Was ich an Snowflake besonders schätze: die vielen Metadaten, die allen Nutzern programmatisch und ohne Zusatzkosten zur Verfügung stehen. Die Snowflake-Datenbank bietet Hunderte verschiedener Views, auf die Sie per SQL zugreifen können – damit lässt sich praktisch jede Frage zur eigenen Snowflake-Nutzung beantworten.
Der Query History Datensatz gehört zu den meistgenutzten der Snowflake-Datenbank, denn er enthält jede Menge nützlicher Metadaten zu jeder Query, die in Ihrem Account ausgeführt wird. Damit lassen sich zahlreiche Anwendungsfälle abdecken – etwa die Analyse historischer Query-Laufzeiten, das Aufspüren teurer Queries oder die Auswertung von Fehlerraten.
In diesem Beitrag zeige ich Ihnen 9 Beispiele aus der Praxis, die Sie noch heute in Ihrem Account ausprobieren können.
Zugriff auf die Query History
Bevor wir uns die Beispiele ansehen, kurz die 3 Wege, über die Sie auf die Query History zugreifen können.
Über die Snowsight-UI
Am schnellsten starten Sie über die Snowsight-UI im Reiter "Monitoring".
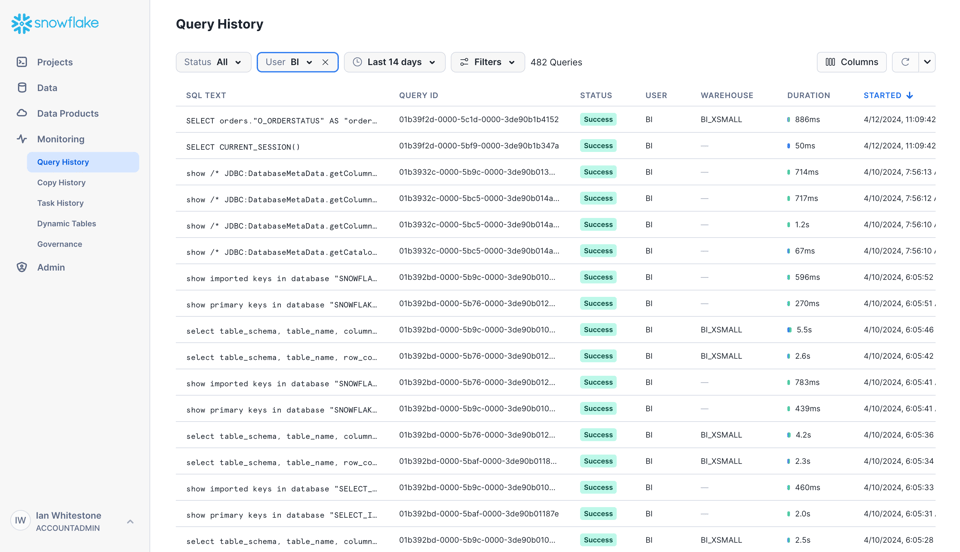
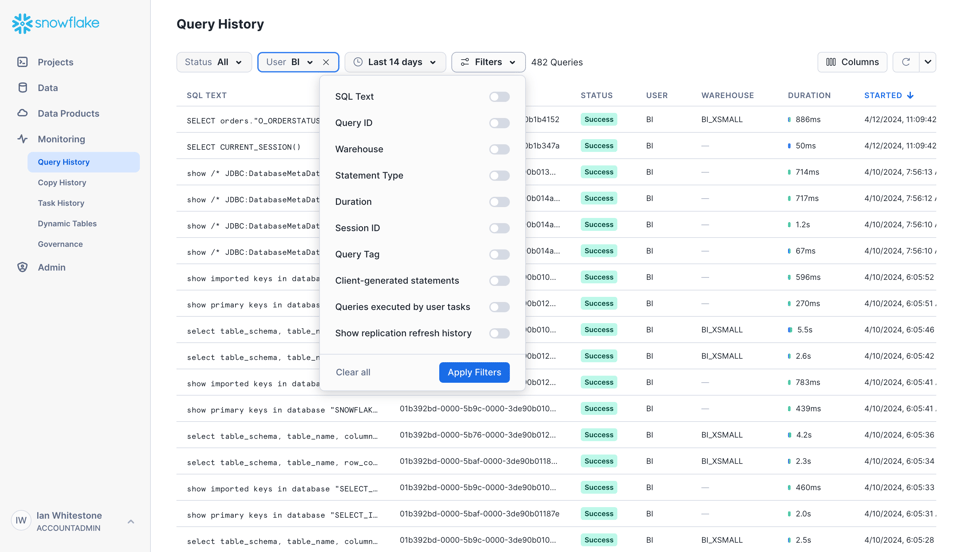
In der UI können Sie verschiedene Filter setzen und zusätzliche Spalten einblenden.
Wichtig: Die UI zeigt nur Queries der letzten 14 Tage:
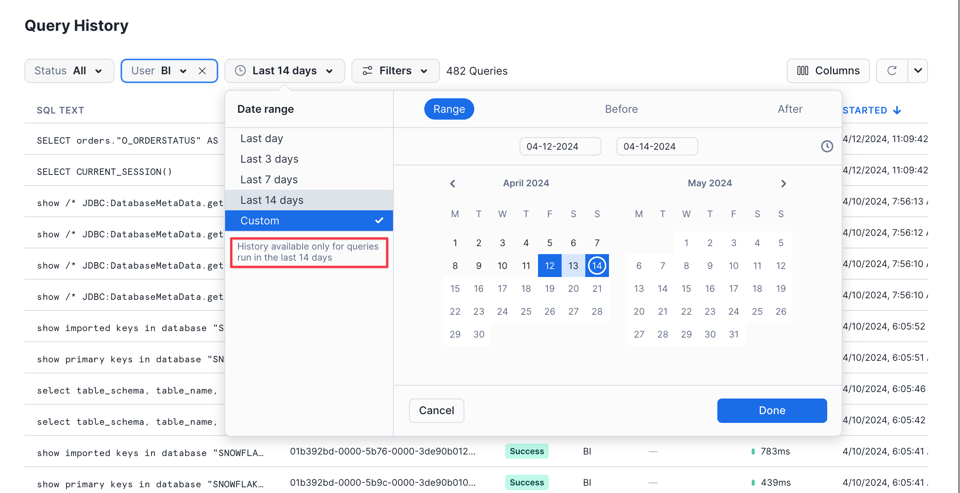
Die UI eignet sich vor allem dafür, schnell nachzusehen, welche Queries kürzlich liefen oder gerade laufen. Sobald Sie flexiblere Filter oder zusätzliche Daten brauchen, wechseln Sie üblicherweise zu einer der beiden folgenden Methoden.
Information Schema Table Functions (information_schema.query_history)
Dieselben Daten wie in der UI erhalten Sie über die Table Function information_schema.query_history() – allerdings nur für die letzten 7 Tage. Der Vorteil: Sie können auch Daten zu Queries abrufen, die gerade ausgeführt werden.
Hier ein Beispiel, mit dem Sie die letzten 100 Queries Ihres Accounts abrufen:
select *
from table(snowflake.information_schema.query_history())
order by start_time
;
Wenn Sie mehr Ergebnisse benötigen, lassen sich über das Argument RESULT_LIMIT bis zu 10000 Datensätze zurückgeben (Standard: 100):
select *
from table(snowflake.information_schema.query_history(result_limit=>10000))
order by start_time
;
Mit den Parametern end_time_range_start und end_time_range_end lässt sich ein eigener Zeitraum festlegen.
select
*
from table(snowflake.information_schema.query_history(
end_time_range_start=>dateadd('hours',-1,current_timestamp()),
end_time_range_end=>current_timestamp(),
result_limit=>10000
))
order by start_time
;
Sie können außerdem die zurückgegebenen Spalten einschränken oder Filter ergänzen. Achtung: Filter greifen erst im Nachhinein – Snowflake liefert zunächst 10000 Datensätze und filtert diese anschließend.
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history(result_limit=>10000))
where
user_name='IAN'
order by start_time
Wenn möglich, sollten Sie zum Filtern die anderen verfügbaren Table Functions nutzen:
QUERY_HISTORY_BY_SESSIONQUERY_HISTORY_BY_USERQUERY_HISTORY_BY_WAREHOUSE
Das obige Beispiel ließe sich so umschreiben:
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history_by_user(user_name=>'IAN', result_limit=>10000))
order by start_time
Latenz & Datenaufbewahrung
Der größte Vorteil der Table Function information_schema.query_history(): keine Latenz. Wurde eine Query vor einer Sekunde abgeschlossen, taucht sie sofort im Ergebnis auf. Dasselbe gilt für Queries, die noch laufen.
Die Nachteile:
- Sie enthält nur Queries der letzten 14 Tage.
- Sie können nur die Ergebnisse von 10K Queries analysieren.
- Table Functions sind weniger intuitiv als ein View oder eine Tabelle.
Wer ältere Queries oder Trends über längere Zeiträume auswerten möchte, kommt um den unten beschriebenen View account_usage nicht herum.
Account Usage View (account_usage.query_history)
Der View snowflake.account_usage.query_history ist meine bevorzugte Methode, um die Query History auszuwerten. Sie müssen sich nicht mit der Syntax von Table Functions herumschlagen und können Daten der letzten 365 Tage flexibel analysieren.
Hier ein Beispiel, in dem ich die Anzahl der Queries eines Nutzers in den letzten 30 Tagen zähle:
select count(*)
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and user_name='IAN'
order by start_time desc
Eine vollständige Übersicht der verfügbaren Spalten finden Sie in der Snowflake-Dokumentation.
Latenz & Datenaufbewahrung
Der View snowflake.account_usage.query_history kann eine Latenz von bis zu 45 Minuten haben. In der Praxis sind die Daten allerdings meist deutlich schneller verfügbar.
Bei der Datenaufbewahrung deckt dieser View die letzten 365 Tage ab.
Sind wirklich alle Queries in der Query History enthalten?
Grundsätzlich tauchen alle in Snowflake ausgeführten Queries in der Query History auf – egal ob programmatisch ausgeführt, über die UI gestartet, von Tasks oder Stored Procedures ausgelöst oder aus Streamlit-Dashboards heraus abgesetzt. Die einzige Ausnahme sind kurz laufende Queries, die ausschließlich auf Hybrid Tables zugreifen. Wer diese analysieren möchte, muss auf den Aggregate Query History View zurückgreifen.
Datenaufbewahrung der Query History
Die Aufbewahrungsdauer hängt davon ab, wie Sie auf die Query History zugreifen:
- Snowsight-UI: 14 Tage
- Information Schema Query History Table Function: 14 Tage
- Account Usage Query History View: 365 Tage
Nach diesen Grundlagen geht es jetzt an die Praxisbeispiele. Alles Folgende basiert auf dem oben beschriebenen Account Usage View.
1\. Die am längsten laufenden Queries identifizieren
Um die am längsten laufenden Queries der letzten 30 Tage zu finden, sortieren Sie nach der Spalte total_elapsed_time:
select
query_id,
total_elapsed_time/1000 as total_elapsed_time_s, -- convert to seconds
user_name,
query_text
from snowflake.account_usage.query_history
where
start_time > current_date - 30
order by total_elapsed_time desc
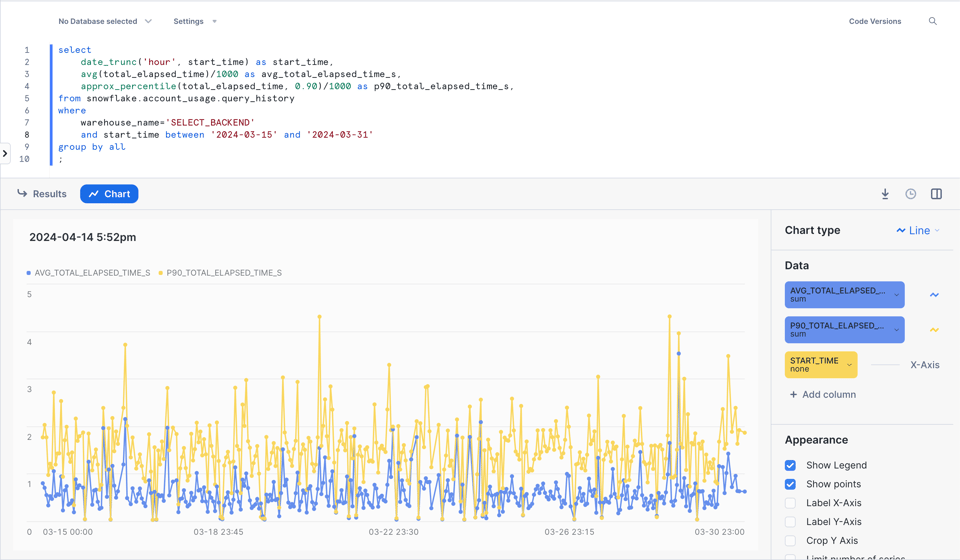
2\. Query-Performance im Zeitverlauf analysieren
Hier ein Beispiel, mit dem Sie die durchschnittliche Laufzeit und das 90. Perzentil der Query-Performance pro Stunde in einem bestimmten Warehouse analysieren.
select
date_trunc('hour', start_time) as start_time,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
approx_percentile(total_elapsed_time, 0.90)/1000 as p90_total_elapsed_time_s,
from snowflake.account_usage.query_history
where
warehouse_name='SELECT_BACKEND'
and start_time between '2024-03-15' and '2024-03-31'
group by 1
;
Direkt in Snowsight bekommen Sie sogar eine ansprechende Visualisierung dazu!
3\. Wiederkehrende Query-Muster mit query\_parameterized\_hash erkennen
Snowflake hat 2023 eine neue Spalte namens query_parameterized_hash eingeführt. Der Wert entsteht, indem Literale aus der Query entfernt und der Query-Text anschließend gehasht wird. Damit lassen sich wiederkehrende Queries erkennen, die sich nur durch Parameterwerte unterscheiden. Mehr zu query_parameterized_hash und seinen Einschränkungen (er funktioniert nur mit bestimmten Vergleichsoperationen) finden Sie hier.
Hier ein Beispiel, das die Top 100 Query-Muster nach Gesamtlaufzeit ermittelt. Zusätzlich liefert es den jüngsten Query-Text, Nutzernamen und Warehouse-Namen zum jeweiligen Query Parameterized Hash.
select
query_parameterized_hash,
count(*) as num_executions,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
sum(total_elapsed_time) as total_elapsed_time_s,
max_by(query_text, start_time) as latest_query_text,
max_by(user_name, start_time) as latest_user_name,
max_by(warehouse_name, start_time) as latest_warehouse_name
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by total_elapsed_time_s desc
limit 100
;
4\. Top-Queries nach Query-Typ
Snowflake stellt eine Spalte query_type bereit, mit der Sie die unterschiedlichen Query-Arten in Ihrem Account unterscheiden können. Beispiele sind SELECT, CREATE_TABLE_AS_SELECT, INSERT, DELETE und [MERGE](/blog/effectively-using-the-merge-command-in-snowflake).
So ermitteln Sie die häufigsten Query-Typen in Ihrem Account der letzten 7 Tage:
select
query_type,
count(*) as cnt
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by cnt desc
5\. Queries eines Nutzers in den letzten 3 Monaten
Um alle Queries eines Nutzers aus den letzten 3 Monaten abzurufen, führen Sie Folgendes aus:
select *
from snowflake.account_usage.query_history
where
user_name='IAN'
and start_time > current_date - 90
6\. Reine Metadaten-Queries
Manche Queries kommen ohne laufendes Virtual Warehouse aus. Sie lassen sich rein über Metadaten aus dem Cloud Services Layer beantworten. Beispiel: select count(*) from my_table – diese Query lässt sich vollständig aus Metadaten bedienen und benötigt kein Warehouse. Ebenso umgeht eine Query das Warehouse, wenn sie in den letzten 24 Stunden bereits einmal ausgeführt wurde – Snowflake liefert das Ergebnis dann sofort aus dem globalen Result Cache.
Solche Queries erkennen Sie daran, dass keine Warehouse-Größe hinterlegt ist:
select *
from snowflake.account_usage.query_history
where
warehouse_size is null
and start_time > current_date - 90
6\. Queries mit hoher Cloud-Services-Nutzung
Die oben erwähnten reinen Metadaten-Queries sind in der Regel kostenlos, da sie kein laufendes Virtual Warehouse benötigen. Snowflake berechnet Cloud Services nur, wenn deren Anteil 10 % Ihrer täglichen Compute-Nutzung übersteigt.
Liegt Ihre Cloud-Services-Nutzung über diesen 10 %, finden Sie die entsprechenden Queries mit folgender Abfrage:
select
query_text,
partitions_scanned,
partitions_total,
partitions_scanned/partitions_total as fraction_scanned,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and bytes_scanned/power(1024,3) > 1
and fraction_scanned > 0.8
limit 100
7\. Queries mit schlechtem Pruning
Ist die abgefragte Tabelle nicht sauber geclustert oder fehlt ein Filter, der die abgerufenen Daten eingrenzt, scannt Ihre Query am Ende sehr viele Micro-Partitions. Da das Scannen von Daten teuer ist, führt das zu längeren Laufzeiten und höheren Kosten.
Hier ein Beispiel zur Identifikation von Queries mit schlechtem Pruning. Wir definieren schlechtes Pruning als Queries, die mehr als 1 GB Daten und mehr als 80 % der Micro-Partitions scannen.
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
8\. Queries mit Spilling auf Disk & Remote Storage
Geht dem Virtual Warehouse, auf dem Ihre Query läuft, der Arbeitsspeicher aus, beginnt die Query, auf die lokale Disk auszulagern (Spilling). Ist auch dort kein Platz mehr, geht es weiter in den Remote Storage. Beides ist langsam und teuer. Lässt sich Ihre Query nicht so umschreiben, dass das Spilling entfällt (etwa durch geringere Datenmengen), ist es meist günstiger, sie auf einem größeren Virtual Warehouse auszuführen.
So identifizieren Sie Queries mit Spilling auf Disk und Remote Storage:
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
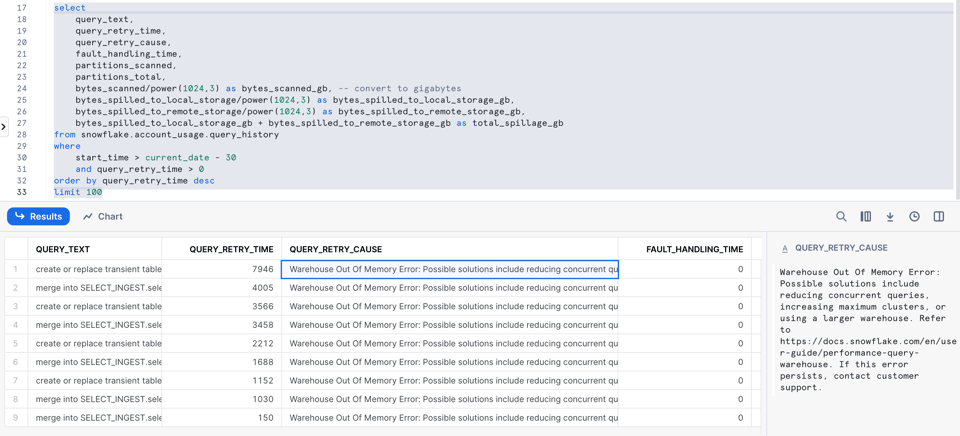
9\. Queries mit Out-of-Memory-Fehlern und Retries
Wie oben beschrieben, versucht Snowflake, Out-of-Memory-Fehler abzufangen, indem die Query auf Disk ausgelagert wird. Manchmal laufen jedoch so viele Queries gleichzeitig, dass der Node abstürzt. In diesem Fall wiederholt Snowflake die Query automatisch.
Snowflake hat kürzlich neue Query-Retry-Spalten ergänzt, mit denen Sie solche Vorfälle erkennen können.
select
query_text,
query_retry_time,
query_retry_cause,
fault_handling_time,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and query_retry_time > 0
Code ausklappen
query_retry_cause liefert sogar Hinweise, wie sich das Problem beheben lässt!
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder und CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT leitete er 6 Jahre lang Full-Stack-Teams aus Data Science und Engineering bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.