Warum ungenutzte dbt-Modelle ein Thema sind
Eine der einfachsten Methoden, unnötige Snowflake-Kosten zu senken, ist es, alles loszuwerden, was niemand mehr nutzt. In einem früheren Beitrag zum Thema ungenutzte Tabellen in Snowflake identifizieren hat Ian erklärt, wie sich mit den Account Usage Views von Snowflake die Objektnutzung nachvollziehen lässt, um Tabellen aufzuspüren und zu entfernen, die nicht aktiv abgefragt werden – und so Speicherkosten zu sparen. Bei Tabellen, die von ELT-Tools wie dbt erstellt und laufend aktualisiert werden, ist das Einsparpotenzial sogar deutlich höher: Hier sparen Sie zusätzlich zu den Speicherkosten auch die Compute-Kosten, die beim Erstellen und Aktualisieren der Tabelle anfallen.
Wenn Ihr dbt-Projekt schon länger als ein Jahr läuft, stehen die Chancen gut, dass eine ganze Reihe Ihrer dbt-Modelle gar nicht mehr verwendet wird – aber trotzdem täglich läuft und Compute-Kosten verursacht. Wer einen schnellen Hebel sucht, um Kosten zu senken und gleichzeitig sein Data Warehouse aufzuräumen, ist hier richtig!
dbt-Modellnutzung verstehen
In diesem Artikel baue ich auf der Grundidee auf, die Nutzung von Snowflake-Objekten nachzuvollziehen – konkret, um die Nutzung von dbt-Modellen zu erfassen. Dafür brauchen wir ein zusätzliches Modell, das die Beziehungen zwischen dbt-Modellen abbildet (den DAG als Tabelle), damit Zwischenmodelle ohne direkte Nutzung nicht fälschlich als ungenutzt markiert werden, solange ihre Downstream-Modelle noch Query-Aktivität aufweisen. Ich empfehle, mit dem ursprünglichen Beitrag zu starten, um sich zumindest mit dem account_usage-Schema vertraut zu machen.
Warum der Ansatz aus jenem Beitrag nicht ausreicht, um ungenutzte dbt-Modelle zu finden, zeigt der folgende DAG:
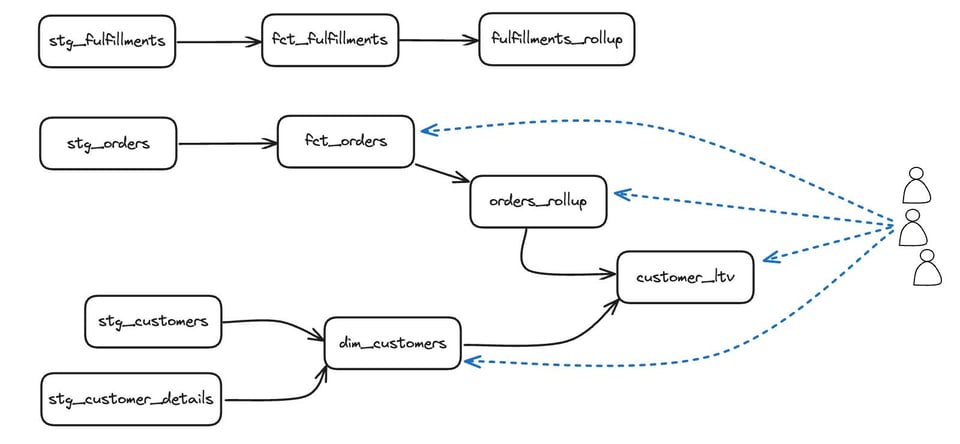
Würden wir nach ungenutzten Tabellen suchen, erschienen zunächst alle Tabellen als genutzt – diese Nutzung käme aber von dbt selbst, das Tests ausführt oder Downstream-Modelle baut. Schließen wir die Queries von dbt aus, würden wir die obere Reihe – stg_fulfillments, fct_fulfillments und fulfillments_rollup – korrekt als ungenutzte Modelle erkennen. Unser Ergebnis würde aber auch die gesamte stg_-Schicht als ungenutzt einstufen. Bei dbt zählt eben nicht nur die direkte Nutzung – wir müssen auch die Nutzung der Downstream-Abhängigkeiten berücksichtigen.
Dafür bauen wir ein Modell, das die Nachfahren eines dbt-Modells erfasst, und aggregieren Queries dann entlang dieser DAG-Abhängigkeiten geschickt "nach oben".
Der Ansatz im Überblick
Schauen wir uns einen noch einfacheren DAG mit nur 4 Modellen an. Um ungenutzte dbt-Modelle zuverlässig zu identifizieren, müssen wir zunächst verstehen, welche Modelle voneinander abhängen.
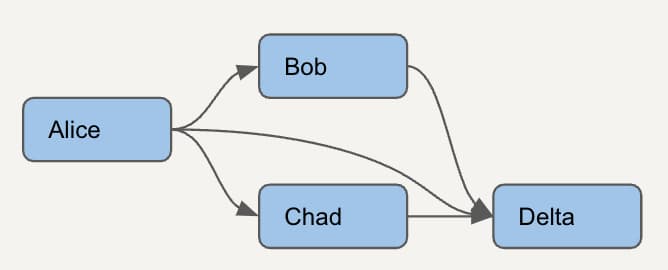
Für jedes Modell müssen wir alle Downstream-Modelle auflisten. So sieht dieser einfache DAG in dem neuen Abhängigkeitsmodell aus, das wir gleich erstellen. Die grünen Zeilen zeigen einen Knoten und sich selbst, die orangefarbenen die direkten Eltern, und die lila Zeile macht deutlich, dass ein direkter Elternknoten zugleich ein indirekter Elternknoten sein kann.
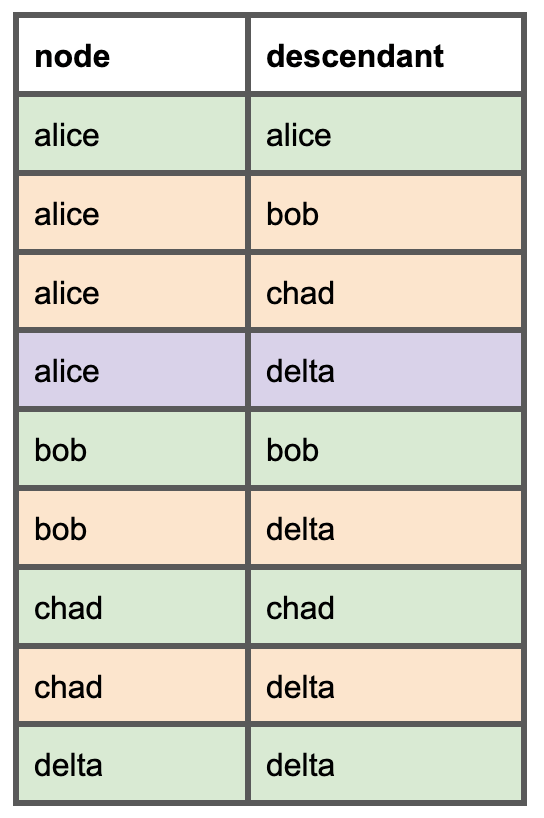
Mit diesem Modell können wir dann etwa prüfen, ob sich das Modell Alice gefahrlos entfernen lässt – indem wir die Nutzung seiner Downstream-Abhängigkeiten Bob, Chad und Delta betrachten.
Voraussetzungen
Um zu ermitteln, welche Tabellen genutzt werden, greifen wir auf die Modelle aus dem vorherigen Artikel zurück. Beide sind im Paket dbt-snowflake-monitoring enthalten, das von SELECT entwickelt und gepflegt wird.
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
Für unser Modell der dbt-Abhängigkeiten bauen wir etwas Neues: dbt_model_descendants. Dieses lässt sich aus dbt-snowflake-monitoring ableiten – oder noch präziser aus dbt_artifacts, sofern Sie dieses Paket eingerichtet haben. Ich stelle SQL für beide Quellen bereit:
- Variante 1:
dbt_snowflake_monitoring/dbt_queries.sql - Variante 2:
dbt_artifacts/dim_dbt__current_models.sql
So modellieren Sie Abhängigkeiten in Ihrem dbt-DAG
Schritt 1: Eltern jedes Modells ermitteln
Im ersten Schritt leiten wir eine Tabelle ab, die pro dbt-Modell eine Zeile enthält und in einer Array-Spalte die direkten Eltern des Modells erfasst.
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | ["customers", "events"] |
| events | prod.analytics.events | ["stg_events"] |
| ... | ... | ... |
Für den Aufbau dieses Datasets gibt es zwei Wege.
Variante mit dbt_snowflake_monitoring
Die erste Möglichkeit ist dbt_snowflake_monitoring/dbt_queries.sql, das Sie für die anderen benötigten Modelle (query_base_object_access, query_history_enriched) ohnehin bereits installiert haben sollten. Die beiden größten Nachteile: Gelöschte Modelle bleiben noch ein paar Tage in den Daten enthalten, nachdem sie aus dem Projekt entfernt wurden, und Sources tauchen nie auf, weil sie keine "refs" sind.
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
-- and dbt_target_name = <my target>
-- and dbt_target_database = <my prod db>
-- and dbt_target_schema in <my prod schemas>
Code einblenden
Variante mit dbt_artifacts
Die zweite Möglichkeit ist dbt_artifacts/dim_dbt__current_models. Das ist die robustere Option, setzt aber das Paket dbt_artifacts voraus, dessen Einrichtung etwas aufwendiger ist.
select
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array,
from dim_dbt__current_models
where
-- [optional] filter to specific databases
-- database in (<your databases>)
Schritt 2: Kindknoten ableiten
Da wir nun eine Liste der Knoten haben, erstellen wir ein neues CTE namens node_children, indem wir das CTE nodes entpacken. Damit bilden wir die direkten Eltern ab.
Variante mit dbt_snowflake_monitoring
with
nodes as (
select
dbt_node_name as node,
dbt_node_refs as parent_array,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
query_id
from dbt_queries_select
where true
and start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
qualify row_number() over (partition by dbt_node_name order by end_time desc) = 1
Code einblenden
Variante mit dbt_artifacts
with
nodes as (
select
-- assume packaged model names do not collide
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array
from dim_dbt__current_models
),
-- Unpack the parents (refs) array and swap the relationship into node -> descendent terms.
node_children as (
Code einblenden
Schritt 3: Rekursiv alle Modell-Nachfahren finden
Der Rest der Query ist identisch – ob Sie nun dbt-snowflake-monitoring oder dbt-artifacts verwenden. Sie führt folgende Schritte aus:
- Ableitung von
node_descendants_recursive(alle Ebenen) durch rekursives Joinen vonnode_children(siehe oben) mit sich selbst - Granularität an dieser Stelle: alle Pfade
- Per Union eine zusätzliche Zeile für "ein Knoten und sich selbst" hinzufügen
- Aggregation von
node_descendantszu eindeutigen Knoten-Nachfahren-Paaren
So sieht die Query aus, wenn Sie dbt-snowflake-monitoring nutzen:
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
Code einblenden
Im Anhang finden Sie eine Variante dieser Query, die Sie direkt in Ihrem dbt-Projekt einsetzen können.
So fragen Sie ungenutzte dbt-Modelle ab
Mit unserem neuen Modell dbt_model_descendants, das Modell-Abhängigkeiten (oder sollte man sagen: Nachfahrschaften?) abbildet, lässt sich die direkte Tabellennutzung aggregieren und über den DAG nach oben verteilen. Das läuft auf einen Join der Query-Zahlen auf der Nachfahrenseite hinaus, der bedingt um den Elternknoten aggregiert wird. Die Selbstkante (jeder Knoten als sein eigener Nachfahre) spielt hier eine zentrale Rolle, denn die bedingte Aggregation kann zwischen direkter und indirekter Nutzung unterscheiden, indem sie prüft, ob der Nachfahre tatsächlich der Knoten selbst ist.
with
table_queries as (
select
lower(query_base_object_access.object_name) as table_sk,
count(*) as count_queries
from query_history_enriched_select
inner join query_base_object_access
on query_history_enriched_select.query_id = query_base_object_access.query_id
and query_history_enriched_select.start_time = query_base_object_access.query_start_time
where
query_history_enriched_select.start_time > current_date - 180
and query_history_enriched_select.query_type = 'SELECT'
and query_history_enriched_select.execution_status = 'SUCCESS'
-- exclude dbt queries
and dbt_metadata is null
Code einblenden
Diese Query zeigt uns, wie viele Nutzungs-Queries direkt auf jedes dbt-Modell zugreifen und wie viele sich über die Downstream-Nachfahren des Modells verteilen. Steht bei einem Modell total_queries = 0, bedient es weder eine direkte Nutzung noch stützt es eine indirekte Downstream-Nutzung. Beachten Sie: downstream_queries und total_queries liegen über Ihrer tatsächlichen Gesamtzahl an Snowflake-Queries, weil eine einzelne Query mehreren Modellen zugerechnet werden kann.
Was tun mit ungenutzten Modellen?
Als Analytics Engineer kenne ich mich besser damit aus, neue Tabellen zu bauen, als alte zu löschen.
Die meisten dbt-Modelle sind feste Transformationen von Rohdaten und lassen sich ein- und ausschalten, ohne dass etwas "verloren" geht. Klar, das Produktionsmodell veraltet, bis es wieder eingeschaltet wird – aber es entsteht kein unwiederbringlicher Informationsverlust. In solchen Fällen ist es eine gute Idee, das Modell entweder schlicht zu deaktivieren oder es zu löschen und in der Git-Historie weiterleben zu lassen. Ich empfehle, an dieser Stelle auch die Tabelle zu droppen, damit niemand mehr auf veraltete Daten zugreift.
Modelle wie dbt-Snapshots oder andere ausgefeilte inkrementelle Verfahren passen nicht unbedingt in dieses Schema. Etwas aus dieser Kategorie zu deprecaten, verlangt eine sorgfältigere Einzelfallbetrachtung – aber wer schon einmal in dieser Lage steckte, weiß: Mit hoher Wahrscheinlichkeit weiß ohnehin niemand mehr, wofür das Modell überhaupt da ist oder was es eigentlich tun soll.
So entfernen Sie ein dbt-Modell aus Ihrem Projekt
Schritte, um ein Modell zu löschen:
- Löschen Sie die
.sql-Modelldatei.
- Suchen Sie mit
Strg+Umschalt+Fim gesamten Projekt nach dem Modellnamen, um Folgendes zu finden:refs()auf das Modell- Schema- oder Config-Referenzen in
.yml-Dateien.
- Droppen Sie die zugehörige Snowflake-Tabelle (oder -View).
Bei diesem Vorgehen müssen Sie wahrscheinlich keinen ref() anpassen, denn jedes Modell, das auf ein ungenutztes Modell verweist, muss selbst ungenutzt sein – sonst hätte der Elternknoten ja eine Downstream-Nutzung. Bei einer Kette ungenutzter Modelle empfehle ich, am Ende anzufangen und sich rückwärts vorzuarbeiten: Bei A -> B -> C löschen Sie zuerst C!
Ein Modell zu deaktivieren ist ein schneller Weg, es abzuschalten, ohne Code zu löschen. Deaktivierte Modelle verhalten sich, als existierten sie nicht – ihr Code bleibt aber im Projekt erhalten. Es reicht eine einzige Config-Zeile:
-- my_unused_model.sql
{{ config(enabled = false) }}
select ...
Das ist vielleicht der schnellste und am leichtesten umkehrbare Weg, ein Modell abzuschalten – aber wenn Sie ohnehin git verwenden, geht Ihnen auch beim Löschen kein Code verloren. Und wer einem Wildwuchs an Modellen vorbeugen will, fährt besser damit, ungenutzte Modelle direkt zu entsorgen, statt eine eigene "Müllecke" einzurichten.
Vergessen Sie zum Schluss nicht, Ihren Modellen für ihre harte Arbeit zu danken. Wie die große Data Engineer Marie Kondo zu sagen pflegt:
Schätze die [Analyse-Modelle], die dir Freude bereiten – und lass den Rest mit Dankbarkeit los.
Anhang – Dateien für Ihr dbt-Projekt
{{ config(materialized='table') }}
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from {{ ref('dbt_queries') }}
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
Code einblenden
version: 2
models:
- name: dbt_model_descendants
description: >-
A table mapping each DAG model node to all of its descendant model nodes. The
mapping includes the model's self as a descendant with depth = 0. Sources are not included.
columns:
- name: node_descendant_sk
description: Unique identifier of a node-descendant pairing
tests:
- unique
- not_null
- name: node
description: The name of a node in the DAG
- name: descendant
Code einblenden
Jay Sobel · Analytics Engineer bei Ramp
Jay ist Senior Analytics Engineer bei Ramp, einem der am schnellsten wachsenden Startups in den USA. Er bringt fast ein Jahrzehnt Erfahrung in Data Analysis und Engineering mit – gesammelt bei zahlreichen schnell wachsenden Technologieunternehmen wie Gopuff, Drizly, Wanderu und LevelUp. Jay ist begeistertes Mitglied der dbt- und Snowflake-Community und beteiligt sich regelmäßig an Diskussionen rund um Optimierung und Best Practices.