¿Por qué importan los modelos dbt sin uso?
Una de las formas más fáciles de reducir el gasto innecesario en Snowflake es deshacerte de lo que ya nadie usa. En un post anterior sobre cómo identificar tablas sin uso en Snowflake, Ian explicó cómo las vistas Account Usage de Snowflake permiten inspeccionar el uso de objetos para, en última instancia, detectar y eliminar tablas que ya no se consultan activamente, lo que se traduce en ahorro en costos de almacenamiento. Cuando se trata de tablas que se crean y actualizan continuamente con herramientas ELT como dbt, el ahorro potencial al eliminarlas es mucho mayor, porque además del costo de almacenamiento te ahorras el costo de cómputo asociado a crearlas y mantenerlas actualizadas.
Si tu proyecto de dbt ya tiene más de un año, lo más probable es que tengas varios modelos que ya nadie usa, pero que siguen corriendo todos los días y generando costos de cómputo. Si buscas una victoria rápida para bajar costos y, de paso, ordenar tu data warehouse, ¡este post es para ti!
Entender el uso de los modelos dbt
En este artículo voy a ampliar la idea de analizar el uso de objetos de Snowflake para enfocarme específicamente en el uso de modelos dbt. Esto requiere un modelo adicional que represente la relación entre modelos dbt (el DAG, en forma de tabla), de modo que los modelos intermedios con 0 uso directo no se marquen como sin uso siempre que sus descendientes sí tengan actividad de consulta. Te recomiendo empezar por el post original, aunque sea para familiarizarte con el esquema account_usage.
Para entender por qué no podemos aplicar el enfoque de ese post para identificar modelos dbt sin uso, considera el siguiente DAG:
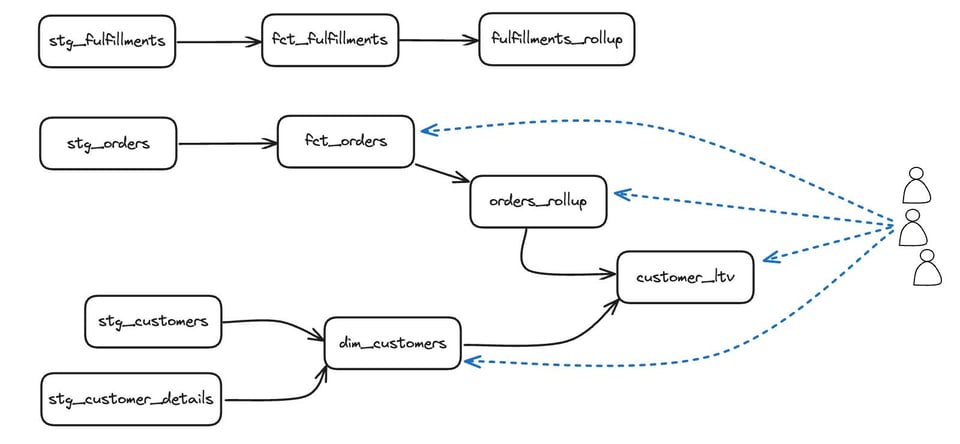
Si consultáramos por tablas sin uso, en un inicio veríamos que todas las tablas tienen algo de uso, pero ese uso vendría del propio dbt al ejecutar tests o construir modelos descendientes. Al excluir las consultas ejecutadas por dbt, identificaríamos correctamente la fila superior: stg_fulfillments, fct_fulfillments y fulfillments_rollup como modelos sin uso, pero el resultado también marcaría toda la capa stg_ como sin uso. En dbt, el uso directo no es lo único que importa. También hay que tener en cuenta el uso de los dependientes descendientes.
Esto se logra construyendo un modelo que capture los descendientes de los modelos dbt y, luego, agregando consultas de forma ingeniosa "hacia arriba" a lo largo de esas dependencias del DAG.
Visión general del enfoque
Veamos un DAG aún más sencillo, con solo 4 modelos. Para identificar correctamente los modelos dbt sin uso, primero tenemos que entender qué modelos dependen entre sí.
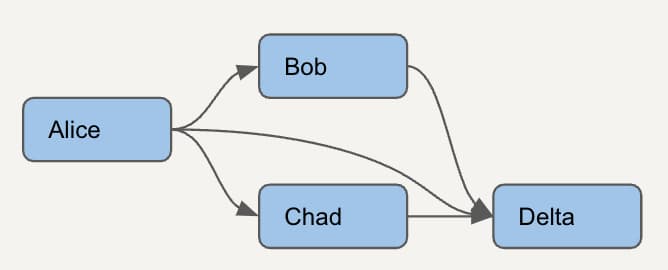
Para cada modelo necesitamos listar todos los modelos descendientes. Así se verá este DAG simple en el nuevo modelo de dependencias que vamos a crear. Las filas verdes representan un nodo y sí mismo, las naranjas son los padres directos, y la fila morada muestra que un padre directo también puede ser un padre indirecto.
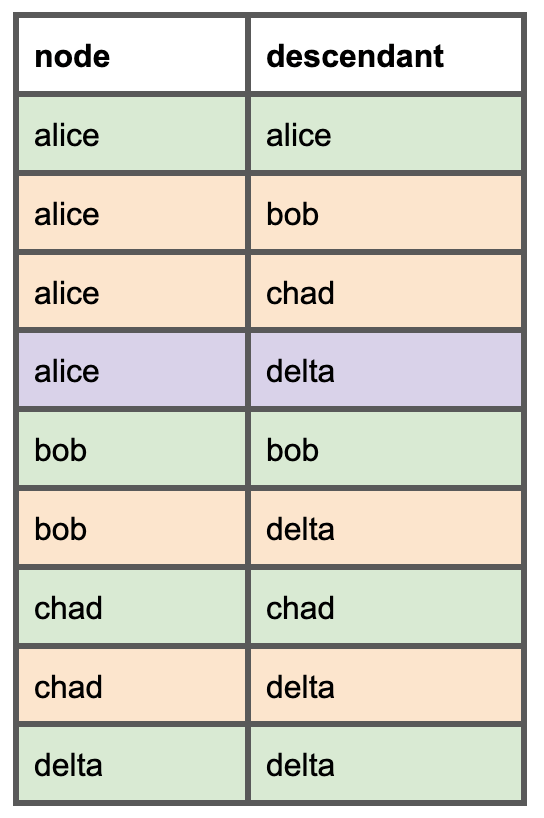
Una vez que tengamos este modelo, podremos hacer cosas como determinar si el modelo Alice se puede eliminar sin riesgo revisando el uso de sus dependencias descendientes: Bob, Chad y Delta.
Requisitos previos
Para determinar qué tablas se están usando, vamos a apoyarnos en los modelos que se discutieron en el artículo anterior. Ambos están disponibles en el paquete dbt-snowflake-monitoring, desarrollado y mantenido por SELECT.
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
Para nuestro modelo de dependientes de dbt vamos a construir algo nuevo: dbt_model_descendants. Se puede derivar de dbt-snowflake-monitoring o, con mayor precisión, de dbt_artifacts si ya lo tienes configurado. Te dejo el SQL para cualquiera de las dos fuentes:
- Opción 1:
dbt_snowflake_monitoring/dbt_queries.sql - Opción 2:
dbt_artifacts/dim_dbt__current_models.sql
Cómo modelar las dependencias en tu DAG de dbt
Paso 1: obtener los padres de cada modelo
El primer paso es derivar una tabla con una fila por cada modelo dbt y una columna tipo array que capture los padres directos del modelo.
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | ["customers", "events"] |
| events | prod.analytics.events | ["stg_events"] |
| ... | ... | ... |
Para construir este dataset hay dos opciones.
Usando dbt_snowflake_monitoring
La primera opción es usar dbt_snowflake_monitoring/dbt_queries.sql, que ya deberías tener instalado para los otros modelos requeridos (query_base_object_access, query_history_enriched). Las dos desventajas principales son que los modelos eliminados se siguen incluyendo durante un par de días después de salir del proyecto, y que los sources nunca se incluyen porque no son "refs".
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
-- and dbt_target_name = <my target>
-- and dbt_target_database = <my prod db>
-- and dbt_target_schema in <my prod schemas>
Expand Code
Usando dbt_artifacts
La segunda opción es usar dbt_artifacts/dim_dbt__current_models. Es la opción más robusta, pero requiere el paquete dbt_artifacts, cuya configuración es más compleja.
select
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array,
from dim_dbt__current_models
where
-- [optional] filter to specific databases
-- database in (<your databases>)
Paso 2: derivar los hijos de cada nodo
Ahora que tenemos la lista de nodos, vamos a crear un nuevo CTE, node_children, aplanando el CTE nodes. Esto mapea los "padres de primer grado".
Usando dbt_snowflake_monitoring
with
nodes as (
select
dbt_node_name as node,
dbt_node_refs as parent_array,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
query_id
from dbt_queries_select
where true
and start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
qualify row_number() over (partition by dbt_node_name order by end_time desc) = 1
Expand Code
Usando dbt_artifacts
with
nodes as (
select
-- assume packaged model names do not collide
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array
from dim_dbt__current_models
),
-- Unpack the parents (refs) array and swap the relationship into node -> descendent terms.
node_children as (
Expand Code
Paso 3: encontrar de forma recursiva todos los descendientes del modelo
El resto de la consulta es igual, sin importar si usas dbt-snowflake-monitoring o dbt-artifacts. Hace lo siguiente:
- Deriva
node_descendants_recursive(de todos los grados) uniendo recursivamentenode_children(del paso anterior) consigo mismo - La granularidad en este punto es "todas las rutas"
- Une una fila adicional para "un nodo y sí mismo"
- Agrega
node_descendantsen pares únicos nodo-descendiente
Esta es la consulta asumiendo que usas dbt-snowflake-monitoring:
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
Expand Code
En el apéndice encontrarás una versión de esta consulta lista para usar en tu proyecto de dbt.
Cómo consultar modelos dbt sin uso
Con el nuevo modelo dbt_model_descendants que ya tiene en cuenta las dependencias entre modelos (¿o deberíamos decir descendencias?), podemos agregar el uso directo de las tablas y propagarlo hacia arriba por el DAG. Se trata de un join de conteos de consultas del lado del descendiente, agregado de forma condicional alrededor del padre. Aquí entra en juego la self-edge: la agregación condicional permite diferenciar el uso directo del indirecto verificando si el descendiente es, en realidad, el nodo mismo.
with
table_queries as (
select
lower(query_base_object_access.object_name) as table_sk,
count(*) as count_queries
from query_history_enriched_select
inner join query_base_object_access
on query_history_enriched_select.query_id = query_base_object_access.query_id
and query_history_enriched_select.start_time = query_base_object_access.query_start_time
where
query_history_enriched_select.start_time > current_date - 180
and query_history_enriched_select.query_type = 'SELECT'
and query_history_enriched_select.execution_status = 'SUCCESS'
-- exclude dbt queries
and dbt_metadata is null
Expand Code
Esta consulta nos dice cuántas consultas de "uso" impactan directamente a cada modelo dbt, y cuántas consultas de uso se distribuyen entre los descendientes de un modelo. Si un modelo tiene total_queries = 0, no está sirviendo uso directo ni soportando uso directo en sus descendientes. Ten en cuenta que downstream_queries y total_queries serán mayores que tu conteo real de consultas en Snowflake, ya que una misma consulta puede contarse en más de un nodo.
Qué hacer con los modelos sin uso
Como Analytics Engineer, sé más sobre construir tablas nuevas que sobre eliminar las viejas.
La mayoría de los modelos dbt son transformaciones fijas de datos crudos que se pueden apagar y volver a prender sin "perder" nada. Claro, el modelo en producción quedará desactualizado hasta que vuelvas a activarlo, pero no habrá pérdida irrecuperable de información. En estos casos, deshabilitar el modelo, o eliminarlo y dejar que viva en tu historial de git, son dos buenas opciones. En esta etapa también recomiendo dropear la tabla, para evitar que algún usuario termine accediendo a datos desactualizados.
Los modelos como los snapshots de dbt u otros esquemas incrementales más elaborados quizá no encajen en esta descripción. Dar de baja algo de esta categoría va a requerir consideraciones más específicas según el caso pero, habiendo estado en esa posición, sé que también es muy probable que nadie sepa para qué sirve el modelo, ni cuál era su propósito original.
Cómo eliminar un modelo dbt de tu proyecto
Pasos para eliminar un modelo:
- Borra el archivo
.sqldel modelo.
- Con
Ctrl+Shift+Fbusca el nombre del modelo en todo el proyecto para encontrar…refs()al modelo- referencias al modelo en archivos
.ymlde schema o config.
- Dropea la tabla (o vista) correspondiente en Snowflake
Lo más probable es que no tengas que actualizar ningún ref() con este enfoque, porque cualquier modelo que referencie a un modelo sin uso también debe estar sin uso (¡de lo contrario, el padre tendría uso descendiente!). Si hay una cadena de modelos sin uso, te recomiendo empezar por el final e ir hacia atrás; en A -> B -> C, ¡borra C primero!
Deshabilitar un modelo es una forma rápida de apagarlo sin borrar nada de código. Los modelos deshabilitados se comportan como si no existieran, pero su código sigue en tu proyecto; basta con una línea de configuración:
-- my_unused_model.sql
{{ config(enabled = false) }}
select ...
Esta podría ser la forma más rápida y reversible de apagar un modelo, pero si ya estás usando git, tampoco perderías el código que elimines. Y si te preocupa el desorden de modelos, lo mejor es mandar los modelos sin uso directo a la basura, en vez de declarar un rincón dedicado a la chatarra.
Por último, no te olvides de agradecerle a tus modelos por su arduo trabajo. Como dice la gran Data Engineer Marie Kondo:
Atesora los [modelos analíticos] que te dan alegría y deja ir el resto con gratitud.
Apéndice - archivos para tu proyecto de modelos dbt
{{ config(materialized='table') }}
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from {{ ref('dbt_queries') }}
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
Expand Code
version: 2
models:
- name: dbt_model_descendants
description: >-
A table mapping each DAG model node to all of its descendant model nodes. The
mapping includes the model's self as a descendant with depth = 0. Sources are not included.
columns:
- name: node_descendant_sk
description: Unique identifier of a node-descendant pairing
tests:
- unique
- not_null
- name: node
description: The name of a node in the DAG
- name: descendant
Expand Code
Jay Sobel·Analytics Engineer en Ramp
Jay es Senior Analytics Engineer en Ramp, una de las startups de mayor crecimiento en Estados Unidos. Tiene casi una década de experiencia en análisis e ingeniería de datos, con paso por varias empresas tecnológicas en pleno crecimiento, como Gopuff, Drizly, Wanderu y LevelUp. Es un miembro apasionado de la comunidad de dbt y Snowflake, y participa con frecuencia en discusiones sobre optimización y buenas prácticas en general.