Les Snowflake Tasks sont une fonctionnalité puissante, couramment utilisée pour les pipelines de données ou l'orchestration de tâches d'administration (sauvegardes, contrôles qualité des données) et d'alertes. Dans ce guide complet, je passe en revue tout ce qu'il faut savoir sur les Snowflake Tasks : configuration et création, différents modèles de calcul, gestion et observabilité.
Que sont les Snowflake Tasks
Les Snowflake Tasks permettent d'exécuter du SQL selon une planification. La commande SQL peut être de toute nature : une instruction SQL unique ou l'appel d'une procédure stockée invoquant plusieurs instructions SQL. Les Tasks sont des objets de première classe dans Snowflake : elles ont un propriétaire et leur accès se contrôle via l'attribution de privilèges, comme pour tout autre objet Snowflake.
Comment créer une Snowflake Task
Comme les autres objets Snowflake, les Tasks se créent et se gèrent par programmation en SQL. Les paramètres les plus courants lors de la création d'une nouvelle task sont :
schedule: à quel moment la task doit être déclenchéewarehouse: quel cluster de calcul utilisercode: la commande SQL à exécutercondition: une expression booléenne évaluée au déclenchement de la Task. Elle détermine si la Task sera exécutée ou ignorée lorsque la condition n'est pas remplie.
Pour la liste complète des paramètres et réglages associés aux tasks, consultez la documentation Snowflake.
Exemple de création de Task
L'un des paramètres clés à définir à la création d'une Task est schedule. Il détermine le moment où la Task sera déclenchée. La planification peut être définie de plusieurs manières : avec la syntaxe CRON, en définissant un intervalle en minutes (par exemple, une exécution toutes les 5 minutes), ou en spécifiant que la Task s'exécutera après une autre Task.
Créons une Task simple pour rafraîchir un modèle dimensionnel contenant des stations de vélos. Nous allons la planifier pour qu'elle s'exécute chaque nuit à 4 h du matin :
create or replace task t_dim_station
warehouse = compute_wh
schedule = 'USING CRON 0 4 * * * UTC'
as
merge into dim_station t using
(select distinct
start_station_id station_id,
start_station_name station_name,
start_station_latitude station_latitude,
start_station_longitude station_longitude
from raw_trips
union
select distinct
end_station_id station_id,
end_station_name station_name,
Développer le code
Cet exemple utilise la syntaxe CRON pour planifier la Task. Cette syntaxe peut être un peu déroutante au premier abord. Je recommande des sites comme crontab, qui génèrent la bonne syntaxe pour vous et fournissent une explication.
Toute task nouvellement créée démarre à l'état suspendu : elle n'est pas planifiée et vous devez d'abord la reprendre. Voici la commande à utiliser :
1alter task t_dim_station resume;
Chaque modification de la définition de la Task (par exemple via une commande alter task) la repasse à l'état suspendu : il faut donc la reprendre ! D'expérience, c'est souvent la cause première des pipelines de données qui ne s'exécutent plus. Lors du débogage des Tasks, vérifiez toujours qu'elles sont bien reprises. Vous pouvez obtenir l'état de la Task dans la sortie de la commande show tasks.
Dépendances entre Tasks
Les Tasks peuvent être enchaînées pour bâtir des pipelines de données plus complexes regroupant plusieurs tasks. Les data practitioners désignent souvent cette chaîne de dépendances par le terme DAG (Directed Acyclic Graph, ou graphe orienté acyclique), illustré ci-dessous.
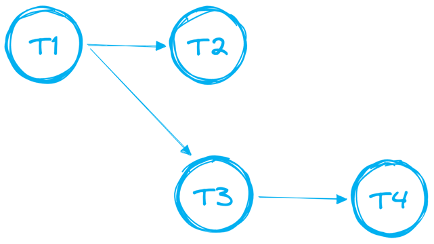
Pour les DAG, certaines règles et limites s'appliquent :
- Un DAG doit comporter une seule task racine
- Une seule direction est prise en charge : le DAG ne peut pas contenir de boucles
- Un DAG peut comporter jusqu'à 1000 Tasks au total
- Une Task peut avoir jusqu'à 100 prédécesseurs et jusqu'à 100 tasks enfants
Ajoutons une task supplémentaire à notre pipeline pour constituer un DAG. La task actuelle t_dim_station rafraîchit la table de dimension à partir d'une table brute. Nous allons ajouter une task prédécesseur chargée d'alimenter la table brute depuis un stage externe. Nous mettrons aussi à jour sa planification : au lieu d'une exécution à 4 h UTC, nous ajouterons une condition AFTER pour que la Task se déclenche dès que la task prédécesseur s'achève avec succès.
Définissons d'abord la nouvelle Task prédécesseur t_raw_trips :
create task t_raw_trips
warehouse = compute_wh
schedule = 'using cron 0 4 * * * utc'
as
copy into raw_trips from @s3_source_data
on_error = skip_file
Modifions à présent la task initiale. Il faut d'abord retirer le paramètre SCHEDULE, puis ajouter la condition AFTER.
alter task t_dim_station unset schedule;
alter task t_dim_station add after t_raw_trips;
Nous avons ainsi formé un DAG composé de deux Tasks, où t_raw_trips joue le rôle de task racine.
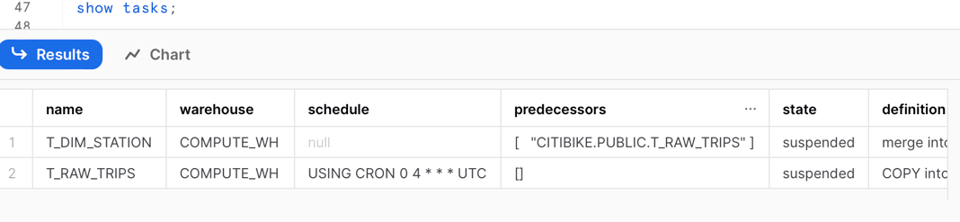
En relançant la commande show task, on constate les changements suivants :
- La task initiale n'a plus de planification
- La task initiale a désormais une task prédécesseur
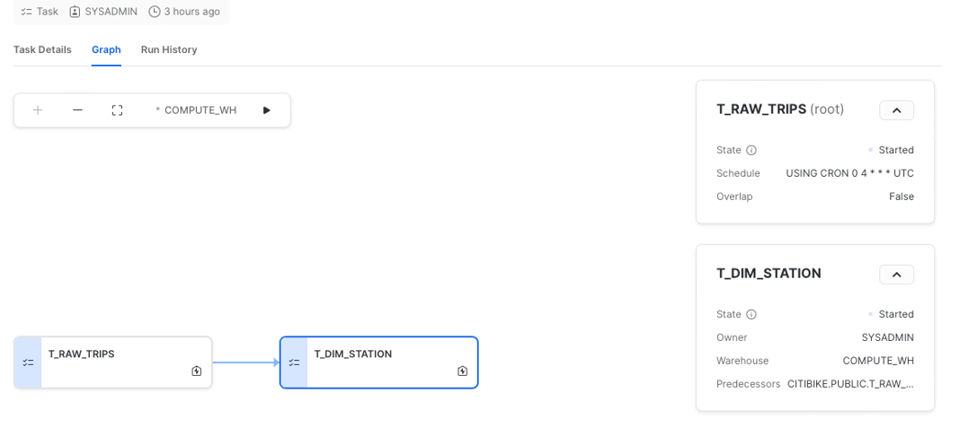
Snowflake propose aussi une excellente interface pour travailler avec les tasks, en particulier les DAG. L'onglet Graph permet de visualiser l'ensemble du pipeline, d'accéder au détail des tasks et de consulter l'historique des exécutions.
Modèles de calcul des Tasks
Warehouses gérés par l'utilisateur
Nos deux Tasks d'exemple ci-dessus étaient configurées pour s'exécuter sur un warehouse géré par l'utilisateur, COMPUTE_WH. Les commandes SQL exécutées par les Tasks tournent donc sur notre propre COMPUTE_WH, et c'est à nous d'en assurer la gestion (choix de la taille, nombre de clusters, auto-suspend, etc.).
Une autre approche consiste à utiliser les Serverless Tasks.
Serverless Tasks
Au lieu de tourner sur l'un de vos virtual warehouses, les Serverless Tasks s'exécutent sur des ressources de calcul fournies par Snowflake. Pour créer une Task serverless, il suffit d'omettre le paramètre warehouse lors de la création.
L'un des atouts des Serverless Tasks est que Snowflake détermine automatiquement la taille de warehouse optimale pour exécuter la Task. Le paramètre USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE définit la taille initiale du warehouse pour la première exécution. Après quelques exécutions, Snowflake ignore ce paramètre et choisit le warehouse en s'appuyant sur les enseignements tirés des exécutions réussies. Le service apprend au fil du temps quelle est la meilleure taille pour une task donnée et l'ajuste dynamiquement selon les besoins.
Si vous avez une Task qui s'exécute sur l'un de vos warehouses, vous pouvez la convertir en Serverless Task avec l'instruction ALTER TASK :
1alter task t_dim_station unset warehouse;
Serverless Tasks ou warehouse géré : quand choisir l'un ou l'autre ?
D'après la Snowflake Credit Consumption Table, les Serverless Tasks coûtent 1,5 fois plus cher que les Tasks tournant sur votre propre warehouse géré.
Un rapide calcul montre que l'option serverless est avantageuse pour les Tasks qui durent moins de 40 secondes. Au-delà, le warehouse géré sera plus économique.
Les Serverless Tasks ont l'avantage de dimensionner automatiquement la ressource de calcul nécessaire à votre Task, ce qui peut générer des gains de coût et de performance si vous aviez initialement choisi un warehouse trop petit.
Gérer les Tasks
Pour bien gérer les Snowflake Tasks, plusieurs questions méritent réponse :
- À quelle fréquence la task s'exécute-t-elle ?
- Combien de temps dure son exécution ?
- À quelle fréquence échoue-t-elle ?
- Peut-on déclencher des alertes en cas d'échec d'une Task ?
Via l'interface Snowflake
Voyons comment utiliser l'interface Snowflake pour gérer les Tasks.
Pour retrouver vos Tasks, rendez-vous dans la base de données et le schéma où vous les avez créées.
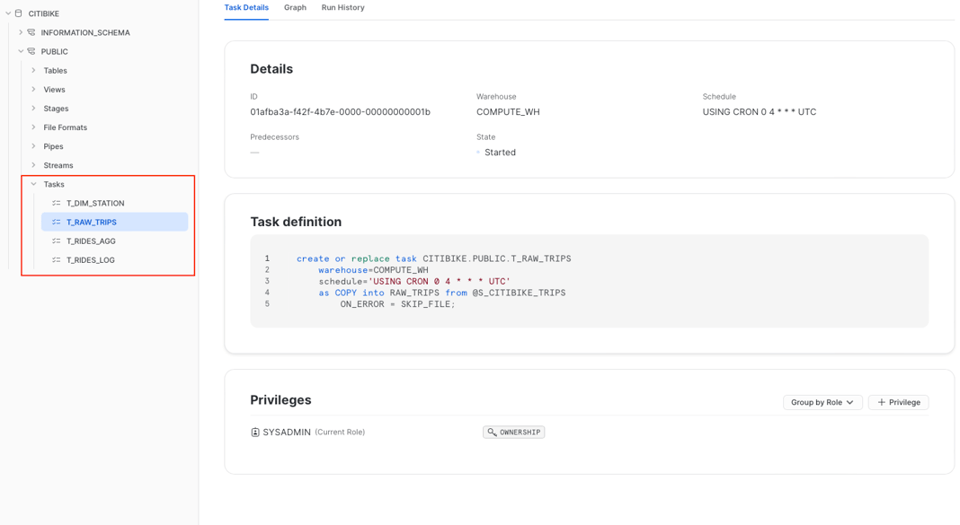
L'onglet Details de la Task offre une vue d'ensemble : définition, paramètres clés (warehouse assigné, planification, privilèges accordés). L'onglet Graph donne ensuite une vue sur l'ensemble du DAG, comme vu plus haut.
Pour consulter l'historique des exécutions, ouvrez l'onglet Run History.
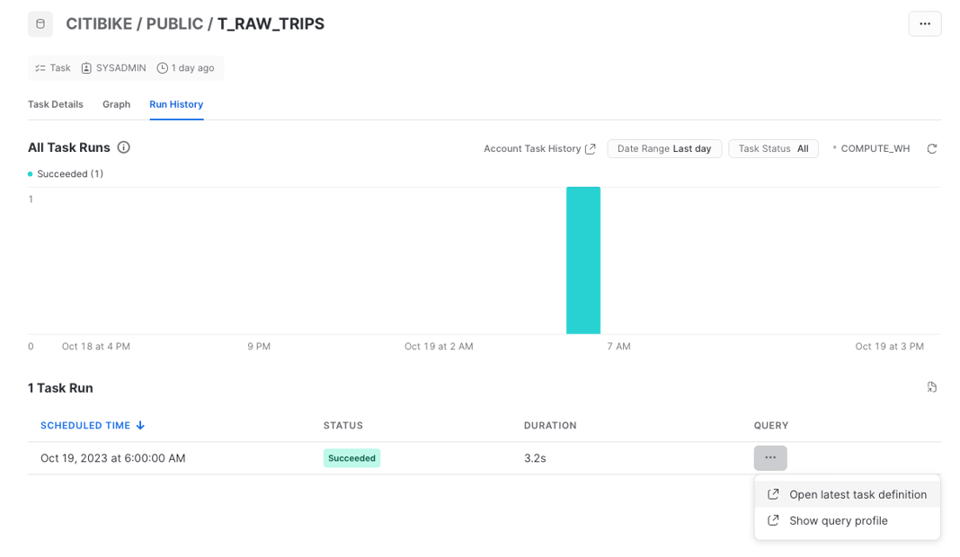
L'historique de la Task est visualisé sous forme de diagramme en barres représentant le nombre d'exécutions au fil du temps. Les exécutions individuelles figurent dans le tableau en dessous. À noter : cette page ne contient que les données des 7 derniers jours.
Pour suivre et analyser les Tasks à l'échelle de tout votre compte, rendez-vous dans Activity -> Task History.
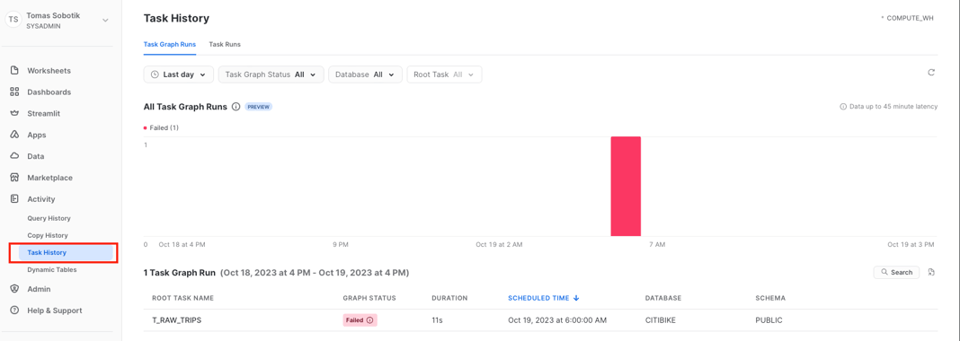
Vous pouvez ouvrir chaque exécution de graphe et vérifier le statut de chaque Task et de chaque exécution. Cette interface d'historique des graphes au niveau du compte est actuellement en Public Preview.

Surveiller les Tasks par programmation
Pour ceux qui préfèrent le code à l'interface Snowflake, ou qui souhaitent construire leurs propres visualisations autour des Tasks, Snowflake propose plusieurs vues fournissant des données sur les exécutions, leurs statuts et bien plus. Voici quelques exemples.
Nous avons déjà utilisé la commande show tasks, qui donne un aperçu de base des Tasks de votre compte : état, définition, prédécesseurs, warehouse, etc.
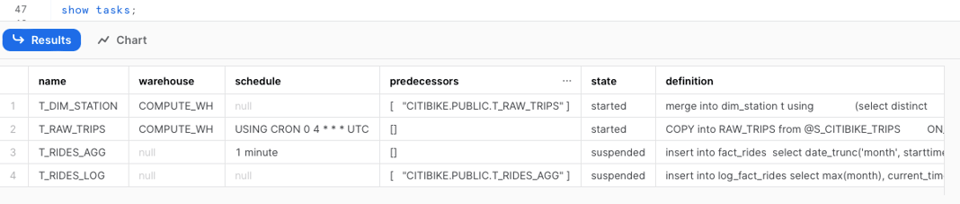
Pour parcourir l'historique d'une task en SQL, vous pouvez utiliser la fonction de table TASK_HISTORY() de INFORMATION_SCHEMA, ou la vue TASK_HISTORY de ACCOUNT_USAGE dans la base de données SNOWFLAKE.
La fonction de table renvoie les exécutions des 7 derniers jours sans latence : c'est une source idéale pour surveiller les exécutions en cours via vos propres outils. La vue ACCOUNT_USAGE présente quant à elle une latence pouvant atteindre 45 minutes et conserve les données jusqu'à 365 jours. Elle se prête donc mieux à l'analyse historique des exécutions de Tasks qu'au suivi des exécutions courantes.
Voici un exemple de requête qui utilise la fonction de table d'historique des Tasks de l'information schema pour lister toutes les Tasks ayant échoué sur une plage de temps donnée.
select *
from table(information_schema.task_history(
scheduled_time_range_start=>to_timestamp_ltz('2023-10-18 00:00:00.000'),
error_only => TRUE
))
order by scheduled_time desc

Le résultat contient des informations sur l'erreur ainsi que le query_id. Vous pouvez ensuite consulter le détail dans l'historique des requêtes ou dans le profil de requête pour en savoir plus sur l'échec. Si vous interrogez cette fonction de table sans paramètre, vous obtenez l'ensemble des exécutions de tasks des 7 derniers jours, planifications incluses.
select *
from table(information_schema.task_history())
order by scheduled_time desc

Cette approche fonctionne bien lorsque votre Task déclenche une seule instruction SQL. Mais que faire si votre Task lance une procédure stockée qui déclenche elle-même plusieurs instructions ? Comment identifier toutes les instructions associées ?
La solution consiste à exploiter l'attribut SESSION_ID de la vue QUERY_HISTORY. Toutes les requêtes déclenchées par une procédure stockée tournent très probablement au sein d'une même session. Il faut donc commencer par combiner TASK_HISTORY() et QUERY_HISTORY pour retrouver le SESSION_ID de l'appel à la procédure stockée :
select
b.session_id,
a.name,
a.query_text,
a.query_start_time,
a.completed_time
from table(information_schema.task_history(task_name => 't_dim_station')) t
inner join snowflake.account_usage.query_history q
on t.query_id = q.query_id

Vous pouvez ensuite exécuter une autre requête pour retrouver toutes les requêtes partageant le même SESSION_ID.
select *
from query_history
where session_id = <<session id from previous step>>
and start_time >= '<<task start time>>'
and start_time <= '<<task end time>>';
Recevoir des alertes en cas d'échec d'une Task
Être averti automatiquement dès qu'une Task échoue est un besoin essentiel pour la plupart des déploiements de Tasks.
Snowflake propose plusieurs fonctionnalités d'alerte et de notification utilisables avec les Tasks. J'ai rédigé des articles dédiés qui les détaillent. Vous pouvez les consulter via les liens ci-dessous :
Limites des Tasks
Nous avons déjà évoqué certaines limites des Tasks dans la section consacrée aux DAG. Voici un récapitulatif de l'ensemble des limites liées aux Tasks :
- Une Task ne peut exécuter qu'une seule instruction SQL ou un seul appel de procédure stockée
- Une task peut avoir jusqu'à 100 prédécesseurs
- Une task peut avoir jusqu'à 100 tasks enfants
- Un DAG peut contenir jusqu'à 1000 tasks
- Un DAG doit avoir une seule task racine
- Les DAG ne prennent pas en charge les boucles
- Les Tasks ne peuvent pas être partagées via les fonctionnalités de data sharing de Snowflake
Comment les Tasks sont-elles facturées
Aucun frais supplémentaire ni surcoût n'est appliqué à l'utilisation des Tasks. La facturation porte uniquement sur les ressources de calcul mobilisées pour exécuter les instructions SQL associées à chaque Task. Si vos tasks s'exécutent sur vos propres warehouses gérés, ces ressources sont facturées comme pour des requêtes SQL classiques tournant sur un warehouse. Avec les Serverless Tasks, vous êtes facturé pour les ressources de calcul gérées par Snowflake. Pour rappel, le calcul des Serverless Tasks coûte 1,5 fois plus cher que le calcul équivalent sur vos propres virtual warehouses.
Suivre les coûts des Serverless Tasks
Les coûts des Serverless Tasks peuvent être suivis via la vue serverless_task_history du schéma account_usage. Voici un exemple de requête :
select
start_time,
end_time,
task_name,
credits_used
from snowflake.account_usage.serverless_task_history
where
start_time > current_date - 30
order by start_time desc
Tomáš Sobotík·Senior Data Engineer & Snowflake SME chez Norlys
Tomas est un Snowflake Data SuperHero de longue date et un expert reconnu de Snowflake. Fort de plus d'une décennie d'expérience dans le monde de la donnée, il a occupé les rôles de data engineer, architecte et administrateur Snowflake sur des projets variés, dans des secteurs et technologies très divers. Membre actif de la communauté, Tomas partage volontiers son expertise et inspire les autres. Il est également formateur chez O'Reilly, où il anime des sessions de formation en ligne en direct.