未使用のdbtモデルを放置してはいけない理由
Snowflakeの無駄な支出を減らす最も手軽な方法のひとつは、使われていないものを削ることです。以前の記事「Snowflakeで未使用のテーブルを特定する方法」では、IanがSnowflakeのAccount Usageビューを使ってオブジェクトの利用状況を可視化し、実際にはクエリされていないテーブルを特定・削除してストレージコストを抑える方法を紹介しました。一方、dbtのようなELTツールで作成され、継続的に更新されているテーブルを削除できれば、節約効果はさらに大きくなります。ストレージコストだけでなく、テーブルの作成・更新にかかるコンピュートコストも同時に削減できるからです。
運用1年を超えるdbtプロジェクトであれば、すでに誰も使っていないのに毎日実行され、コンピュートコストを発生させ続けているモデルがいくつもあるはずです。コスト削減とデータウェアハウスの整理を同時に進められる手堅い一手を探しているなら、本記事はまさにうってつけです。
dbtモデルの利用状況を理解する
本記事では、Snowflakeオブジェクトの利用状況を把握するという考え方を発展させ、dbtモデルそのものの利用状況をとらえる方法を取り上げます。そのためには、dbtモデル間の関係(DAG)をテーブルとして表現する追加モデルが必要です。これがあれば、直接の利用がゼロでも下流に何らかのクエリ活動がある中間モデルを、誤って未使用と判定せずに済みます。まずは元の記事に目を通し、account_usageスキーマに慣れておくことをおすすめします。
前回の記事のアプローチではdbtの未使用モデルを特定できない理由を、次のDAGを見ながら考えてみましょう。
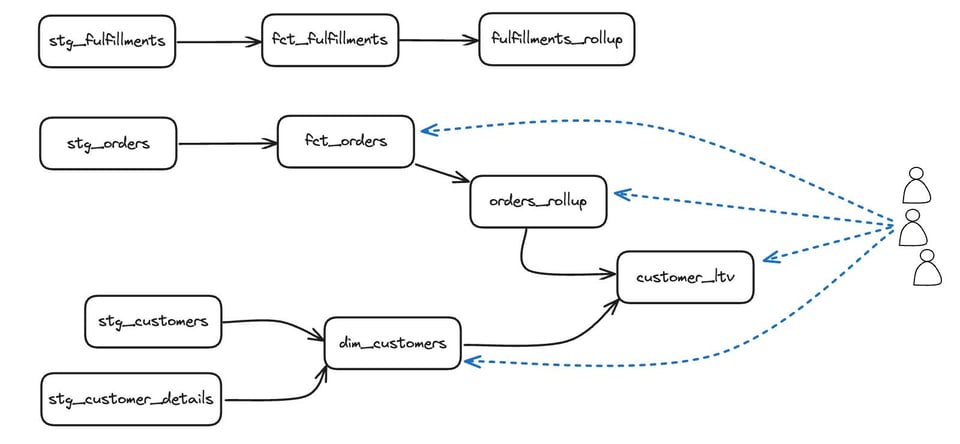
未使用テーブルをそのままクエリすると、最初はすべてのテーブルに何らかの利用があるように見えます。しかしその実態は、dbt自身によるテスト実行や下流モデルの構築です。dbtが発行したクエリを除外すれば、上段のstg_fulfillments、fct_fulfillments、fulfillments_rollupは未使用モデルとして正しく特定できますが、同時にstg_レイヤー全体まで未使用と判定されてしまうでしょう。dbtにおいては、直接の利用だけを見ていては不十分で、下流の依存モデルの利用状況も合わせて考慮する必要があるのです。
そのためには、dbtモデルの子孫関係をとらえるモデルを構築し、DAGの依存関係に沿ってクエリを「上向きに」うまく集計する仕組みを用意します。
アプローチの全体像
まずは、わずか4モデルだけのよりシンプルなDAGを見てみましょう。未使用のdbtモデルを正しく特定するには、どのモデルがどのモデルに依存しているかを把握することから始める必要があります。
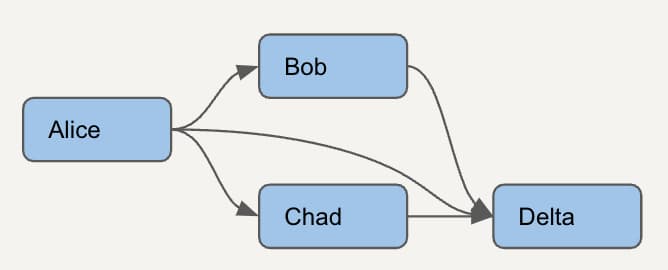
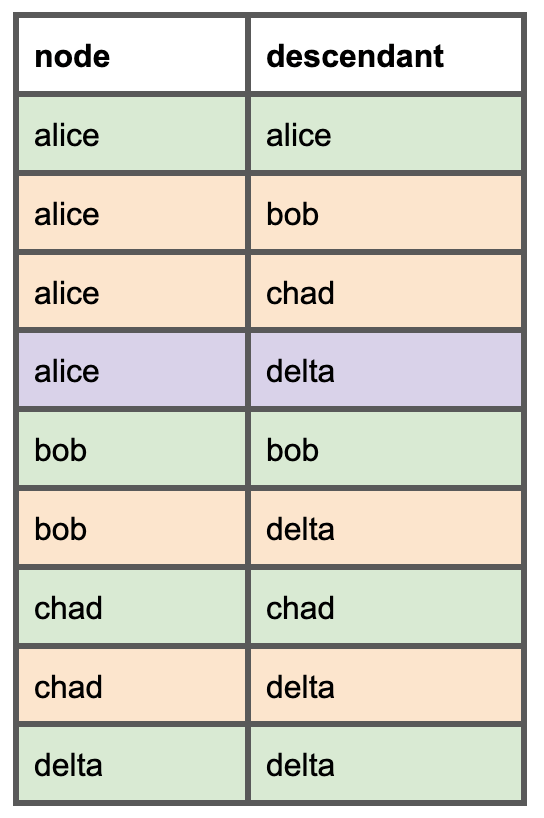
各モデルについて、すべての下流モデルをリスト化します。これから作成する依存関係モデルでは、このシンプルなDAGは次のように表現されます。緑の行はノードと自分自身、オレンジの行は直接の親、紫の行は「直接の親が間接的な親にもなり得る」ことを示しています。
このモデルが手に入れば、たとえばAliceモデルを安全に削除できるかどうかを、下流の依存先であるBob、Chad、Deltaの利用状況をチェックすることで判断できます。
前提条件
テーブルが実際に使われているかどうかを判断するため、前回の記事で紹介したモデルを活用します。いずれもSELECTが開発・メンテナンスしているdbt-snowflake-monitoringパッケージに含まれています。
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
dbtの依存関係モデルとしては、新たにdbt_model_descendantsを構築します。これはdbt-snowflake-monitoringから導出することも、より正確には(導入済みであれば)dbt_artifactsから導出することもできます。どちらのソースにも対応したSQLを示します。
- オプション1:
dbt_snowflake_monitoring/dbt_queries.sql - オプション2:
dbt_artifacts/dim_dbt__current_models.sql
dbt DAGの依存関係をモデル化する方法
ステップ1: 各モデルの親を取得する
最初のステップとして、各dbtモデルを1行で表し、その直接の親を配列カラムに格納したテーブルを導出します。
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | ["customers", "events"] |
| events | prod.analytics.events | ["stg_events"] |
| ... | ... | ... |
このデータセットを構築する方法は2つあります。
dbt_snowflake_monitoringを使う場合
1つ目は、dbt_snowflake_monitoring/dbt_queries.sqlを使う方法です。他の必須モデル(query_base_object_access、query_history_enriched)のためにすでに導入済みのはずです。このオプションの主な弱点は2つあります。削除されたモデルがプロジェクトから外れた後も数日間はリストに残ってしまうこと、そしてソースは「ref」ではないため一切含まれないことです。
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
-- and dbt_target_name = <my target>
-- and dbt_target_database = <my prod db>
-- and dbt_target_schema in <my prod schemas>
コードを展開
dbt_artifactsを使う場合
2つ目は、dbt_artifacts/dim_dbt__current_modelsを使う方法です。こちらの方が堅牢ですが、セットアップ手順がより複雑なdbt_artifactsパッケージが必要になります。
select
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array,
from dim_dbt__current_models
where
-- [optional] filter to specific databases
-- database in (<your databases>)
ステップ2: ノードの子を導出する
ノードのリストが揃ったので、次はnodes CTEをフラット化し、新たなCTE node_childrenを作ります。これで「1次の親」がマッピングされます。
dbt_snowflake_monitoringを使う場合
with
nodes as (
select
dbt_node_name as node,
dbt_node_refs as parent_array,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
query_id
from dbt_queries_select
where true
and start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
qualify row_number() over (partition by dbt_node_name order by end_time desc) = 1
コードを展開
dbt_artifactsを使う場合
with
nodes as (
select
-- assume packaged model names do not collide
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array
from dim_dbt__current_models
),
-- Unpack the parents (refs) array and swap the relationship into node -> descendent terms.
node_children as (
コードを展開
ステップ3: 再帰的にすべての子孫モデルを洗い出す
残りのクエリは、dbt-snowflake-monitoringとdbt-artifactsのどちらを使っていても共通です。処理の流れは次のとおりです。
- 先ほどの
node_childrenを自己再帰的に結合し、node_descendants_recursive(あらゆる次数の子孫)を導出する - この時点の粒度は「すべての経路」です
- 「ノードと自分自身」を表す行をUNIONで追加する
node_descendantsを、ノードと子孫のユニークなペアに集約する
dbt-snowflake-monitoringを使う前提のクエリは以下のとおりです。
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optional] add additional filters if you want to exclude certain environments or projects
-- and dbt_node_package_name = <my project>
コードを展開
ご自身のdbtプロジェクトで使えるバージョンのクエリは、巻末の付録を参照してください。
未使用のdbtモデルをクエリで見つける方法
モデル依存関係(「子孫関係」と呼ぶべきかもしれません)を反映したdbt_model_descendantsモデルを使えば、テーブルへの直接利用を集計し、DAGの上流へとさかのぼって配分できます。具体的には、子孫側のクエリ件数をJOINし、親を軸に条件付きで集計する形になります。ここで「自分自身への辺」が活きてきます。条件付き集計の際に、その子孫がノード自身かどうかを判定することで、直接利用と間接利用を区別できるのです。
with
table_queries as (
select
lower(query_base_object_access.object_name) as table_sk,
count(*) as count_queries
from query_history_enriched_select
inner join query_base_object_access
on query_history_enriched_select.query_id = query_base_object_access.query_id
and query_history_enriched_select.start_time = query_base_object_access.query_start_time
where
query_history_enriched_select.start_time > current_date - 180
and query_history_enriched_select.query_type = 'SELECT'
and query_history_enriched_select.execution_status = 'SUCCESS'
-- exclude dbt queries
and dbt_metadata is null
コードを展開
このクエリからは、各dbtモデルに直接ヒットした「利用」クエリ数と、そのモデルの下流の子孫に配分される利用クエリ数がわかります。あるモデルのtotal_queries = 0であれば、そのモデルは直接利用されておらず、下流の直接利用も支えていないということです。なお、downstream_queriesとtotal_queriesはSnowflakeの実際の総クエリ数より大きくなる点にご注意ください。1つのクエリが複数モデルにまたがってカウントされる場合があるためです。
未使用モデルをどう扱うか
アナリティクスエンジニアとして正直に言えば、新しいテーブルの作り方には詳しくても、古いテーブルの片付け方となると経験が少ないものです。
ほとんどのdbtモデルは生データを変換しているだけの固定的な処理であり、オン・オフを切り替えても何かを「失う」わけではありません。確かに本番モデルは、再度オンにするまでの間は古いままになりますが、取り返しのつかない情報損失が起きるわけではないのです。こうしたケースでは、モデルを無効化するか、削除してgitの履歴の中で生かしておくか、どちらも有効な選択肢です。古いデータにユーザーがアクセスしてしまうのを防ぐため、この段階でテーブル自体もDROPしておくことをおすすめします。
dbtのスナップショットや、その他の凝ったインクリメンタル方式のモデルは、この単純なパターンには当てはまらないかもしれません。この種のモデルの廃止には、ケースバイケースの検討が欠かせません。とはいえ、私自身も同じ立場に置かれた経験から言えば、そのモデルが何のためにあるのか、そもそも何を意図したものなのかを誰も把握していない、というケースが少なくないのも事実です。
プロジェクトからdbtモデルを削除する方法
モデルを削除する手順:
.sqlモデルファイルを削除します。
Ctrl+Shift+Fでプロジェクト全体からモデル名を検索し、以下を探します。- そのモデルへの
refs() - schemaやconfigの
.ymlでのモデル参照
- そのモデルへの
- 対応するSnowflakeのテーブル(またはビュー)をDROPします。
このアプローチでは、おそらくref()を書き換える必要はありません。未使用モデルを参照しているモデルもまた未使用のはずだからです(そうでなければ、親モデルに下流の利用があることになります!)。未使用モデルが連鎖している場合は、末端から順にさかのぼって削除することをおすすめします。A -> B -> Cなら、まずCから手をつけましょう。
モデルの無効化は、コードを一切消さずにモデルをオフにできる手軽な方法です。無効化されたモデルはあたかも存在しないかのように振る舞いますが、コード自体はプロジェクトに残ります。必要なのは設定1行だけです。
-- my_unused_model.sql
{{ config(enabled = false) }}
select ...
これはおそらく最も手早く、最も元に戻しやすいモデル停止方法ですが、すでにgitを使っているなら、削除したコードが失われることもありません。モデルの乱立を本気で抑えたいのであれば、未使用モデルは「ゴミ捨て場」として一角にためておくよりも、思い切って処分してしまう方が得策でしょう。
最後に、これまで働いてくれたモデルへの感謝を忘れずに。データエンジニア界の偉人、近藤麻理恵氏の言葉を借りるなら——
ときめく[分析モデル]を大切にし、それ以外のものには感謝を込めて手放しましょう。
付録 - dbtプロジェクトで使えるファイル
{{ config(materialized='table') }}
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from {{ ref('dbt_queries') }}
where
start_time > current_date - 3 -- tunes risk of deleted model inclusion
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
コードを展開
version: 2
models:
- name: dbt_model_descendants
description: >-
A table mapping each DAG model node to all of its descendant model nodes. The
mapping includes the model's self as a descendant with depth = 0. Sources are not included.
columns:
- name: node_descendant_sk
description: Unique identifier of a node-descendant pairing
tests:
- unique
- not_null
- name: node
description: The name of a node in the DAG
- name: descendant
コードを展開
Jay Sobel・Analytics Engineer at Ramp
Jayは、米国で最も急成長中のスタートアップの一つであるRampでSenior Analytics Engineerを務めています。Gopuff、Drizly、Wanderu、LevelUpといった急成長中のテック企業を渡り歩き、データ分析・エンジニアリング分野で10年近いキャリアを積んできました。dbtとSnowflakeコミュニティの熱心な一員として、最適化やベストプラクティスに関する議論にも継続的に貢献しています。