Perché occuparsi dei modelli dbt inutilizzati?
Uno dei modi più semplici per ridurre la spesa Snowflake superflua è eliminare ciò che non viene utilizzato. In un articolo precedente su come individuare le tabelle inutilizzate in Snowflake, Ian ha spiegato come sfruttare le viste Account Usage di Snowflake per analizzare l'utilizzo degli oggetti e, in ultima analisi, identificare e rimuovere le tabelle non interrogate attivamente, risparmiando così sui costi di storage. Quando si tratta di tabelle create e aggiornate in continuazione da strumenti ELT come dbt, il risparmio potenziale legato alla loro rimozione è molto più consistente, perché oltre ai costi di storage si abbattono anche quelli di compute associati alla creazione e all'aggiornamento della tabella.
Se il vostro progetto dbt ha più di un anno di vita, è molto probabile che vi siano diversi modelli dbt ormai inutilizzati ma comunque eseguiti ogni giorno, con costi di compute che continuano a maturare. Se cercate un risultato rapido per ridurre i costi e fare al tempo stesso un po' di ordine nel vostro data warehouse, questo articolo fa per voi!
Capire l'utilizzo dei modelli dbt
In questo articolo amplierò il discorso sull'analisi dell'utilizzo degli oggetti Snowflake per concentrarmi nello specifico sull'utilizzo dei modelli dbt. Serve un modello aggiuntivo che rappresenti la relazione tra i modelli dbt (il DAG, sotto forma di tabella), così che i modelli intermedi con 0 utilizzi diretti non vengano etichettati come inutilizzati finché i loro modelli a valle mostrano una qualche attività di query. Consiglio di partire dall'articolo originale, quanto meno per prendere confidenza con lo schema account_usage.
Per capire perché l'approccio di quell'articolo non basta a individuare i modelli dbt inutilizzati, prendiamo in esame il seguente DAG:
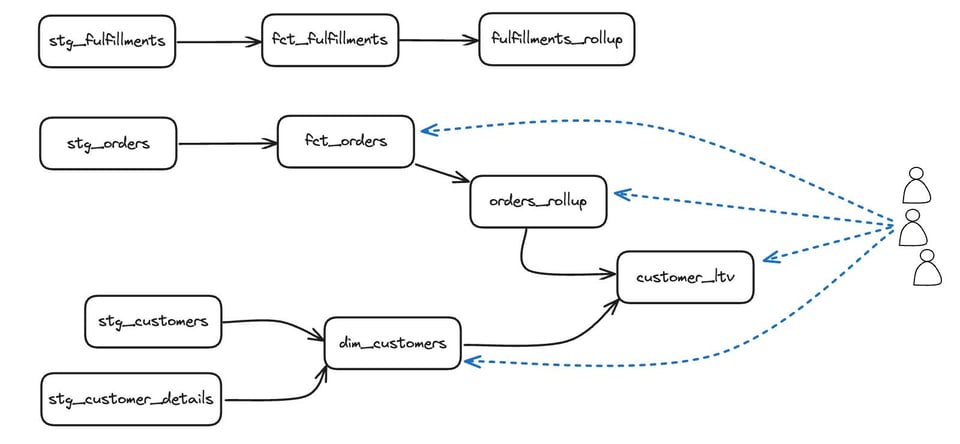
Interrogando le tabelle inutilizzate, in un primo momento ogni tabella risulterebbe avere un qualche utilizzo, ma si tratterebbe dell'utilizzo generato da dbt stesso mentre esegue test o costruisce modelli a valle. Una volta escluse le query eseguite da dbt, potremmo identificare correttamente come inutilizzati i modelli della riga superiore — stg_fulfillments, fct_fulfillments e fulfillments_rollup — ma il risultato segnalerebbe come inutilizzato anche l'intero livello stg_. In dbt l'utilizzo diretto non è l'unico aspetto da considerare: occorre tenere conto anche dell'utilizzo delle dipendenze a valle.
Possiamo farlo costruendo un modello che catturi i discendenti dei modelli dbt e poi aggregando in modo opportuno le query "verso l'alto" lungo queste dipendenze del DAG.
Panoramica dell'approccio
Consideriamo un DAG ancora più semplice, con appena 4 modelli. Per individuare correttamente i modelli dbt inutilizzati dobbiamo prima capire quali modelli dipendono gli uni dagli altri.
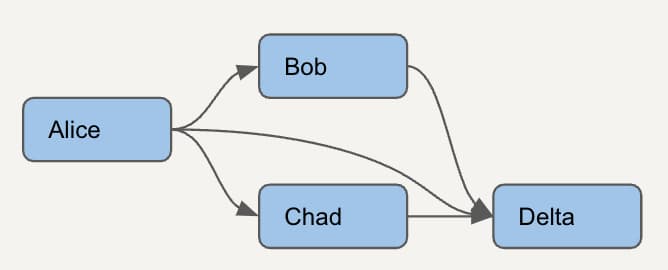
Per ciascun modello dobbiamo elencare tutti i modelli a valle. Ecco come si presenterà questo semplice DAG nel nuovo modello di dipendenze che andremo a creare. Le righe verdi rappresentano un nodo con sé stesso, quelle arancioni i genitori diretti, mentre la riga viola mostra che un genitore diretto può essere anche un genitore indiretto.
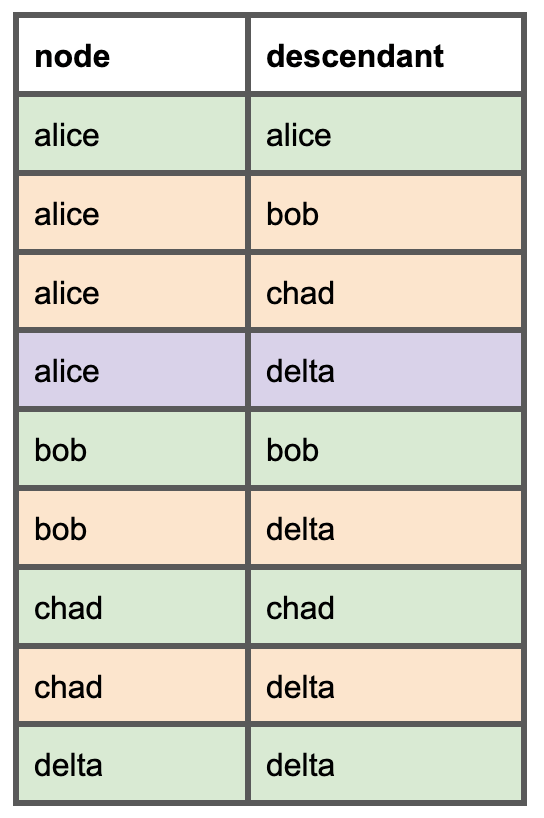
Una volta ottenuto questo modello potremo, per esempio, stabilire se il modello Alice può essere rimosso in sicurezza verificando l'utilizzo delle dipendenze a valle: Bob, Chad e Delta.
Prerequisiti
Per stabilire quali tabelle vengono utilizzate ci appoggeremo ai modelli illustrati nell'articolo precedente. Sono entrambi disponibili nel pacchetto dbt-snowflake-monitoring, creato e mantenuto da SELECT.
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
Per il nostro modello delle dipendenze dbt costruiremo qualcosa di nuovo: dbt_model_descendants. Si può derivare da dbt-snowflake-monitoring oppure, in modo più accurato, da dbt_artifacts, se lo avete configurato. Fornirò il codice SQL per entrambe le fonti:
- Opzione 1:
dbt_snowflake_monitoring/dbt_queries.sql - Opzione 2:
dbt_artifacts/dim_dbt__current_models.sql
Come modellare le dipendenze nel DAG dbt
Step 1: ottenere i genitori di ciascun modello
Il primo passo è ricavare una tabella con una riga per ogni modello dbt e una colonna array che ne raccoglie i genitori diretti.
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | ["customers", "events"] |
| events | prod.analytics.events | ["stg_events"] |
| ... | ... | ... |
Per costruire questo dataset ci sono due opzioni.
Con dbt_snowflake_monitoring
La prima opzione è usare dbt_snowflake_monitoring/dbt_queries.sql, che dovreste avere già installato per gli altri modelli richiesti (query_base_object_access, query_history_enriched). I due principali svantaggi sono che i modelli eliminati restano inclusi per un paio di giorni dopo essere usciti dal progetto e che le sources non vengono mai incluse, perché non sono "refs".
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
-- and dbt_target_name = <my target>
-- and dbt_target_database = <my prod db>
-- and dbt_target_schema in <my prod schemas>
Espandi codice
Con dbt_artifacts
La seconda opzione è usare dbt_artifacts/dim_dbt__current_models. È la più robusta, ma richiede il pacchetto dbt_artifacts, la cui configurazione è più complessa.
select
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array,
from dim_dbt__current_models
where
-- [optional] filter to specific databases
-- database in (<your databases>)
Step 2: ricavare i figli dei nodi
Ora che abbiamo un elenco di nodi, creiamo una nuova CTE, node_children, appiattendo la CTE nodes. In questo modo mappiamo i "genitori di primo grado".
Con dbt_snowflake_monitoring
with
nodes as (
select
dbt_node_name as node,
dbt_node_refs as parent_array,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
query_id
from dbt_queries_select
where true
and start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
qualify row_number() over (partition by dbt_node_name order by end_time desc) = 1
Espandi codice
Con dbt_artifacts
with
nodes as (
select
-- assume packaged model names do not collide
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array
from dim_dbt__current_models
),
-- Unpack the parents (refs) array and swap the relationship into node -> descendent terms.
node_children as (
Espandi codice
Step 3: trovare ricorsivamente tutti i discendenti dei modelli
Il resto della query è identico sia che stiate usando dbt-snowflake-monitoring sia dbt-artifacts. Esegue i seguenti passaggi:
- Ricava
node_descendants_recursive(tutti i gradi) con un join ricorsivo dinode_children(visto sopra) su sé stesso - A questo punto la granularità è quella di "tutti i percorsi"
- Aggiunge in union una riga ulteriore per "un nodo e sé stesso"
- Aggrega
node_descendantsin coppie nodo-discendente univoche
Ecco la query nel caso stiate usando dbt-snowflake-monitoring:
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
Espandi codice
In appendice trovate una versione di questa query da integrare nel vostro progetto dbt.
Come interrogare i modelli dbt inutilizzati
Con il nuovo modello dbt_model_descendants, che tiene conto delle dipendenze tra modelli (o dovremmo dire "discendenze"?), possiamo aggregare l'utilizzo diretto delle tabelle e distribuirlo verso l'alto lungo il DAG. In pratica si tratta di una join dei conteggi di query sul lato discendente, aggregata in modo condizionale attorno al genitore. È qui che entra in gioco l'auto-arco: l'aggregazione condizionale può distinguere l'utilizzo diretto da quello indiretto verificando se il discendente coincide con il nodo stesso.
with
table_queries as (
select
lower(query_base_object_access.object_name) as table_sk,
count(*) as count_queries
from query_history_enriched_select
inner join query_base_object_access
on query_history_enriched_select.query_id = query_base_object_access.query_id
and query_history_enriched_select.start_time = query_base_object_access.query_start_time
where
query_history_enriched_select.start_time > current_date - 180
and query_history_enriched_select.query_type = 'SELECT'
and query_history_enriched_select.execution_status = 'SUCCESS'
-- exclude dbt queries
and dbt_metadata is null
Espandi codice
Questa query ci dice quante query di "utilizzo" colpiscono direttamente ciascun modello dbt e quante sono distribuite tra i suoi discendenti a valle. Se un modello presenta total_queries = 0, non sta servendo alcun utilizzo diretto né supportando alcun utilizzo diretto a valle. Attenzione: downstream_queries e total_queries saranno più alti del conteggio effettivo totale delle query Snowflake, perché una singola query può essere conteggiata su più di un nodo.
Cosa fare con i modelli inutilizzati
Come analytics engineer, ne so molto di più sul costruire nuove tabelle che sull'eliminare quelle vecchie.
La maggior parte dei modelli dbt sono trasformazioni fisse di dati grezzi che si possono spegnere e riaccendere senza "perdere" nulla. È vero, il modello in produzione diventerà obsoleto finché non lo si riaccende, ma non ci sarà alcuna perdita irrecuperabile di informazioni. In questi casi, disabilitare semplicemente il modello, oppure eliminarlo lasciandolo vivere nello storico di git, sono entrambe buone scelte. In questa fase consiglio anche di fare il drop della tabella, giusto per evitare che qualcuno acceda a dati ormai obsoleti.
Modelli come gli snapshot dbt, o altri schemi incrementali più sofisticati, potrebbero non rientrare in questa descrizione. Deprecare qualcosa del genere richiederà valutazioni più specifiche caso per caso, ma per esperienza personale so che spesso è probabile che nessuno ricordi più a cosa serva quel modello, né con quale intento sia stato creato.
Come rimuovere un modello dbt dal proprio progetto
Passaggi per eliminare un modello:
- Eliminare il file modello
.sql.
- Con
Ctrl+Shift+Fcercare il nome del modello nell'intero progetto per individuare…- i
refs()al modello - i riferimenti al modello nei
.ymldi schema o configurazione.
- i
- Fare il drop della tabella (o vista) Snowflake corrispondente
Con questo approccio difficilmente dovrete aggiornare un ref(): qualsiasi modello che faccia riferimento a un modello inutilizzato deve essere a sua volta inutilizzato (altrimenti il genitore avrebbe utilizzo a valle!). Se c'è una catena di modelli inutilizzati, consiglio di partire dall'estremità finale e procedere a ritroso: in A -> B -> C, eliminate prima C!
Disabilitare un modello è un modo rapido per spegnerlo senza eliminare codice. I modelli disabilitati si comportano come se non esistessero, ma il loro codice resta nel progetto: basta una riga di configurazione.
-- my_unused_model.sql
{{ config(enabled = false) }}
select ...
Potrebbe essere il modo più rapido e più facile da invertire per spegnere un modello, ma se state già usando git non perdereste comunque il codice eliminato. E se vi preoccupa la proliferazione dei modelli, tanto vale buttare gli inutilizzati nel cestino, invece di destinare loro un angolo della discarica.
Infine, ricordatevi di ringraziare i vostri modelli per il duro lavoro svolto. Come dice la grande Data Engineer Marie Kondo:
Custodite i [modelli analitici] che vi regalano gioia e lasciate andare il resto con gratitudine.
Appendice - file per il vostro progetto dbt
{{ config(materialized='table') }}
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from {{ ref('dbt_queries') }}
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
Espandi codice
version: 2
models:
- name: dbt_model_descendants
description: >-
A table mapping each DAG model node to all of its descendant model nodes. The
mapping includes the model's self as a descendant with depth = 0. Sources are not included.
columns:
- name: node_descendant_sk
description: Unique identifier of a node-descendant pairing
tests:
- unique
- not_null
- name: node
description: The name of a node in the DAG
- name: descendant
Espandi codice
Jay Sobel·Analytics Engineer presso Ramp
Jay è Senior Analytics Engineer presso Ramp, una delle startup in più rapida crescita negli Stati Uniti. Ha quasi un decennio di esperienza in data analysis ed engineering, maturata in numerose aziende tecnologiche in forte crescita come Gopuff, Drizly, Wanderu e LevelUp. Jay è un membro appassionato della community dbt e Snowflake, a cui contribuisce regolarmente con interventi su ottimizzazione e best practice.