Introducción a Snowflake Streams y Change Data Capture
Un Snowflake Stream se encarga del Change Data Capture (CDC) y permite saber qué cambió en una tabla desde un momento determinado. Pero ¿qué es CDC?
En pocas palabras, CDC es el proceso de responder a la pregunta: "¿qué cambió en mi fuente de datos desde la última vez que cargué o procesé los datos?".
Dicho de forma más técnica, CDC es un método para identificar y capturar los cambios realizados sobre los datos de una fuente. Lo hace registrando todas las inserciones, actualizaciones y eliminaciones que ocurren en una tabla determinada. Esta forma de rastrear cambios es mucho más flexible que los enfoques basados en snapshots que usan herramientas de carga de datos como Fivetran, ya que te permite reproducir el estado exacto de tu tabla en cualquier momento.
Los Streams son la respuesta de Snowflake al CDC interno
Citando la documentación de Snowflake:
Un objeto stream registra los cambios de lenguaje de manipulación de datos (DML) realizados sobre las tablas —inserciones, actualizaciones y eliminaciones—, junto con metadatos de cada cambio, de modo que se puedan tomar acciones a partir de los datos modificados.
Vamos a desglosarlo un poco más.
En Snowflake, una Stream Table, conocida simplemente como Stream, es un conjunto de registros de una tabla fuente que cambiaron desde la última vez que los datos del stream se usaron en una transacción DML. Esto se logra rastreando las nuevas micro-particiones que se agregaron desde la última vez que se consumió el stream.
El primer concepto importante sobre un stream es que se puede consultar en la cláusula from de una sentencia SQL y se comporta muy parecido a una vista. Lo que lo hace especial es que devuelve filas de una tabla fuente que cambiaron desde un punto en el tiempo, llamado offset. El offset se reinicia al usar los datos del stream en una consulta DML (insert, update, delete, CTAS).
Entendiendo el offset del Stream
Cuando creas un stream y haces un select inmediatamente, por defecto el stream estará vacío al inicializarse. Si luego insertas o modificas 5 registros en la tabla fuente, al consultar el stream se devolverán 5 registros. Puedes hacer select del stream sin alterar el offset. El offset solo se reinicia cuando consultas el stream desde una sentencia DML: insert, update, merge o CTAS.
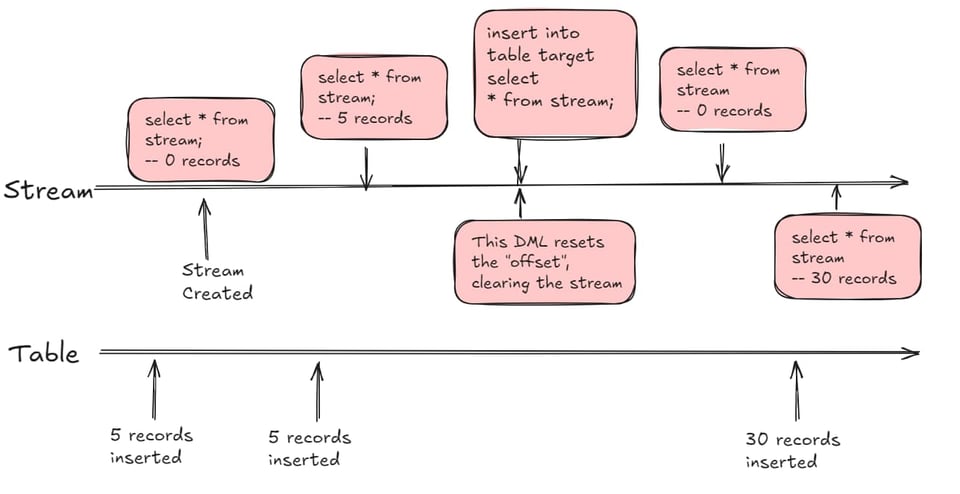
Ejemplo de uso de un Stream
Datos fuente
En este ejemplo voy a crear un stream sobre una vista, porque la tabla fuente tiene demasiadas columnas y están en un orden raro. Verás que crear streams sobre vistas es sencillo: el proceso es prácticamente igual al de crearlos sobre tablas.
Tengo una vista llamada raw_sales_data definida así:
create view raw_sales_data as
select
sales_order_id,
name, -- the customer's Full Name
email, -- the customer's email
ordered_at_utc -- unix timestamp in milliseconds
from fake_sales_orders -- the table where data is added
;
Crear y consultar el Stream
Creemos un stream sobre esta vista fuente:
create or replace stream sales_stream
on view raw_sales_orders;
Hagamos un select del stream y apliquemos una transformación ligera:
select
sales_order_id as order_id,
name as customer_name,
email as customer_email,
(ordered_at_utc / 1e9)::timestamptz as ordered_at_utc
from
sales_stream;
Como no hemos manipulado ni agregado datos en la tabla fuente, la stream table estará vacía:
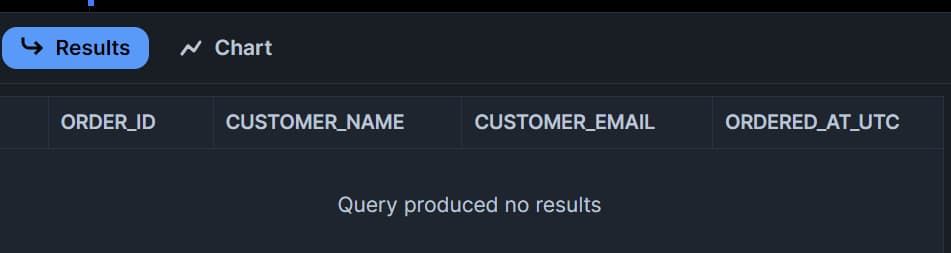
Agregar datos a la fuente y consultar el stream
Voy a agregar 1000 filas a la tabla ejecutando un script de Extract/Load en Python, y después haré select del stream de nuevo:
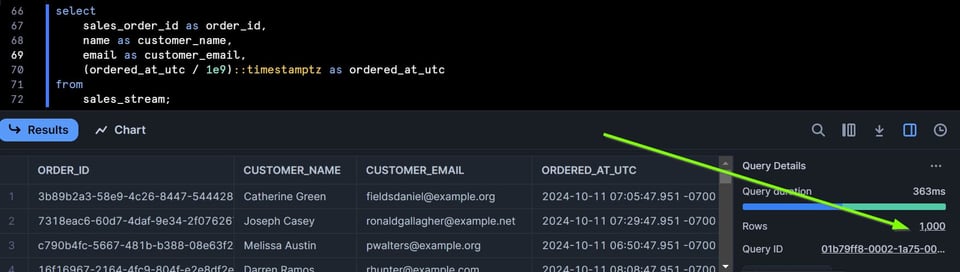
Ahora el stream tiene 1000 filas.
Usar los datos del stream para reiniciar el offset / limpiar el stream
Para limpiar el stream, o reiniciar el offset, hay que usar los datos del stream dentro de una transacción DML. Para este ejemplo simple, voy a insertar los datos en una temporary table, que será la forma más sencilla de limpiar el stream. Pero lo más probable es que en la práctica termines haciendo merge de estos datos en una tabla destino permanente.
create temp table
clear_the_stream as
(select * from sales_stream);
select count(*) from sales_stream; --now returns 0 since the offset has been reset.
Después de "consumir" los datos del stream, este queda limpio. Se crea un nuevo offset, así que podemos repetir el ciclo: manipular los datos fuente, consultar el stream y consumirlo.
Actualizar y eliminar datos en la fuente
Ya vimos cómo agregar registros nuevos en la fuente, ¿pero qué pasa al actualizarlos? Actualicemos un registro y eliminemos otro.
update fake_sales_orders
-- note: table `fake_sales_orders` is the basis for the view `raw_sales_orders`
set name = 'Jeff Skoldberg'
where sales_order_id = '59472696-660a-4935-bc30-2078ed35f044'
;
delete from fake_sales_orders
where sales_order_id = '4dfc5e0f-4268-4a46-9dbf-816acf48588e'
;
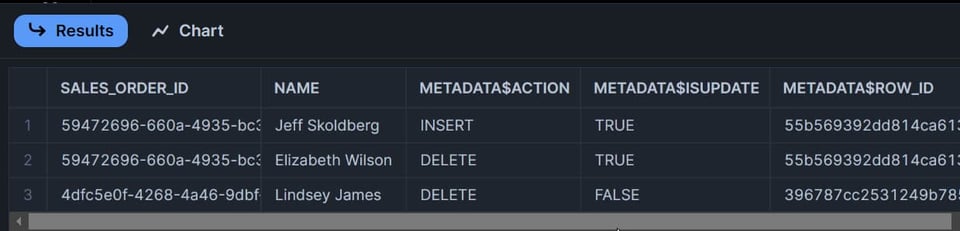
Ahora que modifiqué dos filas, ¿cuántas filas crees que devolverá el stream?
Si pensaste "dos"… te equivocaste 🤔😀. Era una pregunta con trampa.
La respuesta correcta es tres filas:
- La fila actualizada aparecerá como dos filas en el stream: una marcada con
METADATA$ACTION=DELETEy otra conMETADATA$ACTION=INSERT. - La fila eliminada aparecerá como un solo registro en el stream con
METADATA$ACTION=DELETE.
select
sales_order_id,
name,
metadata$action,
metadata$isupdate,
metadata$row_id
from
sales_stream;
Actualizar la tabla destino
Este es el SQL que usaría para eliminar del destino el registro eliminado y actualizar el registro modificado:
MERGE INTO clear_the_stream AS tgt -- the temp table from earlier
USING (
SELECT *
FROM sales_stream
) AS src
ON tgt.sales_order_id = src.sales_order_id
-- For rows marked as insert or update
WHEN MATCHED AND src.metadata$action = 'INSERT'
THEN UPDATE
SET
tgt.name = src.name
-- you would use all the columns
-- I'm only using the "NAME" field for simplicity,
-- because I know which field was updated
Expandir código
Después de ejecutar la consulta, revisemos los resultados:
select * from
clear_the_stream --the temp table acting as my target table
where sales_order_id in -- the two rows I manipulated in the source
(
'4dfc5e0f-4268-4a46-9dbf-816acf48588e',
'59472696-660a-4935-bc30-2078ed35f044'
);

Eliminó correctamente el sales_order_id que empieza con 4df... y actualizó el id 594... para que el campo name ahora diga Jeff Skoldberg. ¡Excelente!
Cuándo usar SHOW_INITIAL_ROWS
Hasta ahora hemos creado streams con el comportamiento por defecto. Hay un parámetro opcional importante llamado show_initial_rows que puede definirse al crear un stream:
create or replace stream my_stream on table my_table
show_initial_rows = TRUE
En este caso, el stream no estará vacío al crearse. Al hacer select de my_stream, contendrá todas las filas no procesadas: las que existían antes de crear el stream y cualquier dato que haya cambiado o llegado desde entonces.
Esta propiedad resuelve varios retos que aparecerían al construir destinos downstream completos. Sin ella, habría que recurrir a alguna solución alterna; por ejemplo, unir los registros existentes con los modificados. Pero para la mayoría de los escenarios de modelado de datos, habilitar show_initial_rows será justo lo que necesitas.
Columnas de metadata del Stream
Ya hemos estado usando las columnas de metadata del Stream, pero vale la pena detenerse a definir cada una con precisión. Por eficiencia y para que quede completo, copié esta sección directamente de la documentación de Snowflake:
**METADATA$ACTION:**\\ **Indica la operación DML (INSERT, DELETE) registrada.**METADATA$ISUPDATE:**\\ **Indica si la operación formó parte de una sentencia UPDATE. Las actualizaciones de filas en el objeto fuente se representan como un par de registros DELETE e INSERT en el stream, con la columna de metadata METADATA$ISUPDATE en TRUE. Ten en cuenta que los streams registran las diferencias entre dos offsets. Si una fila se agrega y luego se actualiza dentro del offset actual, el cambio neto es una nueva fila. La fila de METADATA$ISUPDATE registrará el valor FALSE.**METADATA$ROW_ID:**\\ **especifica el ID único e inmutable de la fila, que sirve para rastrear cambios en filas específicas a lo largo del tiempo.
Usar streams dentro de un task
Un caso de uso común es programar el consumo de un stream dentro de un Snowflake task. Para lograrlo, puedes incluir la sentencia MERGE de Snowflake directamente en la definición del task:
CREATE TASK consume_the_stream
SCHEDULE = 'USING CRON 0 9-17 * * SUN America/Los_Angeles'
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
AS
-- copy / paste the merge statement from above
;
alter task consume_the_stream resume;
El task anterior se ejecuta de 9 AM a 5 PM todos los días.
Otra opción es envolver la sentencia merge dentro de un stored procedure de Snowflake y hacer que el task ejecute ese stored procedure. Así mantienes la definición del task más limpia.
Tipos de streams
Snowflake tiene 3 tipos de streams:
- Standard Streams: rastrean todas las inserciones, actualizaciones y eliminaciones sobre una fuente. Es el que usamos en el recorrido anterior.
- Append Only: rastrea únicamente las filas insertadas en la fuente. Ejemplo: supongamos que tenemos un offset nuevo y un stream sin datos. Se agregan 5 registros a la tabla fuente, se actualizan otros 5 y se eliminan otros 5. El stream resultante contendrá solamente los 5 registros insertados. Ejemplo de uso:
create or replace stream my_stream
on table my_table
append_only=true;
3. Insert Only: es similar a Append Only, pero aplica a archivos en cloud storage detrás de External Tables, Iceberg tables o Dynamic External Tables. Los datos de los nuevos archivos agregados al cloud storage aparecerán en el stream. Eliminar un archivo del cloud storage no afecta al stream. Ejemplo de uso:
create or replace stream my_stream
on external table my_external_table
insert_only=TRUE;
Verificar si un stream tiene datos con STREAM\_HAS\_DATA
Ya vimos que puedes comprobar si un stream tiene datos con algo como select count(*) from sales_stream o select * from sales_stream. Pero existe una función de sistema muy útil que conviene conocer: SYSTEM$STREAM_HAS_DATA. Puedes usarla en una sentencia select y devolverá TRUE o FALSE según si el stream tiene datos o no.
select
SYSTEM$STREAM_HAS_DATA('SALES_STREAM')
as stream_has_data;
-- returns FALSE since we just reset the offset by consuming the stream in DML.
CHANGES: una alternativa de solo lectura a los streams
Cuando el change tracking está activado —ya sea con alter table <table_name> set change_tracking = TRUE; o con create stream <stream_name> on table <table_name>—, puedes consultar los cambios desde un punto específico en el tiempo, incluso si el offset ya se reinició.
Al agregar la palabra clave changes a la cláusula from y pasar un at (timestamp => <timestamp>, puedes ver todos los cambios ocurridos desde ese timestamp, sin reiniciar el offset.
set ts = dateadd('hours', -3, current_timestamp);
SELECT *
FROM fake_sales_orders
CHANGES(INFORMATION => DEFAULT)
AT(TIMESTAMP => $ts);
La consulta anterior muestra todos los cambios en la tabla durante las últimas 3 horas. Las columnas de metadata se devuelven en los resultados, así que puedes usarlas en tu proceso de transformación.
Cuándo usar changes en lugar de streams
Puede ser buena idea usar changes si:
- Tienes varios consumidores ELT sobre la misma fuente y no quieres administrar múltiples streams.
- Estás extrayendo datos fuera de Snowflake. Por ejemplo, al cargar datos de Snowflake hacia Mixpanel o Amplitude tiene sentido almacenar tu propio cursor de timestamp y seleccionar los datos que cambiaron desde ese momento. Esto se debe a que:
- Puede que no tengas ninguna acción DML dentro de Snowflake para limpiar un stream.
- Quieres flexibilidad para recargar una porción específica de los datos.
El tema de "seleccionar desde changes" da para su propio post, ya que hay muchos ejemplos y casos de uso; aquí solo lo menciono brevemente para que quede completo.
Usar Dynamic Tables en lugar de Streams
Antes de crear un nuevo proceso de transformación con streams, vale la pena considerar si la funcionalidad nativa de Dynamic Tables de Snowflake ofrece una solución más simple para tu caso. Muchas veces puedes lograr algo similar con una dynamic table en Snowflake, pero todo depende de lo que quieras hacer. Si tu objetivo es aislar registros nuevos o modificados, ¡Streams y Changes son herramientas excelentes!
Frequently asked
questions
¿Cuánto cuestan los streams?
El costo principal de los Streams es el cómputo asociado a consultar el stream o usarlo en un paso de transformación.
Una stream table en sí no contiene datos, aunque puedas consultarla como si los tuviera. Como los datos modificados no se replican, los streams tienen costos de almacenamiento muy bajos. Cuando activas el change tracking en una tabla, se agregan tres columnas de metadata a la tabla fuente. El único costo adicional de almacenamiento es el pequeño espacio que ocupan esas columnas extra.
Revisa aquí los detalles sobre time travel y tiempo de retención de datos. Para un repaso de los costos de Snowflake, consulta la Guía de Precios y Facturación de Snowflake de SELECT.
¿Se pueden crear varios streams sobre la misma tabla?
Puedes crear tantos streams sobre una tabla como quieras. La buena práctica es que cada consumidor o tabla destino tenga su propio stream asociado. No uses un mismo stream para escribir en dos tablas distintas, porque el offset se limpiará y tus datos quedarán desincronizados. Si quieres transformar una misma tabla fuente de 5 formas distintas, puedes crear 5 streams sin problema.
¿Cuáles son las limitaciones?
Como vimos en el ejemplo anterior, puedes habilitar un stream sobre una vista igual que sobre una tabla. Pero hay algunas limitaciones:
- Las tablas subyacentes deben ser tablas nativas de Snowflake.
- Se admiten vistas anidadas, CTEs y subconsultas. Pero la consulta SQL totalmente expandida solo puede usar estas operaciones: proyecciones, filtros, union all, inner join o cross join. Esto significa que
unionsinallyleft outer joinno son compatibles.
Para más detalles, revisa la documentación.
¿Cómo se administran los streams?
Puedes encontrar todos los streams de tu cuenta, base de datos o schema con cualquiera de estos comandos:
show streams in account;
show streams in database <db_name>;
show streams in schema <qualified_schema_name>;
show streams; -- uses your worksheet or connection context / default schema.
En la UI, puedes encontrar los streams dentro de un schema:
Los streams se eliminan con el comando drop: drop stream db.schema.stream_name;
¡Esperamos que ahora te sientas con la confianza para usar streams en producción! Los Streams son una excelente forma de capturar datos nuevos o modificados en tablas fuente grandes. Se usan con mayor frecuencia cuando la fuente tiene un volumen considerable y necesitas una manera confiable de capturar de forma incremental los registros nuevos o modificados.
Jeff es Consultor de Data y Analytics con más de 15 años de experiencia automatizando insights y usando datos para controlar procesos de negocio. En lo tecnológico, se especializa en Snowflake + dbt + Tableau. En lo sectorial, tiene experiencia en Servicios Públicos, Ensayos Clínicos, Editorial, CPG y Manufactura. Escríbele cuando quieras a [email protected].