Uma das coisas que mais gosto no Snowflake é a quantidade de metadados que ficam acessíveis de forma programática para todos os usuários, sem custo adicional! O banco de dados do Snowflake reúne centenas de views diferentes que os usuários podem consultar via SQL para responder praticamente qualquer pergunta sobre o uso da plataforma.
O dataset Query History é um dos mais usados desse banco, porque traz vários metadados úteis sobre cada query executada na sua conta. Dá para usá-lo em diversos cenários, como analisar tempos de execução históricos, encontrar queries caras ou acompanhar taxas de falha.
Neste post, vou mostrar 9 exemplos reais que você já pode rodar na sua conta hoje mesmo.
Acessando o Query History
Antes de partir para os exemplos, vamos passar rapidamente pelas 3 formas de acessar o query history.
Pela interface do Snowsight
O jeito mais fácil de começar a usar o dataset Query History é pela interface do Snowsight, na aba Monitoring.
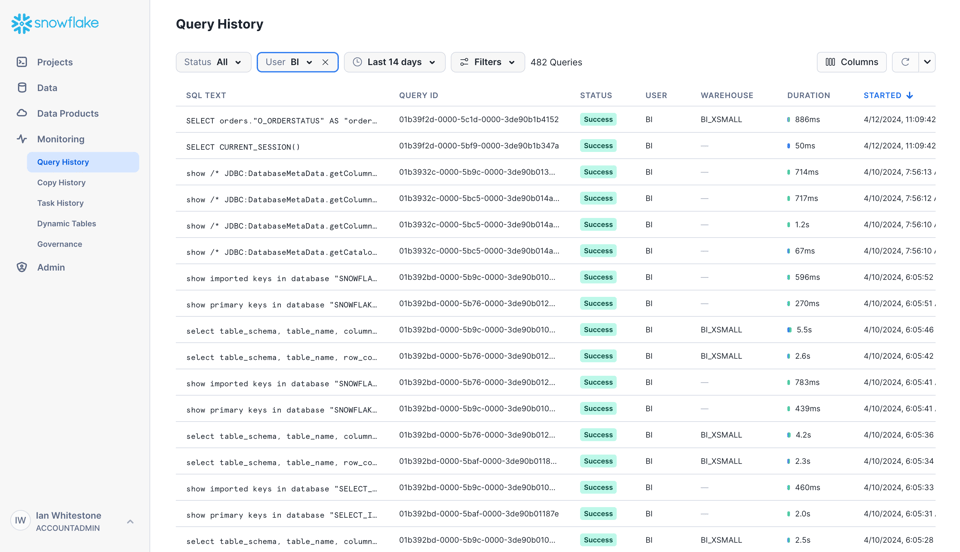
Pela interface, você pode aplicar diversos filtros e visualizar colunas adicionais.
Vale lembrar que a interface mostra apenas as queries dos últimos 14 dias:
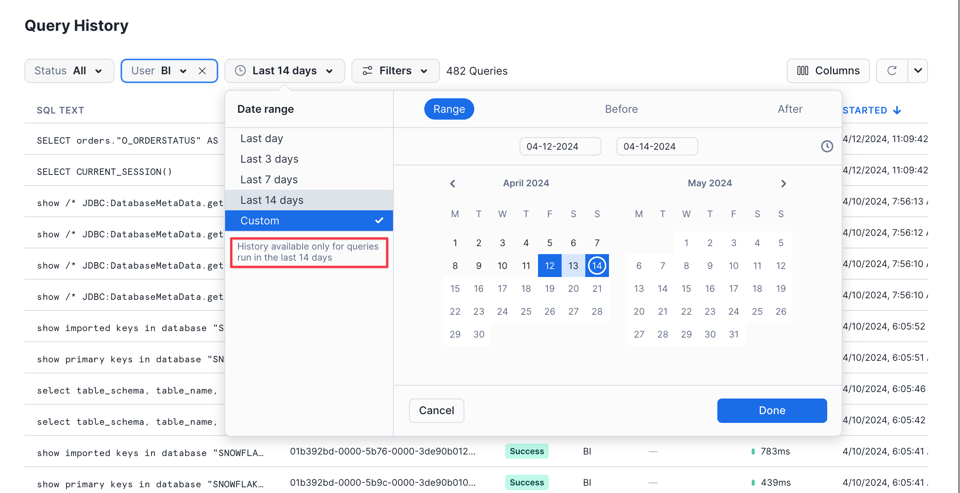
A interface é mais útil para checar rapidamente queries que rodaram há pouco ou que estão em execução. Quando o caso de uso exige filtros mais flexíveis ou dados adicionais, os usuários costumam migrar para um dos dois próximos métodos.
Funções de tabela do Information Schema (information_schema.query_history)
Os mesmos dados exibidos na interface estão disponíveis pela função de tabela information_schema.query_history(), mas você só consegue acessar os dados dos últimos 7 dias. Em compensação, dá para recuperar dados de queries que ainda estão em execução!
Veja um exemplo para trazer as últimas 100 queries executadas na sua conta:
select *
from table(snowflake.information_schema.query_history())
order by start_time
;
Se quiser trazer mais, dá para retornar até 10.000 com o argumento RESULT_LIMIT (o padrão é 100):
select *
from table(snowflake.information_schema.query_history(result_limit=>10000))
order by start_time
;
Você pode definir um intervalo de tempo personalizado com os parâmetros end_time_range_start e end_time_range_end.
select
*
from table(snowflake.information_schema.query_history(
end_time_range_start=>dateadd('hours',-1,current_timestamp()),
end_time_range_end=>current_timestamp(),
result_limit=>10000
))
order by start_time
;
Também é possível restringir quais colunas serão retornadas ou adicionar filtros. Importante: qualquer filtro que você adicionar será aplicado depois, ou seja, o Snowflake primeiro retorna 10.000 registros e só então faz a filtragem.
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history(result_limit=>10000))
where
user_name='IAN'
order by start_time
Sempre que possível, prefira as outras funções de tabela disponíveis para aplicar filtros:
QUERY_HISTORY_BY_SESSIONQUERY_HISTORY_BY_USERQUERY_HISTORY_BY_WAREHOUSE
O exemplo acima poderia ser reescrito assim:
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history_by_user(user_name=>'IAN', result_limit=>10000))
order by start_time
Latência e retenção de dados
A grande vantagem da função de tabela information_schema.query_history() é que ela não tem latência. Se uma query terminou há um segundo, ela já aparece no resultado. O mesmo vale para queries em execução.
As principais desvantagens são:
- contém apenas queries dos últimos 14 dias;
- só dá para analisar o resultado de 10 mil queries;
- funções de tabela são menos intuitivas do que consultar uma view/tabela.
Se precisar analisar queries mais antigas ou tendências em um período mais longo, você vai depender da view account_usage, que veremos a seguir.
View Account Usage (account_usage.query_history)
A view snowflake.account_usage.query_history é o meu jeito preferido de analisar e acessar o dataset Query History. Você não precisa lembrar como trabalhar com funções de tabela e ainda consegue analisar, com flexibilidade, os dados do último ano.
Veja um exemplo em que conto o número de queries de um usuário nos últimos 30 dias:
select count(*)
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and user_name='IAN'
order by start_time desc
Para a lista completa de colunas disponíveis, consulte a documentação do Snowflake.
Latência e retenção de dados
A view snowflake.account_usage.query_history pode ter latência de até 45 minutos. Dito isso, na prática os dados costumam aparecer bem antes.
Quanto à retenção, essa view guarda os dados dos últimos 365 dias.
Todas as queries entram no Query History?
De modo geral, sim: todas as queries executadas no Snowflake aparecem no Query History. Isso inclui queries executadas programaticamente, queries rodadas pela interface, queries disparadas por tasks ou stored procedures e queries executadas por dashboards do Streamlit. As únicas exceções são as queries de curta duração que operam exclusivamente sobre hybrid tables. Para analisar essas queries, você precisará recorrer à view aggregate query history.
Retenção de dados do Query History
O período de retenção dos dados do Query History depende do método usado para acessar o dataset:
- Interface do Snowsight: 14 dias
- Função de tabela Query History do Information Schema: 14 dias
- View Query History do Account Usage: 365 dias
Agora que cobrimos o básico sobre o Query History e como acessá-lo, vamos aos exemplos reais! Tudo daqui em diante vai usar a view account usage citada acima.
1\. Identifique as queries mais demoradas
Para encontrar as queries mais demoradas dos últimos 30 dias, basta ordenar pela coluna total_elapsed_time:
select
query_id,
total_elapsed_time/1000 as total_elapsed_time_s, -- convert to seconds
user_name,
query_text
from snowflake.account_usage.query_history
where
start_time > current_date - 30
order by total_elapsed_time desc
2\. Analise a performance das queries ao longo do tempo
Veja um exemplo para analisar a performance média e o percentil 90 das queries em cada hora, dentro de um determinado warehouse.
select
date_trunc('hour', start_time) as start_time,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
approx_percentile(total_elapsed_time, 0.90)/1000 as p90_total_elapsed_time_s,
from snowflake.account_usage.query_history
where
warehouse_name='SELECT_BACKEND'
and start_time between '2024-03-15' and '2024-03-31'
group by 1
;
Você ainda consegue uma visualização bacana direto no Snowsight!
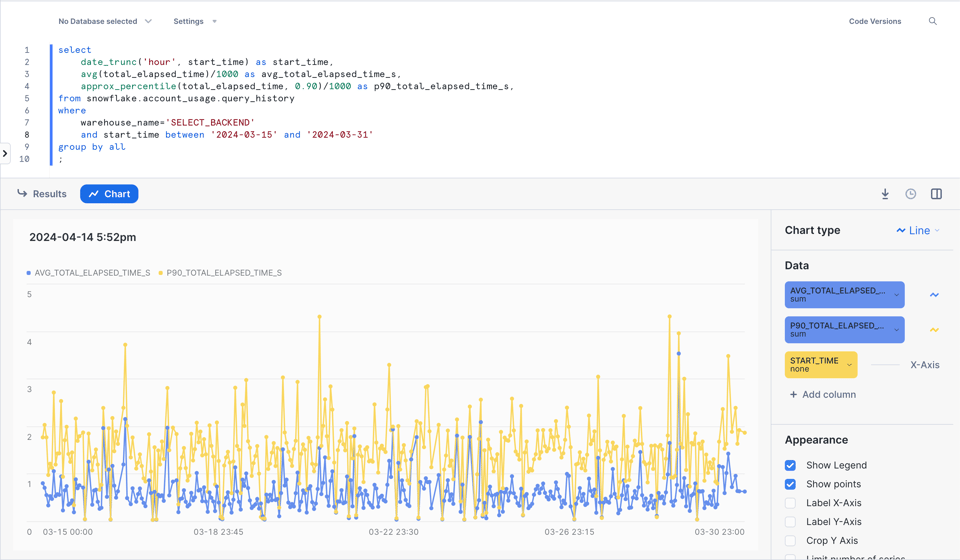
3\. Identifique padrões recorrentes de query com query\_parameterized\_hash
Em 2023, o Snowflake lançou uma nova coluna chamada query_parameterized_hash. Esse valor é gerado removendo os literais da query e aplicando um hash no texto resultante. A ideia é ajudar você a identificar queries recorrentes que diferem apenas levemente por causa dos valores dos parâmetros. Saiba mais sobre o query_parameterized_hash aqui, incluindo suas limitações (ele só funciona com certas operações de comparação).
Veja um exemplo para identificar os 100 principais padrões de query com base no tempo total decorrido. O exemplo também traz o texto mais recente da query, o nome do usuário e o warehouse associados ao query parameterized hash.
select
query_parameterized_hash,
count(*) as num_executions,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
sum(total_elapsed_time) as total_elapsed_time_s,
max_by(query_text, start_time) as latest_query_text,
max_by(user_name, start_time) as latest_user_name,
max_by(warehouse_name, start_time) as latest_warehouse_name
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by total_elapsed_time_s desc
limit 100
;
4\. Top queries por tipo
O Snowflake traz uma coluna query_type para ajudar você a diferenciar os tipos de queries executadas na sua conta. Alguns exemplos: SELECT, CREATE_TABLE_AS_SELECT, INSERT, DELETE e [MERGE](/blog/effectively-using-the-merge-command-in-snowflake).
Veja uma query para identificar os tipos mais comuns na sua conta nos últimos 7 dias:
select
query_type,
count(*) as cnt
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by cnt desc
5\. Queries executadas por um usuário nos últimos 3 meses
Para trazer todas as queries executadas por um usuário nos últimos 3 meses, rode o seguinte:
select *
from snowflake.account_usage.query_history
where
user_name='IAN'
and start_time > current_date - 90
6\. Queries só de metadata
Algumas queries não exigem um virtual warehouse em execução. Elas podem ser atendidas pela camada de Cloud Services usando apenas metadata. Por exemplo, ao rodar select count(*) from my_table, essa query é respondida totalmente a partir da metadata e não precisa de warehouse. Da mesma forma, uma query pode dispensar o warehouse se já tiver sido executada nas últimas 24 horas — nesse caso, o Snowflake retorna o resultado na hora a partir do cache global de resultados.
Para identificar essas queries, filtre pelas que não têm um tamanho de warehouse registrado:
select *
from snowflake.account_usage.query_history
where
warehouse_size is null
and start_time > current_date - 90
6\. Queries com alto uso de Cloud Services
As queries só de metadata citadas acima costumam ser gratuitas, já que não exigem um virtual warehouse em execução, e o Snowflake só cobra por Cloud Services quando o uso ultrapassa 10% do seu consumo diário de compute.
Se o seu uso de Cloud Services passar dos 10%, dá para identificar as queries com alto consumo desse recurso com a seguinte query:
select
query_text,
partitions_scanned,
partitions_total,
partitions_scanned/partitions_total as fraction_scanned,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and bytes_scanned/power(1024,3) > 1
and fraction_scanned > 0.8
limit 100
7\. Queries com pruning ruim
Se a tabela consultada não está bem clusterizada ou se você não inclui um filtro para limitar os dados acessados, sua query vai acabar escaneando muitas micro-partitions. Como escanear dados custa caro, isso resulta em queries mais lentas e mais caras.
Veja um exemplo de query para identificar queries com pruning ruim. Neste exemplo, vamos considerar pruning ruim toda query que escaneia mais de 1GB de dados e mais de 80% das micro-partitions.
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
8\. Queries com spilling para disco e armazenamento remoto
Quando o virtual warehouse onde a query está rodando fica sem memória, a query começa a fazer spilling para o disco local. Quando o disco local também enche, o spilling passa para o armazenamento remoto. Isso é lento e caro. Se não der para reescrever a query e eliminar o spilling em disco (por exemplo, processando menos dados), provavelmente sai mais barato rodar a query em um virtual warehouse maior.
Veja como identificar queries com spilling para disco e armazenamento remoto:
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
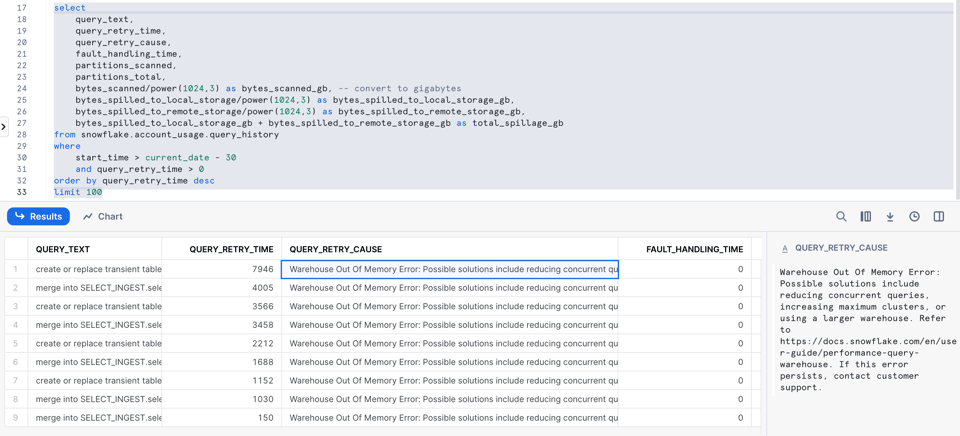
9\. Queries com erros de falta de memória e retries
Como vimos acima, o Snowflake tenta lidar com erros de falta de memória de forma elegante, fazendo a query usar spilling para o disco. Mas, às vezes, há queries demais rodando ao mesmo tempo, o que faz o nó cair. Quando isso acontece, o Snowflake refaz a query automaticamente.
Recentemente, o Snowflake adicionou novas colunas de retry de query para ajudar você a identificar essas situações.
select
query_text,
query_retry_time,
query_retry_cause,
fault_handling_time,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and query_retry_time > 0
Expandir código
O query_retry_cause ainda traz algumas dicas de como resolver o problema!
Ian Whitestone·Co-founder e CEO da SELECT
Ian é Co-founder e CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia no Shopify e no Capital One. No Shopify, ele liderou os esforços para otimizar o data warehouse e ampliar a observabilidade de custos.