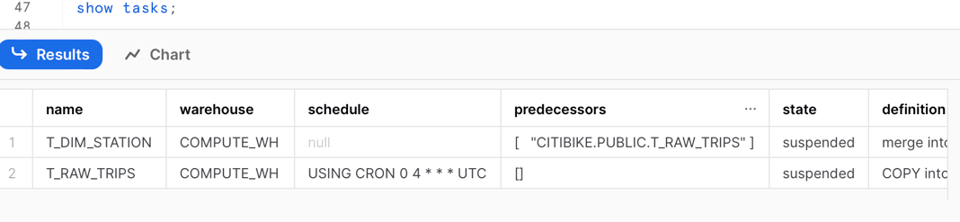
Rodando o comando show task de novo, dá pra notar as seguintes mudanças:
- A task original agora não tem agendamento
- A task original agora tem uma task predecessora
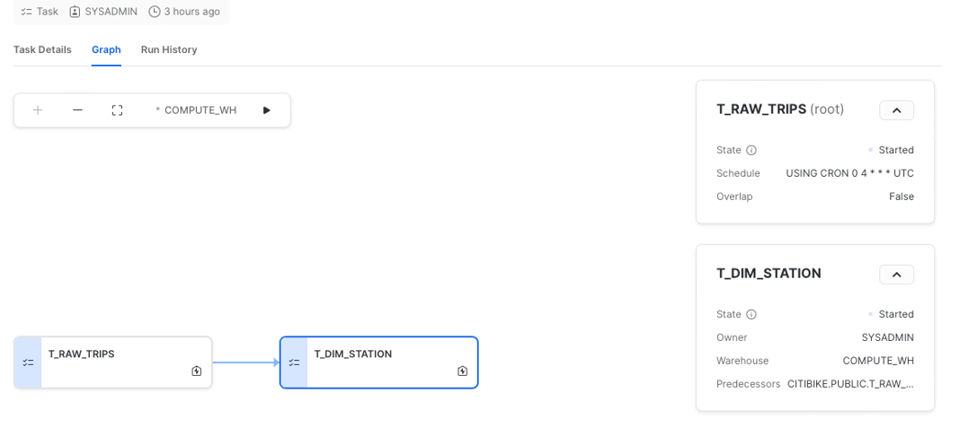
O Snowflake também oferece uma ótima UI para trabalhar com tasks, principalmente DAGs. Você consegue visualizar o pipeline inteiro pela aba "Graph", acessar os detalhes da task ou consultar o histórico de execuções.
Modelos de computação das Tasks
Warehouses autogerenciados
As duas Tasks de exemplo acima foram configuradas para rodar em um warehouse autogerenciado, o COMPUTE_WH. Isso significa que os comandos SQL executados pelas Tasks rodam no nosso próprio COMPUTE_WH, e somos nós que cuidamos desse warehouse (escolhendo o tamanho certo, a quantidade de clusters, o auto-suspend etc.).
Uma alternativa é usar Serverless Tasks.
Serverless Tasks
Em vez de rodar em um dos seus próprios virtual warehouses, as Serverless Tasks rodam em recursos de computação fornecidos pelo Snowflake. Para criar uma Task serverless, basta omitir o parâmetro warehouse ao criar a task.
Uma vantagem das Serverless Tasks é que o Snowflake determina automaticamente o tamanho ideal do warehouse para rodar a Task. Existe um parâmetro chamado USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE que define o tamanho inicial do warehouse na primeira execução. Após algumas execuções, o Snowflake ignora esse parâmetro e passa a definir o tamanho com base nos aprendizados das execuções bem-sucedidas. Ele aprende com o tempo qual é o melhor tamanho de warehouse para cada task e ajusta dinamicamente conforme necessário.
Se você já tem uma Task rodando em um dos seus próprios warehouses, dá para convertê-la em Serverless Task com o comando ALTER TASK:
1alter task t_dim_station unset warehouse;
Quando usar Serverless Tasks em vez de um warehouse gerenciado?
Segundo a Tabela de Consumo de Créditos do Snowflake, as Serverless Tasks custam 1,5x mais do que as Tasks rodando no seu próprio warehouse gerenciado.
Fazendo as contas, dá pra concluir que a opção serverless compensa para Tasks que levam menos de 40 segundos para rodar. Acima disso, é mais econômico usar a opção de warehouse gerenciado.
As Serverless Tasks têm a vantagem de escolher automaticamente o volume certo de recursos de computação para a sua Task, o que pode trazer ganhos de custo e desempenho caso você tenha definido um tamanho de warehouse pequeno demais.
Gerenciando Tasks
Na hora de gerenciar Snowflake Tasks, há alguns pontos que você vai querer entender:
- Com que frequência a task está rodando?
- Quanto tempo ela leva pra rodar?
- Com que frequência ela está falhando?
- Dá para disparar alertas quando as Tasks falham?
Pela UI do Snowflake
Vamos ver como usar a UI do Snowflake para gerenciar Tasks.
Para localizar suas Tasks, vá até o database e o schema em que elas foram criadas.
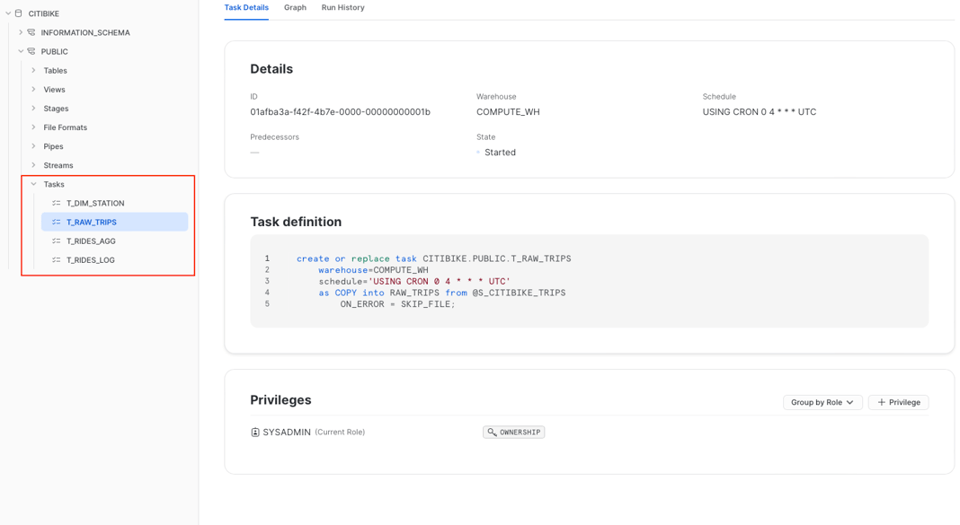
A aba "Details" da Task traz uma visão geral completa. Você vê a definição junto com os parâmetros mais importantes, como o warehouse atribuído, o agendamento e os privilégios concedidos. Já a aba "Graph" mostra a visão completa do DAG, como vimos acima.
Para conferir o histórico de execuções, abra a aba "Run History".
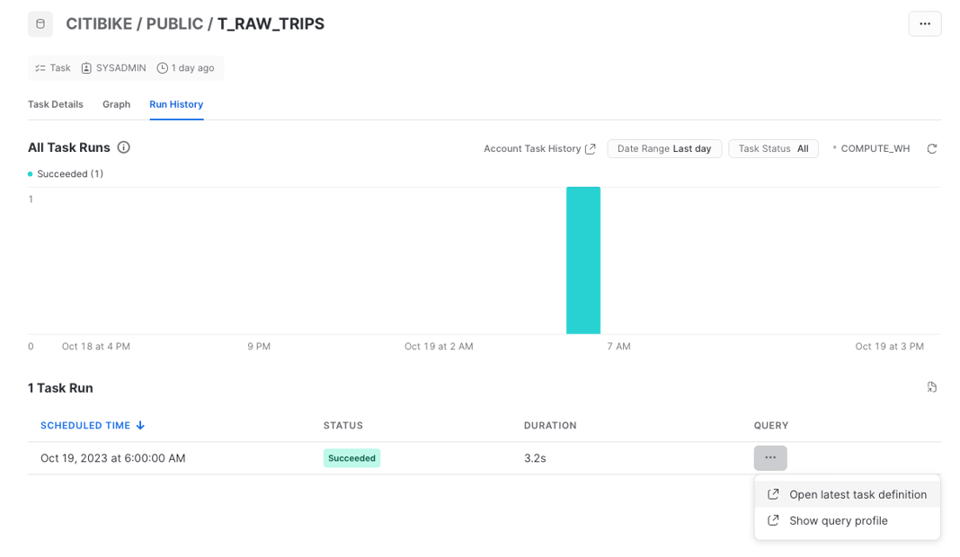
O histórico da Task aparece em um gráfico de barras com o número de execuções ao longo do tempo. As execuções individuais ficam na tabela abaixo. Vale lembrar que essa página traz apenas os dados dos últimos 7 dias.
Se quiser entender e monitorar as Tasks de toda a conta, vá em Activity -> Task History.
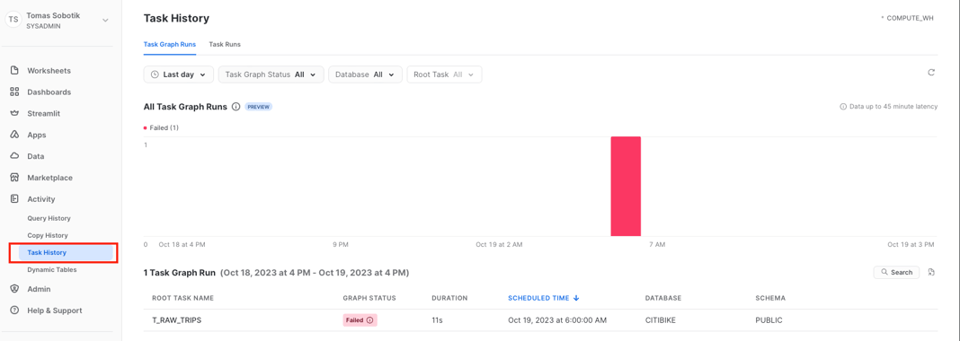
A partir daí, você pode abrir execuções individuais do grafo e verificar o status de cada Task e execução. Essa UI de histórico de grafos em nível de conta está em Public Preview no momento.

Monitorando Tasks de forma programática
Para quem prefere código em vez da UI do Snowflake, ou quer montar suas próprias visualizações sobre as Tasks, o Snowflake oferece diversas views com dados sobre execuções, status e muito mais. Vamos ver alguns exemplos.
Já usamos o comando show tasks, que traz um panorama básico das Tasks na sua conta. Ele mostra informações como estado da Task, definição, predecessoras, warehouse e muito mais.
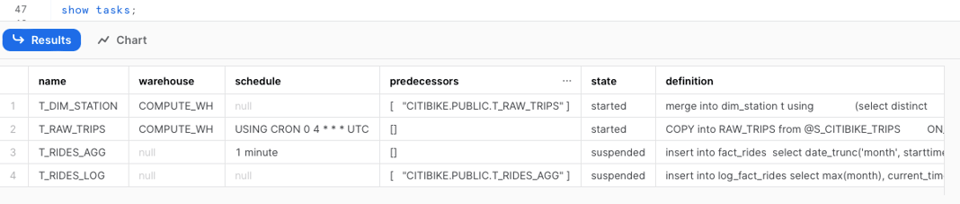
Se você precisa percorrer o histórico de tasks via SQL, pode usar a função de tabela TASK_HISTORY() do INFORMATION_SCHEMA ou a view TASK_HISTORY em ACCOUNT_USAGE, dentro do database SNOWFLAKE.
A função de tabela retorna as execuções dos últimos 7 dias sem latência, o que a torna uma fonte ideal para monitoramento personalizado das execuções em tempo real. Já a view em ACCOUNT_USAGE tem latência de até 45 minutos e guarda dados de até 365 dias. Por isso, ela é mais adequada para análise histórica das execuções de Tasks do que para acompanhar execuções atuais.
Veja um exemplo de consulta usando a função de tabela do histórico de Tasks do information schema para mostrar todas as Tasks que falharam no intervalo de tempo informado.
select *
from table(information_schema.task_history(
scheduled_time_range_start=>to_timestamp_ltz('2023-10-18 00:00:00.000'),
error_only => TRUE
))
order by scheduled_time desc

Repare que, na saída, vêm informações sobre o erro junto com o query_id. Se quiser, você pode entrar nos detalhes do Query History ou no query profile para investigar a falha. Se consultar essa função de tabela sem nenhum parâmetro, você obtém todas as execuções de task dos últimos 7 dias, incluindo as agendadas.
select *
from table(information_schema.task_history())
order by scheduled_time desc

Essa abordagem funciona bem quando a Task dispara uma única instrução SQL. Mas e quando a Task executa uma stored procedure que, por sua vez, dispara várias instruções? Como identificar todas elas?
Para isso, precisamos usar o atributo SESSION_ID da view QUERY_HISTORY. Todas as queries disparadas por uma stored procedure provavelmente rodam dentro da mesma sessão. Então, o primeiro passo é combinar TASK_HISTORY() e QUERY_HISTORY para descobrir o SESSION_ID da chamada da stored procedure:
select
b.session_id,
a.name,
a.query_text,
a.query_start_time,
a.completed_time
from table(information_schema.task_history(task_name => 't_dim_station')) t
inner join snowflake.account_usage.query_history q
on t.query_id = q.query_id

Depois, é só rodar outra query para encontrar todas as queries com o mesmo SESSION_ID.
select *
from query_history
where session_id = <<session id from previous step>>
and start_time >= '<<task start time>>'
and start_time <= '<<task end time>>';
Recebendo alertas de falhas de Tasks
Ser notificado automaticamente quando alguma Task falha é um requisito crítico na maioria dos cenários com Tasks.
O Snowflake oferece diferentes recursos de alertas e notificações que podem ser usados com Tasks. Escrevi posts dedicados que cobrem essas opções em mais detalhes. Confira nos links abaixo:
Limitações das Tasks
Já comentamos algumas limitações das Tasks quando falamos sobre DAGs mais cedo no post. Aqui vai um resumo de todas as limitações relacionadas a Tasks:
- Sua Task pode executar uma única instrução SQL ou uma chamada de stored procedure
- Uma única task pode ter até 100 predecessoras
- Uma única task pode ter até 100 tasks filhas
- Um único DAG pode ter até 1000 tasks
- Um DAG precisa ter uma única task raiz
- DAGs não suportam loops
- Tasks não podem ser compartilhadas pelos recursos de data sharing do Snowflake
Como as Tasks são cobradas
Não há cobranças extras nem taxas adicionais pelo uso de Tasks. Você só paga pelos recursos de computação usados na execução das instruções SQL de cada Task. Se suas tasks rodam nos seus próprios warehouses gerenciados, a cobrança é igual à de queries SQL comuns rodando em um warehouse. Se você estiver usando Serverless Tasks, paga pelos recursos de computação gerenciados pelo Snowflake. Lembrando: a computação das Serverless Tasks custa 1,5x mais do que o custo equivalente de computação nos seus próprios virtual warehouses.
Monitorando os custos das Serverless Tasks
Os custos das Serverless Tasks podem ser monitorados pela view serverless_task_history do schema account_usage. Veja um exemplo de consulta:
select
start_time,
end_time,
task_name,
credits_used
from snowflake.account_usage.serverless_task_history
where
start_time > current_date - 30
order by start_time desc
Tomáš Sobotík·Senior Data Engineer & Snowflake SME na Norlys
Tomas é um Snowflake Data SuperHero de longa data e referência geral no assunto. Sua vasta experiência no mundo dos dados se estende por mais de uma década, atuando como data engineer, arquiteto e admin do Snowflake em projetos de diversos setores e tecnologias. Tomas é um membro ativo da comunidade, sempre compartilhando seu conhecimento e inspirando outras pessoas. Também é instrutor da O'Reilly, conduzindo treinamentos ao vivo online.