L'un des aspects que je préfère chez Snowflake, ce sont toutes ces métadonnées rendues accessibles par programmation à l'ensemble des utilisateurs, sans surcoût ! La base de données Snowflake regorge de centaines de vues que les utilisateurs peuvent interroger en SQL pour répondre à pratiquement n'importe quelle question sur leur usage de Snowflake.
Le jeu de données Query History fait partie des plus utilisés de la base Snowflake, car il contient une multitude de métadonnées utiles sur chaque requête exécutée dans votre compte. Le Query History couvre de nombreux cas d'usage : analyse historique des temps d'exécution, identification des requêtes coûteuses ou encore analyse des taux d'échec.
Dans cet article, je partage 9 exemples concrets que vous pouvez exécuter dans votre compte dès aujourd'hui.
Accéder au Query History
Avant d'aborder les exemples d'utilisation du Query History, passons rapidement en revue les 3 façons d'y accéder.
Via l'interface Snowsight
Le moyen le plus simple de prendre en main le jeu de données Query History est de passer par l'interface Snowsight, dans l'onglet Monitoring.
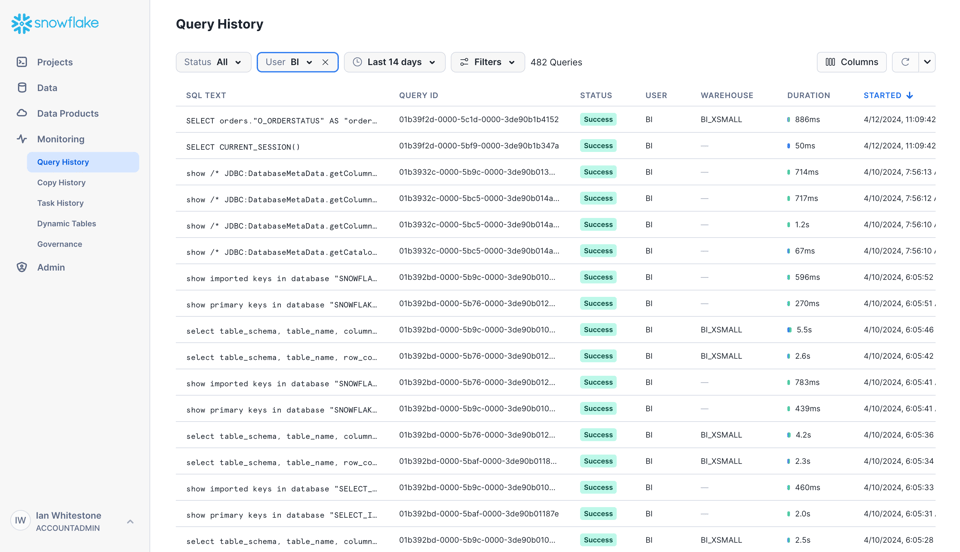
Depuis l'interface, vous pouvez appliquer plusieurs filtres et afficher des colonnes supplémentaires.
À noter : l'interface ne couvre que les requêtes des 14 derniers jours :
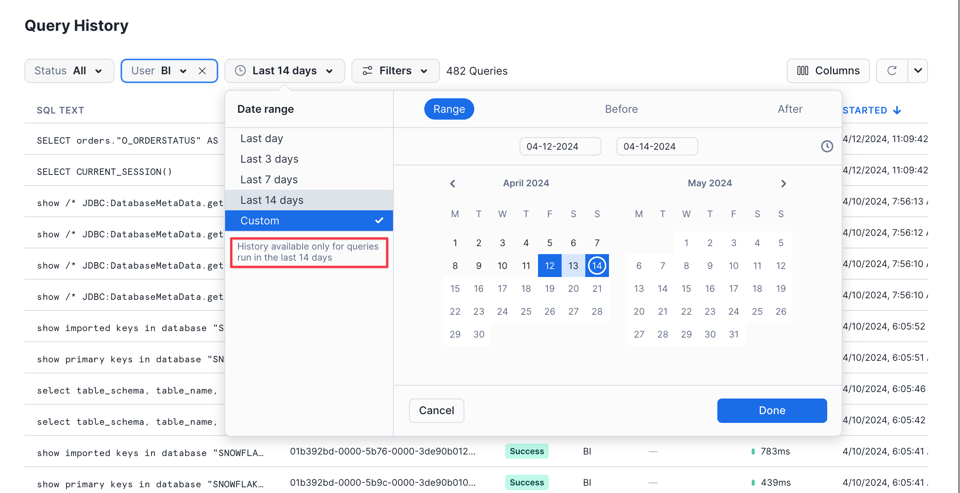
L'interface est surtout pratique pour vérifier rapidement les requêtes récemment exécutées ou en cours d'exécution. Dès que le cas d'usage exige un filtrage plus souple ou davantage de données, on bascule généralement vers l'une des deux méthodes suivantes.
Fonctions de table de l'Information Schema (information_schema.query_history)
Les données affichées dans l'interface sont également disponibles via la fonction de table information_schema.query_history(), mais l'accès est limité aux 7 derniers jours. Bon point : vous pouvez récupérer les informations des requêtes en cours d'exécution !
Voici un exemple pour récupérer les 100 dernières requêtes exécutées sur votre compte :
select *
from table(snowflake.information_schema.query_history())
order by start_time
;
Pour en récupérer davantage, vous pouvez aller jusqu'à 10 000 grâce à l'argument RESULT_LIMIT (la valeur par défaut est 100) :
select *
from table(snowflake.information_schema.query_history(result_limit=>10000))
order by start_time
;
Vous pouvez préciser une plage temporelle personnalisée via les paramètres end_time_range_start et end_time_range_end.
select
*
from table(snowflake.information_schema.query_history(
end_time_range_start=>dateadd('hours',-1,current_timestamp()),
end_time_range_end=>current_timestamp(),
result_limit=>10000
))
order by start_time
;
Vous pouvez aussi restreindre les colonnes retournées ou ajouter des filtres. Attention : les filtres ajoutés s'appliquent a posteriori, autrement dit Snowflake retourne d'abord 10 000 enregistrements, puis les filtre.
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history(result_limit=>10000))
where
user_name='IAN'
order by start_time
Dans la mesure du possible, privilégiez les autres fonctions de table disponibles pour effectuer le filtrage :
QUERY_HISTORY_BY_SESSIONQUERY_HISTORY_BY_USERQUERY_HISTORY_BY_WAREHOUSE
L'exemple ci-dessus peut être réécrit ainsi :
select
query_id,
query_text,
user_name,
execution_status,
start_time,
end_time
from table(snowflake.information_schema.query_history_by_user(user_name=>'IAN', result_limit=>10000))
order by start_time
Latence et rétention des données
Le principal atout de la fonction de table information_schema.query_history() est son absence totale de latence. Une requête terminée il y a une seconde apparaîtra immédiatement dans sa sortie. Idem pour une requête encore en cours.
Les principaux inconvénients de ce jeu de données :
- il ne couvre que les requêtes des 14 derniers jours ;
- vous ne pouvez analyser que les résultats de 10 000 requêtes ;
- les fonctions de table sont moins intuitives à manipuler qu'une vue ou une table classique.
Pour analyser des requêtes plus anciennes ou étudier des tendances sur une plus longue période, il faudra s'appuyer sur la vue account_usage décrite ci-dessous.
La vue Account Usage (account_usage.query_history)
La vue snowflake.account_usage.query_history est ma méthode préférée pour analyser et accéder au jeu de données Query History. Pas besoin de mémoriser le fonctionnement des fonctions de table, et vous pouvez analyser librement les données de l'année écoulée.
Voici un exemple où je compte le nombre de requêtes exécutées par un utilisateur sur les 30 derniers jours :
select count(*)
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and user_name='IAN'
order by start_time desc
Pour la liste complète des colonnes disponibles, consultez la documentation Snowflake.
Latence et rétention des données
La vue snowflake.account_usage.query_history peut présenter une latence allant jusqu'à 45 minutes. Cela dit, en pratique, les données apparaissent souvent bien plus tôt.
Côté rétention, cette vue conserve les données des 365 derniers jours.
Toutes les requêtes figurent-elles dans le Query History ?
De manière générale, toutes les requêtes que vous exécutez dans Snowflake apparaissent dans le Query History. Cela inclut les requêtes lancées par programmation, celles exécutées via l'interface, celles déclenchées par des tasks ou des procédures stockées, ou encore celles exécutées par des dashboards Streamlit. Les seules exclusions concernent les requêtes courtes opérant exclusivement sur des hybrid tables. Pour analyser ce type de requêtes, il faudra se tourner vers la vue aggregate query history.
Rétention des données du Query History
Les durées de rétention des données du Query History dépendent de la méthode d'accès :
- Interface Snowsight : 14 jours
- Fonction de table Query History de l'Information Schema : 14 jours
- Vue Query History de l'Account Usage : 365 jours
Maintenant que les bases sont posées, passons aux exemples concrets ! Tout ce qui suit s'appuiera sur la vue account usage décrite plus haut.
1\. Identifier les requêtes les plus longues
Pour identifier les requêtes les plus longues sur les 30 derniers jours, triez sur la colonne total_elapsed_time :
select
query_id,
total_elapsed_time/1000 as total_elapsed_time_s, -- conversion en secondes
user_name,
query_text
from snowflake.account_usage.query_history
where
start_time > current_date - 30
order by total_elapsed_time desc
2\. Analyser la performance des requêtes dans le temps
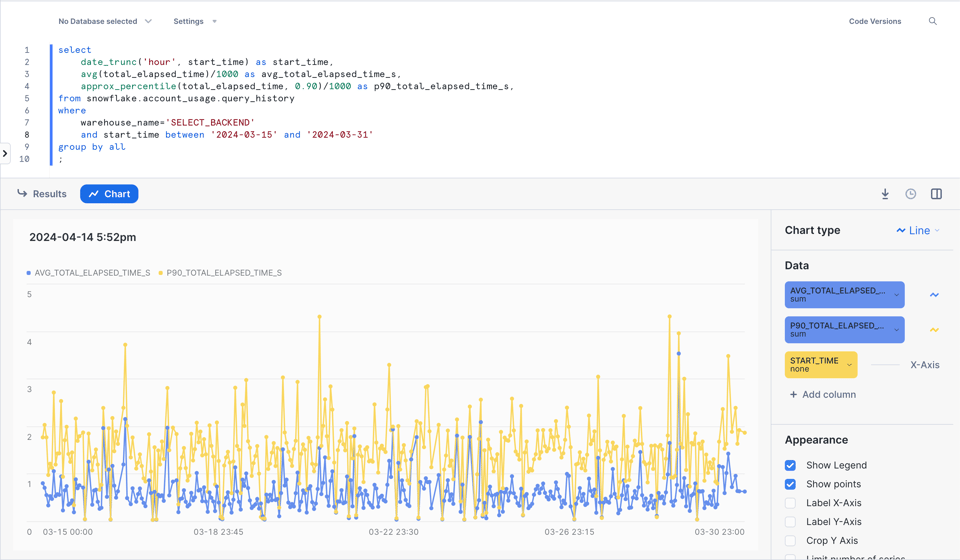
Voici un exemple pour analyser la performance moyenne et au 90e centile des requêtes, heure par heure, sur un warehouse donné.
select
date_trunc('hour', start_time) as start_time,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
approx_percentile(total_elapsed_time, 0.90)/1000 as p90_total_elapsed_time_s,
from snowflake.account_usage.query_history
where
warehouse_name='SELECT_BACKEND'
and start_time between '2024-03-15' and '2024-03-31'
group by 1
;
Vous obtenez même une visualisation soignée directement dans Snowsight !
3\. Repérer les patterns de requêtes récurrents avec query\_parameterized\_hash
Snowflake a introduit récemment (en 2023) une nouvelle colonne, query_parameterized_hash. Cette valeur est obtenue en supprimant les littéraux de la requête puis en hashant le texte résultant. L'objectif : repérer les requêtes récurrentes qui ne diffèrent que par leurs valeurs de paramètres. Vous trouverez plus de détails sur query_parameterized_hash ici, ainsi que sur ses limites (il ne fonctionne qu'avec certaines opérations de comparaison).
Voici un exemple pour identifier les 100 principaux patterns de requêtes en fonction du temps d'exécution total. L'exemple récupère également le dernier texte de requête, le nom d'utilisateur et le warehouse associés au hash paramétré.
select
query_parameterized_hash,
count(*) as num_executions,
avg(total_elapsed_time)/1000 as avg_total_elapsed_time_s,
sum(total_elapsed_time) as total_elapsed_time_s,
max_by(query_text, start_time) as latest_query_text,
max_by(user_name, start_time) as latest_user_name,
max_by(warehouse_name, start_time) as latest_warehouse_name
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by total_elapsed_time_s desc
limit 100
;
4\. Top des requêtes par type
Snowflake inclut une colonne query_type pour distinguer les différents types de requêtes exécutées sur votre compte. Quelques exemples : SELECT, CREATE_TABLE_AS_SELECT, INSERT, DELETE et [MERGE](/blog/effectively-using-the-merge-command-in-snowflake).
Voici une requête pour identifier les types de requêtes les plus fréquents sur votre compte ces 7 derniers jours :
select
query_type,
count(*) as cnt
from snowflake.account_usage.query_history
where
start_time > current_date - 7
group by 1
order by cnt desc
5\. Requêtes exécutées par un utilisateur sur les 3 derniers mois
Pour récupérer toutes les requêtes exécutées par un utilisateur sur les 3 derniers mois :
select *
from snowflake.account_usage.query_history
where
user_name='IAN'
and start_time > current_date - 90
6\. Requêtes traitées uniquement via les métadonnées
Certaines requêtes ne nécessitent pas de virtual warehouse en exécution. Elles peuvent être servies directement depuis la couche Cloud Services à partir des métadonnées. Par exemple, select count(*) from my_table peut être traitée entièrement à partir des métadonnées, sans recourir à un warehouse. De même, une requête peut éviter de tourner sur un warehouse si elle a déjà été exécutée dans les 24 dernières heures : Snowflake renvoie alors instantanément le résultat depuis le cache global.
Pour identifier ces requêtes, filtrez sur celles dont la taille de warehouse n'est pas renseignée :
select *
from snowflake.account_usage.query_history
where
warehouse_size is null
and start_time > current_date - 90
6\. Requêtes à forte consommation Cloud Services
Les requêtes traitées uniquement via les métadonnées évoquées ci-dessus sont généralement gratuites, car elles n'exigent pas de virtual warehouse en exécution. Snowflake ne facture les Cloud Services que lorsqu'ils dépassent 10 % de votre consommation compute quotidienne.
Si votre usage des Cloud Services franchit ce seuil de 10 %, vous pouvez identifier les requêtes les plus gourmandes avec la requête suivante :
select
query_text,
partitions_scanned,
partitions_total,
partitions_scanned/partitions_total as fraction_scanned,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- conversion en gigaoctets
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and bytes_scanned/power(1024,3) > 1
and fraction_scanned > 0.8
limit 100
7\. Requêtes au pruning inefficace
Si la table interrogée n'est pas bien clusterisée ou si aucun filtre ne vient restreindre les données accédées, votre requête finira par scanner un grand nombre de micro-partitions. Or, scanner des données coûte cher : cela se traduit par des requêtes plus longues et plus onéreuses.
Voici un exemple pour identifier les requêtes au pruning inefficace. Ici, on définit un pruning inefficace comme les requêtes scannant plus de 1 Go de données et plus de 80 % des micro-partitions.
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- conversion en gigaoctets
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
8\. Requêtes qui débordent sur le disque et le stockage distant
Lorsque le virtual warehouse sur lequel s'exécute votre requête manque de mémoire, celle-ci commence à déborder sur le disque local. Une fois le disque local saturé, le débordement se poursuit sur le stockage distant. C'est à la fois lent et coûteux. S'il est impossible de réécrire la requête pour éliminer ce débordement (par exemple en traitant moins de données), il sera probablement plus économique de l'exécuter sur un virtual warehouse plus puissant.
Voici comment identifier les requêtes qui débordent sur le disque et le stockage distant :
select
query_text,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- conversion en gigaoctets
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 7
and total_spillage_gb > 0
order by total_spillage_gb desc
limit 100
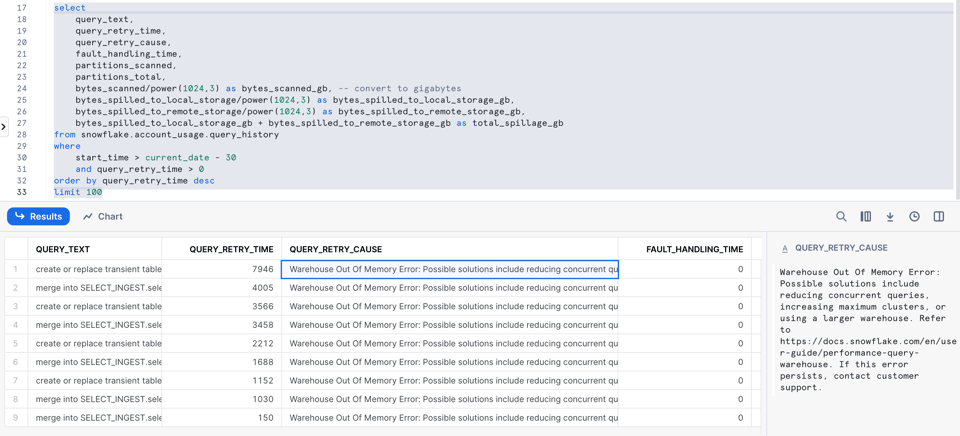
9\. Requêtes avec erreurs de mémoire insuffisante et reprises
Comme évoqué plus haut, Snowflake tente de gérer en douceur les erreurs de mémoire insuffisante en faisant déborder la requête sur le disque. Mais il arrive qu'un trop grand nombre de requêtes tournent en parallèle, ce qui provoque un crash du nœud. Dans ce cas, Snowflake relance automatiquement la requête.
Snowflake a récemment ajouté de nouvelles colonnes de reprise de requête pour vous aider à repérer ces situations.
select
query_text,
query_retry_time,
query_retry_cause,
fault_handling_time,
partitions_scanned,
partitions_total,
bytes_scanned/power(1024,3) as bytes_scanned_gb, -- conversion en gigaoctets
bytes_spilled_to_local_storage/power(1024,3) as bytes_spilled_to_local_storage_gb,
bytes_spilled_to_remote_storage/power(1024,3) as bytes_spilled_to_remote_storage_gb,
bytes_spilled_to_local_storage_gb + bytes_spilled_to_remote_storage_gb as total_spillage_gb
from snowflake.account_usage.query_history
where
start_time > current_date - 30
and query_retry_time > 0
Déplier le code
La colonne query_retry_cause propose même quelques pistes pour résoudre le problème !
Ian Whitestone·Co-founder & CEO of SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à la tête d'équipes data science et engineering full stack chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation du data warehouse et le renforcement de l'observabilité des coûts.