Uno degli aspetti che apprezzo di più di Snowflake è la mole di metadati resi accessibili a tutti gli utenti via codice, senza costi aggiuntivi. Il database Snowflake mette a disposizione centinaia di view interrogabili in SQL per rispondere praticamente a qualsiasi domanda sull'utilizzo di Snowflake.
Il dataset Query History è uno dei più utilizzati del database Snowflake, perché raccoglie numerosi metadati su ogni query eseguita nel proprio account. La Query History abilita casi d'uso molto diversi tra loro: analizzare i tempi di esecuzione storici, individuare le query più costose o studiare il tasso di fallimento delle query.
In questo articolo Le mostrerò 9 esempi concreti che può eseguire da subito nel suo account.
Accedere alla Query History
Prima di passare agli esempi pratici, vediamo rapidamente i 3 modi per accedere alla Query History.
Dall'interfaccia Snowsight
Il modo più semplice per iniziare a usare il dataset Query History è tramite l'interfaccia Snowsight, nella scheda Monitoring.
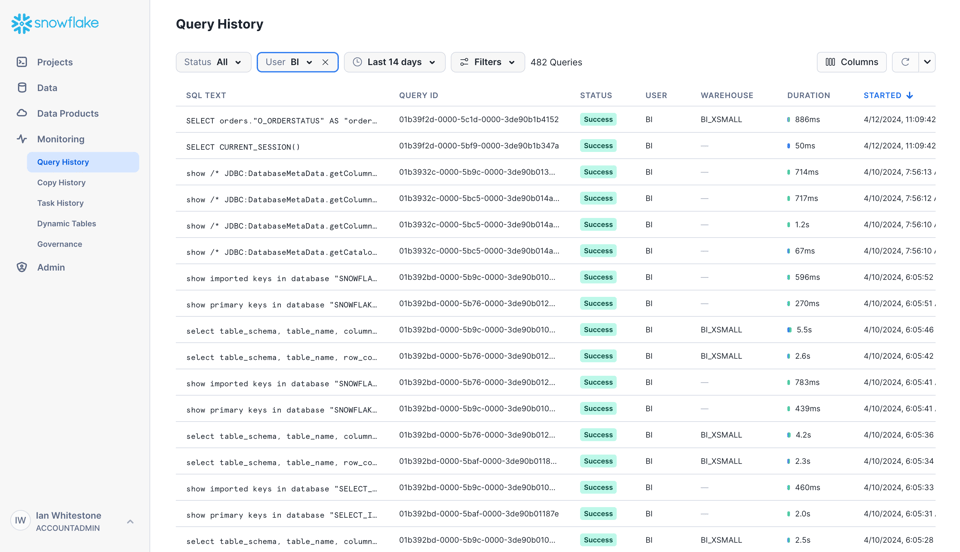
Dall'interfaccia può applicare diversi filtri e visualizzare colonne aggiuntive.
È importante ricordare che l'interfaccia mostra solo le query degli ultimi 14 giorni:
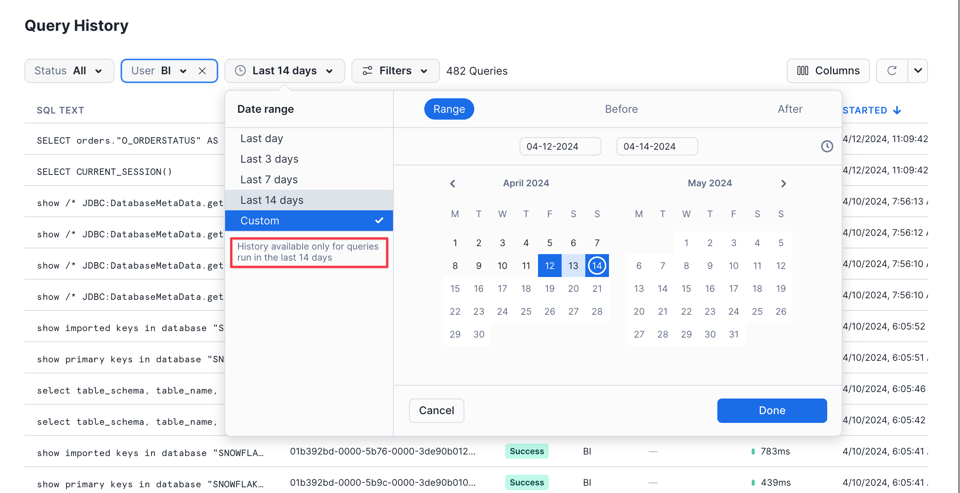
L'interfaccia è particolarmente comoda per controllare al volo le query eseguite di recente o quelle ancora in corso. Quando il caso d'uso richiede filtri più flessibili o dati aggiuntivi, di norma si passa a uno dei due metodi successivi.
Table function dell'Information Schema (information_schema.query_history)
Gli stessi dati visibili nell'interfaccia sono disponibili tramite la table function information_schema.query_history(), ma in questo caso si accede solo agli ultimi 7 giorni. In compenso, può recuperare anche i dati delle query in corso di esecuzione.
Ecco un esempio per recuperare le ultime 100 query eseguite nel suo account:
select *
from table(snowflake.information_schema.query_history())
order by start_time
;
Se vuole ottenere più risultati, può arrivare fino a 10.000 righe usando l'argomento RESULT_LIMIT (il valore predefinito è 100):
select *
from table(snowflake.information_schema.query_history(result_limit=>10000))
order by start_time
;
Può anche specificare un intervallo temporale personalizzato con i parametri end_time_range_start e end_time_range_end.
select
*
from table(snowflake.information_schema.query_history(
end_time_range_start=>dateadd('hours',-1,current_timestamp()),
end_time_range_end=>current_timestamp(),
result_limit=>10000
))
order by start_time
;
È inoltre possibile limitare le colonne restituite o aggiungere filtri. Attenzione però: i filtri vengono applicati a valle, quindi Snowflake restituisce prima 10.000 record e solo dopo li filtra.
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history(result_limit=>10000))
where
user_name='IAN'
order by start_time
Quando possibile, conviene affidarsi alle altre table function disponibili per il filtraggio:
QUERY_HISTORY_BY_SESSIONQUERY_HISTORY_BY_USERQUERY_HISTORY_BY_WAREHOUSE
L'esempio precedente potrebbe essere riscritto così:
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history_by_user(user_name=>'IAN', result_limit=>10000))
order by start_time
Latenza e retention dei dati
Il vantaggio principale della table function information_schema.query_history() è la latenza nulla. Se una query si è conclusa un secondo fa, comparirà già nell'output della funzione. Lo stesso vale per le query ancora in esecuzione.
Gli svantaggi principali di questo dataset sono:
- contiene solo le query degli ultimi 14 giorni;
- permette di analizzare al massimo 10K query;
- lavorare con le table function è meno intuitivo rispetto a interrogare una view o una tabella.
Per analizzare query meno recenti o trend su periodi più lunghi, dovrà invece affidarsi alla view account_usage, illustrata di seguito.
View Account Usage (account_usage.query_history)
La view snowflake.account_usage.query_history è il mio metodo preferito per analizzare e accedere al dataset Query History: non richiede di ricordare la sintassi delle table function e consente di interrogare con flessibilità i dati dell'ultimo anno.
Ecco una query di esempio che conta il numero di query eseguite da un utente negli ultimi 30 giorni:
select count(*)
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and user_name='IAN'
order by start_time desc
Per l'elenco completo delle colonne disponibili, consulti la documentazione Snowflake.
Latenza e retention dei dati
La view snowflake.account_usage.query_history può avere una latenza fino a 45 minuti. Detto questo, nella pratica i dati sono spesso disponibili molto prima.
Sul fronte della retention, la view conserva i dati degli ultimi 365 giorni.
Tutte le query compaiono nella Query History?
In linea generale, qualsiasi query eseguita in Snowflake compare nella Query History: vale per le query lanciate via codice, dall'interfaccia, da task, da stored procedure o dai dashboard di Streamlit. Le uniche escluse sono le query a esecuzione breve che operano esclusivamente su hybrid table. Per analizzare anche queste ultime dovrà affidarsi alla aggregate query history view.
Retention dei dati della Query History
I periodi di retention dei dati della Query History dipendono dal metodo scelto per accedere al dataset:
- Interfaccia Snowsight: 14 giorni
- Table function Query History dell'Information Schema: 14 giorni
- View Query History di Account Usage: 365 giorni
Ora che abbiamo visto le basi della Query History e come accedervi, passiamo agli esempi concreti. Tutti gli esempi che seguono si basano sulla view Account Usage descritta sopra.
1\. Individuare le query più lunghe
Per individuare le query con il tempo di esecuzione più lungo negli ultimi 30 giorni può ordinare i risultati in base alla colonna total_elapsed_time:
select
query_id,
total_elapsed_time/1000 as total_elapsed_time_s, -- convert to seconds
user_name,
query_text
from snowflake.account_usage.query_history
where
start_time > current_date - 30
order by total_elapsed_time desc
2\. Analizzare le performance delle query nel tempo
Ecco un esempio per analizzare, ora per ora, le performance medie e al 90° percentile delle query su un determinato warehouse.
select
date_trunc('hour', start_time) as start_time,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
approx_percentile(total_elapsed_time, 0.90)/1000 as p90_total_elapsed_time_s,
from snowflake.account_usage.query_history
where
warehouse_name='SELECT_BACKEND'
and start_time between '2024-03-15' and '2024-03-31'
group by 1
;
Può anche ottenere una visualizzazione efficace direttamente in Snowsight.
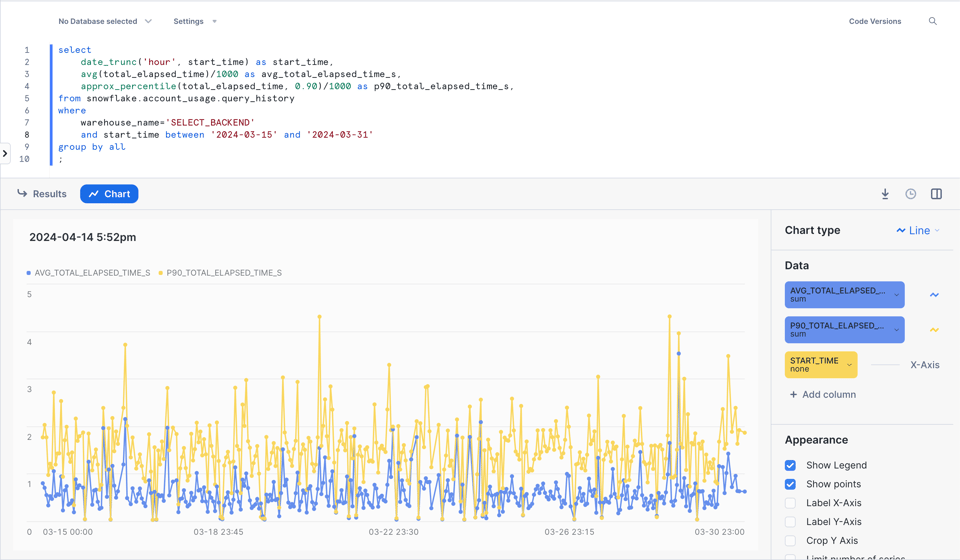
3\. Individuare pattern di query ricorrenti con query\_parameterized\_hash
Nel 2023 Snowflake ha introdotto una nuova colonna: query_parameterized_hash. Il valore si ottiene rimuovendo i letterali dalla query e calcolando l'hash del testo risultante. L'obiettivo è aiutarLa a individuare le query ricorrenti che differiscono solo lievemente per i valori dei parametri. Può approfondire query_parameterized_hash qui, dove sono spiegati anche i suoi limiti (funziona solo con determinati operatori di confronto).
Ecco un esempio per identificare i primi 100 pattern di query in base al tempo totale di esecuzione. L'esempio recupera anche l'ultimo testo della query, lo user name e il warehouse associati al query parameterized hash.
select
query_parameterized_hash,
count(*) as num_executions,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
sum(total_elapsed_time) as total_elapsed_time_s,
max_by(query_text, start_time) as latest_query_text,
max_by(user_name, start_time) as latest_user_name,
max_by(warehouse_name, start_time) as latest_warehouse_name
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by total_elapsed_time_s desc
limit 100
;
4\. Top query per tipologia
Snowflake mette a disposizione la colonna query_type per distinguere le diverse tipologie di query eseguite nel suo account. Alcuni esempi sono SELECT, CREATE_TABLE_AS_SELECT, INSERT, DELETE e [MERGE](/blog/effectively-using-the-merge-command-in-snowflake).
Ecco una query per individuare le tipologie più comuni nel suo account negli ultimi 7 giorni:
select
query_type,
count(*) as cnt
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by cnt desc
5\. Query eseguite da un utente negli ultimi 3 mesi
Per recuperare tutte le query eseguite da un utente negli ultimi 3 mesi può lanciare la seguente:
select *
from snowflake.account_usage.query_history
where
user_name='IAN'
and start_time > current_date - 90
6\. Query basate sui soli metadati
Alcune query non richiedono un virtual warehouse attivo. Possono essere servite direttamente dal livello Cloud Services usando solo i metadati. Ad esempio, una query come select count(*) from my_table può essere risolta interamente dai metadati, senza bisogno di un warehouse attivo. Allo stesso modo, una query può evitare l'esecuzione su un warehouse se è già stata eseguita nelle ultime 24 ore: in quel caso Snowflake la restituisce istantaneamente dal global result cache.
Per individuare queste query, filtri quelle senza warehouse size indicata:
select *
from snowflake.account_usage.query_history
where
warehouse_size is null
and start_time > current_date - 90
6\. Query con utilizzo elevato dei Cloud Services
Le query basate sui soli metadati appena descritte sono in genere gratuite, perché non richiedono un virtual warehouse attivo e Snowflake addebita i Cloud Services solo se superano il 10% del consumo di compute giornaliero.
Se il suo utilizzo dei Cloud Services supera il 10%, può individuare le query con utilizzo elevato dei Cloud Services con la query seguente:
select
query_text,
partitions_scanned,
partitions_total,
partitions_scanned/partitions_total as fraction_scanned,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and bytes_scanned/power(1024,3) > 1
and fraction_scanned > 0.8
limit 100
7\. Query con pruning inefficace
Se la tabella che sta interrogando non è ben clusterizzata o non applica un filtro che riduca i dati da leggere, la query finirà per scansionare un gran numero di micro-partition. Poiché la scansione dei dati è onerosa, il risultato saranno query più lente e più costose.
Ecco una query di esempio per individuare le query con pruning inefficace. In questo caso definiamo "pruning inefficace" le query che scansionano più di 1 GB di dati e oltre l'80% delle micro-partition.
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
8\. Query con spilling su disco e remote storage
Quando il virtual warehouse su cui gira la query esaurisce la memoria, la query inizia a fare spilling sul disco locale. Esaurito anche lo spazio sul disco locale, lo spilling prosegue sul remote storage. Si tratta di un processo lento e costoso. Se non è possibile riscrivere la query per eliminare lo spilling (ad esempio elaborando meno dati), in genere conviene eseguirla su un virtual warehouse più grande.
Ecco come individuare le query con spilling su disco e remote storage:
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
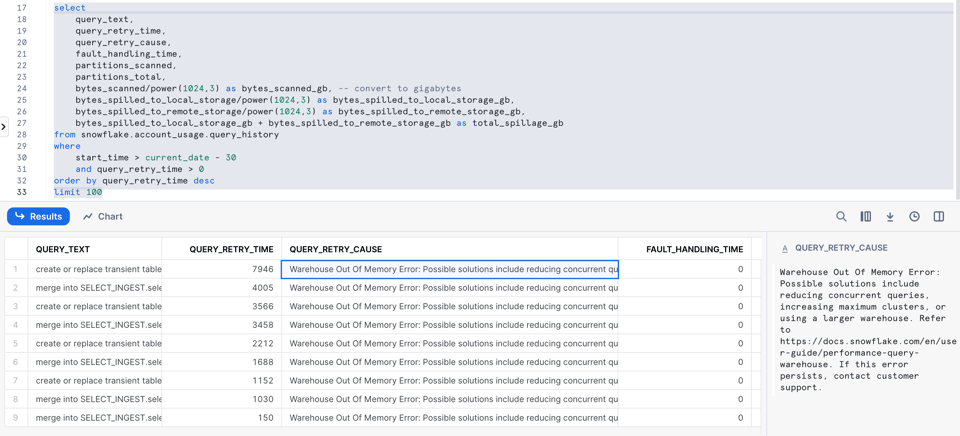
9\. Query con errori di out-of-memory e retry
Come anticipato, Snowflake cerca di gestire gli errori di out-of-memory in modo trasparente facendo fare spilling su disco alla query. A volte però le query eseguite in contemporanea sono troppe e il nodo va in crash. In questi casi Snowflake esegue automaticamente un retry della query.
Di recente Snowflake ha aggiunto alcune colonne dedicate ai retry delle query che La aiutano a capire quando questo accade.
select
query_text,
query_retry_time,
query_retry_cause,
fault_handling_time,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- convert to gigabytes
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and query_retry_time > 0
Espandi codice
La colonna query_retry_cause include persino alcuni suggerimenti su come risolvere il problema.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT ha guidato per 6 anni team full stack di data science ed engineering in Shopify e Capital One. In Shopify si è occupato in prima persona dell'ottimizzazione del data warehouse e dell'aumento dell'osservabilità dei costi.