Introduzione agli Streams di Snowflake e al Change Data Capture
Uno Stream di Snowflake si occupa del Change Data Capture (CDC) e aiuta a capire cosa è cambiato in una tabella da un certo momento in poi. Ma cos'è il CDC?
In parole semplici, il CDC è il processo che risponde alla domanda: "cosa è cambiato nella mia sorgente dati dall'ultimo caricamento o elaborazione?"
In termini più tecnici, il CDC è un metodo per identificare e catturare le modifiche apportate ai dati in una sorgente. Lo fa tracciando tutti gli inserimenti, aggiornamenti ed eliminazioni che avvengono su una determinata tabella di database. Questa modalità di tracciamento è molto più flessibile rispetto agli approcci basati su snapshot usati dagli strumenti di data loading come Fivetran, perché consente di riprodurre lo stato esatto della tabella in qualsiasi momento.
Gli Streams sono la risposta di Snowflake al CDC interno
Citando la documentazione di Snowflake:
Un oggetto stream registra le modifiche in linguaggio di manipolazione dati (DML) effettuate sulle tabelle, inclusi insert, update e delete, oltre ai metadati di ciascuna modifica, in modo da poter intraprendere azioni sui dati modificati.
Vediamo meglio nel dettaglio.
In Snowflake, una Stream Table — chiamata semplicemente Stream — è l'insieme dei record di una tabella sorgente che sono cambiati dall'ultima volta in cui i dati dello stream sono stati utilizzati in una transazione DML. Snowflake ottiene questo risultato tracciando le nuove micro-partitions aggiunte dopo l'ultimo consumo dello stream.
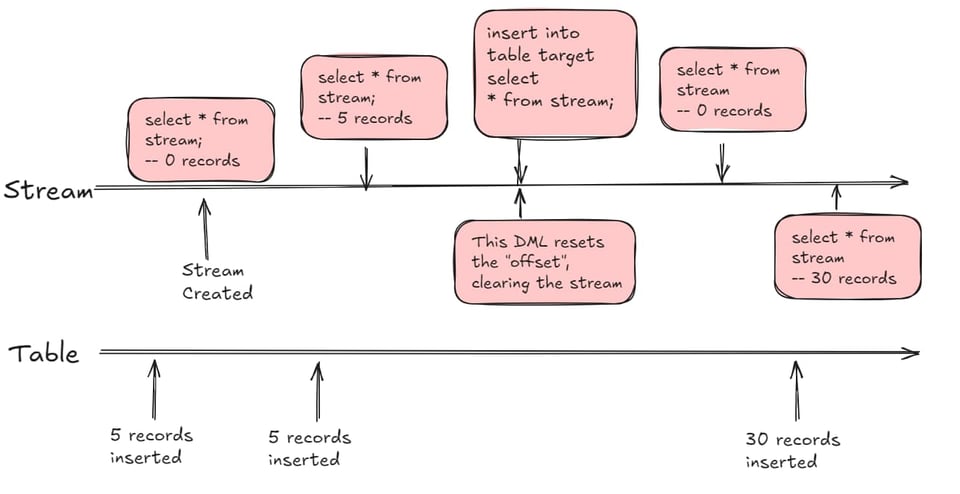
Il primo concetto importante da capire è che uno stream può essere interrogato nella clausola from di un'istruzione SQL e si comporta in modo molto simile a una view. La sua particolarità è che restituisce le righe di una tabella sorgente che sono cambiate a partire da un certo momento, chiamato offset. L'offset si reimposta usando i dati dello stream in una query DML (insert, update, delete, CTAS).
Capire l'offset dello Stream
Quando si crea uno stream e lo si interroga subito, per impostazione predefinita lo stream è vuoto al momento dell'inizializzazione. Se poi si inseriscono o si modificano 5 record nella tabella sorgente, l'interrogazione dello stream restituirà 5 record. Si può fare una select dallo stream senza modificare l'offset: l'offset si reimposta solo quando si interroga lo stream con un'istruzione DML, ovvero insert, update, merge o CTAS.
Esempio di utilizzo di uno Stream
Dati di origine
In questo esempio creerò uno stream su una view, perché la tabella sorgente ha troppe colonne e in un ordine poco pratico. Vedrete che creare stream sulle view è semplice: il procedimento è molto simile a quello per le tabelle.
Ho una view chiamata raw_sales_data definita così:
create view raw_sales_data as
select
sales_order_id,
name, -- the customer's Full Name
email, -- the customer's email
ordered_at_utc -- unix timestamp in milliseconds
from fake_sales_orders -- the table where data is added
;
Creare e interrogare lo Stream
Creiamo uno stream su questa view sorgente:
create or replace stream sales_stream
on view raw_sales_orders;
Facciamo una select dallo stream applicando una leggera trasformazione:
select
sales_order_id as order_id,
name as customer_name,
email as customer_email,
(ordered_at_utc / 1e9)::timestamptz as ordered_at_utc
from
sales_stream;
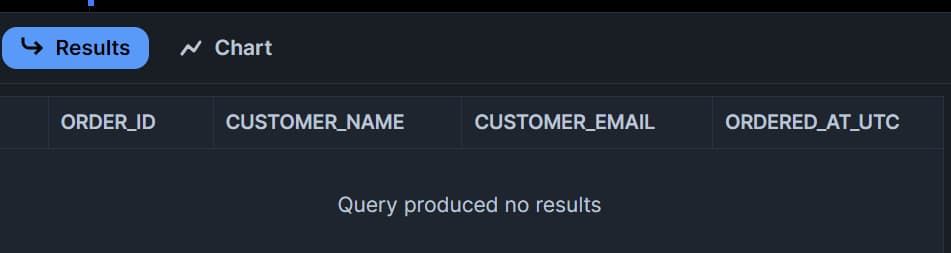
Dato che non abbiamo modificato né aggiunto dati nella tabella sorgente, la stream table sarà vuota:
Aggiungere dati alla sorgente e interrogare lo stream
Aggiungerò 1000 righe alla tabella eseguendo uno script Python di Extract/Load e poi farò di nuovo una select sullo stream:
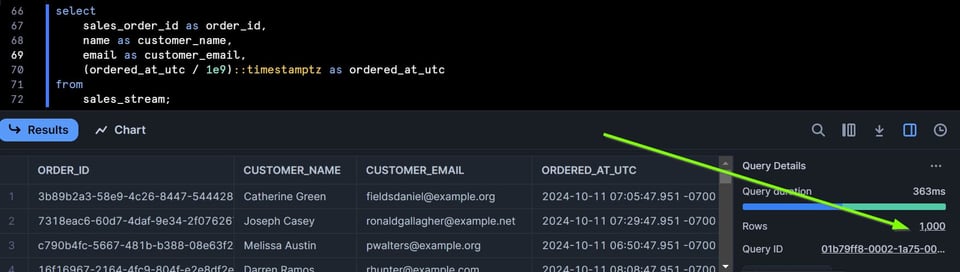
Lo stream ora contiene 1000 righe.
Usare i dati dello stream per resettare l'offset / svuotare lo stream
Per svuotare lo stream, ovvero resettare l'offset, devo usare i dati dello stream in una transazione DML. In questo semplice esempio inserirò i dati in una temporary table: è il modo più rapido per svuotare lo stream. Nella pratica, però, è più probabile che si esegua un merge di questi dati in una tabella di destinazione permanente.
create temp table
clear_the_stream as
(select * from sales_stream);
select count(*) from sales_stream; --now returns 0 since the offset has been reset.
Dopo aver "consumato" i dati dello stream, lo stream risulta svuotato. Viene creato un nuovo offset e possiamo ripetere il ciclo: modificare i dati sorgente, interrogare lo stream e consumarlo.
Aggiornare ed eliminare dati sorgente
Abbiamo visto come aggiungere nuovi record ai dati sorgente, ma cosa succede se li aggiorniamo? Aggiorniamo un record ed eliminiamone un altro.
update fake_sales_orders
-- note: table `fake_sales_orders` is the basis for the view `raw_sales_orders`
set name = 'Jeff Skoldberg'
where sales_order_id = '59472696-660a-4935-bc30-2078ed35f044'
;
delete from fake_sales_orders
where sales_order_id = '4dfc5e0f-4268-4a46-9dbf-816acf48588e'
;
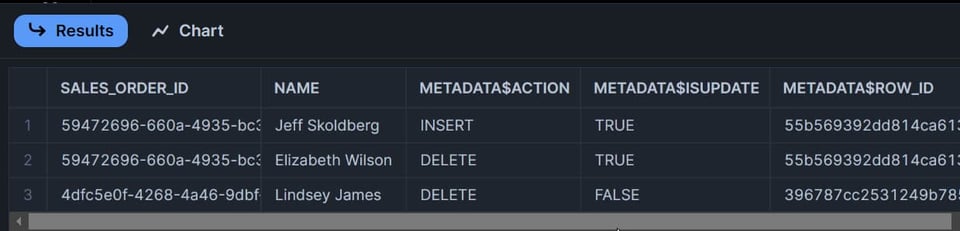
Ora che ho modificato due righe dei miei dati, quante righe pensate restituirà lo stream?
Se avete risposto "due"… avete sbagliato 🤔😀. Era una domanda trabocchetto.
La risposta corretta è tre righe:
- La riga aggiornata produrrà due righe nello stream. Una sarà contrassegnata con
METADATA$ACTION=DELETEe la seconda conMETADATA$ACTION=INSERT. - La riga eliminata comparirà come singolo record nello stream con
METADATA$ACTION=DELETE
select
sales_order_id,
name,
metadata$action,
metadata$isupdate,
metadata$row_id
from
sales_stream;
Aggiornare la tabella di destinazione
Ecco l'SQL che userei per eliminare dalla destinazione il record cancellato e aggiornare quello modificato:
MERGE INTO clear_the_stream AS tgt -- the temp table from earlier
USING (
SELECT *
FROM sales_stream
) AS src
ON tgt.sales_order_id = src.sales_order_id
-- For rows marked as insert or update
WHEN MATCHED AND src.metadata$action = 'INSERT'
THEN UPDATE
SET
tgt.name = src.name
-- you would use all the columns
-- I'm only using the "NAME" field for simplicity,
-- because I know which field was updated
Espandi il codice
Eseguita la query, verifichiamo i risultati:
select * from
clear_the_stream --the temp table acting as my target table
where sales_order_id in -- the two rows I manipulated in the source
(
'4dfc5e0f-4268-4a46-9dbf-816acf48588e',
'59472696-660a-4935-bc30-2078ed35f044'
);

Ha eliminato correttamente il sales_order_id che inizia con 4df... e ha aggiornato l'id 594..., così che il campo name ora riporti Jeff Skoldberg. Ottimo!
Quando usare SHOW_INITIAL_ROWS
Finora abbiamo creato stream con il comportamento predefinito. Esiste però un parametro opzionale importante, show_initial_rows, che si può impostare in fase di creazione dello stream:
create or replace stream my_stream on table my_table
show_initial_rows = TRUE
In questo caso, lo stream non sarà vuoto al momento della creazione. Quando si esegue una select su my_stream, esso conterrà tutte le righe non ancora elaborate: quelle già esistenti prima della creazione dello stream e tutti i dati cambiati o arrivati nel frattempo.
Questa proprietà risolve alcune problematiche che si presenterebbero altrimenti nella costruzione di destinazioni downstream complete. Senza, servirebbe una soluzione alternativa: ad esempio, fare l'union tra i record esistenti e quelli modificati. Nella maggior parte degli scenari di data modeling, però, abilitare show_initial_rows sarà esattamente ciò che vi serve.
Colonne di metadati dello Stream
Abbiamo già usato le colonne di metadati dello Stream, ma vale la pena definirle correttamente. Per efficienza e completezza, riportiamo questa sezione direttamente dalla documentazione di Snowflake:
**METADATA$ACTION:**\\ **Indica l'operazione DML (INSERT, DELETE) registrata.**METADATA$ISUPDATE:**\\ **Indica se l'operazione faceva parte di un'istruzione UPDATE. Gli aggiornamenti delle righe nell'oggetto sorgente sono rappresentati come una coppia di record DELETE e INSERT nello stream, con la colonna di metadati METADATA$ISUPDATE impostata a TRUE. Va notato che gli stream registrano le differenze tra due offset. Se una riga viene aggiunta e poi aggiornata nell'offset corrente, il delta è una nuova riga. La riga METADATA$ISUPDATE registra il valore FALSE.**METADATA$ROW_ID:**\\ **specifica l'ID univoco e immutabile della riga, che può essere usato per tracciare nel tempo le modifiche apportate a righe specifiche.
Usare gli streams in un task
Un caso d'uso comune è pianificare il consumo di uno stream all'interno di un task di Snowflake. Per farlo, basta inserire l'istruzione MERGE di Snowflake direttamente nella definizione del task:
CREATE TASK consume_the_stream
SCHEDULE = 'USING CRON 0 9-17 * * SUN America/Los_Angeles'
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
AS
-- copy / paste the merge statement from above
;
alter task consume_the_stream resume;
Il task qui sopra verrà eseguito dalle 9 alle 17 tutti i giorni.
In alternativa, si può incapsulare l'istruzione merge in una stored procedure di Snowflake e far sì che il task la richiami. Così la definizione del task resta più ordinata.
Tipi di streams
Snowflake offre 3 tipi di streams:
- Standard Streams: tracciano tutti gli insert, update e delete su una sorgente. È il tipo che abbiamo utilizzato nell'esempio precedente.
- Append Only: tracciano solo le righe inserite nella sorgente. Esempio: supponiamo di avere un offset appena creato e nessun dato nello stream. Vengono aggiunti 5 record alla tabella sorgente, altri 5 vengono aggiornati e altri 5 vengono eliminati. Lo stream risultante conterrà solo i 5 record inseriti. Esempio di utilizzo:
create or replace stream my_stream
on table my_table
append_only=true;
3. Insert Only: simile ad Append Only, ma pensato per i file in cloud storage gestiti tramite External Tables, Iceberg tables o Dynamic External Tables. I dati dei nuovi file aggiunti al cloud storage compariranno nello stream. La rimozione di un file dal cloud storage, invece, non avrà effetto sullo stream. Esempio di utilizzo:
create or replace stream my_stream
on external table my_external_table
insert_only=TRUE;
Verificare se uno stream contiene dati con STREAM\_HAS\_DATA
Abbiamo già visto che si può controllare se uno stream contiene dati con istruzioni come select count(*) from sales_stream o select * from sales_stream. Esiste però una pratica funzione di sistema da tenere a mente: SYSTEM$STREAM_HAS_DATA. La si può usare in un'istruzione select e restituirà TRUE o FALSE a seconda che lo stream contenga o meno dati.
select
SYSTEM$STREAM_HAS_DATA('SALES_STREAM')
as stream_has_data;
-- returns FALSE since we just reset the offset by consuming the stream in DML.
CHANGES: un'alternativa di sola lettura agli streams
Quando il change tracking è attivo, sia con alter table <table_name> set change_tracking = TRUE; sia con create stream <stream_name> on table <table_name>, è possibile interrogare le modifiche da un determinato momento in poi, anche se l'offset è stato resettato.
Aggiungendo la parola chiave changes alla clausola from e passando un at (timestamp => <timestamp>, si possono vedere tutte le modifiche avvenute da quel timestamp in poi, senza resettare l'offset.
set ts = dateadd('hours', -3, current_timestamp);
SELECT *
FROM fake_sales_orders
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => $ts);
La query qui sopra mostra tutte le modifiche apportate alla tabella nelle ultime 3 ore. Le colonne di metadati vengono restituite nei risultati della query, così possono essere usate nel processo di trasformazione.
Quando usare changes al posto degli streams
Usare changes può essere una buona idea quando:
- Si hanno più consumer ELT sulla stessa sorgente e non si vogliono gestire più stream.
- Si estraggono dati al di fuori di Snowflake. Ad esempio, caricando dati da Snowflake verso Mixpanel o Amplitude, ha senso memorizzare un proprio timestamp cursore e selezionare i dati cambiati da quel momento. Questo perché:
- Potreste non avere alcuna azione DML all'interno di Snowflake in grado di svuotare uno stream.
- Volete la flessibilità di ricaricare una determinata porzione di dati.
L'argomento del "select from changes" è così vasto da meritare un articolo dedicato, vista la quantità di esempi e casi d'uso; qui lo accenniamo soltanto per completezza.
Usare Dynamic Tables al posto degli Streams
Prima di costruire un nuovo processo di trasformazione basato sugli streams, vale la pena chiedersi se la funzionalità nativa Dynamic Tables di Snowflake non offra una soluzione più semplice per il vostro caso d'uso. Spesso si ottengono risultati simili usando una dynamic table in Snowflake, ma dipende tutto da ciò che si vuole fare. Se l'obiettivo è isolare i record nuovi o modificati, Streams e Changes restano strumenti eccellenti!
Frequently asked
questions
Quanto costano gli streams?
Il costo principale legato agli Streams è quello di compute associato all'interrogazione dello stream o al suo utilizzo in una fase di trasformazione.
Una stream table di per sé non contiene dati, anche se la si può interrogare come se ne contenesse. Poiché i dati modificati non vengono replicati, gli streams hanno costi di storage molto contenuti. Quando si abilita il change tracking su una tabella, le tre colonne di metadati vengono aggiunte alla tabella sorgente. L'unico costo aggiuntivo di storage riguarda quindi il piccolo spazio necessario per queste colonne extra.
Consultate qui le avvertenze relative a time travel e tempi di retention dei dati. Per un ripasso sui costi di Snowflake, date un'occhiata alla Snowflake Pricing & Billing Guide di SELECT.
Si possono creare più streams sulla stessa tabella?
Si possono creare quanti stream si vuole su una tabella. La best practice è che ogni consumer o tabella di destinazione abbia un proprio stream univoco associato. Non usate un singolo stream per scrivere su due tabelle diverse: l'offset verrebbe azzerato e i dati risulterebbero disallineati. Se volete trasformare una tabella sorgente in 5 modi diversi, potete creare 5 stream, senza alcun problema.
Quali sono le limitazioni?
Come abbiamo visto nell'esempio, è possibile abilitare uno stream su una view esattamente come su una tabella. Esistono però alcune limitazioni:
- Le tabelle sottostanti devono essere tabelle native di Snowflake.
- View annidate, CTE e Subquery sono supportate. Tuttavia, la query SQL completamente espansa può utilizzare solo queste operazioni: proiezioni, filtri, union all, inner o cross join. Ciò significa che
unionsenzaalleleft outer joinnon sono supportati.
Per maggiori dettagli, consultate la documentazione.
Come si gestiscono gli streams?
Si possono trovare tutti gli stream del proprio account, database o schema con uno qualsiasi di questi comandi:
show streams in account;
show streams in database <db_name>;
show streams in schema <qualified_schema_name>;
show streams; -- uses your worksheet or connection context / default schema.
Nella UI, gli stream si trovano all'interno di uno schema:
Gli stream si possono eliminare con il comando drop: drop stream db.schema.stream_name;
A questo punto dovreste sentirvi pronti a usare gli streams in produzione! Gli Streams sono un ottimo modo per catturare dati nuovi o modificati su tabelle sorgente di grandi dimensioni. Si usano soprattutto quando i dati sorgente sono piuttosto voluminosi e serve un metodo affidabile per catturare in modo incrementale i record nuovi o modificati.
Jeff è un consulente Data and Analytics con oltre 15 anni di esperienza nell'automazione degli insight e nell'uso dei dati per governare i processi aziendali. Sul piano tecnologico è specializzato in Snowflake + dbt + Tableau. Sul piano settoriale ha esperienza in Public Utility, Clinical Trials, Editoria, CPG e Manifatturiero. Potete contattarlo in qualsiasi momento all'indirizzo [email protected].