Introduction aux Streams Snowflake et au Change Data Capture
Un Stream Snowflake assure le Change Data Capture (CDC) : il permet de savoir ce qui a changé dans une table depuis un instant donné. Mais qu'est-ce que le CDC, au juste ?
En clair, le CDC consiste à répondre à la question : qu'est-ce qui a changé dans ma source de données depuis le dernier chargement ou traitement ?
Plus techniquement, le CDC est une méthode permettant d'identifier et de capturer les modifications apportées aux données d'une source. Il suit l'ensemble des insertions, mises à jour et suppressions effectuées sur une table donnée. Ce mode de suivi est bien plus souple que les approches par snapshot utilisées par les outils de chargement de données comme Fivetran, puisqu'il permet de reproduire l'état exact de votre table à n'importe quel instant.
Les Streams : la réponse de Snowflake au CDC en interne
Citons la documentation Snowflake :
Un objet stream enregistre les modifications de type DML (data manipulation language) appliquées aux tables — insertions, mises à jour et suppressions — ainsi que des métadonnées sur chaque changement, afin que des actions puissent être déclenchées à partir des données modifiées.
Décortiquons un peu.
Dans Snowflake, une Stream Table, appelée Stream, regroupe les enregistrements d'une table source qui ont changé depuis la dernière utilisation des données du stream dans une transaction DML. Snowflake y parvient en suivant les nouvelles micro-partitions ajoutées depuis la dernière consommation du stream.
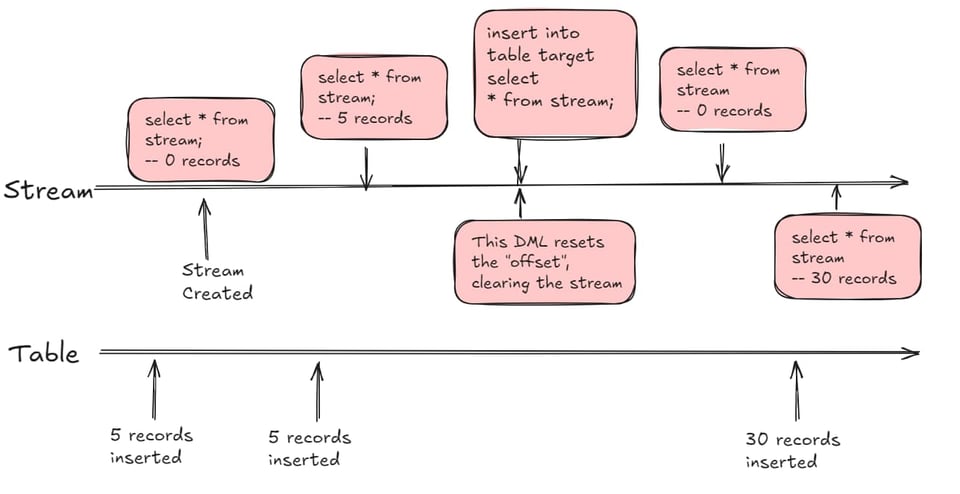
Premier concept clé : un stream peut être interrogé dans la clause from d'une requête SQL et se comporte un peu comme une vue. Sa particularité : il renvoie les lignes d'une table source qui ont changé depuis un instant précis, appelé offset. Cet offset est réinitialisé dès que les données du stream sont utilisées dans une requête DML (insert, update, delete, CTAS).
Comprendre l'offset d'un Stream
Lorsque vous créez un stream et que vous l'interrogez aussitôt, son comportement par défaut est d'être vide à l'initialisation. Si vous insérez ou modifiez ensuite 5 enregistrements dans la table source, le stream en renverra 5. Vous pouvez l'interroger autant de fois que vous voulez sans toucher à l'offset. Celui-ci n'est réinitialisé que lorsque vous interrogez le stream dans une instruction DML : insert, update, merge ou CTAS.
Exemple d'utilisation d'un Stream
Données source
Dans cet exemple, je vais créer un stream sur une vue, car la table source comporte trop de colonnes, rangées dans un ordre peu pratique. Vous verrez que créer des streams sur des vues est tout aussi simple que sur des tables.
J'ai une vue nommée raw_sales_data définie ainsi :
create view raw_sales_data as
select
sales_order_id,
name, -- le nom complet du client
email, -- l'email du client
ordered_at_utc -- timestamp unix en millisecondes
from fake_sales_orders -- la table où les données sont ajoutées
;
Créer et interroger le Stream
Créons un stream sur cette vue source :
create or replace stream sales_stream
on view raw_sales_orders;
Interrogeons ce stream en y appliquant une légère transformation :
select
sales_order_id as order_id,
name as customer_name,
email as customer_email,
(ordered_at_utc / 1e9)::timestamptz as ordered_at_utc
from
sales_stream;
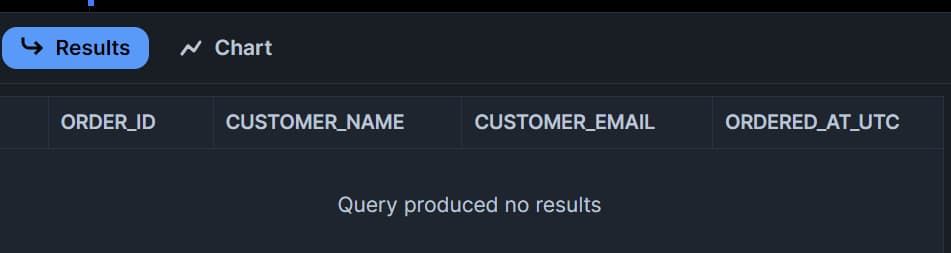
Comme nous n'avons ni manipulé ni ajouté de données dans la table source, la stream table est vide :
Ajouter des données à la source, puis interroger le Stream
Je vais ajouter 1000 lignes à la table via un script Python d'Extract/Load, puis interroger à nouveau le stream :
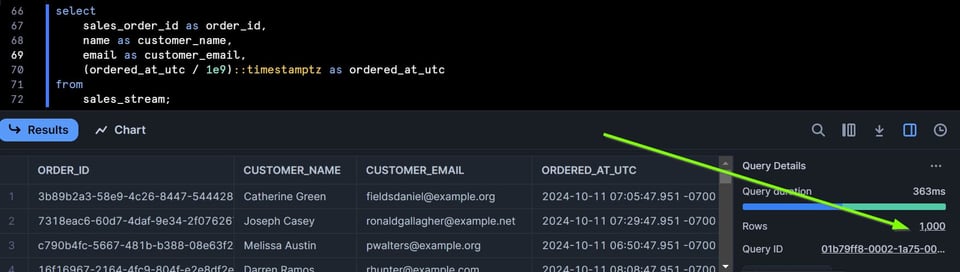
Le stream contient désormais 1000 lignes.
Utiliser les données du Stream pour réinitialiser l'offset / vider le Stream
Pour vider le stream, autrement dit réinitialiser l'offset, je dois utiliser ses données dans une transaction DML. Pour cet exemple simple, je vais insérer les données dans une temporary table — la manière la plus directe de vider le stream. En pratique, vous ferez plutôt un merge de ces données dans une table cible permanente.
create temp table
clear_the_stream as
(select * from sales_stream);
select count(*) from sales_stream; --renvoie maintenant 0 puisque l'offset a été réinitialisé.
Après avoir consommé les données du stream, celui-ci est vidé. Un nouvel offset est créé, et le cycle peut recommencer : manipuler les données source, interroger le stream, puis le consommer.
Mettre à jour et supprimer des données source
Nous avons vu comment ajouter de nouveaux enregistrements ; voyons maintenant les mises à jour. Modifions un enregistrement et supprimons-en un autre.
update fake_sales_orders
-- note : la table `fake_sales_orders` sert de base à la vue `raw_sales_orders`
set name = 'Jeff Skoldberg'
where sales_order_id = '59472696-660a-4935-bc30-2078ed35f044'
;
delete from fake_sales_orders
where sales_order_id = '4dfc5e0f-4268-4a46-9dbf-816acf48588e'
;
J'ai modifié deux lignes : combien de lignes le stream va-t-il renvoyer, à votre avis ?
Si vous avez répondu deux… c'est raté 🤔😀. Question piège.
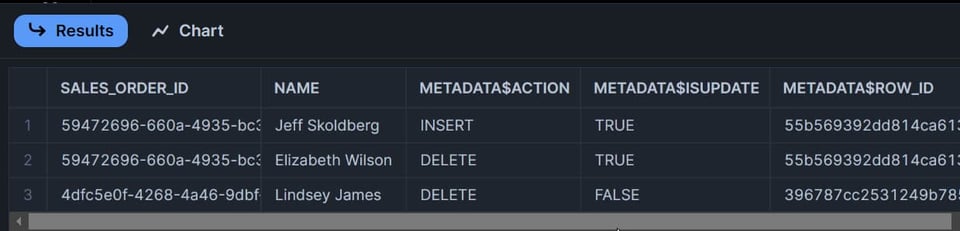
La bonne réponse est trois lignes :
- La ligne mise à jour apparaît sur deux lignes dans le stream : l'une avec
METADATA$ACTION=DELETE, l'autre avecMETADATA$ACTION=INSERT. - La ligne supprimée apparaît sur une seule ligne dans le stream avec
METADATA$ACTION=DELETE.
select
sales_order_id,
name,
metadata$action,
metadata$isupdate,
metadata$row_id
from
sales_stream;
Mettre à jour la table cible
Voici le SQL que j'utiliserais pour supprimer l'enregistrement supprimé de la cible et mettre à jour l'enregistrement modifié :
MERGE INTO clear_the_stream AS tgt -- la table temporaire créée plus haut
USING (
SELECT *
FROM sales_stream
) AS src
ON tgt.sales_order_id = src.sales_order_id
-- Pour les lignes marquées comme insert ou update
WHEN MATCHED AND src.metadata$action = 'INSERT'
THEN UPDATE
SET
tgt.name = src.name
-- vous utiliseriez toutes les colonnes
-- je n'utilise ici que le champ "NAME" par souci de simplicité,
-- car je sais quel champ a été mis à jour
Déployer le code
Vérifions le résultat après exécution :
select * from
clear_the_stream --la table temporaire qui joue le rôle de table cible
where sales_order_id in -- les deux lignes manipulées dans la source
(
'4dfc5e0f-4268-4a46-9dbf-816acf48588e',
'59472696-660a-4935-bc30-2078ed35f044'
);

Le sales_order_id commençant par 4df... a bien été supprimé, et l'identifiant 594... a été mis à jour : le champ name affiche désormais Jeff Skoldberg. Parfait !
Quand utiliser SHOW_INITIAL_ROWS
Jusqu'ici, nous avons créé des streams avec leur comportement par défaut. Il existe un paramètre optionnel important, show_initial_rows, que l'on peut définir à la création :
create or replace stream my_stream on table my_table
show_initial_rows = TRUE
Dans ce cas, le stream n'est pas vide à sa création. Lorsque vous interrogerez my_stream, il contiendra toutes les lignes non traitées : celles présentes avant la création du stream et toutes celles arrivées ou modifiées depuis.
Cette propriété résout certaines difficultés liées à la construction de cibles aval complètes. Sans elle, il faudrait passer par un contournement — par exemple unir les enregistrements existants et les enregistrements modifiés. Mais pour la plupart des scénarios de modélisation de données, activer show_initial_rows est exactement ce qu'il vous faut.
Les colonnes de métadonnées d'un Stream
Nous avons déjà utilisé les colonnes de métadonnées des Streams ; prenons le temps de les définir proprement. Par souci d'efficacité et d'exhaustivité, j'ai repris cette section directement de la documentation de Snowflake :
**METADATA$ACTION:**\\ **Indique l'opération DML enregistrée (INSERT, DELETE).**METADATA$ISUPDATE:**\\ **Indique si l'opération faisait partie d'une instruction UPDATE. Les mises à jour de lignes dans l'objet source sont représentées par une paire d'enregistrements DELETE et INSERT dans le stream, avec une colonne de métadonnées METADATA$ISUPDATE à TRUE. À noter : les streams enregistrent les différences entre deux offsets. Si une ligne est ajoutée puis mise à jour dans l'offset courant, la différence nette est une nouvelle ligne. La ligne METADATA$ISUPDATE enregistre alors la valeur FALSE.**METADATA$ROW_ID:**\\ **spécifie l'identifiant unique et immuable de la ligne, qui permet de suivre l'évolution de lignes spécifiques dans le temps.
Utiliser les Streams dans une tâche
Un cas d'usage courant consiste à planifier la consommation d'un stream dans une tâche Snowflake. Pour cela, vous pouvez placer l'instruction MERGE de Snowflake directement dans la définition de la tâche :
CREATE TASK consume_the_stream
SCHEDULE = 'USING CRON 0 9-17 * * SUN America/Los_Angeles'
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
AS
-- copier / coller l'instruction merge précédente
;
alter task consume_the_stream resume;
La tâche ci-dessus s'exécute de 9h à 17h, tous les jours.
Vous pouvez aussi encapsuler l'instruction merge dans une procédure stockée Snowflake et faire exécuter cette procédure par la tâche. Votre définition de tâche reste ainsi propre et lisible.
Les types de Streams
Snowflake propose 3 types de streams :
- Standard Streams : suit toutes les insertions, mises à jour et suppressions sur une source. C'est ce que nous avons utilisé dans l'exemple ci-dessus.
- Append Only : ne suit que les lignes insérées dans la source. Exemple : partons d'un offset frais et d'un stream vide. 5 enregistrements sont ajoutés à la table source, 5 autres sont mis à jour et 5 autres encore sont supprimés. Le stream ne contiendra que les 5 enregistrements insérés. Exemple d'utilisation :
create or replace stream my_stream
on table my_table
append_only=true;
3. Insert Only : similaire à Append Only, mais destiné aux fichiers en stockage cloud derrière des External Tables, Iceberg tables ou Dynamic External Tables. Les données des nouveaux fichiers ajoutés au stockage cloud apparaîtront dans le stream. La suppression d'un fichier du stockage cloud n'a aucun effet sur le stream. Exemple d'utilisation :
create or replace stream my_stream
on external table my_external_table
insert_only=TRUE;
Vérifier si un Stream contient des données avec STREAM\_HAS\_DATA
Nous avons déjà vu qu'on peut vérifier si un stream contient des données avec une commande du type select count(*) from sales_stream ou select * from sales_stream. Mais il existe une fonction système bien pratique à connaître : SYSTEM$STREAM_HAS_DATA. Utilisée dans une instruction select, elle renvoie TRUE ou FALSE selon que le stream contient ou non des données.
select
SYSTEM$STREAM_HAS_DATA('SALES_STREAM')
as stream_has_data;
-- renvoie FALSE puisque nous venons de réinitialiser l'offset en consommant le stream dans une instruction DML.
CHANGES : une alternative en lecture seule aux Streams
Lorsque le change tracking est activé, soit avec alter table <table_name> set change_tracking = TRUE;, soit avec create stream <stream_name> on table <table_name>, vous pouvez interroger les changements à partir d'un instant donné, même si l'offset a été réinitialisé.
En ajoutant le mot-clé changes à la clause from et en passant un at (timestamp => <timestamp>, vous obtenez tous les changements survenus depuis cet horodatage, sans réinitialiser l'offset.
set ts = dateadd('hours', -3, current_timestamp);
SELECT *
FROM fake_sales_orders
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => $ts);
La requête ci-dessus affiche tous les changements survenus sur la table au cours des 3 dernières heures. Les colonnes de métadonnées sont renvoyées dans les résultats, et vous pouvez les exploiter dans votre processus de transformation.
Quand préférer changes aux Streams
Utiliser changes peut être pertinent si :
- Vous avez plusieurs consommateurs ELT sur la même source et ne voulez pas gérer plusieurs streams.
- Vous extrayez des données en dehors de Snowflake. Par exemple, pour charger des données de Snowflake vers Mixpanel ou Amplitude, il est judicieux de stocker votre propre timestamp de curseur et de sélectionner les données modifiées depuis cet horodatage. Pour deux raisons :
- Vous n'aurez peut-être aucune action DML dans Snowflake pour vider un stream.
- Vous voulez la flexibilité de recharger une portion donnée des données.
Le sujet du select from changes mériterait un article à lui seul, tant les exemples et cas d'usage sont nombreux ; je le mentionne ici brièvement par souci d'exhaustivité.
Utiliser les Dynamic Tables plutôt que les Streams
Avant de bâtir un nouveau processus de transformation basé sur des streams, il peut être utile de vérifier si la fonctionnalité native Dynamic Tables de Snowflake n'offre pas une solution plus simple à votre cas d'usage. On peut souvent obtenir un résultat similaire avec une dynamic table, mais tout dépend de votre objectif. Si vous cherchez à isoler les enregistrements nouveaux ou modifiés, les Streams et Changes restent d'excellents outils !
Frequently asked
questions
Combien coûtent les Streams ?
Le principal coût lié aux Streams correspond aux coûts de compute associés à l'interrogation du stream ou à son utilisation dans une étape de transformation.
Une stream table ne contient en elle-même aucune donnée, même si on peut l'interroger comme si c'était le cas. Comme les données modifiées ne sont pas répliquées, les streams génèrent très peu de coûts de stockage. Lorsque vous activez le change tracking sur une table, les trois colonnes de métadonnées sont ajoutées à la table source. Le seul coût de stockage supplémentaire correspond au faible volume nécessaire à ces colonnes additionnelles.
Consultez cette page pour connaître les subtilités liées au time travel et à la durée de rétention des données. Pour une mise au point sur les coûts de Snowflake, consultez le guide tarifs et facturation Snowflake de SELECT.
Peut-on créer plusieurs Streams sur la même table ?
Vous pouvez créer autant de streams sur une table que vous le souhaitez. La bonne pratique veut que chaque consommateur ou table cible dispose de son propre stream. N'utilisez pas un stream unique pour écrire dans deux tables différentes : l'offset serait réinitialisé et vos données se désynchroniseraient. Si vous souhaitez transformer une même table source de 5 manières différentes, créez 5 streams, sans souci.
Quelles sont les limitations ?
Comme nous l'avons vu dans l'exemple ci-dessus, on peut activer un stream sur une vue tout comme sur une table. Quelques limitations s'appliquent toutefois :
- Les tables sous-jacentes doivent être des tables natives Snowflake.
- Les vues imbriquées, CTE et sous-requêtes sont prises en charge. Mais la requête SQL entièrement développée ne peut utiliser que ces opérations : projections, filtres, union all, inner join ou cross join. Autrement dit,
unionsansalletleft outer joinne sont pas pris en charge.
Pour en savoir plus, consultez la documentation.
Comment gérer les Streams ?
Vous pouvez lister tous les streams de votre compte, base de données ou schéma avec l'une de ces commandes :
show streams in account;
show streams in database <db_name>;
show streams in schema <qualified_schema_name>;
show streams; -- utilise le contexte de votre worksheet ou de votre connexion / schéma par défaut.
Dans l'interface, vous retrouverez les streams au sein d'un schéma :
Les streams se suppriment avec la commande drop : drop stream db.schema.stream_name;
Vous voilà, je l'espère, prêt à utiliser les streams en production ! Les Streams sont un excellent moyen de capturer les données nouvelles ou modifiées sur de grandes tables source. Ils sont particulièrement utiles lorsque les données source sont volumineuses et que vous cherchez une méthode fiable pour capturer de façon incrémentale les enregistrements nouveaux ou modifiés.
Jeff est consultant Data & Analytics, fort de plus de 15 ans d'expérience dans l'automatisation des insights et l'exploitation des données au service des processus métier. Côté technologies, il est spécialisé sur Snowflake + dbt + Tableau. Côté secteurs, il a travaillé dans les services publics, les essais cliniques, l'édition, les biens de grande consommation et l'industrie manufacturière. N'hésitez pas à le contacter : [email protected].