Snowflake Tasksは強力な機能で、データパイプラインや、バックアップ・データ品質チェックといった管理ジョブ、アラートのオーケストレーションに広く使われています。本ガイドでは、Taskのセットアップと作成、各種コンピュートモデル、Taskの管理と可観測性まで、Snowflake Tasksについて押さえておきたい内容を一通り解説します。
Snowflake Tasksとは
Snowflake Tasksは、SQLをスケジュール実行するための機能です。実行できるSQLコマンドに制限はなく、単一のSQL文でも、複数のSQL文を呼び出すストアドプロシージャでも構いません。TasksはSnowflakeのファーストクラスオブジェクトであり、オーナーを持ち、他のSnowflakeオブジェクトと同様に権限付与によってアクセス制御を行えます。
Snowflake Taskの作成方法
他のSnowflakeオブジェクトと同様、TaskもSQLで作成・管理できます。新しいTaskを作成するときによく使うパラメータは次のとおりです。
schedule:Taskをいつトリガーするかwarehouse:どのコンピュートクラスタを使うかcode:実行するSQLコマンドcondition:Taskがトリガーされたときに評価されるブール式。条件を満たさない場合、Taskは実行されずスキップされます。
Taskに関するパラメータと設定の一覧は、Snowflakeの公式ドキュメントを参照してください。
Task作成の例
Task作成時に必ず定義しておきたい重要なパラメータの一つがscheduleです。これによってTaskがいつトリガーされるかが決まります。スケジュールはいくつかの方法で指定でき、CRON構文で書く、分単位の間隔で指定する(例:5分ごとに実行)、別のTaskの後に実行するよう設定する、といった方法があります。
例として、自転車ステーションを格納するディメンションモデルを更新するシンプルなTaskを作ってみましょう。毎晩午前4時に実行されるようスケジュールします。
create or replace task t_dim_station
warehouse = compute_wh
schedule = 'USING CRON 0 4 * * * UTC'
as
merge into dim_station t using
(select distinct
start_station_id station_id,
start_station_name station_name,
start_station_latitude station_latitude,
start_station_longitude station_longitude
from raw_trips
union
select distinct
end_station_id station_id,
end_station_name station_name,
コードを展開
この例ではCRON構文でTaskをスケジュールしています。CRON構文に慣れていないと読みにくいかもしれません。crontabのような、正しい構文を解説付きで生成してくれるサイトを使うのがおすすめです。
Taskは作成直後は必ずサスペンド状態になります。つまりスケジュールされていない状態のため、まず再開する必要があります。次のコマンドで再開できます。
1alter task t_dim_station resume;
Task定義に変更を加えるたび(alter taskコマンドを実行するたび)に、Taskはサスペンド状態に戻り、再度再開が必要になります。経験上、これがデータパイプラインが動かないトラブルの主な原因になりがちです。Taskをデバッグするときは、まずTaskが再開されているかどうかを確認しましょう。Taskの状態はshow tasksコマンドの出力で確認できます。
Taskの依存関係
複数のTaskを連鎖させると、より複雑なデータパイプラインを構築できます。データ実務者はこの依存関係の連なりを「DAG(Directed Acyclic Graph:有向非巡回グラフ)」と呼ぶことが多く、例を以下に示します。
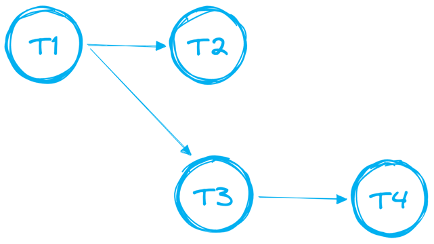
DAGには次のようなルールと制限があります。
- DAGはルートTaskを1つだけ持つ必要がある
- サポートされるのは順方向のみ。DAGにループは作れない
- 1つのDAGに含められるTaskは合計で最大1000個
- 1つのTaskが持てる先行Taskは最大100個、子Taskも最大100個
では、パイプラインにもう1つTaskを追加してDAGを作ってみましょう。現在のTask t_dim_station は、生データテーブルからディメンションテーブルを更新します。ここに先行Taskを追加して、外部ステージから生データテーブルにデータをロードするようにします。あわせてスケジュールも変更し、UTCの午前4時に実行する代わりにAFTER条件を加え、先行Taskが正常終了した時点でこのTaskがトリガーされるようにします。
まず、新しい先行Task t_raw_trips を定義します。
create task t_raw_trips
warehouse = compute_wh
schedule = 'using cron 0 4 * * * utc'
as
copy into raw_trips from @s3_source_data
on_error = skip_file
次に、最初に作成したTaskを修正します。SCHEDULEパラメータを外し、AFTER条件を追加します。
alter task t_dim_station unset schedule;
alter task t_dim_station add after t_raw_trips;
これで、t_raw_tripsを「ルートTask」とする2つのTaskからなるDAGが完成しました。
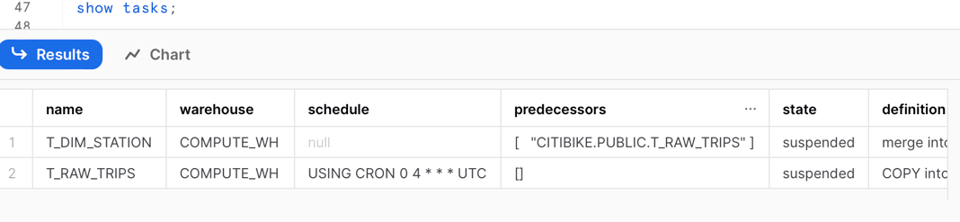
もう一度show taskコマンドを実行すると、次のような変化が確認できます。
- 元のTaskにはスケジュールが設定されていない
- 元のTaskに先行Taskが設定されている
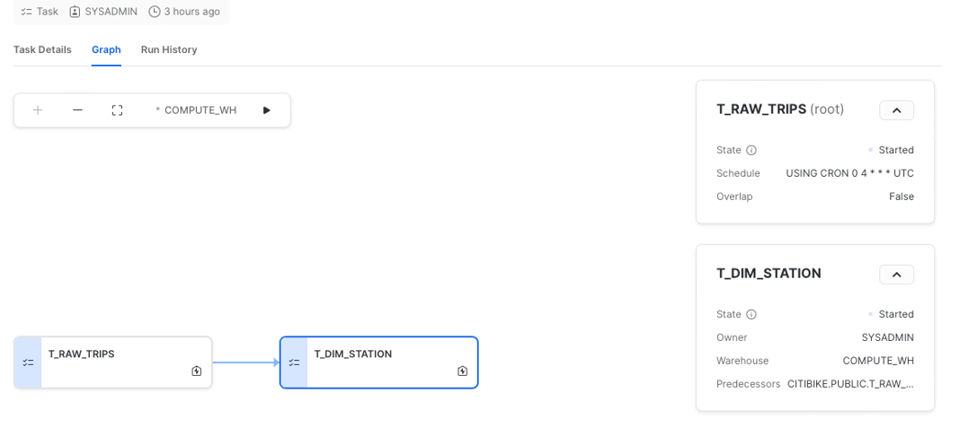
Snowflakeには、特にDAGの操作に便利なTask用UIも用意されています。「Graph」タブからパイプライン全体を可視化したり、Taskの詳細を確認したり、実行履歴を見たりできます。
Taskのコンピュートモデル
セルフマネージドのウェアハウス
前述の2つのTaskは、いずれもセルフマネージドのウェアハウスCOMPUTE_WH上で動かすよう設定していました。これは、Taskで実行されるSQLコマンドが自分のCOMPUTE_WH上で動くことを意味し、そのウェアハウスの管理(適切なサイズ、クラスタ数、自動サスペンドの設定など)も自分で行う必要があります。
もう一つの選択肢が、Serverless Tasksの利用です。
Serverless Tasks
Serverless Tasksは、自前の仮想ウェアハウスではなくSnowflakeが提供するコンピュートリソース上で実行されます。サーバーレスのTaskを作成するには、新規Task作成時にwarehouseパラメータを省略するだけです。
Serverless Tasksの利点の一つは、Snowflakeが最適なウェアハウスサイズを自動的に判断してくれる点です。USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZEというパラメータで、初回実行時のウェアハウスサイズを指定できます。数回実行した後は、Snowflakeはこのパラメータを無視し、正常終了した過去の実行結果から得られた知見に基づいてウェアハウスを割り当てます。時間をかけてTaskごとの最適なウェアハウスサイズを学習し、必要に応じてサイズを動的に変更してくれます。
すでに自前のウェアハウスで動いているTaskがある場合は、ALTER TASK文を実行することでサーバーレスTaskに切り替えられます。
1alter task t_dim_station unset warehouse;
Serverless Tasksとマネージドウェアハウス、どちらを選ぶべきか
SnowflakeのCredit Consumption Tableによると、Serverless Tasksは自前のマネージドウェアハウスで動かすTaskと比べて1.5倍のコストがかかります。
計算してみると、実行時間が40秒未満のTaskではサーバーレスコンピュートの方が有利で、それ以上の場合はマネージドウェアハウスの方がコスト効率に優れることがわかります。
Serverless TasksにはTaskに対して最適なコンピュートリソース量を自動で選んでくれるという利点があり、Taskに対して小さすぎるウェアハウスサイズを選んでしまっているケースでは、コストとパフォーマンスの両面でメリットが得られる可能性があります。
Taskの管理
Snowflake Tasksを運用するうえで、押さえておきたいポイントがいくつかあります。
- Taskはどのくらいの頻度で実行されているか
- 1回あたりの実行時間はどのくらいか
- どのくらいの頻度で失敗しているか
- Taskが失敗したときにアラートをトリガーできるか
Snowflake UIを使う
まず、Snowflake UIを使ったTaskの管理方法を見ていきましょう。
Taskを探すには、Taskを作成したデータベースとスキーマに移動します。
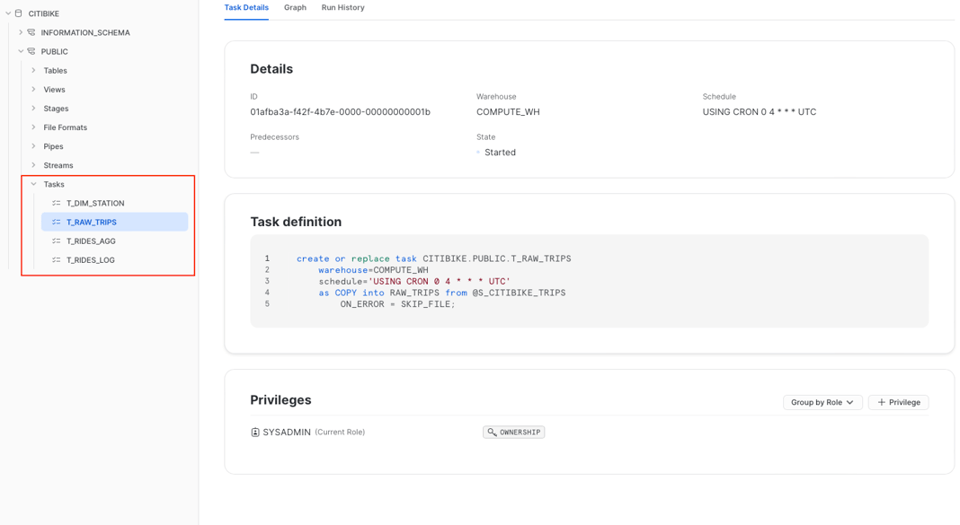
Taskの「Details」タブでは、Task全体の概要を確認できます。定義に加え、割り当てられたウェアハウス、スケジュール、付与されている権限といった主要なパラメータが一覧できます。「Graph」タブでは、前述のとおりDAG全体を俯瞰できます。
実行履歴を確認したい場合は「Run History」タブを開きます。
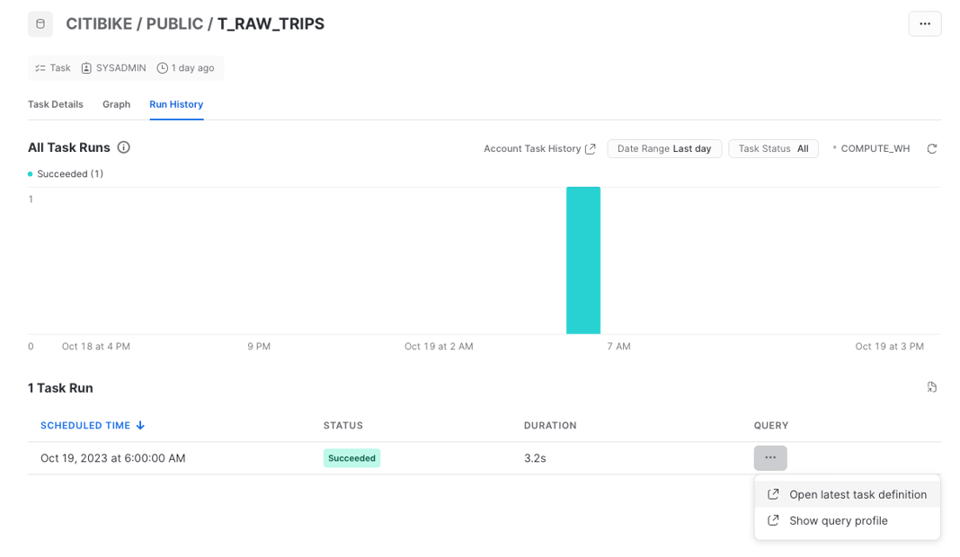
Task履歴は、時系列の実行回数を示す棒グラフで可視化されます。個別の実行は下のテーブルに表示されます。なお、このページに表示されるのは直近7日分の実行データのみです。
アカウント全体のTaskを把握・モニタリングしたい場合は、Activity → Task Historyに移動します。
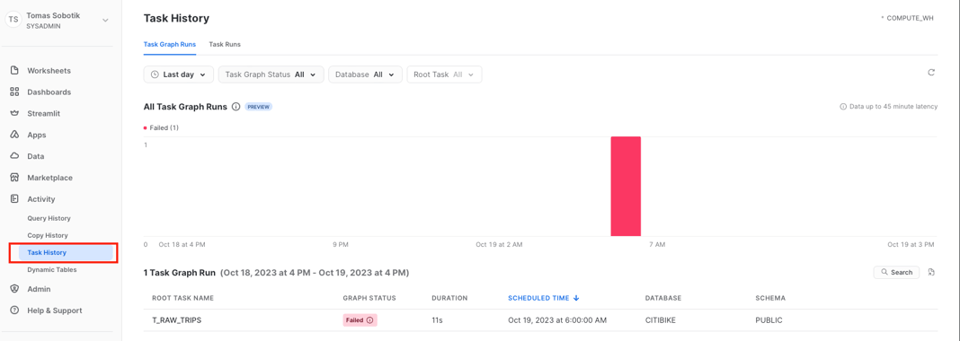
ここから個別のグラフ実行を開き、各Taskや実行のステータスを確認できます。このアカウントレベルのグラフ履歴UIは、現時点ではPublic Previewです。

プログラムからTaskをモニタリングする
SnowflakeのUIよりコードで扱いたい方、あるいはTaskの可視化を独自に作りたい方のために、Snowflakeでは実行状況やステータスなどを取得できるさまざまなビューが提供されています。いくつか例を見ていきましょう。
すでに使ったshow tasksコマンドでは、アカウント内のTaskの基本的な概要を取得できます。Taskの状態、定義、先行Task、ウェアハウスなど、さまざまな情報が得られます。
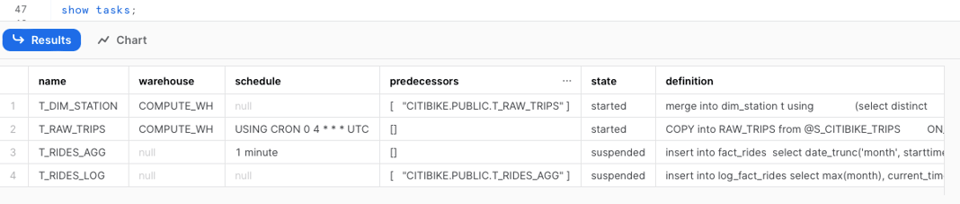
SQLでTask履歴を確認したい場合は、INFORMATION_SCHEMAのTASK_HISTORY()テーブル関数か、SNOWFLAKEデータベース内のACCOUNT_USAGEにあるTASK_HISTORYビューを利用できます。
テーブル関数は直近7日間のTask実行を返し、レイテンシがないため、実際の実行をリアルタイムにカスタム監視するのに最適です。一方、ACCOUNT_USAGEのビューには最大45分のレイテンシがありますが、過去365日分までのデータが含まれます。そのため、現在の実行を追うよりも、Task実行の履歴分析に向いています。
以下は、information schemaのTask履歴テーブル関数を使って、指定した期間に失敗したTaskをすべて表示するクエリの例です。
select *
from table(information_schema.task_history(
scheduled_time_range_start=>to_timestamp_ltz('2023-10-18 00:00:00.000'),
error_only => TRUE
))
order by scheduled_time desc

出力にはエラー情報とquery_idが含まれていることがわかります。失敗の詳しい原因を調べたい場合は、Query Historyの詳細やクエリプロファイルを確認できます。パラメータを指定せずにこのテーブル関数をクエリすると、直近7日間のすべてのTask実行と、スケジュール済みのTask実行を取得できます。
select *
from table(information_schema.task_history())
order by scheduled_time desc

この方法は、Taskが単一のSQL文をトリガーするケースではうまく機能します。では、Taskがストアドプロシージャを呼び出し、その中で複数の文をトリガーする場合はどうでしょうか。関連するすべての文を、どうやって特定すればよいのでしょうか。
これを実現するには、QUERY_HISTORYビューのSESSION_ID属性を活用します。ストアドプロシージャからトリガーされるクエリは、基本的に同じセッション内で実行されます。そこで、まずTASK_HISTORY()とQUERY_HISTORYを組み合わせて、ストアドプロシージャ呼び出しのSESSION_IDを特定します。
select
b.session_id,
a.name,
a.query_text,
a.query_start_time,
a.completed_time
from table(information_schema.task_history(task_name => 't_dim_station')) t
inner join snowflake.account_usage.query_history q
on t.query_id = q.query_id

その後、同じSESSION_IDを持つすべてのクエリを取得する別のクエリを実行します。
select *
from query_history
where session_id = <<session id from previous step>>
and start_time >= '<<task start time>>'
and start_time <= '<<task end time>>';
Task失敗時のアラート設定
Taskが失敗したときに自動で通知を受け取れる仕組みは、ほとんどのTask運用において欠かせない要件です。
Snowflakeはアラートと通知に関連するさまざまな機能を提供しており、Taskにも活用できます。これらの選択肢については別の記事で詳しく解説していますので、以下のリンクからご覧ください。
Taskの制限事項
本記事のDAGに関するセクションで、Taskの制限事項にはすでに少し触れました。ここで、Taskに関する制限事項をまとめておきます。
- Taskで実行できるのは単一のSQL文またはストアドプロシージャ呼び出しのみ
- 1つのTaskが持てる先行Taskは最大100個
- 1つのTaskが持てる子Taskは最大100個
- 1つのDAGに含められるTaskは最大1000個
- DAGはルートTaskを1つだけ持つ必要がある
- DAGはループをサポートしない
- TaskはSnowflakeのデータ共有機能では共有できない
Taskの課金体系
Taskの利用に対する追加料金やオーバーヘッドはありません。課金されるのは、各Taskで実行されるSQL文に紐づくコンピュートリソースの分だけです。自前のマネージドウェアハウス上でTaskを実行する場合は、通常のSQLクエリをウェアハウス上で実行するときと同じ仕組みでコンピュートリソースが課金されます。Serverless Tasksを使う場合は、Snowflakeが管理するコンピュートリソースに対して課金されます。念のためお伝えしておくと、Serverless Tasksのコンピュートは、自前の仮想ウェアハウスを使った場合の同等のコンピュートコストと比べて1.5倍高くなります。
Serverless Taskのコストを監視する
Serverless Taskのコストは、account_usageスキーマのserverless_task_historyビューで監視できます。以下はクエリの例です。
select
start_time,
end_time,
task_name,
credits_used
from snowflake.account_usage.serverless_task_history
where
start_time > current_date - 30
order by start_time desc
Tomáš Sobotík・Senior Data Engineer & Snowflake SME at Norlys
Tomasは長年にわたるSnowflake Data SuperHeroであり、Snowflake全般に精通したスペシャリストです。データ業界での経験は10年以上に及び、その間、さまざまな業界・技術領域のプロジェクトでSnowflakeのデータエンジニア、アーキテクト、管理者として活躍してきました。Tomasはコミュニティの中核メンバーとして、自らの知見を積極的に発信し、多くの人にインスピレーションを与えています。また、O'Reillyのインストラクターとして、オンラインのライブトレーニングも担当しています。