Pourquoi se soucier des modèles dbt inutilisés ?
L'un des moyens les plus simples de réduire les dépenses Snowflake superflues, c'est de supprimer ce qui ne sert plus. Dans un précédent article sur l'identification des tables inutilisées dans Snowflake, Ian expliquait comment les vues Account Usage de Snowflake permettent d'analyser l'utilisation des objets afin de repérer puis supprimer les tables qui ne sont plus interrogées activement, et ainsi réduire les coûts de stockage. Pour les tables créées et mises à jour en continu par des outils ELT comme dbt, les économies potentielles sont bien plus élevées, car on réduit à la fois les coûts de compute liés à la création et à la mise à jour de la table, et les coûts de stockage.
Si votre projet dbt existe depuis plus d'un an, il y a fort à parier que certains modèles ne soient plus utilisés tout en continuant à s'exécuter chaque jour et à générer des coûts de compute. Si vous cherchez une action rapide pour à la fois alléger vos coûts et assainir votre data warehouse, cet article est fait pour vous !
Comprendre l'utilisation des modèles dbt
Dans cet article, je vais approfondir le principe d'analyse de l'utilisation des objets Snowflake pour cibler spécifiquement celle des modèles dbt. Cela nécessite un modèle supplémentaire pour représenter la relation entre les modèles dbt (le DAG, sous forme de table), afin que les modèles intermédiaires sans utilisation directe ne soient pas marqués comme inutilisés, tant que leurs descendants génèrent une activité de requêtes. Je recommande de commencer par l'article original, ne serait-ce que pour se familiariser avec le schéma account_usage.
Pour comprendre pourquoi l'approche de ce précédent article ne suffit pas à identifier les modèles dbt inutilisés, prenons le DAG suivant :
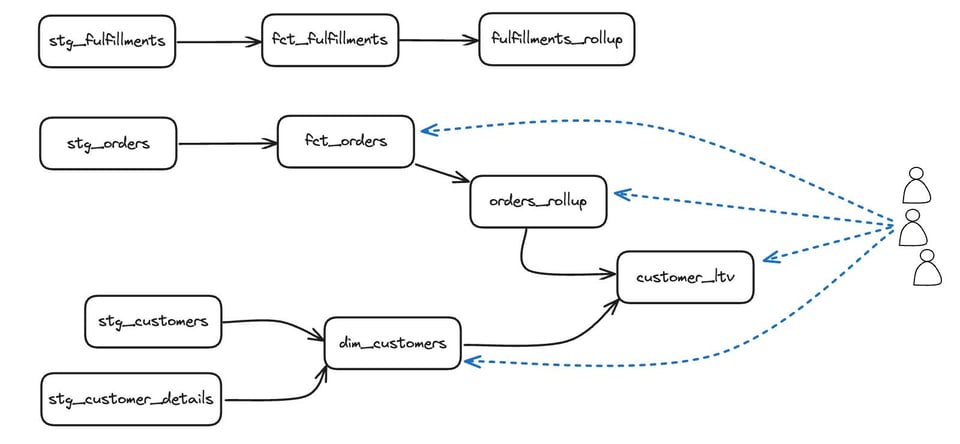
En interrogeant les tables inutilisées, on identifierait initialement chaque table comme ayant une certaine utilisation, mais cette utilisation proviendrait de dbt lui-même, qui exécute des tests ou construit des modèles en aval. Une fois les requêtes lancées par dbt exclues, nous identifierions correctement la ligne du haut — stg_fulfillments, fct_fulfillments et fulfillments_rollup — comme modèles inutilisés, mais notre résultat indiquerait aussi que toute la couche stg_ l'est. Avec dbt, l'utilisation directe n'est pas le seul critère : il faut aussi tenir compte de l'utilisation des dépendances en aval.
Pour y parvenir, on peut construire un modèle qui capture les descendants des modèles dbt, puis agréger astucieusement les requêtes vers le haut à travers ces dépendances du DAG.
Aperçu de l'approche
Prenons un DAG encore plus simple, composé de seulement 4 modèles. Pour identifier correctement les modèles dbt inutilisés, il faut d'abord comprendre comment les modèles dépendent les uns des autres.
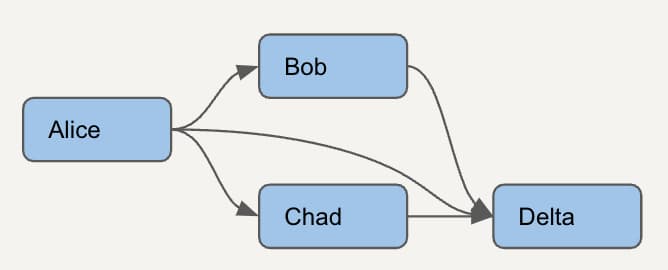
Pour chaque modèle, il faut lister tous les modèles en aval. Voici à quoi ressemblera ce DAG simple dans le nouveau modèle de dépendances que nous allons créer. Les lignes vertes représentent un nœud et lui-même, les lignes oranges les parents directs, et la ligne violette montre qu'un parent direct peut également être un parent indirect.
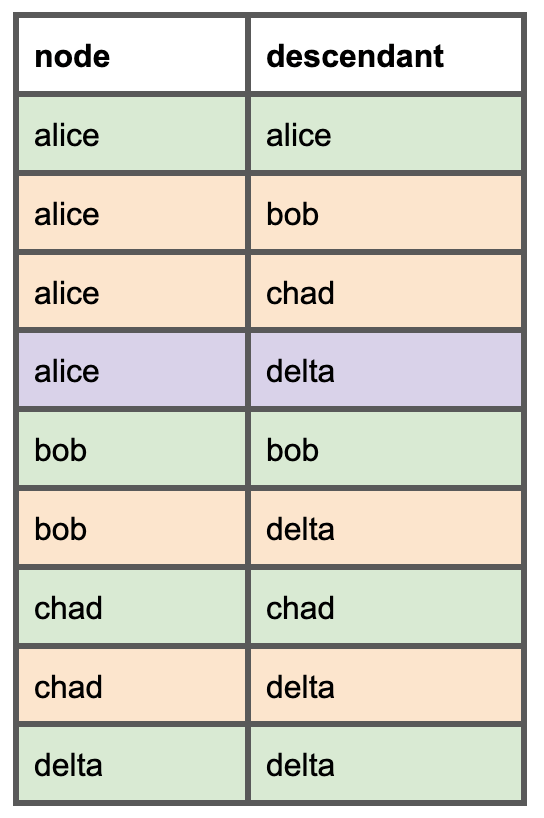
Une fois ce modèle en place, on peut par exemple déterminer si le modèle Alice peut être supprimé sans risque en vérifiant l'utilisation de ses dépendances en aval : Bob, Chad et Delta.
Prérequis
Pour déterminer quelles tables sont utilisées, nous allons nous appuyer sur les modèles présentés dans l'article précédent. Tous deux sont disponibles dans le package dbt-snowflake-monitoring conçu et maintenu par SELECT.
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
Pour notre modèle des dépendances dbt, nous allons construire quelque chose de nouveau : dbt_model_descendants. Il peut être dérivé de dbt-snowflake-monitoring ou, plus précisément, via dbt_artifacts si vous l'avez configuré. Je fournirai le SQL pour les deux sources :
- Option 1 :
dbt_snowflake_monitoring/dbt_queries.sql - Option 2 :
dbt_artifacts/dim_dbt__current_models.sql
Comment modéliser les dépendances dans votre DAG dbt
Étape 1 : récupérer les parents de chaque modèle
La première étape consiste à dériver une table avec une ligne par modèle dbt et une colonne de type tableau capturant les parents directs du modèle.
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | ["customers", "events"] |
| events | prod.analytics.events | ["stg_events"] |
| ... | ... | ... |
Pour construire ce jeu de données, deux options s'offrent à nous.
Avec dbt_snowflake_monitoring
La première option consiste à utiliser dbt_snowflake_monitoring/dbt_queries.sql, que vous devriez déjà avoir installé pour les autres modèles requis (query_base_object_access, query_history_enriched). Les deux principaux inconvénients : les modèles supprimés continueront d'apparaître pendant quelques jours après leur retrait du projet, et les sources ne sont jamais incluses, car ce ne sont pas des refs.
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- ajuste le risque d'inclusion de modèles supprimés
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optionnel] ajoutez des filtres supplémentaires pour exclure certains environnements ou projets
-- and dbt_node_package_name = <mon projet>
-- and dbt_target_name = <ma target>
-- and dbt_target_database = <ma db prod>
-- and dbt_target_schema in <mes schémas prod>
Déployer le code
Avec dbt_artifacts
La seconde option consiste à utiliser dbt_artifacts/dim_dbt__current_models. Plus robuste, elle nécessite toutefois le package dbt_artifacts, dont la mise en place est plus complexe.
select
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array,
from dim_dbt__current_models
where
-- [optionnel] filtrer sur des bases spécifiques
-- database in (<vos bases>)
Étape 2 : déduire les enfants des nœuds
Maintenant que nous avons une liste de nœuds, nous allons créer un nouveau CTE, node_children, en aplatissant le CTE nodes. Cela permet de cartographier les parents au premier degré.
Avec dbt_snowflake_monitoring
with
nodes as (
select
dbt_node_name as node,
dbt_node_refs as parent_array,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
query_id
from dbt_queries_select
where true
and start_time > current_date - 3 -- ajuste le risque d'inclusion de modèles supprimés
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
qualify row_number() over (partition by dbt_node_name order by end_time desc) = 1
Déployer le code
Avec dbt_artifacts
with
nodes as (
select
-- on suppose que les noms de modèles packagés n'entrent pas en collision
split_part(node_id, '.', 3) as node,
lower(concat(database, '.', schema, '.', name)) as table_sk,
depends_on_nodes as parent_array
from dim_dbt__current_models
),
-- Déplie le tableau des parents (refs) et inverse la relation en termes de nœud -> descendant.
node_children as (
Déployer le code
Étape 3 : trouver récursivement tous les descendants d'un modèle
Le reste de la requête est identique, que vous utilisiez dbt-snowflake-monitoring ou dbt-artifacts. Voici les étapes :
- Dériver
node_descendants_recursive(tous les degrés) en joignant récursivementnode_children(ci-dessus) à lui-même - La granularité à ce stade correspond à tous les chemins
- Ajouter par union une ligne supplémentaire pour un nœud et lui-même
- Agréger
node_descendantsen paires uniques nœud-descendant
Voici la requête en supposant que vous utilisez dbt-snowflake-monitoring :
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from dbt_queries
where
start_time > current_date - 3 -- ajuste le risque d'inclusion de modèles supprimés
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
-- [optionnel] ajoutez des filtres supplémentaires pour exclure certains environnements ou projets
-- and dbt_node_package_name = <mon projet>
Déployer le code
Rendez-vous en annexe pour une version de cette requête directement réutilisable dans votre projet dbt.
Comment identifier les modèles dbt inutilisés par requête
Avec notre nouveau modèle dbt_model_descendants qui tient compte des dépendances entre modèles (ou faut-il parler de descendances ?), nous pouvons agréger l'utilisation directe des tables et la propager vers le haut à travers le DAG. Cela prend la forme d'une jointure des comptages de requêtes côté descendants, avec une agrégation conditionnelle autour du parent. La self-edge entre en jeu ici : l'agrégation conditionnelle peut distinguer l'utilisation directe de l'utilisation indirecte en vérifiant si le descendant est en réalité le nœud lui-même.
with
table_queries as (
select
lower(query_base_object_access.object_name) as table_sk,
count(*) as count_queries
from query_history_enriched_select
inner join query_base_object_access
on query_history_enriched_select.query_id = query_base_object_access.query_id
and query_history_enriched_select.start_time = query_base_object_access.query_start_time
where
query_history_enriched_select.start_time > current_date - 180
and query_history_enriched_select.query_type = 'SELECT'
and query_history_enriched_select.execution_status = 'SUCCESS'
-- exclure les requêtes dbt
and dbt_metadata is null
Déployer le code
Cette requête nous indique combien de requêtes d'utilisation ciblent directement chaque modèle dbt, ainsi que le nombre de requêtes d'utilisation réparties sur les descendants en aval. Si un modèle affiche total_queries = 0, c'est qu'il ne sert ni à un usage direct, ni à soutenir un usage direct en aval. Attention : downstream_queries et total_queries seront supérieurs au nombre réel total de requêtes Snowflake, car une même requête peut être comptabilisée sur plusieurs nœuds.
Que faire des modèles inutilisés
En tant qu'analytics engineer, je m'y connais bien mieux en construction de nouvelles tables qu'en suppression d'anciennes.
La plupart des modèles dbt sont des transformations figées de données brutes que l'on peut désactiver puis réactiver sans rien perdre au passage. Bien sûr, le modèle de production deviendra obsolète tant qu'il restera désactivé, mais il n'y aura aucune perte irrécupérable d'information. Dans ces cas-là, il suffit de désactiver le modèle, ou de le supprimer en le laissant vivre dans votre historique git — les deux options se valent. Je recommande aussi de supprimer la table à ce stade, simplement pour éviter que des utilisateurs n'accèdent à des données obsolètes.
Les modèles comme les snapshots dbt, ou d'autres schémas incrémentaux plus sophistiqués, ne rentrent pas forcément dans cette description. Déprécier un élément de cette catégorie demandera une réflexion plus spécifique au cas, mais pour l'avoir vécu, je sais qu'il est aussi probable que personne ne sache à quoi sert le modèle, ni même quelles étaient ses intentions de départ.
Comment supprimer un modèle dbt de votre projet
Étapes pour supprimer un modèle :
- Supprimez le fichier de modèle
.sql.
- Faites une recherche
Ctrl+Shift+Fdu nom du modèle dans tout le projet pour trouver…- les
refs()vers le modèle - les références au modèle dans les fichiers de schéma ou de config
.yml.
- les
- Supprimez la table (ou la vue) Snowflake correspondante
Avec cette approche, vous n'aurez probablement pas besoin de mettre à jour un ref(), car tout modèle qui en référence un autre inutilisé doit lui-même être inutilisé (sinon le parent aurait une utilisation en aval !). En cas de chaîne de modèles inutilisés, je recommande de commencer par la fin et de remonter ; pour A -> B -> C, supprimez C en premier !
Désactiver un modèle est un moyen rapide de l'éteindre sans supprimer de code. Les modèles désactivés se comportent comme s'ils n'existaient pas, mais leur code reste dans votre projet ; il suffit d'une ligne de config :
-- my_unused_model.sql
{{ config(enabled = false) }}
select ...
C'est sans doute la façon la plus rapide et la plus facilement réversible de couper un modèle, mais si vous utilisez déjà git, vous ne perdrez de toute façon aucun code en le supprimant. Et si la prolifération des modèles vous préoccupe, mieux vaut emmener les modèles inutilisés à la déchetterie plutôt que d'instaurer un coin poubelle dédié.
Enfin, n'oubliez pas de remercier vos modèles pour leur dur labeur. Comme le dit la grande Data Engineer Marie Kondo :
Chérissez les [modèles analytiques] qui vous procurent de la joie, et laissez partir les autres avec gratitude.
Annexe – fichiers pour votre projet dbt
{{ config(materialized='table') }}
with
nodes as (
select
dbt_node_name as node,
lower(concat(dbt_target_database, '.', dbt_target_schema, '.', dbt_node_alias)) as table_sk,
dbt_node_refs as parent_array
from {{ ref('dbt_queries') }}
where
start_time > current_date - 3 -- ajuste le risque d'inclusion de modèles supprimés
and dbt_node_resource_type in ('model', 'snapshot', 'seed')
and execution_status = 'SUCCESS'
Déployer le code
version: 2
models:
- name: dbt_model_descendants
description: >-
Une table qui associe chaque nœud de modèle du DAG à l'ensemble de ses nœuds descendants.
Le mapping inclut le modèle lui-même comme descendant avec depth = 0. Les sources ne sont pas incluses.
columns:
- name: node_descendant_sk
description: Identifiant unique d'une paire nœud-descendant
tests:
- unique
- not_null
- name: node
description: Le nom d'un nœud du DAG
- name: descendant
Déployer le code
Jay Sobel·Analytics Engineer chez Ramp
Jay est Senior Analytics Engineer chez Ramp, l'une des startups à la croissance la plus rapide aux États-Unis. Il cumule près de dix ans d'expérience en analyse et en engineering de données, acquise au sein de nombreuses entreprises technologiques à forte croissance comme Gopuff, Drizly, Wanderu et LevelUp. Membre passionné des communautés dbt et Snowflake, il contribue régulièrement aux discussions sur l'optimisation et les bonnes pratiques.