Por que se preocupar com dbt models não usados?
Uma das formas mais simples de reduzir gastos desnecessários no Snowflake é se livrar daquilo que ninguém está usando. Em um post anterior sobre como identificar tabelas não usadas no Snowflake, o Ian explicou como as views de Account Usage do Snowflake podem ser usadas para inspecionar o uso de objetos no Snowflake e, com isso, identificar e remover tabelas que não estão sendo consultadas ativamente, gerando economia em custos de armazenamento. Quando o assunto são tabelas criadas e atualizadas continuamente por ferramentas de ELT como o dbt, o potencial de economia ao removê-las é bem maior, já que você deixa de pagar tanto os custos de computação envolvidos na criação e atualização da tabela quanto os custos de armazenamento.
Se o seu projeto dbt já tem mais de um ano, é bem provável que você tenha vários dbt models que não são mais utilizados, mas que continuam rodando todo dia e gerando custos de computação. Se você procura uma vitória rápida tanto para cortar custos quanto para deixar seu data warehouse mais organizado, este post é pra você!
Entendendo o uso dos dbt models
Neste artigo vou expandir a ideia de analisar o uso de objetos do Snowflake, com foco específico no uso dos dbt models. Para isso, precisamos de um model adicional que represente o relacionamento entre os dbt models (o DAG, na forma de tabela), de modo que models intermediários com 0 uso direto não sejam marcados como não usados, desde que seus downstreams tenham alguma atividade de consulta. Recomendo começar pelo post original, ao menos para se familiarizar com o schema account_usage.
Para entender por que a abordagem daquele post não funciona para identificar dbt models não usados, observe o seguinte DAG:
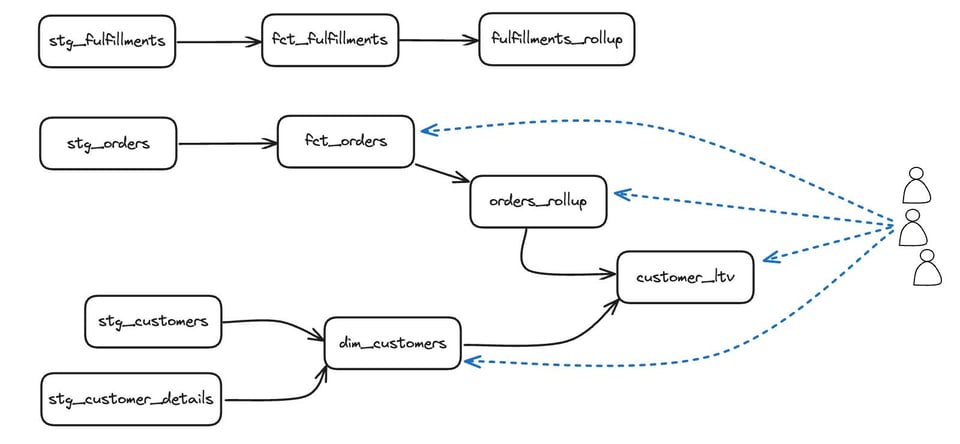
Se fôssemos consultar tabelas não usadas, no começo todas apareceriam com algum uso, mas esse uso seria do próprio dbt rodando testes ou construindo models downstream. Depois de excluir as queries executadas pelo dbt, talvez identifiquemos corretamente a linha de cima — stg_fulfillments, fct_fulfillments e fulfillments_rollup — como models não usados, mas o resultado também apontaria toda a camada stg_ como sem uso. No dbt, o uso direto não é a única coisa a considerar. Também precisamos olhar para o uso dos dependentes downstream.
Podemos resolver isso construindo um model que capture os descendentes dos dbt models e, em seguida, fazendo uma agregação inteligente das queries "para cima" ao longo dessas dependências do DAG.
Uma visão geral da abordagem
Vamos considerar um DAG ainda mais simples, com apenas 4 models. Para identificar corretamente os dbt models não usados, primeiro precisamos entender quais models dependem de quais.
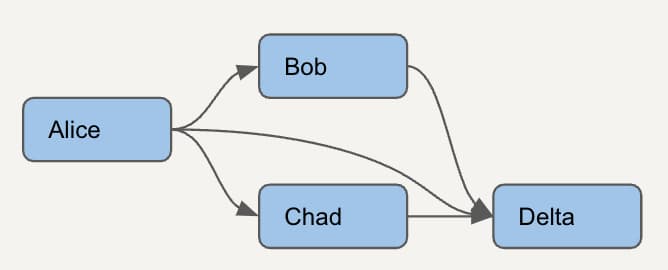
Para cada model, precisamos listar todos os models downstream. Veja como esse DAG simples vai ficar no novo model de dependências que vamos criar. As linhas verdes representam um nó e ele mesmo, as laranjas representam os pais diretos, e a linha roxa mostra que um pai direto também pode ser um pai indireto.
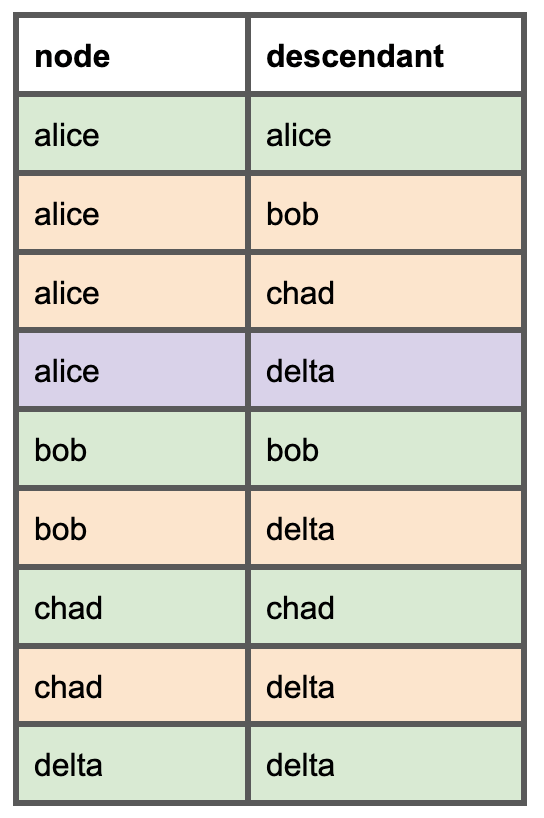
Com esse model em mãos, podemos, por exemplo, descobrir se o model Alice pode ser removido com segurança verificando o uso nos dependentes downstream: Bob, Chad e Delta.
Pré-requisitos
Para descobrir quais tabelas estão sendo usadas, vamos aproveitar os models discutidos no artigo anterior. Os dois estão disponíveis no pacote dbt-snowflake-monitoring, criado e mantido pela SELECT.
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
Para o nosso model de dependentes do dbt, vamos criar algo novo: dbt_model_descendants. Ele pode ser derivado a partir do dbt-snowflake-monitoring ou, de forma mais precisa, via dbt_artifacts, caso você já tenha configurado. Vou mostrar o SQL para as duas fontes:
- Opção 1:
dbt_snowflake_monitoring/dbt_queries.sql - Opção 2:
dbt_artifacts/dim_dbt__current_models.sql
Como modelar as dependências do seu DAG no dbt
Passo 1: obter os pais de cada model
Nosso primeiro passo é montar uma tabela com uma linha para cada dbt model, contendo uma coluna do tipo array com os pais diretos do model.
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | ["customers", "events"] |
| events | prod.analytics.events | ["stg_events"] |
| ... | ... | ... |
Para montar esse dataset, há duas opções.
Usando dbt_snowflake_monitoring
A primeira opção é usar dbt_snowflake_monitoring/dbt_queries.sql, que você já deve ter instalado por causa dos outros models necessários (query_base_object_access, query_history_enriched). As duas principais desvantagens dessa opção são: models deletados continuam aparecendo por alguns dias depois de saírem do projeto, e sources nunca são incluídos, porque não são "refs".
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
-- and dbt_target_name = <my target>
-- and dbt_target_database = <my prod db>
-- and dbt_target_schema in <my prod schemas>
Expandir código
Usando dbt_artifacts
A segunda opção é usar dbt_artifacts/dim_dbt__current_models. É a opção mais robusta, mas exige o pacote dbt_artifacts, que tem um processo de configuração mais complicado.
select
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array,
from dim_dbt__current_models
where
-- [optional] filter to specific databases
-- database in (<your databases>)
Passo 2: derivar os filhos dos nós
Agora que temos a lista de nós, vamos criar uma nova CTE, node_children, fazendo o flatten da CTE nodes. Isso mapeia os "pais de primeiro grau".
Usando dbt_snowflake_monitoring
with
nodes as (
select
dbt_node_name as node,
dbt_node_refs as parent_array,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
query_id
from dbt_queries_select
where true
and start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
qualify row_number() over (partition by dbt_node_name order by end_time desc) = 1
Expandir código
Usando dbt_artifacts
with
nodes as (
select
-- assume packaged model names do not collide
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array
from dim_dbt__current_models
),
-- Unpack the parents (refs) array and swap the relationship into node -> descendent terms.
node_children as (
Expandir código
Passo 3: encontrar recursivamente todos os descendentes do model
O restante da query é igual, independentemente de você estar usando dbt-snowflake-monitoring ou dbt-artifacts. Ela faz o seguinte:
- Deriva
node_descendants_recursive(todos os graus) fazendo um join recursivo denode_children(acima) com ele mesmo - A granularidade nesse ponto é "todos os caminhos"
- Une uma linha adicional para "um nó e ele mesmo"
- Agrega
node_descendantsem pares únicos de nó-descendente
Veja a query supondo que você esteja usando dbt-snowflake-monitoring:
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
Expandir código
Veja no apêndice uma versão dessa query pronta para usar no seu projeto dbt.
Como consultar dbt models não usados
Com o novo model dbt_model_descendants, que considera as dependências dos models (ou melhor, as descendências?), podemos agregar o uso direto da tabela e distribuí-lo "para cima" ao longo do DAG. Na prática, isso é um join da contagem de queries do lado do descendente, com agregação condicional em torno do pai. A auto-aresta entra em ação aqui, já que a agregação condicional consegue diferenciar uso direto de uso indireto verificando se o descendente é, na verdade, o próprio nó.
with
table_queries as (
select
lower(query_base_object_access.object_name) as table_sk,
count(*) as count_queries
from query_history_enriched_select
inner join query_base_object_access
on query_history_enriched_select.query_id = query_base_object_access.query_id
and query_history_enriched_select.start_time = query_base_object_access.query_start_time
where
query_history_enriched_select.start_time > current_date - 180
and query_history_enriched_select.query_type = 'SELECT'
and query_history_enriched_select.execution_status = 'SUCCESS'
-- exclude dbt queries
and dbt_metadata is null
Expandir código
Essa query mostra quantas queries de "uso" atingem diretamente cada dbt model, além de quantas queries de uso estão distribuídas pelos descendentes downstream de um model. Se um model tem total_queries = 0, ele não está atendendo nenhum uso direto nem dando suporte a uso direto downstream. Vale lembrar que downstream_queries e total_queries ficarão maiores do que sua contagem total real de queries no Snowflake, já que uma mesma query pode ser contabilizada em mais de um model.
O que fazer com os models não usados
Como analytics engineer, entendo mais de construir tabelas novas do que de deletar tabelas antigas.
A maioria dos dbt models é uma transformação fixa de dados brutos, que pode ser desligada e religada sem que nada se "perca". É claro que o model de produção vai ficar desatualizado até ser reativado, mas não haverá perda irrecuperável de informação. Nesses casos, basta desabilitar o model, ou deletá-lo e deixar que ele continue vivo no histórico do git — as duas são boas opções. Recomendo também dropar a tabela nesse momento, só para evitar que algum usuário acesse dados desatualizados.
Models como dbt snapshots, ou outros esquemas incrementais mais elaborados, podem não se encaixar nessa descrição. Aposentar algo nessa categoria exige uma análise mais específica para cada caso, mas, falando por experiência própria, é bem possível que ninguém saiba pra que serve o model, nem qual era a intenção original dele.
Como remover um dbt model do seu projeto
Passos para deletar um model:
- Apague o arquivo
.sqldo model.
- Use
Ctrl+Shift+Fpara procurar o nome do model em todo o projeto e encontrar…refs()para o model- referências ao model em arquivos
.ymlde schema ou config.
- Drope a tabela (ou view) correspondente no Snowflake.
Provavelmente você não vai precisar atualizar nenhum ref() seguindo essa abordagem, porque qualquer model que referencie um model não usado também deve estar sem uso (caso contrário, o pai teria uso downstream!). Se houver uma cadeia de models não usados, recomendo começar pelo fim e ir voltando; em A -> B -> C, delete o C primeiro!
Desabilitar um model é uma forma rápida de desligá-lo sem apagar nenhum código. Models desabilitados se comportam como se não existissem, mas o código continua no projeto — é só uma linha de config:
-- my_unused_model.sql
{{ config(enabled = false) }}
select ...
Essa pode ser a forma mais rápida e fácil de reverter para desligar um model, mas, se você já usa git, não vai perder nada do código que apagar também. E se a sua preocupação é com a proliferação de models, o melhor mesmo é mandar os models não usados pra lixeira, em vez de criar um cantinho dedicado pra eles.
Por fim, não se esqueça de agradecer aos seus models pelo trabalho duro. Como diz a grande Data Engineer Marie Kondo:
Valorize os [models analíticos] que lhe trazem alegria, e deixe os demais partirem com gratidão.
Apêndice — arquivos para o seu projeto dbt
{{ config(materialized='table') }}
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from {{ ref('dbt_queries') }}
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
Expandir código
version: 2
models:
- name: dbt_model_descendants
description: >-
A table mapping each DAG model node to all of its descendant model nodes. The
mapping includes the model's self as a descendant with depth = 0. Sources are not included.
columns:
- name: node_descendant_sk
description: Unique identifier of a node-descendant pairing
tests:
- unique
- not_null
- name: node
description: The name of a node in the DAG
- name: descendant
Expandir código
Jay Sobel·Analytics Engineer na Ramp
Jay é Senior Analytics Engineer na Ramp, uma das startups que mais crescem nos EUA. Jay tem quase uma década de experiência em análise e engenharia de dados, passando por várias empresas de tecnologia em rápido crescimento, como Gopuff, Drizly, Wanderu e LevelUp. Jay é um membro engajado das comunidades dbt e Snowflake, contribuindo regularmente em discussões sobre otimização e boas práticas em geral.