私がSnowflakeを気に入っている点のひとつは、豊富なメタデータがすべてのユーザーに追加料金なしでプログラムから開放されていることです。Snowflakeデータベースには数百ものビューが用意されており、SQLを通じてSnowflakeの利用状況に関するほぼあらゆる疑問に答えることができます。
なかでもQuery Historyデータセットは特によく使われるビューのひとつで、アカウント内で実行されたすべてのクエリに関する有用なメタデータが詰まっています。過去のクエリ実行時間の分析、コストの高いクエリの洗い出し、失敗率の分析など、用途は多岐にわたります。
本記事では、今日からそのまま自分のアカウントで試せる実例を9つ紹介します。
Query Historyへのアクセス方法
実例に入る前に、Query Historyにアクセスする3つの方法をざっと押さえておきましょう。
Snowsight UIから
Query Historyを使い始める最も手軽な方法は、Snowsight UIのMonitoringタブからアクセスすることです。
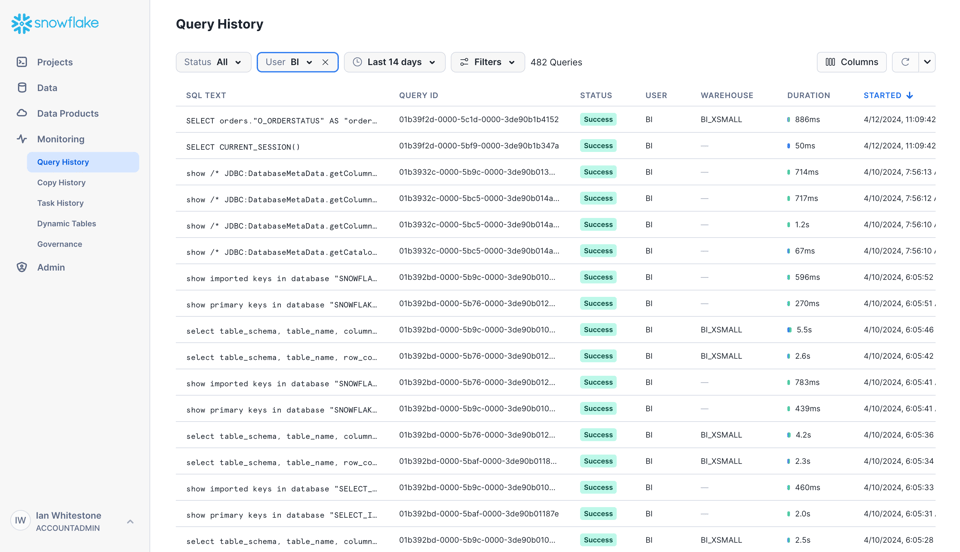
UI上では各種フィルターを適用したり、表示カラムを追加したりできます。
ただし、UIに表示されるのは過去14日間のクエリのみである点には注意が必要です。
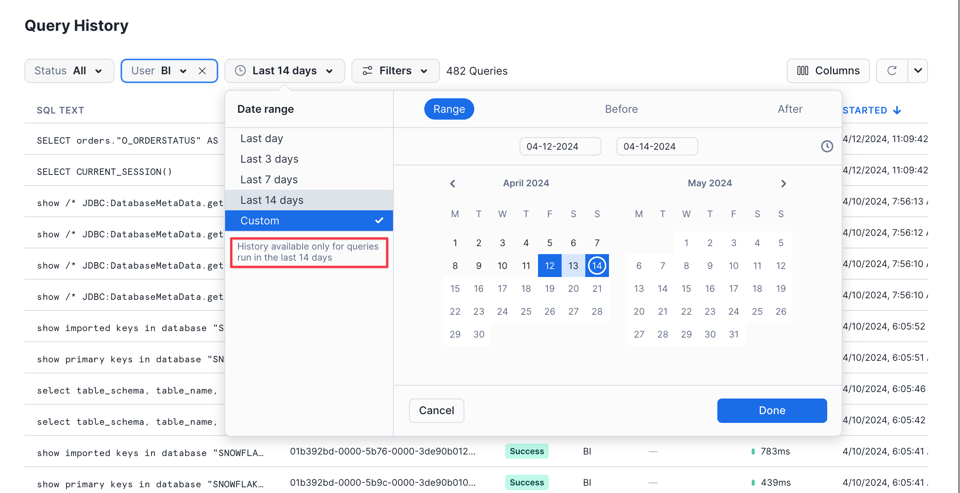
UIは、直近に実行されたクエリや実行中のクエリをサッと確認したいときに最適です。より柔軟な絞り込みや追加のデータが必要になったら、次に紹介する2つの方法に移ることになるでしょう。
Information Schemaのテーブル関数(information_schema.query_history)
UIに表示されるのと同じデータはinformation_schema.query_history()テーブル関数経由でも取得できますが、対象は過去7日間に限られます。一方で、実行中のクエリのデータも取得できるという利点があります。
アカウントで直近に実行された100件のクエリを取得する例を示します。
select *
from table(snowflake.information_schema.query_history())
order by start_time
;
さらに多くのクエリを取得したい場合は、RESULT_LIMIT引数で最大10000件まで取得できます(デフォルトは100件)。
select *
from table(snowflake.information_schema.query_history(result_limit=>10000))
order by start_time
;
end_time_range_startとend_time_range_endパラメーターで、任意の時間範囲を指定することもできます。
select
*
from table(snowflake.information_schema.query_history(
end_time_range_start=>dateadd('hours',-1,current_timestamp()),
end_time_range_end=>current_timestamp(),
result_limit=>10000
))
order by start_time
;
返却するカラムを絞ったり、フィルターを追加したりすることも可能です。ただし、追加したフィルターは取得後に適用される点に注意してください。つまりSnowflakeはまず10000件のレコードを返し、その後にフィルタリングを行います。
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history(result_limit=>10000))
where
user_name='IAN'
order by start_time
絞り込みを行うなら、できるだけ次の専用テーブル関数を使うのがおすすめです。
QUERY_HISTORY_BY_SESSIONQUERY_HISTORY_BY_USERQUERY_HISTORY_BY_WAREHOUSE
先ほどの例は次のように書き換えられます。
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history_by_user(user_name=>'IAN', result_limit=>10000))
order by start_time
レイテンシとデータ保持期間
information_schema.query_history()テーブル関数の最大の強みは、レイテンシがほぼゼロであることです。1秒前に完了したクエリも、この関数の結果にすぐ反映されます。実行中のクエリも同様です。
一方、このデータセットには次のような弱点もあります。
- 対象が過去14日間のクエリに限られる
- 分析できるのは最大1万件まで
- ビューやテーブルを参照するのに比べて、テーブル関数は扱いが直感的でない
もっと古いクエリを分析したい場合や、長期間のトレンドを追いたい場合は、後述のaccount_usageビューを使う必要があります。
Account Usageビュー(account_usage.query_history)
Query Historyの分析・参照には、私はsnowflake.account_usage.query_historyビューを最も好んで使っています。テーブル関数の書き方を覚える必要がなく、過去1年分のデータを柔軟に分析できます。
以下は、過去30日間に特定のユーザーが実行したクエリ数をカウントする例です。
select count(*)
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and user_name='IAN'
order by start_time desc
利用可能なカラムの一覧は、Snowflake公式ドキュメントを参照してください。
レイテンシとデータ保持期間
snowflake.account_usage.query_historyビューには最大45分のレイテンシがあります。とはいえ、実際にはもっと早くデータが反映されるケースがほとんどです。
データ保持期間は過去365日間です。
すべてのクエリがQuery Historyに記録されるのか?
基本的に、Snowflakeで実行したクエリはすべてQuery Historyに記録されます。プログラムから実行したクエリ、UIから実行したクエリ、タスクやストアドプロシージャから実行されたクエリ、Streamlitダッシュボードから実行されたクエリも対象です。例外は、ハイブリッドテーブルのみを対象とする短時間で完了するクエリだけです。これらを分析したい場合は、aggregate query historyビューを使う必要があります。
Query Historyのデータ保持期間
Query Historyの保持期間は、アクセス方法によって次のように異なります。
- Snowsight UI:14日
- Information Schema Query Historyテーブル関数:14日
- Account Usage Query Historyビュー:365日
基本とアクセス方法を押さえたところで、いよいよ実例を見ていきましょう。以降の例はすべて、上で紹介したaccount usageビューを使います。
1\. 実行時間が最も長いクエリを特定する
過去30日間で実行時間が最も長いクエリを特定するには、total_elapsed_timeカラムで並べ替えます。
select
query_id,
total_elapsed_time/1000 as total_elapsed_time_s, -- 秒に変換
user_name,
query_text
from snowflake.account_usage.query_history
where
start_time > current_date - 30
order by total_elapsed_time desc
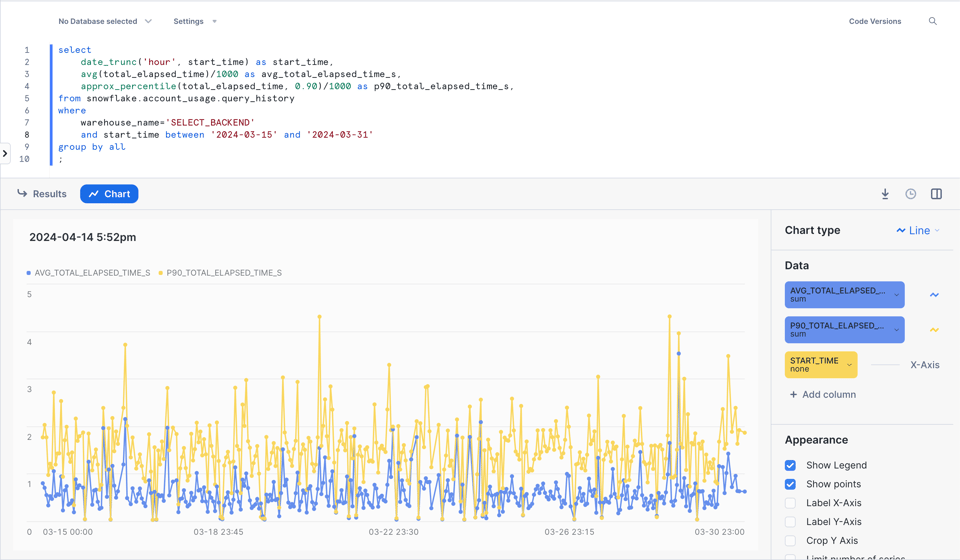
2\. クエリパフォーマンスの推移を分析する
以下は、特定のウェアハウスで1時間ごとの平均および90パーセンタイルのクエリパフォーマンスを分析する例です。
select
date_trunc('hour', start_time) as start_time,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
approx_percentile(total_elapsed_time, 0.90)/1000 as p90_total_elapsed_time_s,
from snowflake.account_usage.query_history
where
warehouse_name='SELECT_BACKEND'
and start_time between '2024-03-15' and '2024-03-31'
group by 1
;
Snowsight上で見やすいグラフをそのまま描けるのも便利です。
3\. query\_parameterized\_hashで繰り返しクエリのパターンを見つける
Snowflakeは2023年にquery_parameterized_hashという新しいカラムを追加しました。これはクエリからリテラルを除いた上でクエリテキストをハッシュ化した値で、パラメーター値だけが異なるような繰り返しクエリを見つけやすくするためのものです。query_parameterized_hashの詳細と制約(特定の比較演算でのみ機能します)はこちらを参照してください。
以下は、合計実行時間でトップ100のクエリパターンを特定する例です。あわせて、各query parameterized hashに紐づく最新のクエリテキスト、ユーザー名、ウェアハウスも取得しています。
select
query_parameterized_hash,
count(*) as num_executions,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
sum(total_elapsed_time) as total_elapsed_time_s,
max_by(query_text, start_time) as latest_query_text,
max_by(user_name, start_time) as latest_user_name,
max_by(warehouse_name, start_time) as latest_warehouse_name
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by total_elapsed_time_s desc
limit 100
;
4\. クエリタイプ別のトップクエリ
Snowflakeにはquery_typeカラムがあり、アカウントで実行されたクエリの種類を判別できます。例としてSELECT、CREATE_TABLE_AS_SELECT、INSERT、DELETE、[MERGE](/blog/effectively-using-the-merge-command-in-snowflake)などがあります。
過去7日間にアカウントで最も多く実行されたクエリタイプは、次のクエリで把握できます。
select
query_type,
count(*) as cnt
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by cnt desc
5\. 過去3か月間に特定ユーザーが実行したクエリ
過去3か月間に特定のユーザーが実行したすべてのクエリを取得するには、次のように書きます。
select *
from snowflake.account_usage.query_history
where
user_name='IAN'
and start_time > current_date - 90
6\. メタデータのみで処理されるクエリ
クエリの中には、仮想ウェアハウスを起動せずに処理できるものがあります。これらはメタデータのみを使ってCloud Servicesレイヤーで処理されます。たとえばselect count(*) from my_tableは、メタデータだけで結果を返せるため、ウェアハウスを起動する必要がありません。同様に、過去24時間以内に同じクエリが実行されていれば、ウェアハウスを使わずにグローバル結果キャッシュから瞬時に結果が返されます。
こうしたクエリを見つけるには、warehouse sizeが記録されていないクエリを絞り込みます。
select *
from snowflake.account_usage.query_history
where
warehouse_size is null
and start_time > current_date - 90
6\. Cloud Servicesの使用量が多いクエリ
前述のメタデータのみで完結するクエリは、仮想ウェアハウスを必要としないため基本的に無料です。Snowflakeは、Cloud Servicesの使用量が1日のコンピューティング使用量の10%を超えた場合にのみCloud Servicesを課金対象とします。
Cloud Servicesの使用量が10%を超えてしまった場合は、次のクエリでCloud Services使用量の多いクエリを特定できます。
select
query_text,
partitions_scanned,
partitions_total,
partitions_scanned/partitions_total as fraction_scanned,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- ギガバイトに変換
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and bytes_scanned/power(1024,3) > 1
and fraction_scanned > 0.8
limit 100
7\. プルーニングが効いていないクエリ
対象のテーブルが適切にクラスタリングされていない場合や、アクセスするデータを絞り込むフィルターが指定されていない場合、クエリは大量のマイクロパーティションをスキャンすることになります。データのスキャンにはコストがかかるため、結果として実行時間が長く割高なクエリになりがちです。
以下はプルーニングが効いていないクエリを特定する例です。ここでは「1GBを超えるデータをスキャンし、かつマイクロパーティションの80%以上をスキャンしているクエリ」をプルーニング不良と定義します。
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- ギガバイトに変換
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
8\. ディスクやリモートストレージにスピルしているクエリ
実行中の仮想ウェアハウスでメモリが不足すると、クエリはローカルディスクへのスピルを始めます。ローカルディスクも使い切ると、今度はリモートストレージへとスピルします。これは処理が遅く、コストもかさみます。処理データ量を減らすなどしてクエリを書き換えてもディスクスピルを解消できない場合は、より大きな仮想ウェアハウスで実行した方が結果的に安く済むケースが多くなります。
ディスクやリモートストレージにスピルしているクエリは、次のように特定できます。
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- ギガバイトに変換
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
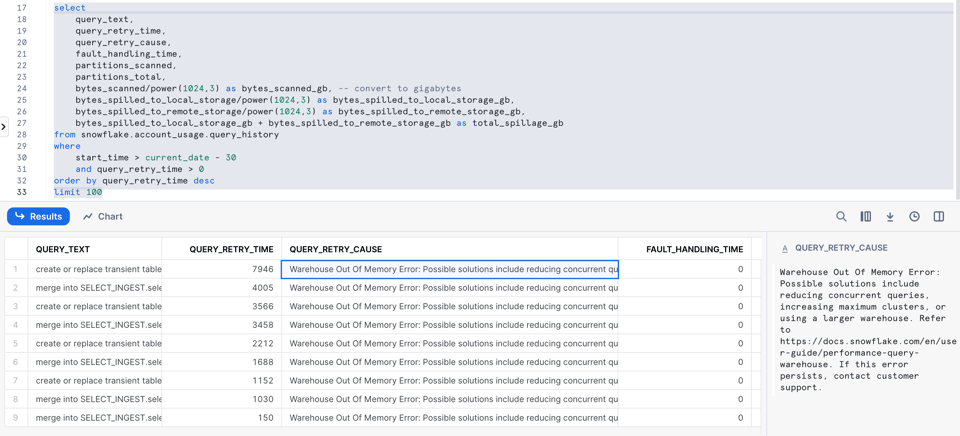
9\. メモリ不足エラーやリトライが発生したクエリ
前述のとおり、Snowflakeはメモリ不足が起きてもクエリをディスクへスピルさせることで、可能な限り処理を継続しようとします。それでも、同時実行クエリが多すぎてノードがクラッシュすることがあります。その場合、Snowflakeは自動でクエリをリトライします。
Snowflakeは最近、こうした状況を把握しやすくするための新しいクエリリトライ用カラムを追加しました。
select
query_text,
query_retry_time,
query_retry_cause,
fault_handling_time,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- ギガバイトに変換
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and query_retry_time > 0
コードを展開
query_retry_causeには、解消のヒントまで含まれているのが嬉しいポイントです。
Ian Whitestone・Co-founder & CEO of SELECT
Ianは、Snowflakeのコスト管理・最適化SaaSであるSELECTの共同創業者兼CEOです。SELECT立ち上げ前は、ShopifyとCapital Oneでフルスタックのデータサイエンス・エンジニアリングチームを6年間にわたって率いてきました。Shopifyでは、データウェアハウスの最適化とコストの可視化向上を牽引しました。