Snowflake Streamsと変更データキャプチャの基礎
Snowflake Streamは変更データキャプチャ(CDC)を担う機能で、特定の時点以降にテーブルで何が変わったかを把握するのに役立ちます。では、そもそもCDCとは何でしょうか。
ひとことで言えば、CDCとは「前回データをロード/処理してから、データソースで何が変わったか?」という問いに答える仕組みです。
より技術的に言えば、CDCはデータソースに加えられた変更を検出してキャプチャする手法です。対象となるデータベーステーブルに対するすべての挿入・更新・削除を追跡することで、これを実現します。この方式はFivetranなどのデータロードツールで使われるスナップショット型のアプローチと比べてはるかに柔軟で、任意の時点におけるテーブルの状態を正確に再現できます。
StreamsはSnowflake内部のCDCソリューション
Snowflakeのドキュメントから引用します。
ストリームオブジェクトは、テーブルに対して行われたデータ操作言語(DML)の変更(挿入、更新、削除)と、各変更に関するメタデータを記録し、変更されたデータを使ったアクションを可能にします。
もう少し噛み砕いて見ていきましょう。
Snowflakeでは、Stream(Stream Table)とは、ストリームのデータが最後にDMLトランザクションで利用されて以降に変更されたソーステーブルのレコード集合を指します。これは、ストリームが最後に消費されてから追加されたマイクロパーティションをSnowflakeが追跡することで実現されています。
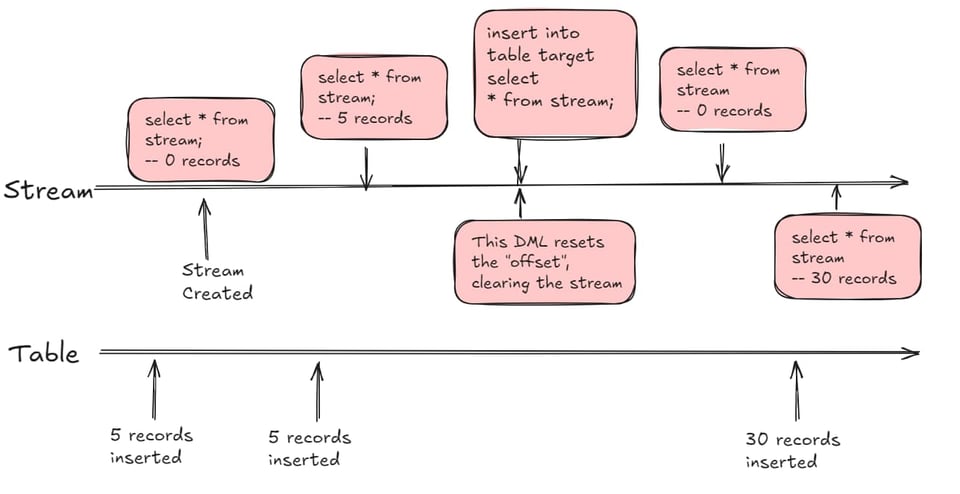
ストリームについてまず押さえておきたいのは、SQL文のfrom句で参照でき、ビューによく似た振る舞いをするという点です。特徴的なのは、offsetと呼ばれる時点以降に変更されたソーステーブルの行を返すところです。このoffsetは、ストリームのデータをDMLクエリ(insert、update、delete、CTAS)で使うとリセットされます。
Stream Offsetを理解する
ストリームを作成してすぐにSELECTすると、デフォルトの挙動では初期化時のストリームは空です。その後ソーステーブルで5件のレコードを挿入または変更してからストリームをクエリすると、5件のレコードが返ります。オフセットを変えずにストリームからSELECTすることも可能です。オフセットがリセットされるのは、insert、update、merge、CTASといったDML文でストリームをクエリしたときだけです。
Streamの利用例
ソースデータ
今回の例では、ビューの上にストリームを作成します。ソーステーブルのカラム数が多く、並びも分かりにくいためです。ビュー上にストリームを作る手順は、テーブル上に作る場合とほぼ同じで簡単なことが分かると思います。
以下のように定義されたraw_sales_dataというビューがあるとします。
create view raw_sales_data as
select
sales_order_id,
name, -- 顧客のフルネーム
email, -- 顧客のメールアドレス
ordered_at_utc -- ミリ秒単位のUnixタイムスタンプ
from fake_sales_orders -- データが追加されるテーブル
;
ストリームの作成とクエリ
このソースビューの上にストリームを作成します。
create or replace stream sales_stream
on view raw_sales_orders;
ストリームからSELECTし、軽い変換を加えてみましょう。
select
sales_order_id as order_id,
name as customer_name,
email as customer_email,
(ordered_at_utc / 1e9)::timestamptz as ordered_at_utc
from
sales_stream;
ソーステーブルに対してまだ何の操作も追加もしていないため、ストリームテーブルは空です。
ソースにデータを追加してストリームをクエリ
PythonのExtract/Loadスクリプトでテーブルに1000行を追加し、もう一度ストリームからSELECTしてみます。
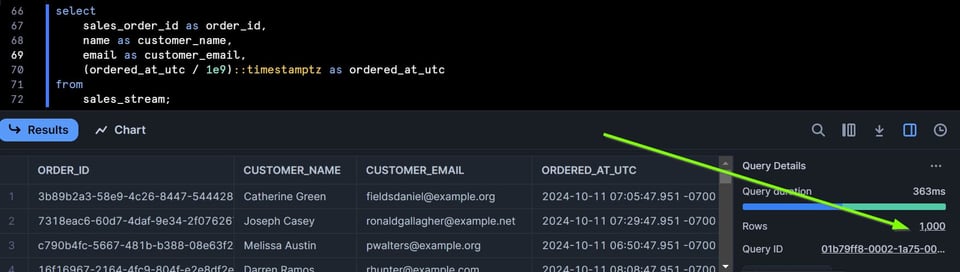
これでストリームに1000行が入りました。
ストリームデータを使ってオフセットをリセット/ストリームをクリアする
ストリームをクリアする、つまりoffsetをリセットするには、ストリームのデータをDMLトランザクションで使う必要があります。ここでは最もシンプルな方法として、temporary tableにデータを挿入してストリームをクリアします。実運用では、このデータを永続的なターゲットテーブルへmergeするケースが多いでしょう。
create temp table
clear_the_stream as
(select * from sales_stream);
select count(*) from sales_stream; -- オフセットがリセットされたため0が返る
ストリームのデータを「消費」したことで、ストリームはクリアされました。新しいoffsetが作成され、ソースデータの操作 → ストリームのクエリ → ストリームの消費というサイクルを再び回せます。
ソースデータの更新と削除
新規レコードの追加は確認しましたが、ソースデータを更新した場合はどうなるでしょうか。1件を更新し、1件を削除してみます。
update fake_sales_orders
-- 注: テーブル `fake_sales_orders` はビュー `raw_sales_orders` の元になっている
set name = 'Jeff Skoldberg'
where sales_order_id = '59472696-660a-4935-bc30-2078ed35f044'
;
delete from fake_sales_orders
where sales_order_id = '4dfc5e0f-4268-4a46-9dbf-816acf48588e'
;
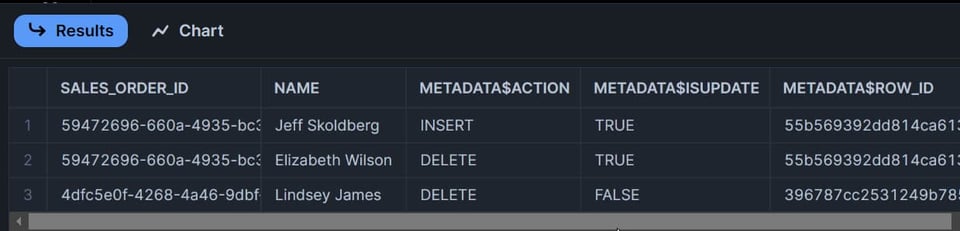
データを2行変更しましたが、ストリームは何行返すと思いますか?
「2行」と答えた方は…残念、不正解です 🤔😀。引っかけ問題でした。
正解は3行です。
- 更新された行は、ストリーム上では2行として現れます。1行は
METADATA$ACTION=DELETE、もう1行はMETADATA$ACTION=INSERTのフラグが付きます。 - 削除された行は、ストリーム上では
METADATA$ACTION=DELETEとして1レコードのみ表示されます。
select
sales_order_id,
name,
metadata$action,
metadata$isupdate,
metadata$row_id
from
sales_stream;
ターゲットテーブルの更新
削除されたレコードをターゲットから取り除き、更新されたレコードを反映するためのSQLは次のとおりです。
MERGE INTO clear_the_stream AS tgt -- 先ほどの一時テーブル
USING (
SELECT *
FROM sales_stream
) AS src
ON tgt.sales_order_id = src.sales_order_id
-- insertまたはupdateとしてマークされた行に対して
WHEN MATCHED AND src.metadata$action = 'INSERT'
THEN UPDATE
SET
tgt.name = src.name
-- 本来はすべてのカラムを使う
-- ここではどのフィールドが更新されたか分かっているので
-- 簡略化のため "NAME" フィールドのみ使用
コードを展開
クエリを実行したら、結果を確認してみましょう。
select * from
clear_the_stream -- ターゲットテーブル代わりの一時テーブル
where sales_order_id in -- ソースで操作した2行
(
'4dfc5e0f-4268-4a46-9dbf-816acf48588e',
'59472696-660a-4935-bc30-2078ed35f044'
);

4df...で始まるsales_order_idはきちんと削除され、594...のIDはnameフィールドがJeff Skoldbergに更新されました。完璧です!
SHOW_INITIAL_ROWSを使うタイミング
ここまでは既定の挙動でストリームを作成してきましたが、ストリーム作成時に指定できるshow_initial_rowsという重要なオプションパラメータがあります。
create or replace stream my_stream on table my_table
show_initial_rows = TRUE
このパラメータを指定すると、作成時点でストリームは空になりません。my_streamからSELECTすると、未処理のすべての行、つまりストリーム作成前から存在していた行と、それ以降に変更・追加されたデータがすべて含まれます。
このプロパティのおかげで、下流のターゲットを完全な形で構築するうえで生じがちな課題を回避できます。これがない場合、既存レコードと変更レコードをUNIONで結合するといった回避策が必要になります。多くのデータモデリングの場面では、show_initial_rowsを有効にするのが最適な選択肢になるはずです。
Streamのメタデータカラム
すでにStreamのメタデータカラムを使ってきましたが、ここで一つひとつをきちんと定義しておきましょう。効率と網羅性のため、Snowflakeのドキュメントからそのまま引用します。
**METADATA$ACTION:**\\ **記録されたDML操作(INSERT、DELETE)を示します。**METADATA$ISUPDATE:**\\ **その操作がUPDATE文の一部であったかどうかを示します。ソースオブジェクト内の行に対する更新は、ストリーム内ではDELETEとINSERTのペアで表現され、メタデータカラムMETADATA$ISUPDATEはTRUEに設定されます。なお、ストリームは2つのオフセット間の差分を記録します。現在のオフセット内で行が追加され、その後更新された場合、差分は新しい行として扱われ、METADATA$ISUPDATEはFALSEを記録します。**METADATA$ROW_ID:**\\ **行に対する一意かつ不変のIDを示し、特定の行の変更を時系列で追跡するのに使えます。
タスクの中でストリームを使う
よくあるユースケースは、ストリームの消費をSnowflakeタスクでスケジュール実行することです。これを実現するには、Snowflake MERGE文をタスク定義に直接書き込みます。
CREATE TASK consume_the_stream
SCHEDULE = 'USING CRON 0 9-17 * * SUN America/Los_Angeles'
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
AS
-- 上記のmerge文をコピー&ペースト
;
alter task consume_the_stream resume;
このタスクは毎日9時から17時まで実行されます。
あるいは、merge文をSnowflakeストアドプロシージャでラップし、タスクからそのプロシージャを呼び出す方法もあります。こうするとタスク定義をすっきり保てます。
ストリームの種類
Snowflakeにはストリームが3種類あります。
- Standard Streams: ソースに対するすべての挿入・更新・削除を追跡します。先ほどのウォークスルーで使ったのはこの種類です。
- Append Only: ソースに対して挿入された行のみを追跡します。例: 新しいオフセットでストリームにデータがない状態から、ソーステーブルに5件のレコードが追加され、別の5件が更新され、さらに別の5件が削除されたとします。この場合、ストリームには挿入された5件のみが含まれます。使用例:
create or replace stream my_stream
on table my_table
append_only=true;
3. Insert Only: Append Onlyに似ていますが、対象はExternal Table、Icebergテーブル、Dynamic External Tableの背後にあるクラウドストレージ上のファイルです。クラウドストレージに新しいファイルが追加されると、そのデータがストリームに現れます。クラウドストレージからファイルを削除してもストリームには影響しません。使用例:
create or replace stream my_stream
on external table my_external_table
insert_only=TRUE;
STREAM\_HAS\_DATAでストリームにデータがあるかを確認する
select count(*) from sales_streamやselect * from sales_streamといった方法でストリームにデータがあるか確認できることは、すでに見てきました。これに加えて、SYSTEM$STREAM_HAS_DATAという便利なシステム関数も知っておくと役立ちます。SELECT文の中で使うと、ストリームにデータがあるかどうかに応じてTRUEまたはFALSEを返します。
select
SYSTEM$STREAM_HAS_DATA('SALES_STREAM')
as stream_has_data;
-- DMLでストリームを消費しオフセットをリセットした直後なのでFALSEが返る
CHANGES: ストリームの読み取り専用な代替手段
変更追跡が有効になっている場合(alter table <table_name> set change_tracking = TRUE;またはcreate stream <stream_name> on table <table_name>のいずれかで有効化)、offsetがリセットされた後でも、特定の時点以降の変更をクエリできます。
from句にchangesキーワードを加え、at (timestamp => <timestamp>を渡すことで、offsetをリセットせずに、そのタイムスタンプ以降の変更をすべて確認できます。
set ts = dateadd('hours', -3, current_timestamp);
SELECT *
FROM fake_sales_orders
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => $ts);
このクエリは、過去3時間にテーブルで発生したすべての変更を返します。メタデータカラムも結果に含まれるため、変換処理の中でそのまま活用できます。
ストリームではなくchangesを使うべき場面
次のようなケースではchangesを使うのが有効です。
- 同一ソースに複数のELTコンシューマーがあり、複数のストリームを管理したくない場合。
- Snowflakeの外にデータを取り出す場合。たとえばSnowflakeからMixpanelやAmplitudeへデータをロードするケースでは、独自にカーソルタイムスタンプを保持し、それ以降に変更されたデータを取得する方が理にかなっています。理由は次のとおりです。
- Snowflake内でストリームをクリアするためのDMLアクションが存在しない可能性がある。
- データの一部を再ロードできる柔軟性が欲しい。
「changesからSELECTする」というテーマは、事例や用途が豊富で、それだけで一本のブログ記事になるほどのボリュームですが、ここでは網羅性のために簡単に触れるにとどめます。
StreamsではなくDynamic Tablesを使うという選択肢
ストリームを使った新しい変換処理を組む前に、Snowflakeネイティブの機能であるDynamic Tablesでよりシンプルに解決できないか検討する価値があります。多くの場合、Dynamic Tablesでも似たことが実現できますが、最適解はやりたいことによって変わります。新規または変更されたレコードだけを切り出したいなら、StreamsとChangesは強力な選択肢です。
Frequently asked
questions
Streamsの利用料金はどれくらいかかりますか?
Streamsで発生する主なコストは、ストリームをクエリしたり変換ステップで利用したりするときのコンピュートコストです。
ストリームテーブル自体はデータを保持していませんが、データを持っているかのようにクエリできます。変更データは複製されないため、ストリームのストレージコストはごくわずかです。テーブルで変更追跡を有効にすると、ソーステーブルに3つのメタデータカラムが追加されます。追加で発生するストレージコストは、これらのカラム分のごく少量だけです。
タイムトラベルやデータ保持期間に関する注意点はこちらを確認してください。Snowflakeのコスト全般のおさらいは、SELECTのSnowflake料金・課金ガイドをご覧ください。
同じテーブルに複数のストリームを作成できますか?
1つのテーブルに対して、いくつでもストリームを作成できます。ベストプラクティスは、コンシューマーやターゲットテーブルごとに固有のストリームを紐付けることです。1つのストリームから2つの異なるテーブルへ書き込むのは避けてください。offsetがクリアされ、データの整合性が崩れます。1つのソーステーブルを5通りの方法で変換したい場合は、5つのストリームを作成すれば問題ありません。
制限事項はありますか?
先ほどの例で見たとおり、テーブルと同様にビューでもストリームを有効にできます。ただし、いくつかの制限があります。
- 基となるテーブルはネイティブなSnowflakeテーブルでなければなりません。
- ネストされたビュー、CTE、サブクエリはサポートされています。ただし、完全に展開されたSQLクエリで使用できるのは、プロジェクション、フィルタ、union all、内部結合またはクロス結合のみです。つまり、
allを伴わないunionやleft outer joinはサポートされません。
詳細はドキュメントを参照してください。
ストリームはどのように管理しますか?
アカウント、データベース、スキーマ内のすべてのストリームは、以下のコマンドのいずれかで確認できます。
show streams in account;
show streams in database <db_name>;
show streams in schema <qualified_schema_name>;
show streams; -- ワークシートまたは接続コンテキスト/デフォルトスキーマを使用
UIからはスキーマ内のストリームを確認できます。
ストリームはdropコマンドで削除できます: drop stream db.schema.stream_name;
これで本番環境でも自信を持ってストリームを使えるようになったのではないでしょうか。Streamsは、大規模なソーステーブルから新規・変更レコードをキャプチャするのに最適な手段です。ソースデータが非常に大きく、新規または変更されたレコードを確実に増分取り込みしたい場面で、Streamsは特に力を発揮します。
Jeffはデータ&アナリティクスのコンサルタントで、インサイトの自動化とデータを活用したビジネスプロセスの制御に15年以上携わってきました。技術面ではSnowflake、dbt、Tableauを得意とし、業界面では公益事業、臨床試験、出版、CPG、製造業などでの経験があります。お気軽にご連絡ください: [email protected]。