Snowflake Tasks es una funcionalidad potente que se usa habitualmente para pipelines de datos, para orquestar tareas administrativas (backups, validaciones de calidad de datos) y alertas. En esta guía definitiva repaso todo lo que necesitas saber sobre Snowflake Tasks: desde su configuración y creación hasta los distintos modelos de cómputo, además de la gestión y la observabilidad.
¿Qué son las Snowflake Tasks?
Las Snowflake Tasks te permiten ejecutar SQL de forma programada. El comando SQL puede ser cualquiera: una única sentencia o la llamada a un stored procedure que invoque varias sentencias SQL. Las Tasks son ciudadanos de primera clase en Snowflake, es decir, tienen un propietario y puedes controlar su acceso otorgando privilegios, igual que con cualquier otro objeto de Snowflake.
Cómo crear una Snowflake Task
Al igual que el resto de objetos de Snowflake, las Tasks se crean y gestionan de manera programática con SQL. Los parámetros más comunes al crear una nueva task son:
schedule: cuándo debe dispararse la taskwarehouse: qué cluster de cómputo debe utilizarsecode: el comando SQL que se va a ejecutarcondition: una expresión booleana que se evalúa cuando la Task se dispara. Determina si la Task se ejecuta o se omite cuando no se cumple la condición.
Para ver la lista completa de parámetros y configuraciones asociados a las tasks, consulta la documentación de Snowflake.
Ejemplo de creación de una Task
Uno de los parámetros clave que debes definir al crear una Task es schedule, que indica cuándo se va a disparar. El schedule se puede definir de varias formas: con sintaxis CRON, con un intervalo en minutos (por ejemplo, cada 5 minutos) o indicando que la Task se ejecute después de otra Task.
Vamos a crear una Task sencilla para refrescar un modelo dimensional con estaciones de bicicletas. La programaremos para que se ejecute todas las noches a las 4 a.m.:
create or replace task t_dim_station
warehouse = compute_wh
schedule = 'USING CRON 0 4 * * * UTC'
as
merge into dim_station t using
(select distinct
start_station_id station_id,
start_station_name station_name,
start_station_latitude station_latitude,
start_station_longitude station_longitude
from raw_trips
union
select distinct
end_station_id station_id,
end_station_name station_name,
Expandir código
Este ejemplo usa la sintaxis CRON para programar la Task. Si no estás familiarizado con ella, puede costar leerla. Te recomiendo apoyarte en sitios como crontab, que generan la sintaxis correcta junto con su explicación.
Cuando creas una task, queda en estado suspendido: no está programada y primero tienes que reanudarla. Puedes hacerlo con el siguiente comando:
1alter task t_dim_station resume;
Cada vez que modifiques la definición de una Task (por ejemplo, al ejecutar un comando alter task), volverá al estado suspendido y tendrás que reanudarla. Por mi experiencia, esta suele ser la causa raíz de los problemas con pipelines de datos que no se ejecutan. Cuando depures Tasks, verifica siempre que estén reanudadas. Puedes consultar el estado en la salida del comando show tasks.
Dependencias entre Tasks
Las Tasks se pueden encadenar para formar pipelines de datos más complejos compuestos por varias tasks. Quienes trabajamos con datos solemos llamar a esta cadena de dependencias "DAGs" (Directed Acyclic Graphs, o grafos acíclicos dirigidos). A continuación tienes un ejemplo.
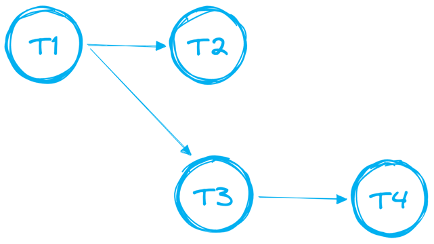
En el caso de los DAGs hay ciertas reglas y limitaciones que deben respetarse:
- El DAG debe tener una única root task
- Solo se admite una dirección hacia adelante. El DAG no puede tener bucles.
- Un mismo DAG puede tener hasta 1000 Tasks en total
- Una Task puede tener hasta 100 predecesoras y hasta 100 tasks hijas
Vamos a sumar otra task al pipeline para formar un DAG. Nuestra task actual, t_dim_station, refresca la tabla dimensional a partir de una tabla raw. Añadiremos una task predecesora que poblará esa tabla raw desde un stage externo. También actualizaremos su schedule: en lugar de ejecutarse a las 4 a.m. UTC, agregaremos una condición AFTER para que la Task se dispare cuando la predecesora termine con éxito.
Primero, definimos la nueva Task predecesora t_raw_trips:
create task t_raw_trips
warehouse = compute_wh
schedule = 'using cron 0 4 * * * utc'
as
copy into raw_trips from @s3_source_data
on_error = skip_file
Ahora hay que modificar la task inicial. Primero se quita el parámetro SCHEDULE y luego se añade la condición AFTER.
alter task t_dim_station unset schedule;
alter task t_dim_station add after t_raw_trips;
Ya tenemos un DAG formado por dos Tasks, en el que t_raw_trips es la "root task".
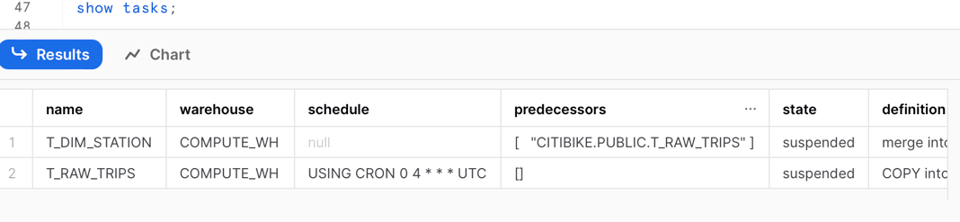
Si ejecutamos de nuevo el comando show task, podremos notar los siguientes cambios:
- La task original ya no tiene schedule
- La task original ahora tiene una task predecesora
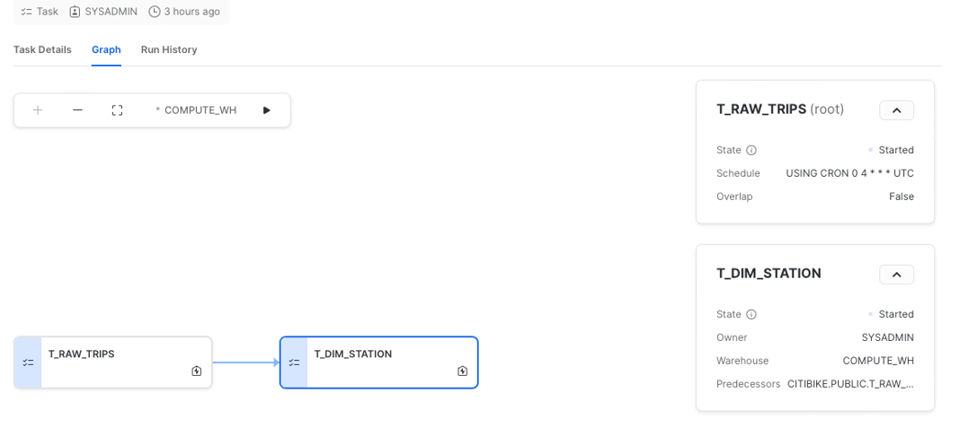
Snowflake también ofrece una excelente UI para trabajar con tasks, sobre todo con DAGs. Desde la pestaña "Graph" puedes visualizar el pipeline completo, abrir el detalle de cada task o revisar el historial de ejecuciones.
Modelos de cómputo para Tasks
Warehouses autogestionados
Las dos Tasks de ejemplo anteriores se configuraron para ejecutarse en un warehouse autogestionado, COMPUTE_WH. Esto significa que los comandos SQL ejecutados por las Tasks se procesan en nuestro propio COMPUTE_WH, y somos nosotros quienes gestionamos ese warehouse (tamaño, número de clusters, auto-suspend, etc.).
Una alternativa es usar Serverless Tasks.
Serverless Tasks
En lugar de ejecutarse en uno de tus propios virtual warehouses, las Serverless Tasks corren sobre recursos de cómputo proporcionados por Snowflake. Para crear una Serverless Task basta con omitir el parámetro warehouse al crear la nueva task.
Una ventaja de las Serverless Tasks es que Snowflake determina automáticamente el tamaño óptimo de warehouse para ejecutar la Task. Existe un parámetro llamado USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE que define el tamaño inicial del warehouse para la primera ejecución. Tras algunas ejecuciones, Snowflake ignora ese parámetro y asigna el warehouse en función de la información recogida en las corridas exitosas. Con el tiempo aprende cuál es el mejor tamaño para una task concreta y lo ajusta dinámicamente según sea necesario.
Si ya tienes una Task que corre en uno de tus warehouses, puedes convertirla en Serverless Task ejecutando la sentencia ALTER TASK:
1alter task t_dim_station unset warehouse;
¿Cuándo conviene usar Serverless Tasks frente a un warehouse gestionado?
Según la Snowflake Credit Consumption Table, las Serverless Tasks cuestan 1.5x más que las Tasks que corren en tu propio warehouse gestionado.
Echando números, se puede comprobar que la opción de cómputo serverless conviene para Tasks que tarden menos de 40 segundos en ejecutarse. Si tardan más, resulta más rentable usar un warehouse gestionado.
Las Serverless Tasks tienen la ventaja de elegir automáticamente la cantidad de recursos de cómputo adecuada, lo que se traduce en beneficios de costo y rendimiento si normalmente eliges un warehouse demasiado pequeño para tu Task.
Gestión de Tasks
A la hora de gestionar Snowflake Tasks, hay varios aspectos que conviene tener claros:
- ¿Con qué frecuencia se ejecuta la task?
- ¿Cuánto tarda en ejecutarse?
- ¿Con qué frecuencia falla?
- ¿Podemos disparar alertas cuando las Tasks fallan?
Usando la UI de Snowflake
Veamos cómo aprovechar la UI de Snowflake para gestionar Tasks.
Para ubicar tus Tasks, ve a la base de datos y al schema donde las creaste.
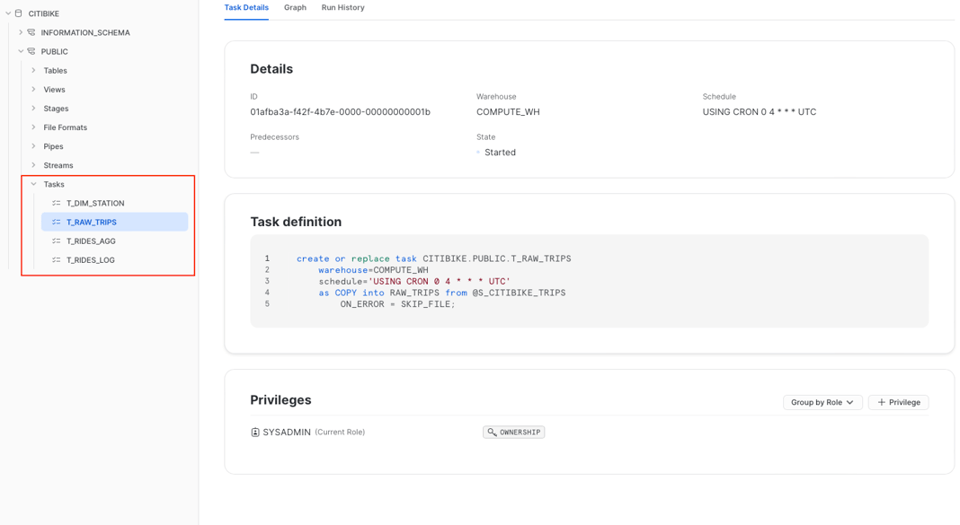
La pestaña "Details" te da una visión general de la Task. Verás la definición junto con los parámetros clave: el warehouse asignado, el schedule y los privilegios otorgados. La pestaña "Graph", por su parte, muestra el DAG completo, tal como vimos antes.
Si necesitas revisar el historial de ejecuciones, abre la pestaña "Run History".
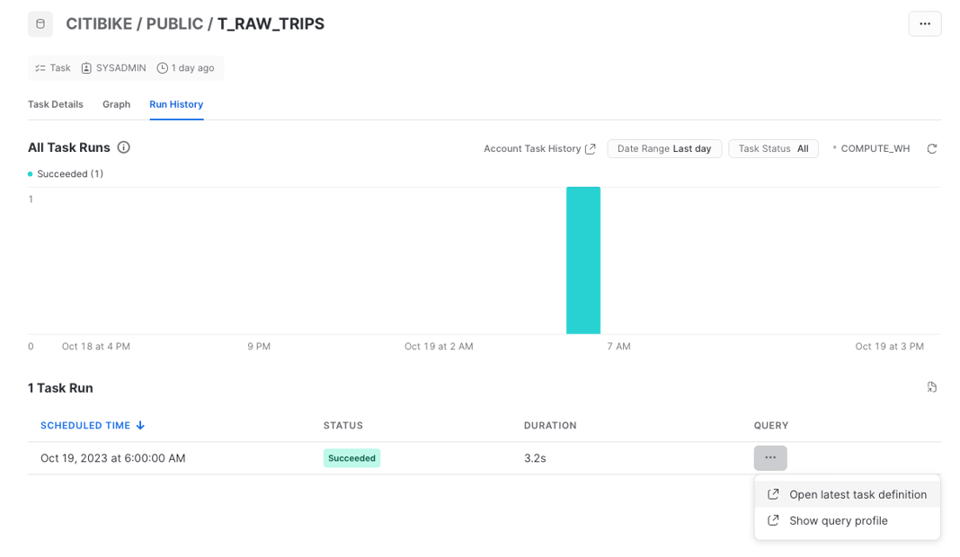
El historial de la Task se visualiza como un gráfico de barras que muestra el número de ejecuciones a lo largo del tiempo. Cada ejecución se detalla en la tabla inferior. Ten en cuenta que esta página solo incluye datos de los últimos 7 días.
Si quieres entender y monitorear las Tasks en toda tu cuenta, ve a Activity -> Task History.
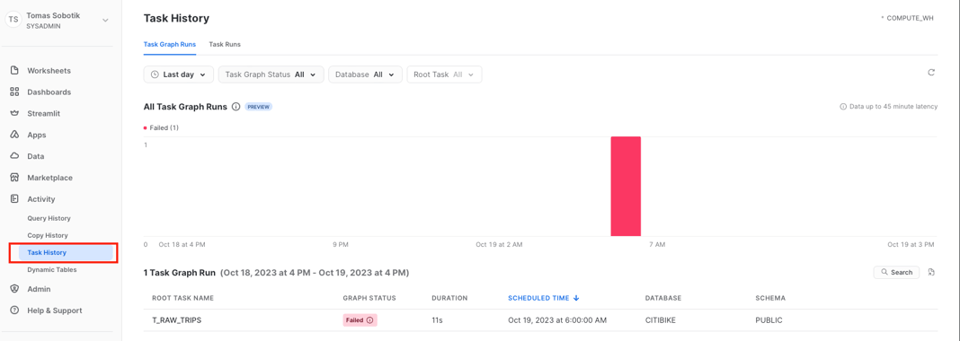
Desde ahí puedes abrir las ejecuciones individuales del grafo y revisar el estado de cada Task y de cada ejecución. Esta UI de historial de grafos a nivel de cuenta está actualmente en Public Preview.

Monitoreo programático de Tasks
Para quienes prefieren el código frente a la UI de Snowflake, o quieren construir su propia visualización sobre las Tasks, Snowflake ofrece varias vistas con datos sobre ejecuciones, estados y mucho más. Veamos algunos ejemplos.
Ya usamos el comando show tasks, que entrega una visión básica de las Tasks de tu cuenta. Aporta información como el estado de la Task, su definición, las predecesoras, el warehouse y mucho más.
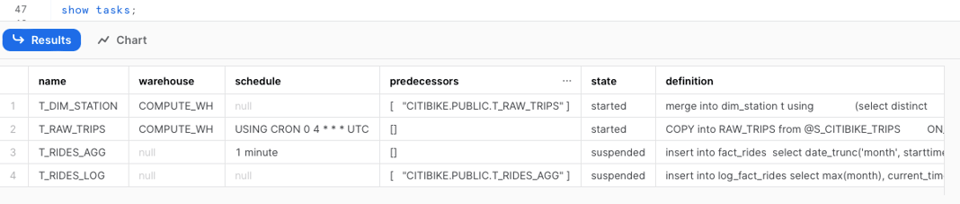
Si necesitas revisar el historial de tasks desde SQL, puedes usar la función de tabla TASK_HISTORY() del INFORMATION_SCHEMA o la vista TASK_HISTORY en ACCOUNT_USAGE, dentro de la base de datos SNOWFLAKE.
La función de tabla devuelve las ejecuciones de los últimos 7 días sin latencia, lo que la hace ideal para el monitoreo personalizado de ejecuciones actuales. La vista de ACCOUNT_USAGE, en cambio, tiene una latencia de hasta 45 minutos y guarda datos de hasta 365 días atrás. Por eso encaja mejor con el análisis histórico de las ejecuciones de Tasks que con la revisión de ejecuciones recientes.
A continuación, un ejemplo de consulta que utiliza la función de tabla del historial de tasks del information schema para mostrar todas las Tasks que fallaron en un rango de tiempo dado.
select *
from table(information_schema.task_history(
scheduled_time_range_start=>to_timestamp_ltz('2023-10-18 00:00:00.000'),
error_only => TRUE
))
order by scheduled_time desc

Como ves, la salida incluye información del error junto con el query_id. Si quieres, puedes profundizar en el detalle del Query History o del query profile para investigar más a fondo esa falla. Si consultas la función de tabla sin parámetros, obtendrás todas las ejecuciones de tasks de los últimos 7 días junto con las ejecuciones programadas.
select *
from table(information_schema.task_history())
order by scheduled_time desc

Este enfoque funciona bien cuando la Task dispara una sola sentencia SQL. ¿Pero qué pasa si la Task ejecuta un stored procedure que, a su vez, dispara varias sentencias? ¿Cómo identificamos todas las sentencias asociadas?
Para lograrlo nos apoyamos en el atributo SESSION_ID de la vista QUERY_HISTORY. Todas las queries que dispara un stored procedure se ejecutan, casi siempre, dentro de la misma sesión. Lo que hay que hacer es combinar primero TASK_HISTORY() y QUERY_HISTORY para averiguar el SESSION_ID de la llamada al stored procedure:
select
b.session_id,
a.name,
a.query_text,
a.query_start_time,
a.completed_time
from table(information_schema.task_history(task_name => 't_dim_station')) t
inner join snowflake.account_usage.query_history q
on t.query_id = q.query_id

Luego puedes ejecutar otra consulta para encontrar todas las queries con el mismo SESSION_ID.
select *
from query_history
where session_id = <<session id from previous step>>
and start_time >= '<<task start time>>'
and start_time <= '<<task end time>>';
Recibir alertas cuando fallan las Tasks
Recibir una notificación automática cuando una Task falla es un requisito crítico en la mayoría de los despliegues.
Snowflake ofrece varias funcionalidades de alertas y notificaciones que se pueden aplicar a las Tasks. Escribí blogs aparte donde cubro estas opciones con más detalle. Puedes consultarlos en los enlaces siguientes:
Limitaciones de las Tasks
Antes vimos algunas limitaciones de las Tasks al hablar de los DAGs. Aquí tienes un resumen de todas las limitaciones:
- La Task puede ejecutar una única sentencia SQL o la llamada a un stored procedure
- Una task puede tener hasta 100 predecesoras
- Una task puede tener hasta 100 tasks hijas
- Un DAG puede contener hasta 1000 tasks
- El DAG debe tener una única root task
- Los DAGs no admiten bucles
- Las Tasks no se pueden compartir con las capacidades de data sharing de Snowflake
Cómo se facturan las Tasks
No hay cargos extra ni costos adicionales por usar Tasks. Solo se factura por los recursos de cómputo asociados a la ejecución de las sentencias SQL de cada Task. Si tus tasks corren en tus propios warehouses gestionados, se facturan esos recursos de cómputo igual que cualquier query SQL ejecutada en un warehouse. Si usas Serverless Tasks, se facturan los recursos de cómputo gestionados por Snowflake. Como recordatorio: el cómputo de Serverless Tasks es 1.5x más caro que el cómputo equivalente en tus propios virtual warehouses.
Monitoreo de costos de Serverless Tasks
Los costos de Serverless Tasks se pueden monitorear con la vista serverless_task_history del schema account_usage. Aquí tienes un ejemplo de consulta:
select
start_time,
end_time,
task_name,
credits_used
from snowflake.account_usage.serverless_task_history
where
start_time > current_date - 30
order by start_time desc
Tomáš Sobotík·Senior Data Engineer y Snowflake SME en Norlys
Tomas es un Snowflake Data SuperHero con una larga trayectoria y un referente en Snowflake. Su experiencia en el mundo de los datos suma más de una década, en la que se ha desempeñado como data engineer, arquitecto y administrador de Snowflake en proyectos de industrias y tecnologías muy variadas. Tomas es un miembro activo de la comunidad: comparte su conocimiento e inspira a otros. Además es instructor de O'Reilly, donde imparte sesiones de capacitación en vivo en línea.