Una de las cosas que más me gustan de Snowflake es toda la metadata que queda disponible de forma programática para todos los usuarios, ¡sin costo adicional! La base de datos de Snowflake incluye cientos de vistas a las que se accede vía SQL para responder prácticamente cualquier pregunta sobre tu uso de Snowflake.
El dataset del Query History es uno de los más usados de la base de datos de Snowflake, ya que contiene un montón de metadata útil sobre cada query que se ejecuta en tu cuenta. El Query History sirve para una variedad de casos de uso: analizar tiempos históricos de ejecución, encontrar queries costosas o medir tasas de fallo.
En este post comparto 9 ejemplos reales que puedes correr en tu cuenta hoy mismo.
Cómo acceder al Query History
Antes de entrar en los ejemplos de uso, repasemos rápido las 3 formas de acceder al query history.
Desde la interfaz de Snowsight
La forma más sencilla de empezar a usar el dataset del Query History es desde la interfaz de Snowsight, en la pestaña Monitoring.
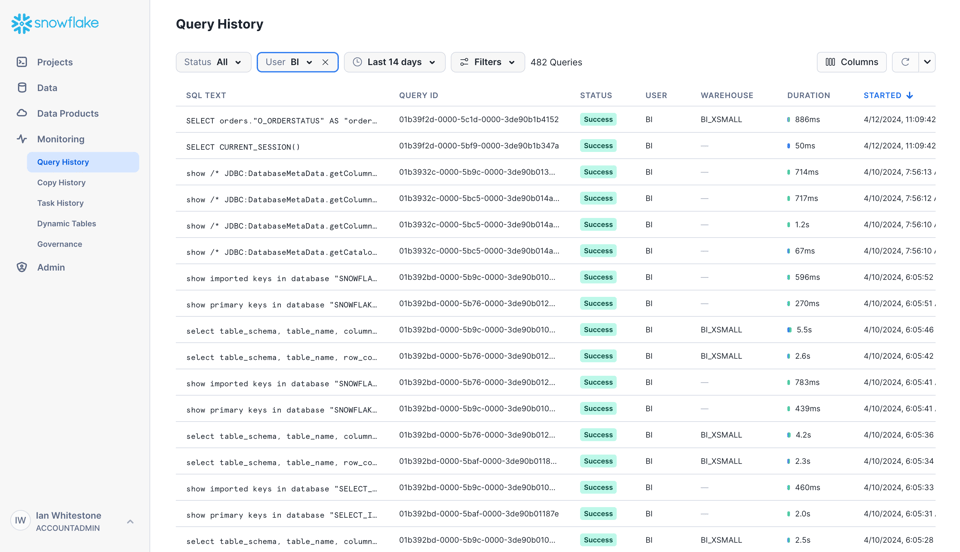
Desde la interfaz se pueden aplicar varios filtros y ver columnas adicionales.
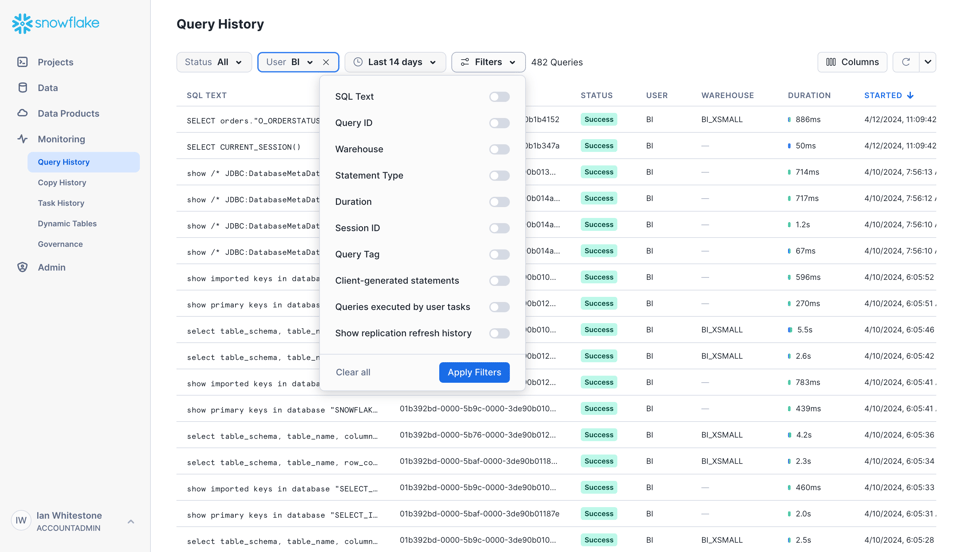
Ten en cuenta que la interfaz solo muestra las queries de los últimos 14 días:
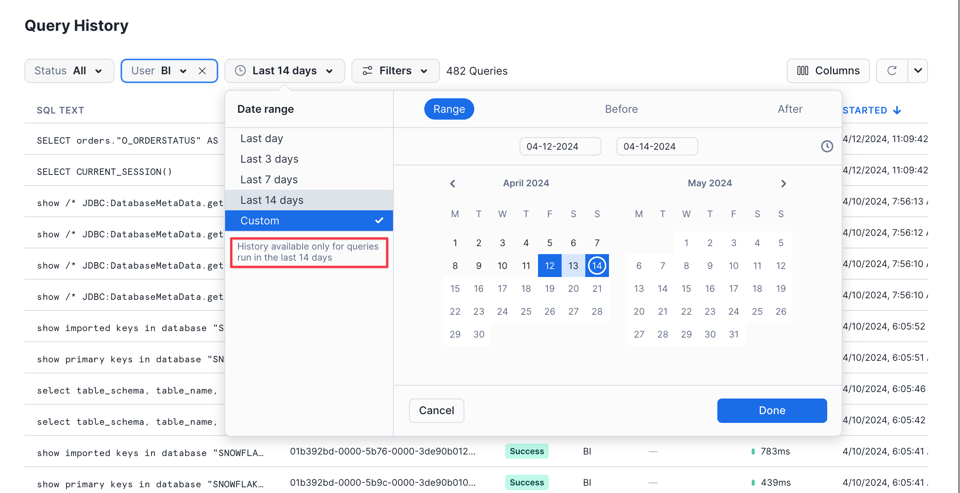
La interfaz es ideal para revisar rápido las queries que se ejecutaron hace poco o las que están corriendo en este momento. Cuando el caso de uso pide un filtrado más flexible o data adicional, lo normal es pasar a alguno de los siguientes dos métodos.
Funciones de tabla del Information Schema (information_schema.query_history)
La misma data que se ve en la interfaz está disponible a través de la función de tabla information_schema.query_history(), pero con esta solo accedes a la data de los últimos 7 días. Lo bueno es que puedes obtener data de queries que se están ejecutando en este momento.
Acá tienes un ejemplo para traer las últimas 100 queries ejecutadas en tu cuenta:
select *
from table(snowflake.information_schema.query_history())
order by start_time
;
Si quieres traer más, puedes devolver hasta 10000 con el argumento RESULT_LIMIT (el valor por defecto es 100):
select *
from table(snowflake.information_schema.query_history(result_limit=>10000))
order by start_time
;
Puedes definir un rango de tiempo personalizado con los parámetros end_time_range_start y end_time_range_end.
select
*
from table(snowflake.information_schema.query_history(
end_time_range_start=>dateadd('hours',-1,current_timestamp()),
end_time_range_end=>current_timestamp(),
result_limit=>10000
))
order by start_time
;
También puedes limitar qué columnas se devuelven o agregar filtros. Ojo: cualquier filtro que apliques se ejecuta después, es decir, Snowflake primero devuelve los 10000 registros y recién ahí los filtra.
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history(result_limit=>10000))
where
user_name='IAN'
order by start_time
Siempre que se pueda, conviene apoyarse en las otras funciones de tabla disponibles para filtrar:
QUERY_HISTORY_BY_SESSIONQUERY_HISTORY_BY_USERQUERY_HISTORY_BY_WAREHOUSE
El ejemplo anterior se podría reescribir así:
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history_by_user(user_name=>'IAN', result_limit=>10000))
order by start_time
Latencia y retención de data
La principal ventaja de la función de tabla information_schema.query_history() es que no tiene latencia. Si una query terminó hace un segundo, ya aparece en su resultado. Lo mismo aplica a una query que sigue corriendo.
Las principales desventajas de este dataset son:
- solo contiene queries de los últimos 14 días
- solo se pueden analizar los resultados de 10K queries
- las funciones de tabla son menos intuitivas que consultar una vista o tabla
Si necesitas analizar queries más antiguas o ver tendencias en un período más largo, tendrás que recurrir a la vista account_usage que veremos a continuación.
Vista Account Usage (account_usage.query_history)
La vista snowflake.account_usage.query_history es mi forma favorita de analizar y acceder al dataset del Query History. No tienes que acordarte de cómo se trabaja con funciones de tabla y puedes analizar con flexibilidad la data del último año.
Acá tienes un ejemplo donde cuento la cantidad de queries de un usuario en los últimos 30 días:
select count(*)
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and user_name='IAN'
order by start_time desc
Para ver la lista completa de columnas disponibles, revisa la documentación de Snowflake.
Latencia y retención de data
La vista snowflake.account_usage.query_history puede tener una latencia de hasta 45 minutos. Dicho esto, en la práctica suele verse la data bastante antes.
En cuanto a retención, esta vista contiene data de los últimos 365 días.
¿Todas las queries aparecen en el Query History?
En términos generales, todas las queries que ejecutes en Snowflake van a aparecer en el Query History. Esto incluye queries ejecutadas de forma programática, queries lanzadas desde la interfaz, queries ejecutadas por tasks o stored procedures, y queries ejecutadas por dashboards de Streamlit. Las únicas queries que quedan fuera del Query History son las de corta duración que operan exclusivamente contra hybrid tables. Si necesitas analizar este tipo de queries, tendrás que recurrir a la vista aggregate query history.
Retención de data en el Query History
Los períodos de retención de data del Query History dependen del método que uses para acceder al dataset:
- Interfaz de Snowsight: 14 días
- Función de tabla del Information Schema Query History: 14 días
- Vista Account Usage Query History: 365 días
Ya cubrimos lo básico del Query History y cómo acceder a él, así que ¡vamos con los ejemplos reales! Todo lo que sigue se apoya en la vista account usage mencionada arriba.
1\. Identificar las queries con mayor tiempo de ejecución
Para identificar las queries con mayor tiempo de ejecución en los últimos 30 días, ordena por la columna total_elapsed_time:
select
query_id,
total_elapsed_time/1000 as total_elapsed_time_s, -- convertir a segundos
user_name,
query_text
from snowflake.account_usage.query_history
where
start_time > current_date - 30
order by total_elapsed_time desc
2\. Analizar el rendimiento de las queries a lo largo del tiempo
Acá tienes un ejemplo para analizar el rendimiento promedio y el percentil 90 de las queries por hora en un warehouse determinado.
select
date_trunc('hour', start_time) as start_time,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
approx_percentile(total_elapsed_time, 0.90)/1000 as p90_total_elapsed_time_s,
from snowflake.account_usage.query_history
where
warehouse_name='SELECT_BACKEND'
and start_time between '2024-03-15' and '2024-03-31'
group by 1
;
¡Y hasta puedes obtener una visualización muy clara directamente en Snowsight!
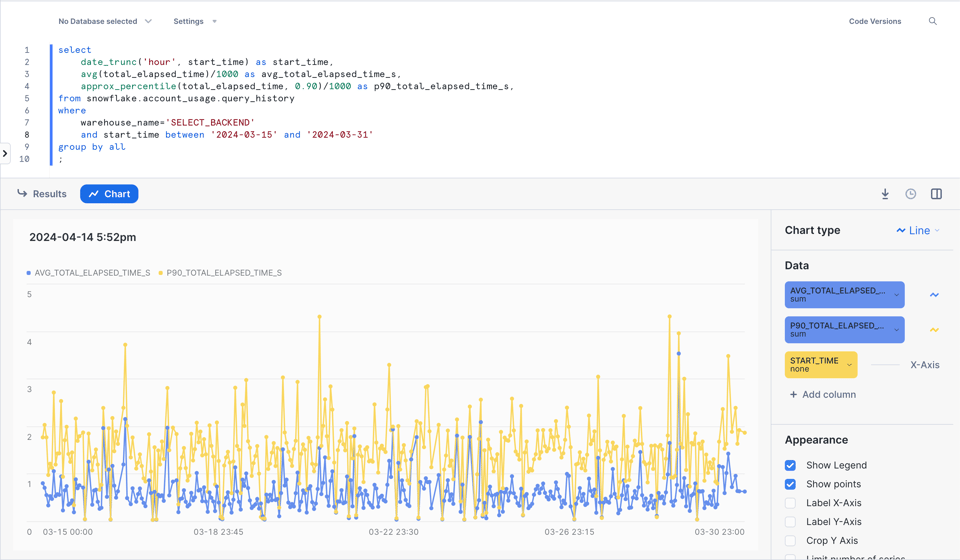
3\. Identificar patrones recurrentes de queries con query\_parameterized\_hash
Snowflake incorporó recientemente (en 2023) una nueva columna llamada query_parameterized_hash. Este valor se obtiene eliminando los literales de la query y luego aplicando un hash al texto. La idea es ayudarte a detectar queries recurrentes que solo difieren un poco por los valores de los parámetros. Puedes leer más sobre query_parameterized_hash aquí, junto con sus limitaciones (solo funciona con ciertas operaciones de comparación).
Acá tienes un ejemplo para identificar los 100 patrones de queries principales según el tiempo total transcurrido. El ejemplo también trae el último texto de query, el nombre de usuario y el warehouse asociados al query parameterized hash.
select
query_parameterized_hash,
count(*) as num_executions,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
sum(total_elapsed_time) as total_elapsed_time_s,
max_by(query_text, start_time) as latest_query_text,
max_by(user_name, start_time) as latest_user_name,
max_by(warehouse_name, start_time) as latest_warehouse_name
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by total_elapsed_time_s desc
limit 100
;
4\. Top de queries por tipo de query
Snowflake incluye una columna query_type que te ayuda a diferenciar entre los distintos tipos de queries que se ejecutan en tu cuenta. Algunos ejemplos son SELECT, CREATE_TABLE_AS_SELECT, INSERT, DELETE y [MERGE](/blog/effectively-using-the-merge-command-in-snowflake).
Acá tienes una query para identificar los tipos de query más comunes en tu cuenta durante los últimos 7 días:
select
query_type,
count(*) as cnt
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by cnt desc
5\. Queries ejecutadas por un usuario en los últimos 3 meses
Para traer todas las queries ejecutadas por un usuario en los últimos 3 meses, puedes correr lo siguiente:
select *
from snowflake.account_usage.query_history
where
user_name='IAN'
and start_time > current_date - 90
6\. Queries solo de metadata
Algunas queries no necesitan un virtual warehouse en ejecución. Pueden resolverse desde la capa de Cloud Services usando solo metadata. Por ejemplo, si corres select count(*) from my_table, esa query se puede responder íntegramente desde la metadata y no necesita ejecutarse en un warehouse. De la misma forma, una query puede evitar correr en un warehouse si ya se ejecutó en las últimas 24 horas: Snowflake la devuelve al instante desde la global result cache.
Para identificar estas queries, filtra por aquellas que no tienen un tamaño de warehouse asignado:
select *
from snowflake.account_usage.query_history
where
warehouse_size is null
and start_time > current_date - 90
6\. Queries con alto uso de Cloud Services
Las queries solo de metadata que vimos antes suelen ser gratis porque no requieren un virtual warehouse en ejecución, y Snowflake solo cobra por Cloud Services cuando supera el 10% del uso diario de cómputo.
Si tu uso de Cloud Services pasa ese 10%, puedes identificar las queries con alto consumo de cloud services con la siguiente query:
select
query_text,
partitions_scanned,
partitions_total,
partitions_scanned/partitions_total as fraction_scanned,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convertir a gigabytes
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and bytes_scanned/power(1024,3) > 1
and fraction_scanned > 0.8
limit 100
7\. Queries con mal pruning
Si la tabla que estás consultando no está bien clusterizada o no incluyes un filtro que limite la data a la que se accede, tu query terminará escaneando muchas micro-partitions. Y como escanear data es costoso, esto se traduce en queries más lentas y más caras.
Acá tienes un ejemplo para identificar queries con mal pruning. Para este ejemplo, definiremos mal pruning como las queries que escanean más de 1 GB de data y más del 80% de las micro-partitions.
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convertir a gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
8\. Queries con spilling a disco y almacenamiento remoto
Cuando el virtual warehouse en el que corre tu query se queda sin memoria, la query empieza a hacer spilling al disco local. Una vez que tampoco queda espacio en el disco local, el spilling pasa al almacenamiento remoto. Esto es lento y caro. Si no se puede reescribir la query para evitar el spilling (por ejemplo, procesando menos data), lo más probable es que salga más barato ejecutarla en un virtual warehouse más grande.
Así puedes identificar las queries que están haciendo spilling a disco y a almacenamiento remoto:
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convertir a gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
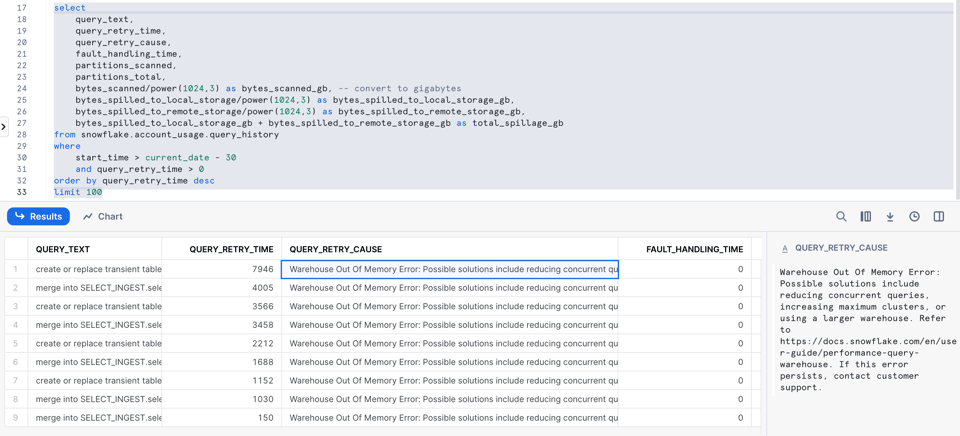
9\. Queries con errores de out-of-memory y reintentos
Como vimos antes, Snowflake intenta manejar los errores de out-of-memory haciendo que la query haga spilling a disco. Pero a veces hay demasiadas queries corriendo en paralelo y eso provoca que el nodo se caiga. Cuando pasa eso, Snowflake reintenta la query automáticamente.
Snowflake agregó recientemente nuevas columnas de reintento de queries que te ayudan a detectar cuándo está ocurriendo esto.
select
query_text,
query_retry_time,
query_retry_cause,
fault_handling_time,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convertir a gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and query_retry_time > 0
Expandir código
¡La columna query_retry_cause hasta incluye algunos tips para resolver el problema!
Ian Whitestone·Co-founder y CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, Ian lideró el trabajo de optimización del data warehouse y de mejora en la visibilidad de costos.