Einführung in Snowflake Streams und Change Data Capture
Ein Snowflake Stream ist für Change Data Capture (CDC) zuständig und zeigt Ihnen, was sich in einer Tabelle seit einem bestimmten Zeitpunkt verändert hat. Aber was steckt eigentlich hinter CDC?
Kurz gesagt: CDC beantwortet die Frage "Was hat sich in meiner Datenquelle verändert, seit ich die Daten zuletzt geladen oder verarbeitet habe?"
Technisch betrachtet ist CDC eine Methode, um Änderungen an Daten in einer Quelle zu erkennen und zu erfassen. Dazu werden alle Inserts, Updates und Deletes einer Datenbanktabelle protokolliert. Diese Art der Änderungsverfolgung ist deutlich flexibler als Snapshot-basierte Ansätze von Data-Loading-Tools wie Fivetran, weil sie es Ihnen erlaubt, den exakten Zustand Ihrer Tabelle zu jedem beliebigen Zeitpunkt zu rekonstruieren.
Streams sind Snowflakes Antwort auf internes CDC
Ein Zitat aus der Snowflake-Dokumentation:
Ein Stream-Objekt zeichnet DML-Änderungen (Data Manipulation Language) an Tabellen auf – einschließlich Inserts, Updates und Deletes – sowie Metadaten zu jeder Änderung, sodass auf Basis der geänderten Daten Aktionen ausgeführt werden können.
Schauen wir uns das im Detail an.
In Snowflake ist eine Stream-Tabelle – kurz Stream – eine Menge von Datensätzen aus einer Quelltabelle, die sich seit der letzten Verwendung der Stream-Daten in einer DML-Transaktion verändert haben. Snowflake realisiert das, indem neue Micro-Partitions nachverfolgt werden, die seit dem letzten Konsum des Streams hinzugekommen sind.
Wichtig zu verstehen: Ein Stream lässt sich in der from-Klausel einer SQL-Anweisung abfragen und verhält sich weitgehend wie ein View. Das Besondere: Er liefert genau jene Zeilen aus einer Quelltabelle, die sich seit einem bestimmten Zeitpunkt – dem sogenannten offset – geändert haben. Der offset wird zurückgesetzt, sobald die Stream-Daten in einer DML-Abfrage verwendet werden (Insert, Update, Delete, CTAS).
Das Stream-Offset verstehen
Wenn Sie einen Stream anlegen und direkt daraus selektieren, ist das Standardverhalten: Der Stream ist nach der Initialisierung leer. Fügen Sie anschließend in der Quelltabelle 5 Datensätze ein oder ändern sie, liefert eine Abfrage des Streams 5 Zeilen zurück. Sie können beliebig oft aus dem Stream selektieren, ohne den Offset zu verändern. Der Offset wird erst dann zurückgesetzt, wenn Sie den Stream in einer DML-Anweisung verwenden – Insert, Update, Merge oder CTAS.
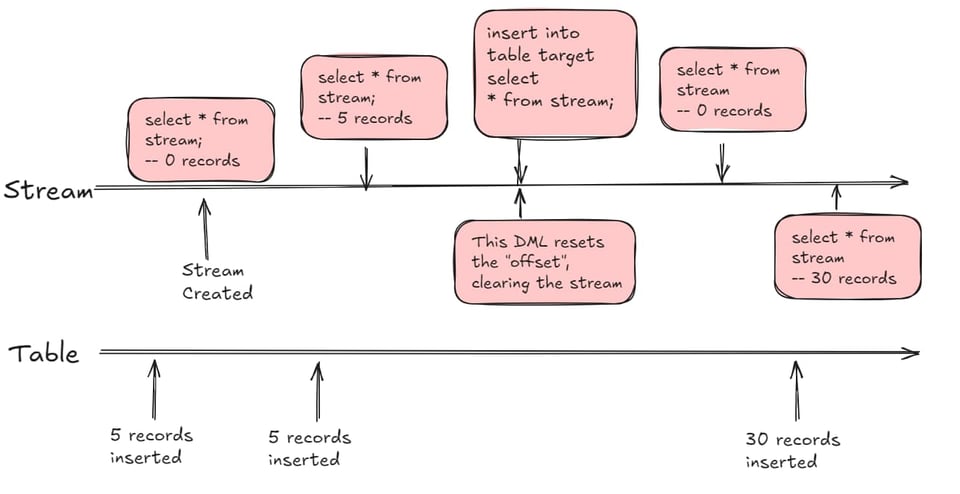
Stream-Nutzung am Beispiel
Quelldaten
Im folgenden Beispiel lege ich einen Stream auf einem View an, weil die Quelltabelle zu viele Spalten in einer ungünstigen Reihenfolge enthält. Sie werden sehen: Streams auf Views anzulegen ist genauso unkompliziert wie auf Tabellen.
Ich habe einen View namens raw_sales_data mit folgender Definition:
create view raw_sales_data as
select
sales_order_id,
name, -- the customer's Full Name
email, -- the customer's email
ordered_at_utc -- unix timestamp in milliseconds
from fake_sales_orders -- the table where data is added
;
Stream anlegen und abfragen
Legen wir einen Stream auf diesem Quell-View an:
create or replace stream sales_stream
on view raw_sales_orders;
Jetzt selektieren wir aus dem Stream und wenden eine kleine Transformation an:
select
sales_order_id as order_id,
name as customer_name,
email as customer_email,
(ordered_at_utc / 1e9)::timestamptz as ordered_at_utc
from
sales_stream;
Da wir an der Quelltabelle nichts verändert oder hinzugefügt haben, ist die Stream-Tabelle leer:
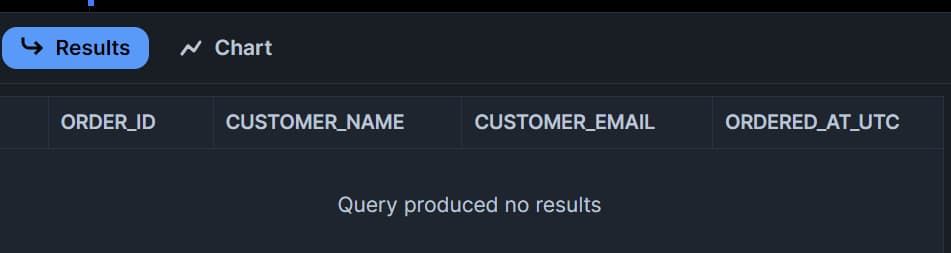
Daten in die Quelle schreiben und Stream abfragen
Ich füge der Tabelle nun über ein Python-Extract/Load-Skript 1000 Zeilen hinzu und selektiere danach erneut aus dem Stream:
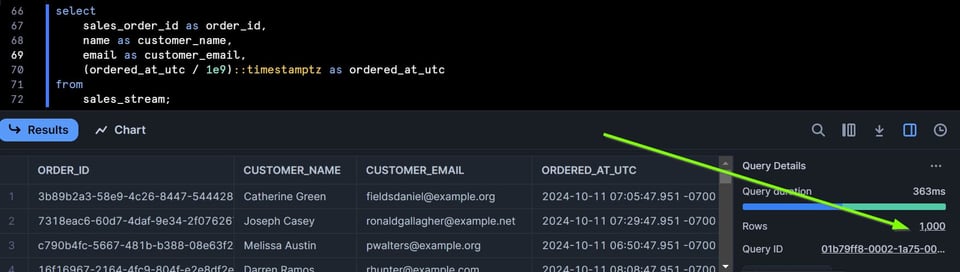
Der Stream enthält jetzt 1000 Zeilen.
Stream-Daten verwenden, um den Offset zurückzusetzen / den Stream zu leeren
Um den Stream zu leeren bzw. den offset zurückzusetzen, muss ich die Stream-Daten in einer DML-Transaktion verwenden. Für dieses einfache Beispiel schreibe ich die Daten in eine temporary table – der einfachste Weg, den Stream zu leeren. In der Praxis werden Sie die Daten in der Regel per merge in eine permanente Zieltabelle übernehmen.
create temp table
clear_the_stream as
(select * from sales_stream);
select count(*) from sales_stream; --now returns 0 since the offset has been reset.
Nach dem "Konsumieren" der Stream-Daten ist der Stream geleert. Es wird ein neuer offset erzeugt, und wir können den Ablauf – Quelldaten ändern, Stream abfragen, Stream konsumieren – beliebig wiederholen.
Quelldaten aktualisieren und löschen
Wir haben gesehen, wie neue Datensätze in die Quelle gelangen – aber wie sieht es mit Updates aus? Aktualisieren wir einen Datensatz und löschen einen anderen.
update fake_sales_orders
-- note: table `fake_sales_orders` is the basis for the view `raw_sales_orders`
set name = 'Jeff Skoldberg'
where sales_order_id = '59472696-660a-4935-bc30-2078ed35f044'
;
delete from fake_sales_orders
where sales_order_id = '4dfc5e0f-4268-4a46-9dbf-816acf48588e'
;
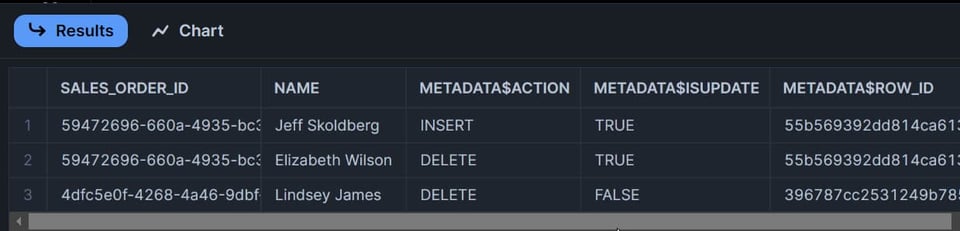
Ich habe also zwei Zeilen in meinen Daten verändert – wie viele Zeilen wird der Stream zurückgeben?
Wenn Sie auf "zwei" getippt haben, liegen Sie falsch 🤔😀. Eine kleine Fangfrage.
Die richtige Antwort lautet drei Zeilen:
- Die aktualisierte Zeile erzeugt zwei Einträge im Stream: einen mit
METADATA$ACTION=DELETEund einen weiteren mitMETADATA$ACTION=INSERT. - Die gelöschte Zeile erscheint als einzelner Eintrag im Stream mit
METADATA$ACTION=DELETE.
select
sales_order_id,
name,
metadata$action,
metadata$isupdate,
metadata$row_id
from
sales_stream;
Zieltabelle aktualisieren
So sieht das SQL aus, mit dem ich den gelöschten Datensatz aus der Zieltabelle entferne und den aktualisierten Datensatz übernehme:
MERGE INTO clear_the_stream AS tgt -- the temp table from earlier
USING (
SELECT *
FROM sales_stream
) AS src
ON tgt.sales_order_id = src.sales_order_id
-- For rows marked as insert or update
WHEN MATCHED AND src.metadata$action = 'INSERT'
THEN UPDATE
SET
tgt.name = src.name
-- you would use all the columns
-- I'm only using the "NAME" field for simplicity,
-- because I know which field was updated
Code ausklappen
Nach Ausführung der Abfrage prüfen wir das Ergebnis:
select * from
clear_the_stream --the temp table acting as my target table
where sales_order_id in -- the two rows I manipulated in the source
(
'4dfc5e0f-4268-4a46-9dbf-816acf48588e',
'59472696-660a-4935-bc30-2078ed35f044'
);

Die sales_order_id, die mit 4df... beginnt, wurde korrekt gelöscht, und bei der ID 594... enthält das Feld name jetzt Jeff Skoldberg. Passt!
Wann SHOW_INITIAL_ROWS sinnvoll ist
Bisher haben wir Streams mit dem Standardverhalten erstellt. Es gibt jedoch einen wichtigen optionalen Parameter namens show_initial_rows, den Sie beim Anlegen eines Streams setzen können:
create or replace stream my_stream on table my_table
show_initial_rows = TRUE
In diesem Fall ist der Stream nach der Erstellung nicht leer. Beim Selektieren aus my_stream erhalten Sie alle noch nicht verarbeiteten Zeilen: jene, die schon vor dem Anlegen des Streams existierten, plus alle Daten, die seitdem geändert oder neu hinzugekommen sind.
Diese Option löst einige Probleme, die sonst beim Aufbau vollständiger Downstream-Ziele entstehen würden. Ohne sie bräuchten Sie einen Workaround – etwa ein Union aus bestehenden und geänderten Datensätzen. Für die meisten Data-Modeling-Szenarien ist show_initial_rows aber genau das, was Sie brauchen.
Stream-Metadatenspalten
Wir haben die Stream-Metadatenspalten bereits genutzt – schauen wir sie uns nun einzeln an. Aus Effizienz- und Vollständigkeitsgründen habe ich diesen Abschnitt direkt aus der Snowflake-Dokumentation übernommen:
**METADATA$ACTION:**\\ **Gibt die aufgezeichnete DML-Operation an (INSERT, DELETE).**METADATA$ISUPDATE:**\\ **Gibt an, ob die Operation Teil eines UPDATE-Statements war. Updates an Zeilen im Quellobjekt werden im Stream als Paar aus DELETE- und INSERT-Datensätzen abgebildet, deren Metadatenspalte METADATA$ISUPDATE den Wert TRUE hat. Beachten Sie: Streams erfassen die Differenz zwischen zwei Offsets. Wird eine Zeile hinzugefügt und im aktuellen Offset anschließend aktualisiert, ist die Delta-Änderung eine neue Zeile. Die METADATA$ISUPDATE-Zeile enthält dann den Wert FALSE.**METADATA$ROW_ID:**\\ **Gibt die eindeutige und unveränderliche ID der Zeile an, mit der sich Änderungen an bestimmten Zeilen über die Zeit nachverfolgen lassen.
Streams in einem Task verwenden
Ein häufiger Anwendungsfall ist, den Konsum eines Streams in einem Snowflake-Task einzuplanen. Dazu können Sie das Snowflake MERGE-Statement direkt in die Task-Definition einsetzen:
CREATE TASK consume_the_stream
SCHEDULE = 'USING CRON 0 9-17 * * SUN America/Los_Angeles'
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
AS
-- copy / paste the merge statement from above
;
alter task consume_the_stream resume;
Der Task läuft täglich von 9 bis 17 Uhr.
Alternativ packen Sie das Merge-Statement in eine Snowflake Stored Procedure und lassen den Task die Procedure ausführen. So bleibt Ihre Task-Definition übersichtlich.
Stream-Typen
Snowflake kennt drei Stream-Typen:
- Standard Streams: erfassen alle Inserts, Updates und Deletes auf einer Quelle. Diesen Typ haben wir oben verwendet.
- Append Only: erfasst ausschließlich eingefügte Zeilen der Quelle. Beispiel: Wir starten mit einem frischen Offset und keinen Daten im Stream. In der Quelltabelle werden 5 Datensätze eingefügt, 5 weitere aktualisiert und nochmals 5 gelöscht. Der resultierende Stream enthält nur die 5 eingefügten Datensätze. Beispielverwendung:
create or replace stream my_stream
on table my_table
append_only=true;
3. Insert Only: Ähnlich wie Append Only, allerdings für Dateien im Cloud-Storage hinter External Tables, Iceberg-Tabellen oder Dynamic External Tables. Daten in neu hinzugefügten Dateien tauchen im Stream auf. Das Entfernen einer Datei aus dem Cloud-Storage hat keinen Einfluss auf den Stream. Beispielverwendung:
create or replace stream my_stream
on external table my_external_table
insert_only=TRUE;
Mit STREAM\_HAS\_DATA prüfen, ob ein Stream Daten enthält
Wir haben bereits gesehen, dass Sie mit select count(*) from sales_stream oder select * from sales_stream prüfen können, ob ein Stream Daten enthält. Daneben gibt es jedoch eine praktische Systemfunktion: SYSTEM$STREAM_HAS_DATA. Sie lässt sich in einer Select-Anweisung verwenden und gibt – je nachdem, ob der Stream Daten enthält – TRUE oder FALSE zurück.
select
SYSTEM$STREAM_HAS_DATA('SALES_STREAM')
as stream_has_data;
-- returns FALSE since we just reset the offset by consuming the stream in DML.
CHANGES: die schreibgeschützte Alternative zu Streams
Sobald Change Tracking aktiviert ist – entweder per alter table <table_name> set change_tracking = TRUE; oder create stream <stream_name> on table <table_name> – können Sie Änderungen ab einem bestimmten Zeitpunkt abfragen, selbst wenn der offset bereits zurückgesetzt wurde.
Mit dem Schlüsselwort changes in der from-Klausel und einem at (timestamp => <timestamp> sehen Sie alle Änderungen seit diesem Zeitpunkt – ohne den offset zurückzusetzen.
set ts = dateadd('hours', -3, current_timestamp);
SELECT *
FROM fake_sales_orders
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => $ts);
Die Abfrage oben zeigt alle Änderungen in der Tabelle aus den letzten 3 Stunden. Die Metadatenspalten werden mitgeliefert, sodass Sie sie in Ihrem Transformationsprozess weiterverwenden können.
Wann CHANGES statt Streams sinnvoll ist
Der Einsatz von changes kann sich anbieten, wenn:
- Sie mehrere ELT-Consumer auf derselben Quelle haben und nicht mehrere Streams verwalten möchten.
- Sie Daten aus Snowflake heraus ziehen. Beispiel: Beim Laden von Daten aus Snowflake nach Mixpanel oder Amplitude ist es sinnvoll, einen eigenen Cursor-Timestamp zu speichern und Daten ab diesem Zeitpunkt zu selektieren. Die Gründe:
- In Snowflake gibt es eventuell keine DML-Aktion, mit der sich ein Stream leeren ließe.
- Sie möchten flexibel bleiben, um Teilmengen erneut laden zu können.
Das Thema "Selektieren aus CHANGES" füllt locker einen eigenen Blogpost, denn die Beispiele und Anwendungsfälle sind zahlreich – hier nur kurz der Vollständigkeit halber erwähnt.
Dynamic Tables statt Streams einsetzen
Bevor Sie einen neuen Transformationsprozess auf Basis von Streams aufsetzen, lohnt sich ein Blick auf Snowflakes native Dynamic Tables – oft bieten sie eine einfachere Lösung für Ihren Anwendungsfall. Vieles lässt sich damit ähnlich umsetzen, doch es kommt immer auf das konkrete Ziel an. Wenn Sie gezielt neue oder geänderte Datensätze isolieren wollen, sind Streams und CHANGES erstklassige Werkzeuge!
Frequently asked
questions
Wie hoch sind die Kosten für Streams?
Die wesentlichen Kosten bei Streams sind die Compute-Kosten beim Abfragen des Streams oder beim Einsatz in einem Transformationsschritt.
Eine Stream-Tabelle selbst enthält keine Daten, auch wenn Sie sie wie eine Tabelle abfragen können. Da die geänderten Daten nicht repliziert werden, fallen für Streams kaum Speicherkosten an. Aktivieren Sie Change Tracking auf einer Tabelle, werden der Quelltabelle die drei Metadatenspalten hinzugefügt. Die einzigen zusätzlichen Speicherkosten ergeben sich aus dem geringen Platzbedarf dieser Spalten.
Hinweise zu Time Travel und Datenaufbewahrung finden Sie hier. Eine Auffrischung zu den Snowflake-Kosten bietet der Snowflake Pricing & Billing Guide von SELECT.
Lassen sich mehrere Streams auf derselben Tabelle anlegen?
Sie können beliebig viele Streams auf einer Tabelle anlegen. Best Practice ist, dass jeder Consumer bzw. jede Zieltabelle einen eigenen Stream hat. Verwenden Sie nicht einen einzigen Stream, um in zwei verschiedene Zieltabellen zu schreiben – der offset würde dabei zurückgesetzt und Ihre Daten würden auseinanderlaufen. Wenn Sie eine Quelltabelle auf 5 verschiedene Arten transformieren möchten, legen Sie problemlos 5 Streams an.
Welche Einschränkungen gibt es?
Wie das Beispiel oben zeigt, lässt sich ein Stream sowohl auf einem View als auch auf einer Tabelle aktivieren. Es gibt jedoch ein paar Einschränkungen:
- Die zugrunde liegenden Tabellen müssen native Snowflake-Tabellen sein.
- Verschachtelte Views, CTEs und Subqueries werden unterstützt. Die vollständig aufgelöste SQL-Abfrage darf jedoch nur folgende Operationen enthalten: Projektionen, Filter, Union All, Inner Join oder Cross Join. Das heißt:
unionohneallundleft outer joinwerden nicht unterstützt.
Weitere Details finden Sie in der Dokumentation.
Wie lassen sich Streams verwalten?
Alle Streams in Ihrem Account, Ihrer Datenbank oder Ihrem Schema finden Sie mit einem dieser Befehle:
show streams in account;
show streams in database <db_name>;
show streams in schema <qualified_schema_name>;
show streams; -- uses your worksheet or connection context / default schema.
In der UI finden Sie Streams innerhalb eines Schemas:
Streams lassen sich mit dem drop-Befehl entfernen: drop stream db.schema.stream_name;
Jetzt sollten Sie sich sicher fühlen, Streams produktiv einzusetzen! Streams sind ein hervorragendes Mittel, um neue oder geänderte Daten in großen Quelltabellen zu erfassen. Am häufigsten kommen sie zum Einsatz, wenn die Quelldaten sehr umfangreich sind und Sie eine zuverlässige Methode brauchen, um neue oder geänderte Datensätze inkrementell zu erfassen.
Jeff ist Data- und Analytics-Consultant mit über 15 Jahren Erfahrung darin, Insights zu automatisieren und Geschäftsprozesse datengetrieben zu steuern. Technologisch ist er auf Snowflake + dbt + Tableau spezialisiert. Fachlich bringt er Erfahrung aus Versorgungswirtschaft, klinischen Studien, Verlagswesen, CPG und Fertigung mit. Kontakt jederzeit gerne unter [email protected].