Introdução a Snowflake Streams e Change Data Capture
Um Snowflake Stream é responsável pelo Change Data Capture (CDC) e ajuda os usuários a entender o que mudou em uma tabela desde determinado momento. Mas o que é CDC?
De forma simples, CDC é o processo de responder à pergunta: "o que mudou na minha fonte de dados desde a última vez que carreguei ou processei esses dados?"
Falando de forma mais técnica, CDC é um método para identificar e capturar alterações feitas nos dados de uma fonte. Para isso, ele acompanha todas as inserções, atualizações e exclusões que acontecem em uma determinada tabela do banco. Essa forma de rastrear alterações é muito mais flexível do que as abordagens baseadas em snapshots usadas em ferramentas de carga de dados como o Fivetran, pois permite reproduzir o estado exato da sua tabela em qualquer ponto no tempo.
Streams são a resposta do Snowflake para CDC interno
Citando a documentação do Snowflake:
Um objeto stream registra as alterações de DML (data manipulation language) feitas em tabelas, incluindo inserções, atualizações e exclusões, além de metadados sobre cada alteração, para que ações possam ser executadas com base nos dados alterados.
Vamos destrinchar isso um pouco mais.
No Snowflake, uma Stream Table, chamada apenas de Stream, é um conjunto de registros de uma tabela de origem que sofreram alterações desde a última vez em que os dados do stream foram usados em uma transação DML. O Snowflake faz isso rastreando novas micro-partitions adicionadas desde a última vez em que o stream foi consumido.
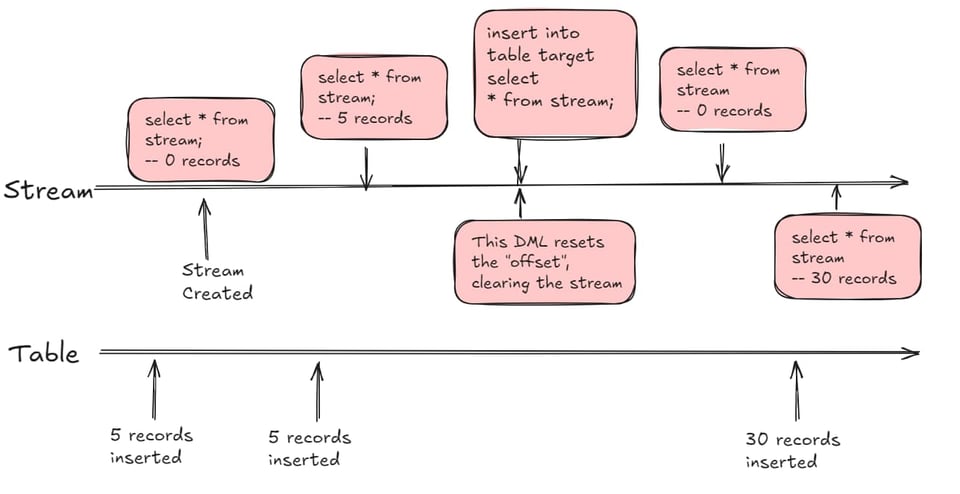
O primeiro conceito importante sobre um stream é que ele pode ser consultado na cláusula from de uma instrução SQL e se comporta de forma muito parecida com uma view. O que o torna especial é o fato de retornar as linhas de uma tabela de origem que mudaram desde um ponto no tempo, chamado de offset. O offset é reiniciado quando você usa os dados do stream em uma query DML (insert, update, delete, CTAS).
Entendendo o offset do Stream
Quando você cria um stream e faz um select nele logo em seguida, o comportamento padrão é que o stream esteja vazio na inicialização. Se você inserir ou alterar 5 registros na tabela de origem, consultar o stream retornará 5 registros. Você pode fazer select no stream sem alterar o offset. O offset só é reiniciado quando você consulta o stream em uma instrução DML — insert, update, merge ou CTAS.
Exemplo de uso de Stream
Dados de origem
Neste exemplo, vou criar um stream em uma view, porque a tabela de origem tem colunas demais e elas estão em uma ordem esquisita. Você vai ver que criar streams em views é fácil; o processo é bem parecido com criar streams em tabelas.
Tenho uma view chamada raw_sales_data definida assim:
create view raw_sales_data as
select
sales_order_id,
name, -- nome completo do cliente
email, -- email do cliente
ordered_at_utc -- timestamp unix em milissegundos
from fake_sales_orders -- a tabela onde os dados são adicionados
;
Criar e consultar o Stream
Vamos criar um stream sobre essa view de origem:
create or replace stream sales_stream
on view raw_sales_orders;
Agora vamos fazer um select no stream e aplicar uma transformação leve:
select
sales_order_id as order_id,
name as customer_name,
email as customer_email,
(ordered_at_utc / 1e9)::timestamptz as ordered_at_utc
from
sales_stream;
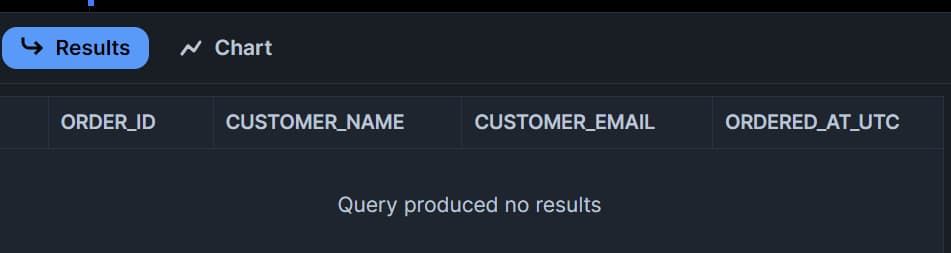
Como não manipulamos nem adicionamos dados na tabela de origem, a tabela do stream vai estar vazia:
Adicionar dados na origem e consultar o stream
Vou adicionar 1000 linhas à tabela rodando um script Python de Extract/Load e depois consultar o stream novamente:
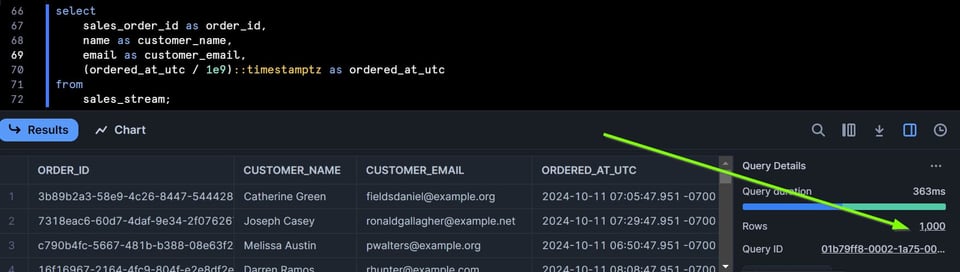
Agora o stream tem 1000 linhas.
Usar os dados do stream para reiniciar o offset / limpar o stream
Para limpar o stream, ou reiniciar o offset, preciso usar os dados do stream em uma transação DML. Neste exemplo simples, vou inserir os dados em uma temporary table, que é a forma mais fácil de limpar o stream. Mas, na prática, você provavelmente vai fazer um merge desses dados em uma tabela de destino permanente.
create temp table
clear_the_stream as
(select * from sales_stream);
select count(*) from sales_stream; --agora retorna 0, já que o offset foi reiniciado.
Depois de "consumir" os dados do stream, ele é limpo. Um novo offset é criado, e podemos repetir o processo de manipular os dados de origem, consultar o stream e consumi-lo.
Atualizar e excluir dados da origem
Vimos como adicionar novos registros à origem, mas e quanto a atualizar os dados da origem? Vamos atualizar um único registro e excluir outro.
update fake_sales_orders
-- observação: a tabela `fake_sales_orders` é a base da view `raw_sales_orders`
set name = 'Jeff Skoldberg'
where sales_order_id = '59472696-660a-4935-bc30-2078ed35f044'
;
delete from fake_sales_orders
where sales_order_id = '4dfc5e0f-4268-4a46-9dbf-816acf48588e'
;
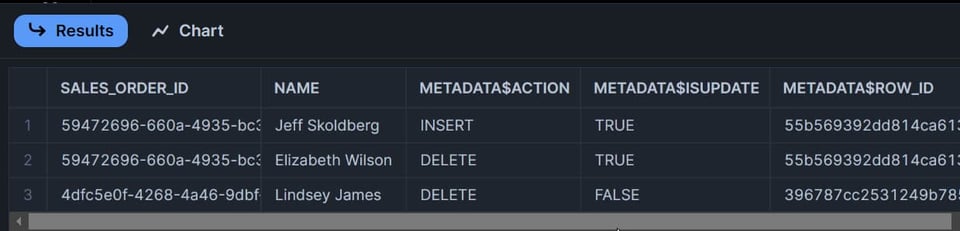
Agora que alterei duas linhas nos meus dados, quantas linhas você acha que o stream vai retornar?
Se você pensou em "duas"… errou 🤔😀. Foi uma pegadinha.
A resposta certa é três linhas:
- A linha atualizada aparece como duas linhas no stream. Uma com
METADATA$ACTION=DELETEe outra comMETADATA$ACTION=INSERT. - A linha excluída aparece como um único registro no stream, com
METADATA$ACTION=DELETE
select
sales_order_id,
name,
metadata$action,
metadata$isupdate,
metadata$row_id
from
sales_stream;
Atualizando a tabela de destino
Aqui está o SQL que eu usaria para excluir o registro removido no destino e atualizar o registro modificado:
MERGE INTO clear_the_stream AS tgt -- a temp table criada antes
USING (
SELECT *
FROM sales_stream
) AS src
ON tgt.sales_order_id = src.sales_order_id
-- Para linhas marcadas como insert ou update
WHEN MATCHED AND src.metadata$action = 'INSERT'
THEN UPDATE
SET
tgt.name = src.name
-- você usaria todas as colunas
-- estou usando só o campo "NAME" para simplificar,
-- já que sei qual campo foi atualizado
Expandir Código
Depois de rodar a query, vamos conferir os resultados:
select * from
clear_the_stream --a temp table funcionando como minha tabela de destino
where sales_order_id in -- as duas linhas que manipulei na origem
(
'4dfc5e0f-4268-4a46-9dbf-816acf48588e',
'59472696-660a-4935-bc30-2078ed35f044'
);

Ele excluiu certinho o sales_order_id que começa com 4df... e atualizou o id 594..., então o campo name agora mostra Jeff Skoldberg. Show!
Quando usar SHOW_INITIAL_ROWS
Até aqui criamos streams com o comportamento padrão. Existe um parâmetro opcional importante chamado show_initial_rows que pode ser definido na criação do stream:
create or replace stream my_stream on table my_table
show_initial_rows = TRUE
Nesse caso, o stream não vai estar vazio quando for criado. Ao fazer um select em my_stream, ele conterá todas as linhas ainda não processadas: as que já existiam antes da criação do stream e quaisquer dados que tenham mudado ou chegado depois disso.
Essa propriedade resolve alguns desafios que existiriam ao montar destinos completos a jusante. Sem ela, seria preciso recorrer a uma solução alternativa; por exemplo, fazer um union dos registros existentes com os registros alterados poderia ser uma abordagem. Mas, na maioria dos cenários de modelagem de dados, ativar show_initial_rows é exatamente o que você vai querer fazer.
Colunas de metadados do Stream
Já estamos usando as colunas de metadados do Stream, mas vale a pena parar para definir cada uma delas como deve ser. Por uma questão de eficiência e completude, copiei esta seção diretamente da documentação do Snowflake:
**METADATA$ACTION:**\\ **Indica a operação DML registrada (INSERT, DELETE).**METADATA$ISUPDATE:**\\ **Indica se a operação fazia parte de uma instrução UPDATE. Atualizações em linhas do objeto de origem são representadas como um par de registros DELETE e INSERT no stream, com a coluna de metadados METADATA$ISUPDATE definida como TRUE. Observe que os streams registram as diferenças entre dois offsets. Se uma linha for adicionada e depois atualizada dentro do offset atual, a diferença líquida será uma nova linha. A linha METADATA$ISUPDATE registra o valor FALSE.**METADATA$ROW_ID:**\\ **especifica o ID único e imutável da linha, que pode ser usado para rastrear alterações em linhas específicas ao longo do tempo.
Usando streams em uma task
Um caso de uso comum é agendar o consumo de um stream em uma task do Snowflake. Para isso, você pode colocar a instrução MERGE do Snowflake diretamente na definição da task:
CREATE TASK consume_the_stream
SCHEDULE = 'USING CRON 0 9-17 * * SUN America/Los_Angeles'
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
AS
-- copiar / colar a instrução merge mostrada acima
;
alter task consume_the_stream resume;
A task acima vai rodar das 9h às 17h todos os dias.
Outra opção é encapsular a instrução merge em uma stored procedure do Snowflake e fazer a task executar essa procedure. Isso mantém a definição da task organizada.
Tipos de streams
O Snowflake tem 3 tipos de streams:
- Standard Streams: rastreia todas as inserções, atualizações e exclusões em uma origem. Foi o que usamos no passo a passo acima.
- Append Only: rastreia apenas linhas inseridas na origem. Exemplo: suponha que temos um offset zerado e nenhum dado no stream. 5 registros são adicionados à tabela de origem, outros 5 são atualizados e mais 5 são excluídos. O stream resultante vai conter apenas os 5 registros inseridos. Exemplo de uso:
create or replace stream my_stream
on table my_table
append_only=true;
3. Insert Only: é parecido com Append Only, mas vale para arquivos em cloud storage por trás de External Tables, Iceberg tables ou Dynamic External Tables. Dados em novos arquivos adicionados ao cloud storage vão aparecer no stream. Remover um arquivo do cloud storage não afeta o stream. Exemplo de uso:
create or replace stream my_stream
on external table my_external_table
insert_only=TRUE;
Verificando se um stream tem dados com STREAM\_HAS\_DATA
Já vimos que dá para verificar se um stream tem dados com algo como select count(*) from sales_stream ou select * from sales_stream. Mas existe uma função de sistema útil que vale conhecer: SYSTEM$STREAM_HAS_DATA. Você pode usá-la em uma instrução select e ela retorna TRUE ou FALSE dependendo de o stream ter dados ou não.
select
SYSTEM$STREAM_HAS_DATA('SALES_STREAM')
as stream_has_data;
-- retorna FALSE, já que acabamos de reiniciar o offset consumindo o stream em DML.
CHANGES: uma alternativa somente leitura aos streams
Quando o change tracking está ativado, seja com alter table <table_name> set change_tracking = TRUE; ou com create stream <stream_name> on table <table_name>, você pode consultar as alterações a partir de um determinado ponto no tempo, mesmo que o offset tenha sido reiniciado.
Adicionando a palavra-chave changes na cláusula from e passando um at (timestamp => <timestamp>, você consegue ver todas as alterações ocorridas desde aquele timestamp, sem reiniciar o offset.
set ts = dateadd('hours', -3, current_timestamp);
SELECT *
FROM fake_sales_orders
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => $ts);
A query acima mostra todas as alterações na tabela nas últimas 3 horas. As colunas de metadados aparecem no resultado da query, então você pode usá-las no seu processo de transformação.
Quando usar changes em vez de streams
Pode ser uma boa ideia usar changes se:
- Você tem vários consumidores ELT na mesma origem e não quer gerenciar vários streams.
- Você está extraindo dados para fora do Snowflake. Por exemplo, ao carregar dados do Snowflake para o Mixpanel ou o Amplitude, faz sentido armazenar seu próprio cursor de timestamp e selecionar os dados que mudaram desde aquele timestamp. Isso porque:
- Talvez você não tenha nenhuma ação DML dentro do Snowflake para limpar um stream.
- Você quer flexibilidade para recarregar uma parte específica dos dados.
O tema "selecting from changes" é grande o suficiente para virar um post próprio, já que os exemplos e casos de uso são muitos; estou só mencionando rapidamente aqui para fins de completude.
Usando Dynamic Tables em vez de Streams
Antes de criar um novo processo de transformação com streams, pode valer a pena considerar se o recurso nativo de Dynamic Tables do Snowflake oferece uma solução mais simples para o seu caso. Muitas vezes dá para fazer algo parecido usando uma dynamic table no Snowflake, mas tudo depende do que você quer alcançar. Se o objetivo é isolar registros novos ou alterados, Streams e Changes são ótimas ferramentas para se ter à mão!
Frequently asked
questions
Quanto custam os streams?
O principal custo que você terá com Streams é o de compute, associado a consultar o stream ou usá-lo em uma etapa de transformação.
Uma stream table em si não contém dados, embora você possa consultá-la como se contivesse. Como os dados alterados não são replicados, os streams têm custos de storage muito baixos. Quando você ativa o change tracking em uma tabela, as três colunas de metadados são adicionadas à tabela de origem. O único custo adicional de storage é o pequeno espaço necessário para essas colunas extras.
Confira aqui as observações sobre time travel e tempo de retenção de dados. Para uma revisão dos custos do Snowflake, veja o Snowflake Pricing & Billing Guide da SELECT.
Dá para criar vários streams na mesma tabela?
Você pode criar quantos streams quiser em uma tabela. A boa prática é que cada consumidor ou tabela de destino tenha um stream exclusivo associado. Não use um único stream para gravar em duas tabelas diferentes, porque o offset vai ser reiniciado e seus dados vão ficar fora de sincronia. Se você quiser transformar uma mesma tabela de origem de 5 maneiras diferentes, pode criar 5 streams sem problemas.
Quais são as limitações?
Como vimos no exemplo acima, dá para ativar um stream em uma view, assim como em uma tabela. Mas existem algumas limitações:
- As tabelas subjacentes precisam ser tabelas nativas do Snowflake.
- Views aninhadas, CTEs e subqueries são suportadas. Mas a query SQL totalmente expandida só pode usar estas operações: projeções, filtros, union all, inner join ou cross join. Ou seja,
unionsemalleleft outer joinnão são suportados.
Para mais detalhes, consulte a documentação.
Como gerenciar streams?
Você pode encontrar todos os streams na sua conta, banco de dados ou schema com qualquer um destes comandos:
show streams in account;
show streams in database <db_name>;
show streams in schema <qualified_schema_name>;
show streams; -- usa o contexto da sua worksheet ou conexão / schema padrão.
Na interface, dá para encontrar os streams dentro de um schema:
Para excluir um stream, use o comando drop: drop stream db.schema.stream_name;
Esperamos que agora você se sinta confiante para usar streams em produção! Streams são uma ótima maneira de capturar dados novos ou alterados em tabelas de origem grandes. Eles costumam ser usados quando os dados de origem são bastante volumosos e você quer uma forma confiável de capturar de maneira incremental os registros novos ou modificados.
Jeff é Consultor de Dados e Analytics, com mais de 15 anos de experiência em automatizar insights e usar dados para conduzir processos de negócio. Do ponto de vista de tecnologia, é especialista em Snowflake + dbt + Tableau. Já em termos de áreas de negócio, tem experiência em Concessionárias Públicas, Estudos Clínicos, Editorial, CPG e Manufatura. Fale com ele a qualquer momento: [email protected].